Datatyper i Power BI Desktop
I denne artikel beskrives de datatyper, som understøttes af Power BI Desktop og DAX (Data Analysis Expressions).
Når Power BI indlæser data, forsøger den at konvertere datatyperne for kildekolonner til datatyper, der understøtter mere effektiv lagring, beregninger og datavisualisering. Hvis en kolonne med værdier, du importerer fra Excel, f.eks. ikke har nogen brøkværdier, konverterer Power BI Desktop datakolonnen til en Heltal datatype, hvilket er bedre egnet til lagring af heltal.
Dette koncept er vigtigt, fordi nogle DAX-funktioner har særlige krav til datatyper. I mange tilfælde konverterer DAX-implicit datatyper, men i nogle tilfælde gør det ikke. Hvis en DAX-funktion f.eks. kræver en dato datatype, men datatypen for kolonnen er Text, fungerer DAX-funktionen ikke korrekt. Det er derfor vigtigt og nyttigt at bruge de korrekte datatyper til kolonner.
Fastlæg og angiv en kolonnes datatype
I Power BI Desktop kan du bestemme og angive en kolonnes datatype i Power Query-editor, i tabelvisning eller i rapportvisning:
Vælg kolonnen i Power Query-editor, og vælg derefter datatype i gruppen Transformér på båndet.
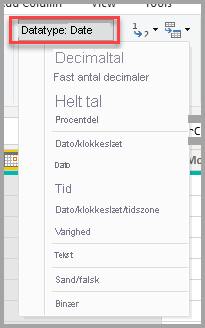
I tabelvisning eller rapportvisning skal du vælge kolonnen og derefter vælge rullepilen ud for Datatype på fanen Kolonneværktøjer fanen på båndet.
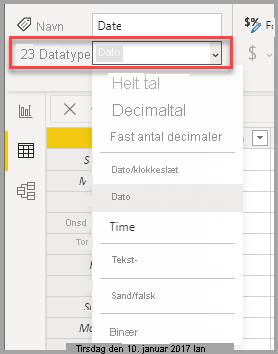
Rullemenuen Datatype i Power Query-editor indeholder to datatyper, der ikke findes i tabelvisning eller rapportvisning: dato/klokkeslæt/tidszone og varighed. Når du indlæser en kolonne med disse datatyper i Power BI-modellen, konverteres en kolonne af typen Date/Time/Timezone til en Dato/klokkeslæt datatype, og en kolonne af typen Varighed konverteres til et decimaltal datatype.
Datatypen binær understøttes ikke uden for Power Query-editoren. I Power Query-editor kan du bruge datatypen binære, når du indlæser binære filer, hvis du konverterer dem til andre datatyper, før du indlæser dem i Power BI-modellen. Det binære valg findes i menuerne Tabelvisning og Rapportvisning af ældre årsager, men hvis du forsøger at indlæse binære kolonner i Power BI-modellen, kan du støde på fejl.
Taltyper
Power BI Desktop understøtter tre taltyper: decimaltal, faste decimaltalog Heltal.
Du kan bruge egenskaben Kolonne DataType tabelobjektmodel (TOM) til at angive de DataType Optællinger for taltyper. Du kan finde flere oplysninger om programmatisk ændring af objekter i Power BI under Program Power BI-semantiske modeller medtabelobjektmodel .
Decimaltal
decimaltal er den mest almindelige taltype og kan håndtere tal med brøkdele og heltal. decimaltal repræsenterer 64-bit (otte byte) flydende tal med negative værdier fra -1,79E +308 til og med -2,23E -1 308, positive værdier fra 2.23E -308 til og med 1.79E +308og 0. Tal som 34, 34.01og 34.000367063 er gyldige decimaltal.
Den højeste præcision, som decimaltal type kan repræsentere, er 15 cifre. Decimalseparatoren kan forekomme et vilkårligt sted i tallet. Denne type svarer til, hvordan Excel gemmer sine tal, og TOM angiver denne type som DataType.Double Enum.
