Lakehouse-selvstudium: Forbered og transformér data i lakehouse
I dette selvstudium bruger du notesbøger med Spark-kørsel til at transformere og forberede rådata i dit lakehouse.
Forudsætninger
Hvis du ikke har et lakehouse, der indeholder data, skal du:
Forbered data
Fra de forrige trin i selvstudiet har vi rådata, der er hentet fra kilden til afsnittet Filer i lakehouse. Nu kan du transformere disse data og forberede dem til oprettelse af Delta-tabeller.
Download notesbøgerne fra mappen Lakehouse Tutorial Source Code .
I arbejdsområdet skal du vælge Importér>notesbog>Fra denne computer.
Vælg Importér notesbog i sektionen Ny øverst på landingssiden.
Vælg Upload i ruden Importstatus , der åbnes i højre side af skærmen.
Vælg alle de notesbøger, du har downloadet i første trin i denne sektion.
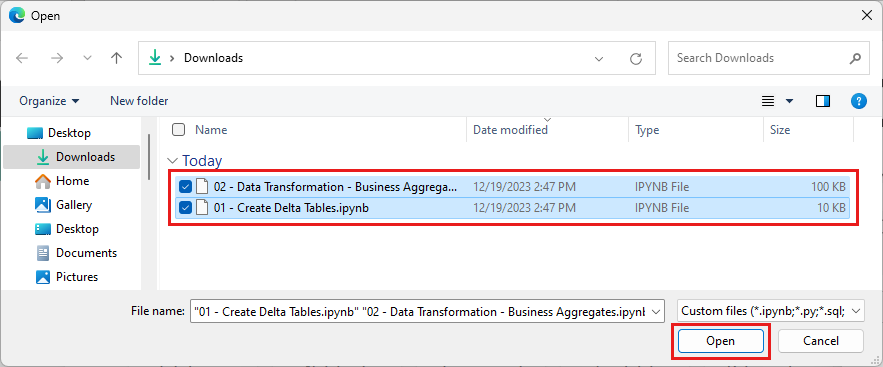
Vælg Åbn. En meddelelse, der angiver status for importen, vises i øverste højre hjørne af browservinduet.
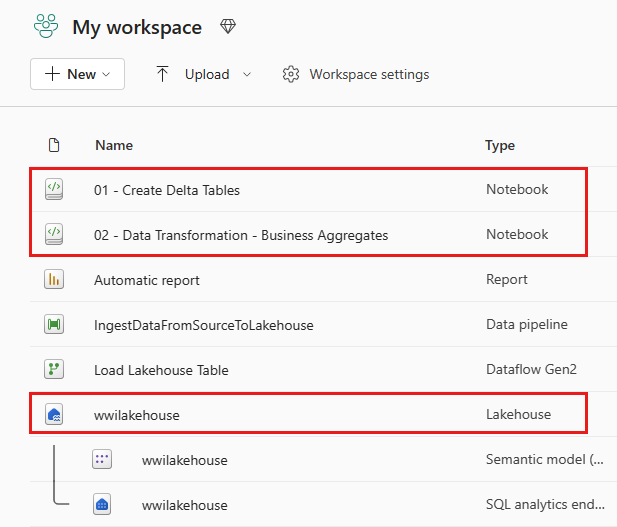
Når importen er fuldført, skal du gå til elementvisning af arbejdsområdet og se de nyligt importerede notesbøger. Vælg wwilakehouse lakehouse for at åbne den.
Når wwilakehouse lakehouse er åbnet, skal du vælge Åbn notesbog>Eksisterende notesbog i den øverste navigationsmenu.
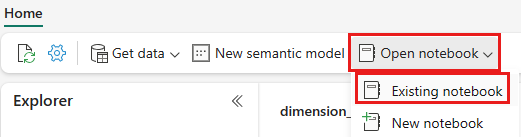
Vælg notesbogen 01 – Opret deltatabeller på listen over eksisterende notesbøger, og vælg Åbn.
I den åbne notesbog i lakehouse Explorer kan du se, at notesbogen allerede er knyttet til dit åbne lakehouse.
Bemærk
Fabric leverer V-order-funktionen til at skrive optimerede Delta lake-filer. V-order forbedrer ofte komprimering med tre til fire gange og op til 10 gange ydeevneacceleration over Delta Lake-filerne, der ikke er optimeret. Spark in Fabric optimerer dynamisk partitioner, mens der genereres filer med en standardstørrelse på 128 MB. Målfilens størrelse kan ændres pr. arbejdsbelastningskrav ved hjælp af konfigurationer.
Med den optimerede skrivefunktion reducerer Apache Spark-programmet antallet af filer, der skrives, og har til formål at øge den individuelle filstørrelse af de skrevne data.
