Indtage eksporterede Dataverse-data med Azure Data Factory
Når du har eksporteret data fra Microsoft Dataverse til Azure Data Lake Storage Gen2 med Azure Synapse Link for Dataverse, kan du bruge Azure Data Factory til at oprette dataflows, transformere dine data og køre analyser.
Bemærk
Azure Synapse Link for Dataverse var tidligere kendt som Eksportér til data lake. Tjenesten blev omdøbt til maj 2021 og vil fortsat eksportere data til både Azure Data Lake og Azure Synapse Analytics.
Denne artikel beskriver, hvordan du udfører følgende opgaver:
Indstil Data Lake Storage Gen2-lagerkontoen med Dataverse-data som kilde i et Data Factory-dataflow.
Transformér Dataverse-dataene i Data Factory med et dataflow.
Indstil Data Lake Storage Gen2-lagerkontoen med Dataverse-data som modtagerpostkasse i et Data Factory-dataflow.
Kør dataflow ved at oprette en pipeline.
Forudsætninger
I dette afsnit beskrives de forudsætninger, der er nødvendige for at kunne indtage eksporterede Dataverse-data med Data Factory.
Azure-roller. Den brugerkonto, der bruges til at logge på Azure, skal være medlem af rollen bidragyder eller ejer eller en administrator af Azure-abonnementet. Hvis du vil have vist de tilladelser, du har i abonnementet, skal du gå til Azure-portalen, vælge dit brugernavn i øverste højre hjørne, vælge ... og derefter vælge Mine tilladelser. Hvis du har adgang til flere abonnementer, skal du vælge den relevante. Hvis du vil oprette og administrere underordnede ressourcer til Data Factory i Azure-portalen, herunder datasæt, sammenkædede tjenester, pipelines, udløsere og integrationskørsler, skal du tilhøre rollen Data Factory-bidragyder på ressourcegruppeniveau eller derover.
Azure Synapse Link for Dataverse. I denne vejledning antages det, at du allerede har eksporteret Dataverse data ved hjælp af Azure Synapse Link for Dataverse. I dette eksempel eksporteres firmatabeldata til Data Lake.
Azure Data Factory. I denne vejledning antages det, at du allerede har oprettet en data fabrik under samme abonnement og ressourcegruppe som den lagerkonto, der indeholder de eksporterede Dataverse-data.
Indstil Data Lake Storage Gen2-lagerkontoen som en kilde
Åbn Azure Data Factory, og vælg den data fabrik, der er i samme abonnement og ressourcegruppe som den lagerkonto, der indeholder de eksporterede Dataverse-data. Vælg derefter Opret dataflow fra startsiden.
Slå Dataflow -fejlfinding til, og vælg det foretrukne tidspunkt at leve i. Dette kan tage op til 10 minutter, men du kan fortsætte med følgende trin.

Vælg Tilføj kilde.

Gør følgende under Kildeindstillinger:
- Navn på outputstream: Angiv det ønskede navn.
- Kildetype: Vælg Inline.
- Indbygget datasæt: Vælg Almindelig datamodel.
- Sammenkædet tjeneste: Vælg lagerkontoen i rullemenuen, og sammenkæd en ny tjeneste ved at angive dine abonnementsoplysninger og bevare alle standardkonfigurationer.
- Sampling: Hvis du vil bruge alle dine data, skal du vælge Deaktiver.
Gør følgende under Kildeindstillinger:
Metadataformat: Vælg Model.json.
Rodplacering: Angiv beholdernavnet i det første felt (Beholder) eller Søg efter Gennemse i beholdernavnet, og vælg OK.
Objekt : Angiv tabelnavnet eller Søg efter i tabellen.