Fast decimaltal
Datatypen Fast decimaltal har en fast placering til decimalseparatoren. Decimalseparatoren har altid fire cifre til højre og tillader 19 betydende cifre. Den største værdi, som det faste decimaltal, kan repræsentere, er positiv eller negativ 922.337.203.685.477,5807.
Den faste decimaltal type er nyttig i de tilfælde, hvor afrunding kan medføre fejl. Tal, der har små brøkværdier, kan nogle gange akkumuleres og tvinge et tal til at være lidt unøjagtigt. Den faste decimaltal type kan hjælpe dig med at undgå denne type fejl ved at afkorte værdierne efter de fire cifre til højre for decimalseparatoren.
Denne datatype svarer til SQL Server's Decimal (19,4)eller datatypen Currency i Analysis Services og Power Pivot i Excel. TOM angiver denne type som DataType.Decimal Enum.
Helt tal
Heltal repræsenterer en heltalsværdi på 64-bit (otte byte). Da det er et heltal, har heltal ingen cifre til højre for decimaltegnet. Denne type tillader 19 cifre med positive eller negative heltal mellem -9.223.372.036.854.775.807 (-2^63+1) og 9.223.372.036.854.775.806 (2^63-2), så de kan repræsentere det størst mulige antal numeriske datatyper.
Som med typen fast decimal kan typen Heltal være nyttig, når du har brug for at styre afrunding. TOM repræsenterer datatypen Heltal som DataType.Int64 Enum.
Seddel
Power BI Desktop-datamodellen understøtter 64-bit heltalsværdier, men på grund af JavaScript-begrænsninger er det største antal Power BI-visualiseringer, der sikkert kan udtrykkes, 9.007.199.254.740.991 (2^53-1). Hvis din datamodel har større tal, kan du reducere deres størrelse ved hjælp af beregninger, før du føjer dem til visualiseringer.
Nøjagtighed af taltypeberegninger
Kolonneværdier for decimaltal datatype gemmes som omtrentlige datatyper i henhold til IEEE 754 Standard for flydende tal. Omtrentlige datatyper har indbyggede præcisionsbegrænsninger, da de i stedet for at gemme nøjagtige talværdier kan gemme tilnærmelser, der er meget tæt eller afrundede.
Præcisionstab eller upåcisionkan forekomme, hvis den flydende talværdi ikke pålideligt kan kvantificere antallet af flydende tal. Upræcision kan potentielt forekomme som uventede eller unøjagtige beregninger, der resulterer i nogle rapporteringsscenarier.
Lighedsrelaterede sammenligningsberegninger mellem værdier af decimaltal datatype kan potentielt returnere uventede resultater. Lighedssammenligninger omfatter lig med =, større end >, mindre end <, større end eller lig med >=og mindre end eller lig med <=.
Dette problem er mest tydeligt, når du bruger funktionen RANKX i et DAX-udtryk, som beregner resultatet to gange, hvilket resulterer i lidt forskellige tal. Rapportbrugere bemærker muligvis ikke forskellen mellem de to tal, men rangeringsresultatet kan være mærkbart unøjagtigt. Hvis du vil undgå uventede resultater, kan du ændre kolonnedatatypen fra decimaltal til enten faste decimaltal eller Heltaleller foretage en tvungen afrunding ved hjælp af ROUND-. Den faste decimaltal datatype har større præcision, fordi decimalseparatoren altid har fire cifre til højre.
Beregninger, der opsummerer værdierne i en kolonne med decimaltal datatype, kan sjældent returnere uventede resultater. Dette resultat er mest sandsynligt med kolonner, der har store mængder både positive tal og negative tal. Sumresultatet påvirkes af fordelingen af værdier på tværs af rækker i kolonnen.
Hvis en påkrævet beregning summerer de fleste positive tal, før de fleste negative tal lægges sammen, kan den store positive delvise sum i begyndelsen potentielt forvrænge resultaterne. Hvis beregningen sker med at tilføje balancerede positive og negative tal, bevarer forespørgslen mere præcision og returnerer derfor mere nøjagtige resultater. Hvis du vil undgå uventede resultater, kan du ændre kolonnedatatypen fra decimaltal til faste decimaltal eller Heltal.
