Planlæg og kør en Apache Spark-jobdefinition
Få mere at vide om, hvordan du kører en Microsoft Fabric Apache Spark-jobdefinition og finder jobdefinitionens status og detaljer.
Forudsætninger
Før du kommer i gang, skal du:
- Opret en Microsoft Fabric-lejerkonto med et aktivt abonnement. Opret en konto gratis.
- Forstå definitionen af Spark-jobbet: se Hvad er en Apache Spark-jobdefinition?.
- Opret en Spark-jobdefinition: Se Sådan opretter du en Apache Spark-jobdefinition i Fabric.
Sådan kører du en Spark-jobdefinition
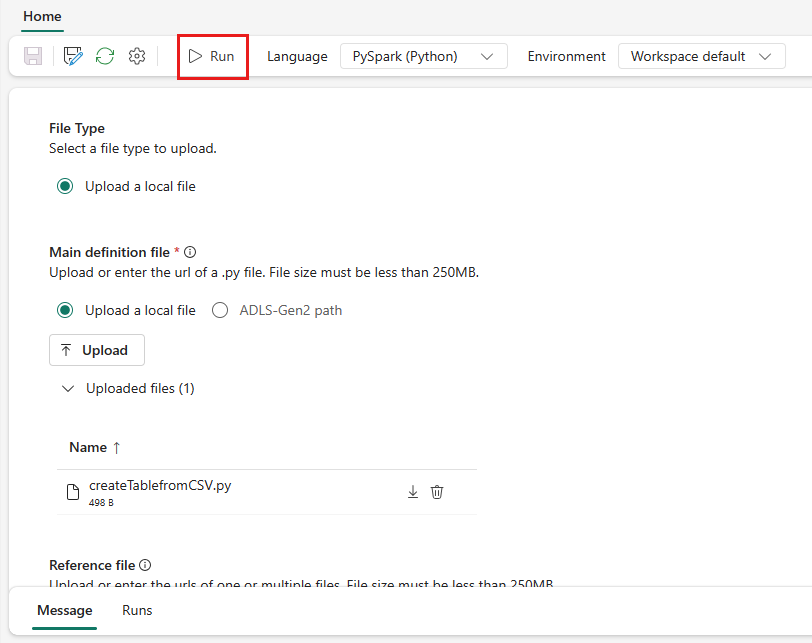
Du kan køre en Spark-jobdefinition på to måder:
Kør definitionen af et Spark-job manuelt ved at vælge Kør fra definitionen af Spark-job på joblisten.
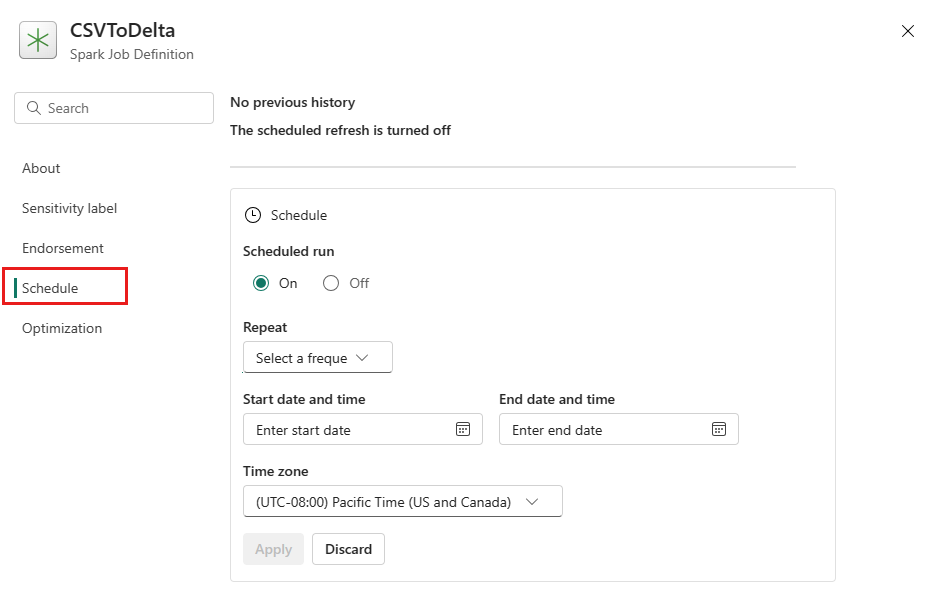
Planlæg en Spark-jobdefinition ved at konfigurere en plan under fanen Indstillinger. Vælg Indstillinger på værktøjslinjen, og vælg derefter Planlæg.