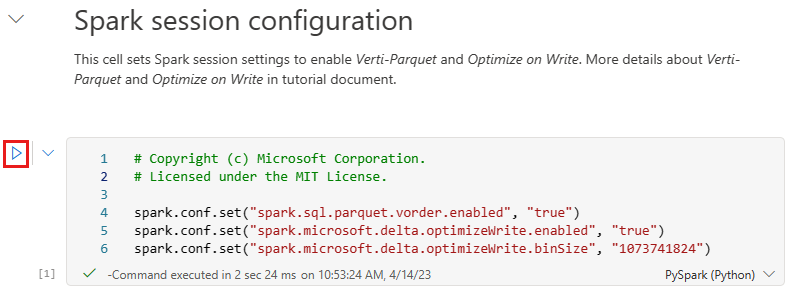
Før du skriver data som Delta Lake-tabeller i afsnittet Tabeller i lakehouse, skal du bruge to Fabric-funktioner (V-order og Optimize Write) til optimeret dataskrivning og til forbedret læseydeevne. Hvis du vil aktivere disse funktioner i din session, skal du angive disse konfigurationer i den første celle i notesbogen.
Hvis du vil starte notesbogen og udføre alle cellerne i rækkefølge, skal du vælge Kør alle på det øverste bånd (under Hjem). Eller hvis du kun vil udføre kode fra en bestemt celle, skal du vælge ikonet Kør , der vises til venstre for cellen, når der peges, eller trykke på SKIFT + ENTER på tastaturet, mens kontrolelementet er i cellen.
Når du kører en celle, behøvede du ikke at angive den underliggende Spark-pulje eller klyngedetaljer, fordi Fabric leverer dem via Live Pool. Alle Fabric-arbejdsområder leveres med en Spark-standardpulje, der kaldes Live Pool. Det betyder, at når du opretter notesbøger, behøver du ikke at bekymre dig om at angive nogen Spark-konfigurationer eller klyngedetaljer. Når du udfører den første notesbogkommando, kører den dynamiske gruppe om et par sekunder. Spark-sessionen er etableret, og den starter udførelsen af koden. Efterfølgende udførelse af kode er næsten øjeblikkelig i denne notesbog, mens Spark-sessionen er aktiv.
Derefter skal du læse rådata fra afsnittet Filer i lakehouse og tilføje flere kolonner til forskellige datodele som en del af transformationen. Endelig skal du bruge partition by Spark API til at partitionere dataene, før du skriver dem som Delta-tabelformat baseret på de nyoprettede datadelskolonner (År og Kvartal).
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/WideWorldImportersDW/parquet/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/" + table_name)Når faktatabellerne er indlæst, kan du gå videre til indlæsning af data for resten af dimensionerne. Følgende celle opretter en funktion til at læse rådata fra afsnittet Filer i lakehouse for hvert af de tabelnavne, der overføres som en parameter. Derefter oprettes der en liste over dimensionstabeller. Til sidst gennemgår den listen over tabeller og opretter en Delta-tabel for hvert tabelnavn, der læses fra inputparameteren. Bemærk, at scriptet dropper den kolonne, der er navngivet
Photoi dette eksempel, fordi kolonnen ikke bruges.from pyspark.sql.types import * def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/WideWorldImportersDW/parquet/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)Hvis du vil validere de oprettede tabeller, skal du højreklikke og vælge Opdater i wwilakehouse lakehouse. Tabellerne vises.
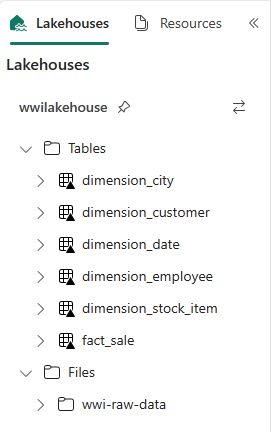
Gå til elementvisningen af arbejdsområdet igen, og vælg wwilakehouse lakehouse for at åbne det.
Åbn nu den anden notesbog. I lakehouse-visningen skal du vælge Åbn notesbog>Eksisterende notesbog på båndet.
På listen over eksisterende notesbøger skal du vælge 02 – Datatransformation – Forretningsnotesbog for at åbne den.
I den åbne notesbog i lakehouse Explorer kan du se, at notesbogen allerede er knyttet til dit åbne lakehouse.