Dato-/klokkeslætstyper
Power BI Desktop understøtter fem dato/klokkeslæt datatyper i Power Query-editor. Både dato/klokkeslæt/tidszone- og varighed konvertere under indlæsning til Power BI Desktop-datamodellen. Modellen understøtter dato/klokkeslæt-, eller du kan formatere værdierne som dato eller klokkeslæt uafhængigt af hinanden.
dato/klokkeslæt- repræsenterer både en dato- og klokkeslætsværdi. Den underliggende dato/klokkeslæt- værdi gemmes som et decimaltal type, så du kan konvertere mellem de to typer. Tidsdelen gemmes som en brøkdel til hele multiplum af 1/300 sekunder (3,33 ms). Datatypen understøtter datoer mellem år 1900 og 9999.
dato kun repræsenterer en dato uden klokkeslætsdel. En dato konverteres til modellen som en dato-/klokkeslætsværdi værdi med nul for brøkværdien.
Klokkeslæt kun repræsenterer et klokkeslæt uden datodel. Et klokkeslæt konverteres til modellen som en dato-/klokkeslætsværdi værdi uden cifre til venstre for decimaltegnet.
dato/klokkeslæt/tidszone repræsenterer en UTC-dato/klokkeslæt med en tidszoneforskydning og konverteres til dato/klokkeslæt, når den indlæses i modellen. Power BI-modellen justerer ikke tidszonen baseret på en brugers placering eller landestandard. En værdi på 09:00, der indlæses i modellen i USA, vises som 09:00, uanset hvor rapporten åbnes eller vises.
Varighed repræsenterer en tidsperiode og konverteres til et decimaltal type, når de indlæses i modellen. Som decimaltal type kan du tilføje eller trække værdierne fra Dato/klokkeslæt værdier med korrekte resultater og nemt bruge værdierne i visualiseringer, der viser størrelse.
Teksttype
Datatypen Text er en Unicode-tegndatastreng, som kan være bogstaver, tal eller datoer, der er repræsenteret i et tekstformat. Den praktiske maksimumgrænse for strenglængde er ca. 32.000 Unicode-tegn baseret på Power BI's underliggende Power Query-program og dens grænser for tekst datatypelængder. Tekstdatatyper, der overskrider den praktiske maksimumgrænse, vil sandsynligvis resultere i fejl.
Den måde, som Power BI gemmer tekstdata på, kan medføre, at dataene vises anderledes i visse situationer. I de næste afsnit beskrives almindelige situationer, der kan medføre, at Tekst data ændrer udseende en smule mellem at forespørge om data i Power Query-editor og indlæse dem i Power BI.
Forskel på små og små bogstaver
Programmet, der gemmer og forespørger data i Power BI, skelner mellem store og små bogstaverog behandler forskellige bogstaver med stort som den samme værdi. "A" er lig med "a". Der er dog forskel på store og små bogstaver i Power Query, hvor "A" ikke er det samme som "a". Forskellen i forskel på store og små bogstaver kan føre til situationer, hvor tekstdata ændrer stort set uforklarligt efter indlæsning i Power BI.
I følgende eksempel vises ordredata: En OrderNo kolonne, der er entydig for hver ordre, og en Addressee kolonne, der viser det modtagernavn, der blev angivet manuelt på ordretidspunktet. I Power Query-editor vises flere ordrer med samme Addressee navne, der er angivet i systemet med forskellige store bogstaver.
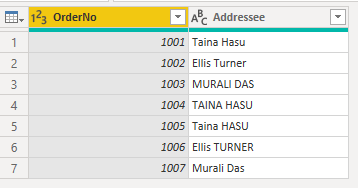
Når Power BI har indlæst dataene, ændres store bogstaver i de dublerede navne i Fanen Data fra den oprindelige post til en af varianterne med stort.
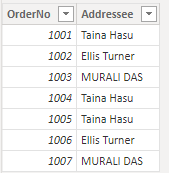
Denne ændring sker, fordi der er forskel på store og små bogstaver i Power Query-editor, så dataene vises nøjagtigt, som de er gemt i kildesystemet. Programmet, der gemmer data i Power BI, skelner ikke mellem store og små bogstaver, så det behandler versionerne med små og store bogstaver af et tegn som identiske. Power Query-data, der indlæses i Power BI-programmet, kan ændres tilsvarende.