Under fanen Projektion kan du sikre dig, at skemaet er importeret. Hvis der ikke er kolonner, skal du vælge Skemaindstillinger og markere indstillingen Infer-drevede kolonnetyper. Konfigurer formateringsindstillingerne, så de stemmer overens med datasættet, og vælg derefter Anvend.
Du kan se dine data under fanen Dataeksempel for at sikre, at kildeoprettelsen er komplet og nøjagtig.
Transformer dine Dataverse-data
Når du har indstillet de eksporterede Dataverse-data i Azure Data Lake Storage Gen2-kontoen som kilde i Data Factory-dataflowet, er der mange muligheder for at transformere dine data. Flere oplysninger: Azure Data Factory
Følg disse instruktioner for at oprette en rangordnede for hver tabel efter kontoens omsætning.
Vælg + i nederste højre hjørne af den forrige transformering, og søg derefter efter og vælg Rangering.
Skriv følgende oplysninger under fanen Ranger indstillinger:
Navn på outputstrømme: Angiv det ønskede navn, f.eks. Rang1.
Indgående stream: Vælg det ønskede kildenavn. I dette tilfælde kildenavnet fra forrige trin.
Indstillinger: Markér ikke indstillingerne.
Rangkolonne: Angiv navnet på den oprettede rangordnede kolonne.
Sorteringsbetingelser: Vælg indtægts-kolonnen, og sortér efter Faldende rækkefølge.
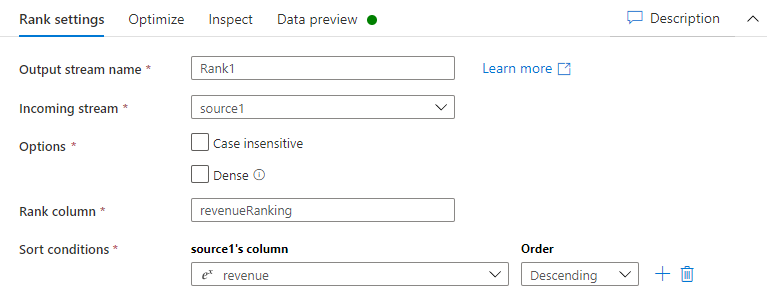
Du kan få vist dataene under fanen til forhåndsvisning af data, hvor du kan finde den nye kolonne af samme kolonne som indtægtskilden på den mest placerede placering.
Angive Data Lake Storage Gen2-lagerkonto som en sink
I sidste ende skal du angive en modtager til dit dataflow. Følg disse instruktioner for at placere de transformerede data som en afgrænset tekstfil i Data Lake.
Vælg + i nederste højre hjørne af den forrige transformering, og søg derefter efter og vælg Sink.
Gør følgende under fanen Modtager:
Navn på outputstream: Angiv det ønskede navn som f.eks. Modtager1.
Indgående stream: Vælg det ønskede kildenavn. I dette tilfælde kildenavnet fra forrige trin.
Sink-type: Vælg Afgrænset tekst.
Sammenkædet tjeneste: Vælg din lagerbeholder til Data Lake Storage Gen2-opbevaring, der indeholder de data, du har eksporteret ved hjælp af Azure Synapse Link for Dataverse-tjenesten.
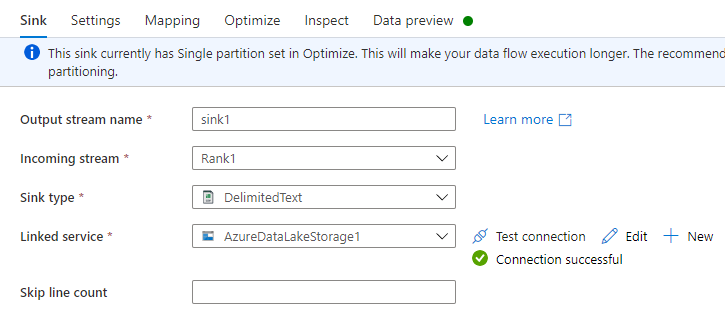
Under fanen Indstillinger skal du gøre følgende:
Mappesti: Angiv beholdernavnet i det første felt (Filsystem) eller Gennemse efter beholdernavnet, og vælg OK.
Indstilling for filnavn: Vælg output til en enkelt fil.
Output til enkelt fil: Angiv et filnavn, f.eks. ADFOutput
Lad alle andre standardindstillinger være.
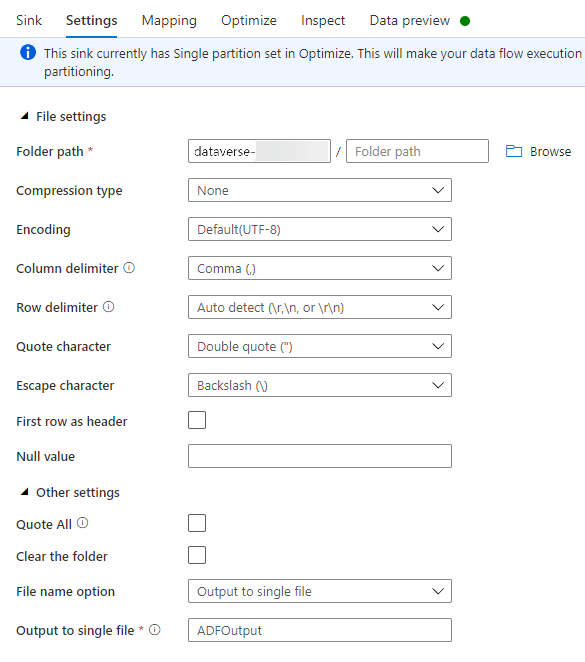
Angiv indstillingen Partition til Enkelt partition under fanen Optimer.
Du kan få vist dataene under fanen Data - forhåndsversion.
Kør dit dataflow
I venstre rude under Factory-ressourcer skal du vælge + og derefter vælge Pipeline.

Under Aktiviteter skal du vælge Flyt og transformer og derefter trække Dataflow til arbejdsområdet.
Vælg Brug eksisterende dataflow, og vælg derefter det dataflow, som du oprettede i forrige trin.
Vælg Fejlfinding på kommandolinjen.
Lad dataflowet køre, indtil den nederste visning angiver, at det er fuldført. Dette kan tage et par minutter.
Gå til den endelige objektbeholder for destinationslageret, og find den transformerede tabeldatafil.
Se også
Konfigurere Azure Synapse Link for Dataverse med Azure Data Lake
Analysere Dataverse-data i Azure Data Lake Storage Gen2 med Power BI
Bemærk
Kan du fortælle os om dine sprogpræferencer for dokumentation? Tag en kort undersøgelse. (bemærk, at denne undersøgelse er på engelsk)
Undersøgelsen tager ca. syv minutter. Der indsamles ingen personlige data (erklæring om beskyttelse af personlige oplysninger).