En organisation kan have datateknikere, der arbejder med Scala/Python og andre datateknikere, der arbejder med SQL (Spark SQL eller T-SQL), og som alle arbejder på den samme kopi af dataene. Fabric gør det muligt for disse forskellige grupper, med forskellig erfaring og præferencer, at arbejde og samarbejde. De to forskellige tilgange transformerer og genererer forretningsaggregater. Du kan vælge den, der passer til dig, eller blande og matche disse tilgange baseret på dine præferencer uden at gå på kompromis med ydeevnen:
Tilgang nr. 1 – Brug PySpark til at joinforbinde og aggregere data til generering af virksomhedsaggregater. Denne fremgangsmåde er at foretrække frem for en person med en programmeringsbaggrund (Python eller PySpark).
Tilgang nr. 2 – Brug Spark SQL til at joinforbinde og aggregere data til generering af virksomhedsaggregater. Denne fremgangsmåde er at foretrække frem for en person med SQL-baggrund, der skifter til Spark.
Tilgang nr. 1 (sale_by_date_city) – Brug PySpark til at joinforbinde og aggregere data til generering af forretningsaggregater. Med følgende kode opretter du tre forskellige Spark-datarammer, der hver især refererer til en eksisterende Delta-tabel. Derefter joinforbinder du disse tabeller ved hjælp af datarammen, grupperer efter for at generere sammenlægning, omdøbe nogle af kolonnerne og til sidst skrive den som en Delta-tabel i afsnittet Tabeller i lakehouse for at bevare dataene.
I denne celle opretter du tre forskellige Spark-datarammer, der hver især refererer til en eksisterende Delta-tabel.
df_fact_sale = spark.read.table("wwilakehouse.fact_sale") df_dimension_date = spark.read.table("wwilakehouse.dimension_date") df_dimension_city = spark.read.table("wwilakehouse.dimension_city")Føj følgende kode til den samme celle for at joinforbinde disse tabeller ved hjælp af de datarammer, der blev oprettet tidligere. Gruppér efter for at generere sammenlægning, omdøb et par af kolonnerne, og skriv det til sidst som en Delta-tabel i afsnittet Tabeller i lakehouse.
sale_by_date_city = df_fact_sale.alias("sale") \ .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") \ .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") \ .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory")\ .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax")\ .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount")\ .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax")\ .withColumnRenamed("sum(Profit)", "SumOfProfit")\ .orderBy("date.Date", "city.StateProvince", "city.City") sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_city")Tilgang nr. 2 (sale_by_date_employee) – Brug Spark SQL til at joinforbinde og aggregere data til generering af virksomhedsaggregater. Med følgende kode opretter du en midlertidig Spark-visning ved at sammenføje tre tabeller, gruppere efter for at generere sammenlægning og omdøbe nogle af kolonnerne. Endelig kan du læse fra den midlertidige Spark-visning og til sidst skrive den som en Delta-tabel i afsnittet Tabeller i lakehouse for at bevare dataene.
I denne celle opretter du en midlertidig Spark-visning ved at sammenføje tre tabeller, gruppere efter for at generere sammenlægning og omdøbe nogle få af kolonnerne.
%%sql CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year ,DE.PreferredName, DE.Employee ,SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax ,SUM(FS.TaxAmount) SumOfTaxAmount ,SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax ,SUM(Profit) SumOfProfit FROM wwilakehouse.fact_sale FS INNER JOIN wwilakehouse.dimension_date DD ON FS.InvoiceDateKey = DD.Date INNER JOIN wwilakehouse.dimension_Employee DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASCI denne celle læser du fra den midlertidige Spark-visning, der blev oprettet i den forrige celle, og til sidst skriver du den som en Delta-tabel i afsnittet Tabeller i lakehouse.
sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_employee")Hvis du vil validere de oprettede tabeller, skal du højreklikke og vælge Opdater i wwilakehouse lakehouse. De aggregerede tabeller vises.
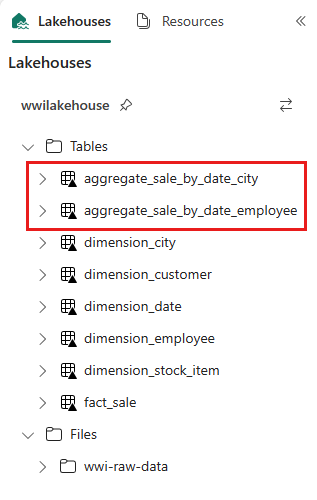
De to tilgange giver et lignende resultat. Hvis du vil minimere behovet for at lære en ny teknologi eller gå på kompromis med ydeevnen, skal du vælge den fremgangsmåde, der passer bedst til din baggrund og dine præferencer.
Du vil måske bemærke, at du skriver data som Delta Lake-filer. Den automatiske tabelsøgnings- og registreringsfunktion i Fabric opfanger og registrerer dem i metalageret. Du behøver ikke eksplicit at kalde CREATE TABLE sætninger for at oprette tabeller, der skal bruges sammen med SQL.