Power BI-programmet evaluerer hver række individuelt, når den indlæser data fra toppen. For hver tekstkolonne, f.eks. Addressee, gemmer programmet en ordbog med entydige værdier for at forbedre ydeevnen ved hjælp af datakomprimering. Programmet ser de første tre værdier i kolonnen Addressee som entydige og gemmer dem i ordbogen. Derefter evalueres navnene som identiske, fordi der ikke skelnes mellem store og små bogstaver i programmet.
Programmet ser navnet "Taina Hasu" som identisk med "TAINA HASU" og "Taina HASU", så det ikke gemmer disse variationer, men refererer til den første variation, den gemte. Navnet "MURALI DAS" vises med store bogstaver, fordi det er sådan, navnet blev vist, første gang programmet evaluerede det, da dataene indlæses oppefra og ned.
Dette billede illustrerer evalueringsprocessen:

I det foregående eksempel indlæser Power BI-programmet den første række data, opretter ordbogen Addressee og føjer Taina Hasu til den. Programmet føjer også en reference til denne værdi i kolonnen Addressee i den tabel, der indlæses. Programmet gør det samme for den anden og tredje række, fordi disse navne ikke svarer til de andre, når der ikke skelnes mellem små og små bogstaver.
For den fjerde række sammenligner programmet værdien med navnene i ordbogen og finder navnet. Da der ikke skelnes mellem store og små bogstaver i programmet, er "TAINA HASU" og "Taina Hasu" de samme. Programmet føjer ikke et nyt navn til ordbogen, men henviser til det eksisterende navn. Den samme proces sker for de resterende rækker.
Seddel
Da der ikke skelnes mellem store og små bogstaver i det program, der gemmer og forespørger om data i Power BI, skal du være særligt forsigtig, når du arbejder i DirectQuery-tilstand med en kilde, hvor der skelnes mellem store og små bogstaver. Power BI forudsætter, at kilden har fjernet dublerede rækker. Da der ikke skelnes mellem store og små bogstaver i Power BI, behandles to værdier, der kun adskiller sig fra store og små bogstaver, som dubletter, mens kilden muligvis ikke behandler dem som sådan. I sådanne tilfælde er det endelige resultat ikke defineret.
Hvis du bruger DirectQuery-tilstand med en datakilde med forskel på store og små bogstaver, skal du normalisere kabinettet i kildeforespørgslen eller i Power Query-editor for at undgå denne situation.
Foranstillede og efterstillede mellemrum
Power BI-programmet trimmer automatisk efterstillede mellemrum, der følger efter tekstdata, men fjerner ikke foranstillede mellemrum foran dataene. Hvis du vil undgå forvirring, skal du bruge funktionen Text.Trim til at fjerne mellemrum i starten eller slutningen af teksten, når du arbejder med data, der indeholder foran- eller efterstillede mellemrum. Hvis du ikke fjerner foranstillede mellemrum, kan en relation muligvis ikke oprette på grund af dublerede værdier, eller visualiseringer kan returnere uventede resultater.
I følgende eksempel vises data om kunder: en Name kolonne, der indeholder navnet på kunden og en Index kolonne, der er entydig for hver post. Navnene vises i anførselstegn for klarheds skyld. Kundenavnet gentages fire gange, men hver gang med forskellige kombinationer af foranstillede og efterstillede mellemrum. Disse variationer kan forekomme med manuel indtastning af data over tid.
| Række | Foranstillet mellemrum | Efterstillet mellemrum | Navn | Indeks | Tekstlængde |
|---|---|---|---|---|---|
| 1 | Nej | Nej | "Dylan Williams" | 1 | 14 |
| 2 | Nej | Ja | "Dylan Williams" | 10 | 15 |
| 3 | Ja | Nej | "Dylan Williams" | 20 | 15 |
| 4 | Ja | Ja | " Dylan Williams " | 40 | 16 |
I Power Query-editor vises de resulterende data på følgende måde.