Vigtigt
Hvis du vil køre, skal en Spark-jobdefinition have en hoveddefinitionsfil og en standard-lakehouse-kontekst.
Tip
I forbindelse med manuel kørsel bruges kontoen for den bruger, der i øjeblikket er logget på, til at sende jobbet. For en kørsel, der udløses af en tidsplan, bruges kontoen for den bruger, der oprettede planplanen, til at sende jobbet.
Tre til fem sekunder efter, at du har indsendt kørslen, vises der en ny række under fanen Kørsler . Rækken viser detaljer om den nye kørsel. Kolonnen Status viser jobbets næsten realtidsstatus, og kolonnen Kørsel viser , om jobbet er manuelt eller planlagt.
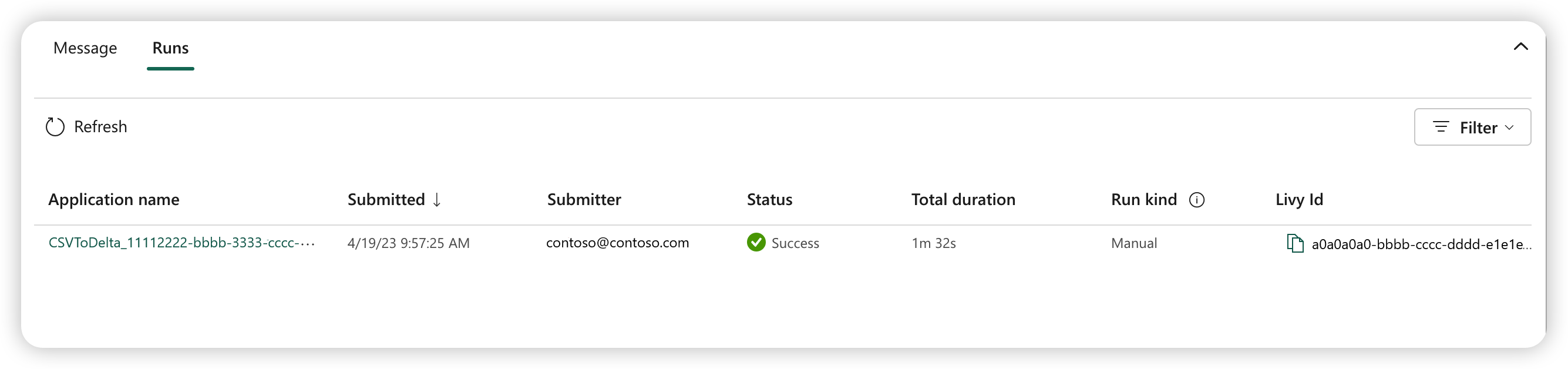
Du kan få flere oplysninger om, hvordan du overvåger et job, under Overvåg definitionen af dit Apache Spark-job.
Sådan annullerer du et kørende job
Når jobbet er sendt, kan du annullere jobbet ved at vælge Annuller aktiv kørsel fra definitionen af Spark-jobelementet på joblisten.
