Selvstudium: Brug en notesbog med Apache Spark til at forespørge en KQL-database
Notesbøger er både læsbare dokumenter, der indeholder beskrivelser af dataanalyser og resultater og eksekverbare dokumenter, der kan køres for at udføre dataanalyse. I denne artikel lærer du, hvordan du bruger en Microsoft Fabric-notesbog til at læse og skrive data til en KQL-database ved hjælp af Apache Spark. I dette selvstudium bruges forudoprettede datasæt og notesbøger i både realtidsintelligens og Dataudvikler miljøer i Microsoft Fabric. Du kan få flere oplysninger om notesbøger under Sådan bruger du Microsoft Fabric-notesbøger.
Specifikt lærer du, hvordan du:
- Opret en KQL-database
- Importér en notesbog
- Skriv data til en KQL-database ved hjælp af Apache Spark
- Forespørg om data fra en KQL-database
Forudsætninger
- Et arbejdsområde med en Microsoft Fabric-aktiveret kapacitet
1 – Opret en KQL-database
Vælg dit arbejdsområde på navigationslinjen til venstre.
Følg et af disse trin for at begynde at oprette en hændelsesstream:
- Vælg Nyt element, og derefter Eventhouse. I feltet Eventhouse-navn skal du angive nycGreenTaxiog derefter vælge Opret. Der oprettes en KQL-database med samme navn.
- Vælg Databaseri et eksisterende hændelseshus. Under KQL-databaser vælge +i feltet KQL-databasenavn skal du angive nycGreenTaxiog derefter vælge Opret.
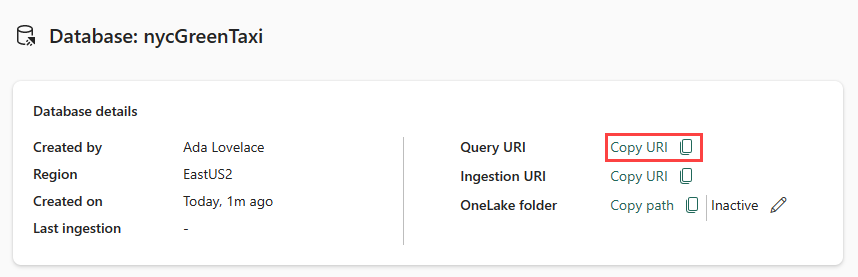
Kopiér forespørgsels-URI'en fra kortet med databaseoplysninger i databasedashboardet, og indsæt den et eller andet sted, f.eks. en notesblok, som skal bruges på et senere trin.
2 – Download NYC GreenTaxi-notesbogen
Vi har oprettet en eksempelnotesbog, der fører dig gennem alle de nødvendige trin til indlæsning af data i din database ved hjælp af Spark-connectoren.
Åbn lageret med Fabric-eksempler på GitHub for at downloade NYC GreenTaxi KQL-notesbogen.
Gem notesbogen lokalt på din enhed.
Bemærk
Notesbogen skal gemmes i filformatet
.ipynb.

3 – Importér notesbogen
Resten af denne arbejdsproces finder sted i Dataudvikler sektionen af produktet og bruger en Spark-notesbog til at indlæse og forespørge om data i din KQL-database.
Vælg Importér>notesbog>Fra denne computer>Upload vælg derefter den NYC GreenTaxi-notesbog, du downloadede i et tidligere trin.
Når importen er fuldført, skal du åbne notesbogen fra dit arbejdsområde.
4 – Hent data
Hvis du vil forespørge din database ved hjælp af Spark-connectoren, skal du give læse- og skriveadgang til NYC GreenTaxi-blobobjektbeholderen.
Vælg afspilningsknappen for at køre følgende celler, eller markér cellen, og tryk på Skift+ Enter. Gentag dette trin for hver kodecelle.
Bemærk
Vent på, at fuldførelsesmærket vises, før du kører den næste celle.
Kør følgende celle for at give adgang til NYC GreenTaxi-blobobjektbeholderen.
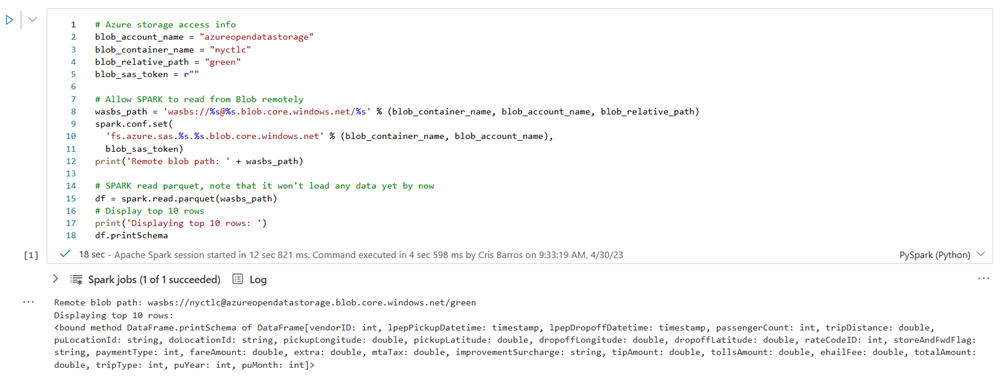
I KustoURI skal du indsætte den forespørgsels-URI , du kopierede tidligere , i stedet for pladsholderteksten.
Skift navnet på pladsholderdatabasen til nycGreenTaxi.
Skift navnet på pladsholdertabellen til GreenTaxiData.

Kør cellen.
Kør den næste celle for at skrive data til databasen. Det kan tage et par minutter, før dette trin er fuldført.




Der er nu indlæst data i databasen i en tabel med navnet GreenTaxiData.
5 – Kør notesbogen
Kør de resterende to celler sekventielt for at forespørge om data fra tabellen. Resultaterne viser de øverste 20 højeste og laveste taxapriser og afstande registreret efter år.

6 – Ryd op i ressourcer
Ryd op i de elementer, der er oprettet, ved at navigere til det arbejdsområde, hvor de blev oprettet.
Peg på den notesbog, du vil slette, i arbejdsområdet, og vælg menuen Flere [...] >Slet.
Vælg Slet. Du kan ikke gendanne din notesbog, når du har slettet den.