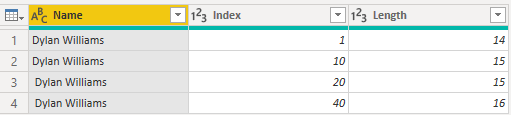
Når du går til fanen Tabel i Power BI, når du har indlæst dataene, ser den samme tabel ud som på følgende billede med det samme antal rækker som før.
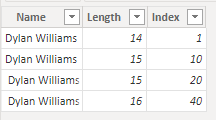
Men en visualisering, der er baseret på disse data, returnerer kun to rækker.

På det foregående billede har den første række en samlet værdi på 60 for feltet Index, så den første række i visualiseringen repræsenterer de sidste to rækker i de indlæste data. Den anden række med totalen Index- værdi på 11 repræsenterer de første to rækker. Forskellen i antallet af rækker mellem visualiseringen og datatabellen skyldes, at programmet automatisk fjerner eller trimmer efterstillede mellemrum, men ikke foranstillede mellemrum. Så programmet evaluerer den første og anden række og den tredje og fjerde række som identisk, og visualiseringen returnerer disse resultater.
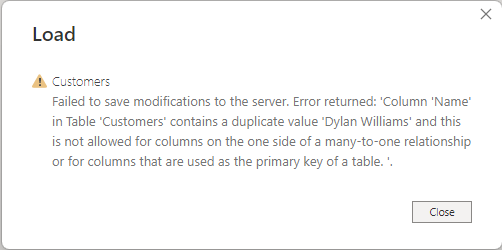
Denne funktionsmåde kan også medføre fejlmeddelelser, der er relateret til relationer, fordi der registreres dubletværdier. Afhængigt af konfigurationen af dine relationer kan du f.eks. se en fejl, der ligner følgende billede:
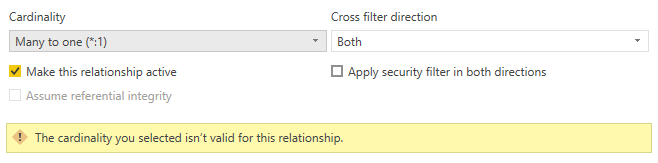
I andre situationer kan du muligvis ikke oprette en mange til en-relation eller en til en-relation, fordi der registreres dubletværdier.
Du kan spore disse fejl tilbage til foranstillede eller efterstillede mellemrum og løse dem ved hjælp af Text.Trimeller Formatér>Trim under Transformérfor at fjerne mellemrummene i Power Query-editor.
Sand/falsk type
Datatypen sand/falsk
Power BI konverterer og viser data forskelligt i visse situationer. I dette afsnit beskrives almindelige tilfælde af konvertering af booleske værdier, og hvordan du håndterer konverteringer, der skaber uventede resultater i Power BI.
I dette eksempel indlæser du data om, hvorvidt dine kunder har tilmeldt sig nyhedsbrevet. Værdien SAND angiver, at kunden har tilmeldt sig nyhedsbrevet, og en værdi på FALSE angiver, at kunden ikke har tilmeldt sig.
Men når du publicerer rapporten i Power BI-tjenesten, vises 0 og -1 i stedet for de forventede værdier for TRUE eller FALSE. I følgende trin beskrives det, hvordan denne konvertering sker, og hvordan du forhindrer den.
Den forenklede forespørgsel til denne tabel vises på følgende billede:
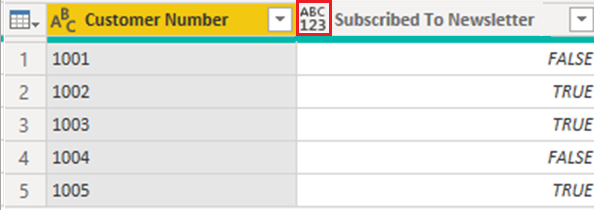
Datatypen for kolonnen Abonner på nyhedsbrev er angivet til Alle, og Derfor indlæser Power BI dataene i modellen som Text.