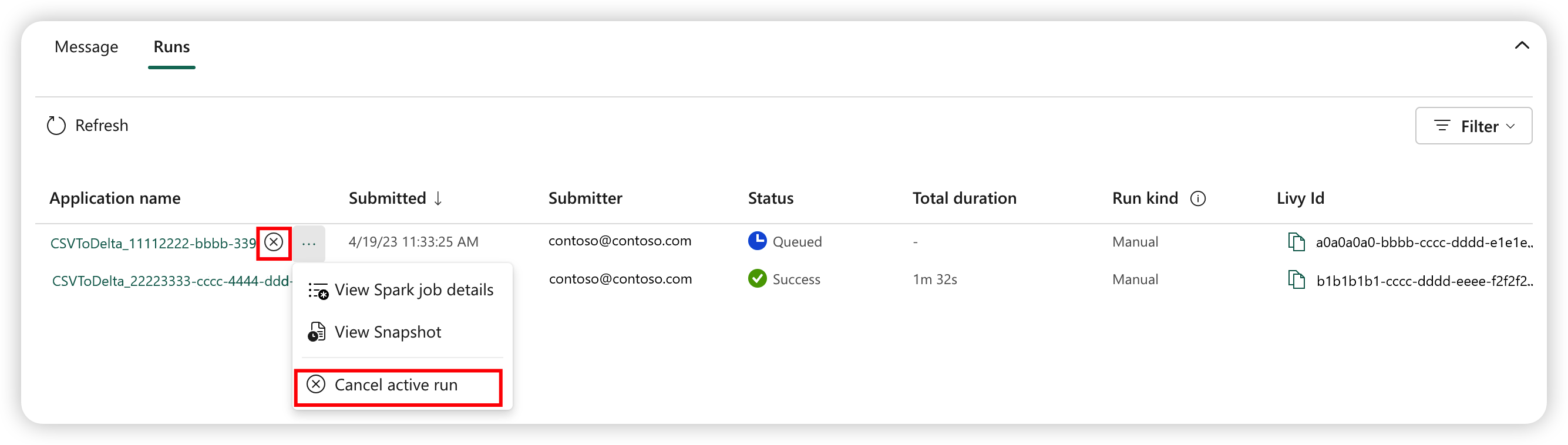
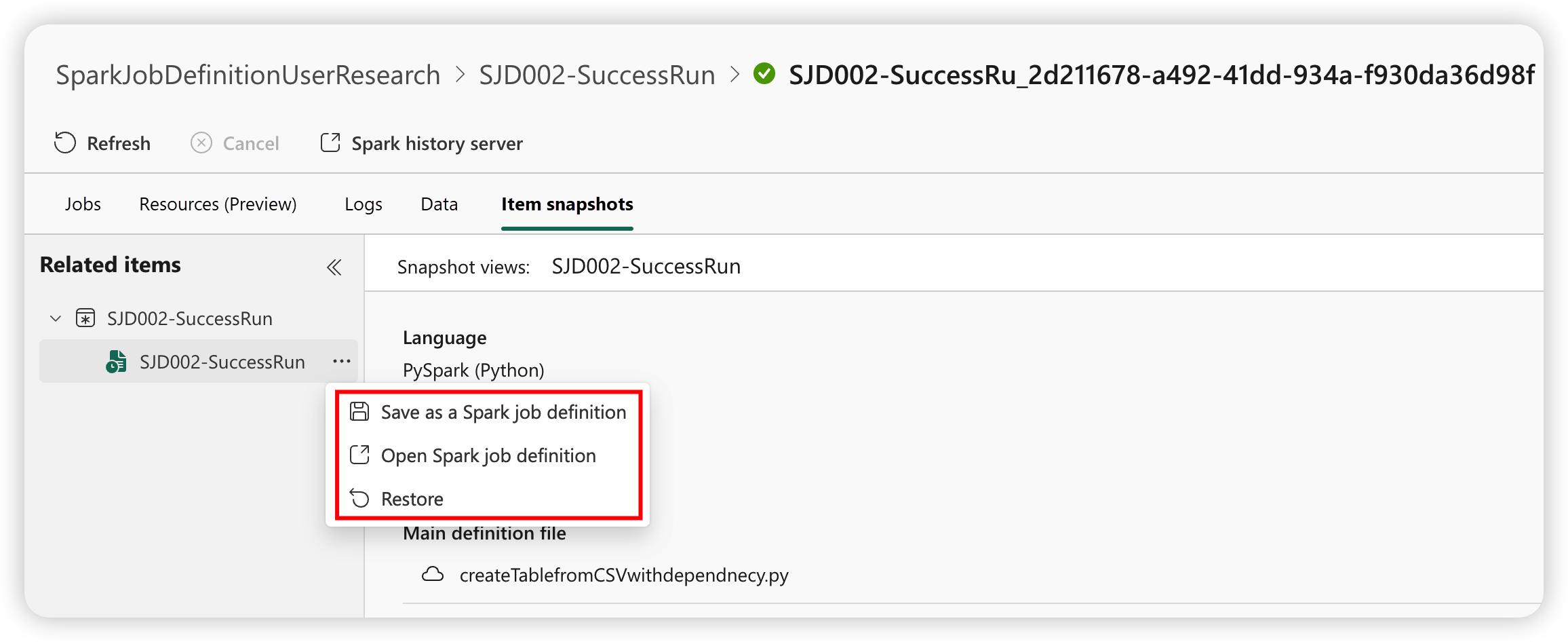
Spark-jobdefinitionssnapshot
Definitionen af Spark-jobbet gemmer den seneste tilstand. Hvis du vil have vist snapshottet af historikkørslen, skal du vælge Vis snapshot fra definitionen af Spark-jobelementet på joblisten. Snapshottet viser status for jobdefinitionen, når jobbet sendes, herunder den primære definitionsfil, referencefilen, kommandolinjeargumenterne, det