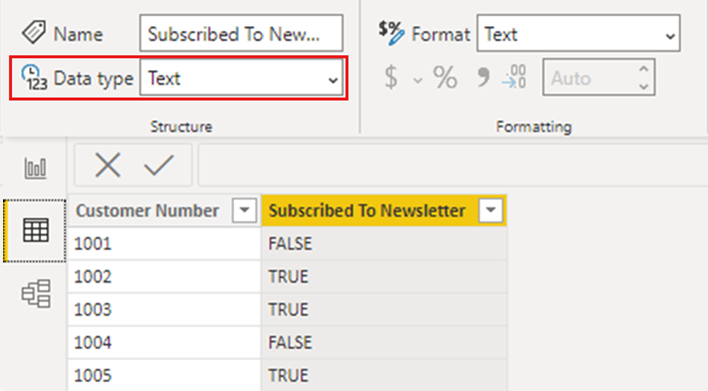
Når du tilføjer en simpel visualisering, der viser de detaljerede oplysninger pr. kunde, vises dataene i visualiseringen som forventet, både i Power BI Desktop og publiceret til Power BI-tjenesten.
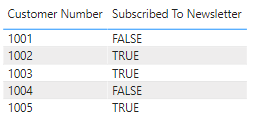
Men når du opdaterer den semantiske model i Power BI-tjenesten , viser kolonnen Abonner på nyhedsbrev i visualiseringerne værdier som -1 og 0i stedet for at vise dem som TRUE eller FALSE:
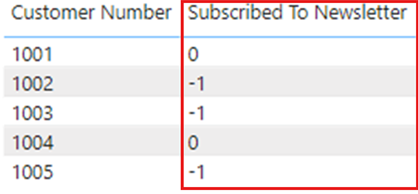
Hvis du publicerer rapporten igen fra Power BI Desktop, viser kolonnen Abonner på nyhedsbrev igen SAND eller FALSE som forventet, men når der sker en opdatering i Power BI-tjenesten, ændres værdierne igen for at vise -1 og 0.
Løsningen til at forhindre denne situation er at angive booleske kolonner til at skrive True/False- i Power BI Desktop og publicere din rapport igen.
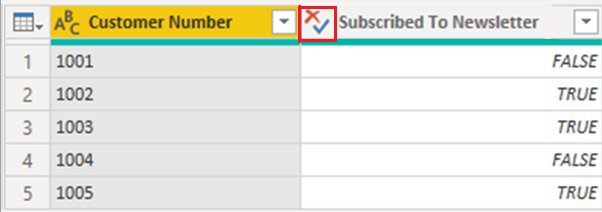
Når du foretager ændringen, viser visualiseringen værdierne i Abonner på nyhedsbrev kolonne lidt anderledes. I stedet for at teksten er alle store bogstaver som indtastet i tabellen, er det kun det første bogstav, der skrives med stort. Denne ændring er et resultat af at ændre kolonnens datatype.
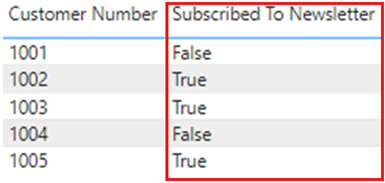
Når du har ændret datatypen, publicerer den igen i Power BI-tjenesten, og der sker en opdatering, viser rapporten værdierne som Sand eller Falsesom forventet.
Hvis du vil opsummere, skal du, når du arbejder med booleske data i Power BI, sørge for, at dine kolonner er angivet til datatypen sand/falsk i Power BI Desktop.
Tom type
Blank er en DAX-datatype, der repræsenterer og erstatter SQL null-værdier. Du kan oprette en tom værdi ved hjælp af funktionen BLANK og teste, om der er tomme værdier, ved hjælp af den ISBLANK logiske funktion.
Binær type
Du kan bruge datatypen binær til at repræsentere alle data med et binært format. I Power Query-editor kan du bruge denne datatype, når du indlæser binære filer, hvis du konverterer dem til andre datatyper, før du indlæser dem i Power BI-modellen.
Binære kolonner understøttes ikke i Power BI-datamodellen. Det binære valg findes i menuerne Tabelvisning og Rapportvisning af ældre årsager, men hvis du forsøger at indlæse binære kolonner i Power BI-modellen, kan der opstå fejl.
Seddel
Hvis der er en binær kolonne i outputtet af trinnene i en forespørgsel, kan det medføre fejl, hvis du forsøger at opdatere dataene via en gateway. Det anbefales, at du eksplicit fjerner alle binære kolonner som det sidste trin i dine forespørgsler.
Tabeltype
DAX bruger datatypen Tabel i mange funktioner, f.eks. sammenlægninger og time intelligence-beregninger. Nogle funktioner kræver en reference til en tabel. Andre funktioner returnerer en tabel, som du derefter kan bruge som input til andre funktioner.
I nogle funktioner, der kræver en tabel som input, kan du angive et udtryk, der evalueres til en tabel. Nogle funktioner kræver en reference til en basistabel. Du kan få oplysninger om kravene til bestemte funktioner i referencen til DAX-funktion.
Konvertering af implicitte og eksplicitte datatyper
Hver DAX-funktion har specifikke krav til de datatyper, der skal bruges som input og output. Nogle funktioner kræver f.eks. heltal for nogle argumenter og datoer for andre. Andre funktioner kræver tekst eller tabeller.
Hvis dataene i den kolonne, du angiver som et argument, ikke er kompatible med den datatype, som funktionen kræver, kan DAX returnere en fejl. Men hvor det er muligt, forsøger DAX implicit at konvertere dataene til den påkrævede datatype.
For eksempel:
- Hvis du skriver en dato som en streng, fortolker DAX strengen og forsøger at angive den som et af Windows-dato- og klokkeslætsformaterne.
- Du kan tilføje TRUE + 1 og få resultatet 2, fordi DAX implicit konverterer TRUE til tallet 1og udfører handlingen 1+1.
- Hvis du tilføjer værdier i to kolonner med én værdi repræsenteret som tekst ("12") og den anden som et tal (12), konverterer DAX implicit strengen til et tal og foretager derefter tilføjelsen for et numerisk resultat. Udtrykket = "22" + 22 returnerer 44.
- Hvis du forsøger at sammenkæde to tal, præsenterer DAX dem som strenge og sammenkæder dem derefter. Udtrykket = 12 & 34 returnerer "1234".
Tabeller med implicitte datakonverteringer
Operatoren bestemmer, hvilken type konvertering DAX udfører, ved at caste de værdier, den kræver, før den anmodede handling udføres. I følgende tabeller vises operatorerne, og DAX-konverteringen sker for hver datatype, når den kombineres med datatypen i den overlappende celle.
Seddel
Disse tabeller indeholder ikke datatypen Tekst. Når et tal repræsenteres i et tekstformat, forsøger Power BI i nogle tilfælde at bestemme taltypen og repræsentere dataene som et tal.
Tilføjelse (+)
| HELTAL | VALUTA | REEL | Dato/klokkeslæt | |
|---|---|---|---|---|
| HELTAL | HELTAL | VALUTA | REEL | Dato/klokkeslæt |
| VALUTA | VALUTA | VALUTA | REEL | Dato/klokkeslæt |
| RIGTIGE | REEL | REEL | REEL | Dato/klokkeslæt |
| |
Dato/klokkeslæt | Dato/klokkeslæt | Dato/klokkeslæt | Dato/klokkeslæt |
Hvis en additionshandling f.eks. bruger et reelt tal i kombination med valutadata, konverterer DAX begge værdier til REAL og returnerer resultatet som REAL.
Subtraktion (-)
I følgende tabel er rækkeoverskriften minuend (venstre side), og kolonneoverskriften er undertrahend (højre side).
| HELTAL | VALUTA | REEL | Dato/klokkeslæt | |
|---|---|---|---|---|
| HELTAL | HELTAL | VALUTA | REEL | REEL |
| VALUTA | VALUTA | VALUTA | REEL | REEL |
| RIGTIGE | REEL | REEL | REEL | REEL |
| |
Dato/klokkeslæt | Dato/klokkeslæt | Dato/klokkeslæt | Dato/klokkeslæt |
Hvis en subtraktionshandling f.eks. bruger en dato med en anden datatype, konverterer DAX begge værdier til datoer, og returværdien er også en dato.