lakehouse, der refereres til, og egenskaberne Spark.
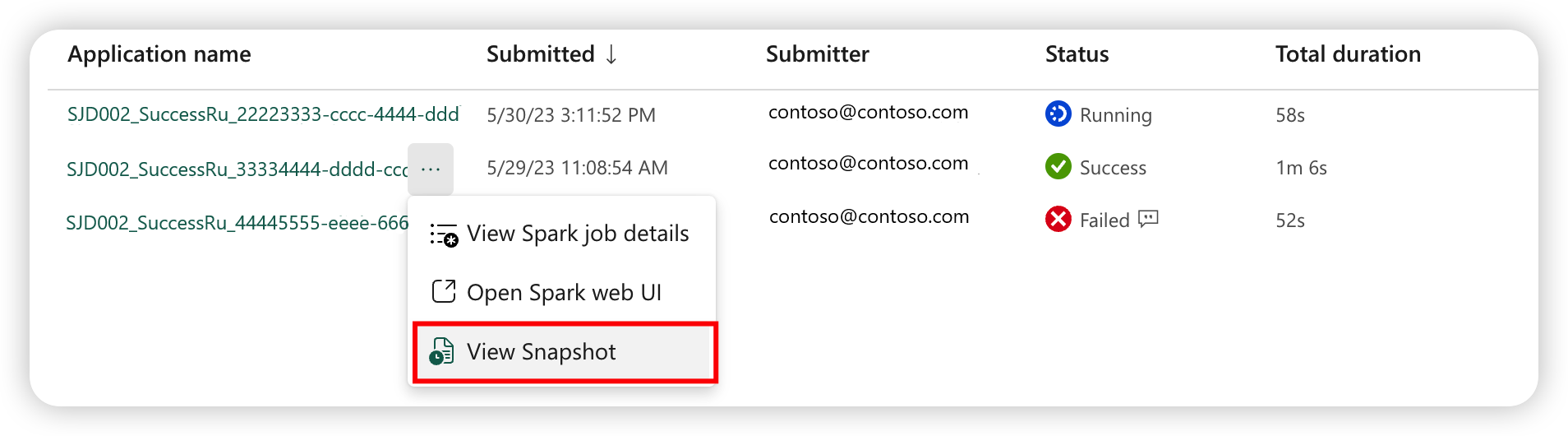
Fra et snapshot kan du foretage tre handlinger:
- Gem som en Spark-jobdefinition: Gem snapshottet som en ny Spark-jobdefinition.
- Åbn Definitionen af Spark-job: Åbn definitionen af det aktuelle Spark-job.
- Gendan: Gendan jobdefinitionen med snapshottet. Jobdefinitionen gendannes til tilstanden, da jobbet blev sendt.