Seddel
Datamodeller understøtter den monadiske operator – (negativ), men denne operator ændrer ikke operandens datatype.
Multiplikation (*)
| HELTAL | VALUTA | REEL | Dato/klokkeslæt | |
|---|---|---|---|---|
| HELTAL | HELTAL | VALUTA | REEL | HELTAL |
| VALUTA | VALUTA | REEL | VALUTA | VALUTA |
| RIGTIGE | REEL | VALUTA | REEL | REEL |
Hvis en multiplikationshandling f.eks. kombinerer et heltal med et reelt tal, konverterer DAX begge tal til reelle tal, og returværdien er også REAL.
Division (/)
I følgende tabel er rækkeoverskriften tælleren, og kolonneoverskriften er nævneren.
| HELTAL | VALUTA | REEL | Dato/klokkeslæt | |
|---|---|---|---|---|
| HELTAL | REEL | VALUTA | REEL | REEL |
| VALUTA | VALUTA | REEL | VALUTA | REEL |
| RIGTIGE | REEL | REEL | REEL | REEL |
| |
REEL | REEL | REEL | REEL |
Hvis en divisionshandling f.eks. kombinerer et heltal med en valutaværdi, konverterer DAX begge værdier til reelle tal, og resultatet er også et reelt tal.
Sammenligningsoperatorer
I sammenligningsudtryk betragter DAX booleske værdier, der er større end strengværdier, og strengværdier, der er større end numeriske værdier eller dato-/klokkeslætsværdier. Tal og dato-/klokkeslætsværdier har samme placering.
DAX foretager ingen implicitte konverteringer for booleske værdier eller strengværdier. BLANK eller en tom værdi konverteres til 0, ""eller False, afhængigt af datatypen for den anden sammenlignede værdi.
Følgende DAX-udtryk illustrerer denne funktionsmåde:
=IF(FALSE()>"true","Expression is true", "Expression is false")returnerer "Expression is true".=IF("12">12,"Expression is true", "Expression is false")returnerer "Expression is true".=IF("12"=12,"Expression is true", "Expression is false")returnerer "Expression is false".
DAX foretager implicitte konverteringer for numeriske typer eller dato-/klokkeslætstyper, som beskrevet i følgende tabel:
| Sammenligning Operatør |
HELTAL | VALUTA | REEL | Dato/klokkeslæt |
|---|---|---|---|---|
| HELTAL | HELTAL | VALUTA | REEL | REEL |
| VALUTA | VALUTA | VALUTA | REEL | REEL |
| RIGTIGE | REEL | REEL | REEL | REEL |
| |
REEL | REEL | REEL | Dato/klokkeslæt |
Tomme værdier, tomme strenge og nulværdier
DAX repræsenterer en null-værdi, en tom værdi, en tom celle eller en manglende værdi af den samme nye værditype, en BLANK. Du kan også generere tomme værdier ved hjælp af funktionen BLANK eller teste, om der er tomme værdier, ved hjælp af funktionen ISBLANK.
Den måde, handlinger som addition eller sammenkædning håndterer tomme værdier på, afhænger af den enkelte funktion. I følgende tabel opsummeres forskellene mellem, hvordan DAX- og Microsoft Excel-formler håndterer tomme værdier.
| Udtryk | DAX | Excel |
|---|---|---|
| BLANK + BLANK | HVID | 0 (nul) |
| BLANK + 5 | 5 | 5 |
| TOM * 5 | HVID | 0 (nul) |
| 5/BLANK | Uendelighed | Fejl |
| 0/BLANK | Nan | Fejl |
| TOM/TOM | HVID | Fejl |
| FALSK ELLER TOM | FALSK | FALSK |
| FALSK OG TOM | FALSK | FALSK |
| TRUE ELLER BLANK | SAND | SAND |
| SAND OG TOM | FALSK | SAND |
| TOM ELLER TOM | HVID | Fejl |
| TOM OG TOM | HVID | Fejl |
Relateret indhold
Du kan gøre mange forskellige ting med Power BI Desktop og data. Du kan få flere oplysninger om Power BI-funktioner i følgende ressourcer: