Administrer Apache Spark-biblioteker i Microsoft Fabric
Et bibliotek er en samling af foruddefineret kode, som udviklere kan importere for at levere funktionalitet. Ved hjælp af biblioteker kan du spare tid og kræfter ved ikke at skulle skrive kode fra bunden for at udføre almindelige opgaver. Importér i stedet biblioteket, og brug dets funktioner og klasser til at opnå den ønskede funktionalitet. Microsoft Fabric indeholder flere mekanismer, der kan hjælpe dig med at administrere og bruge biblioteker.
- Indbyggede biblioteker: Hver Fabric Spark-kørsel giver et omfattende sæt populære forudinstallerede biblioteker. Du kan finde den komplette indbyggede biblioteksliste i Fabric Spark Runtime.
- Offentlige biblioteker: Offentlige biblioteker hentes fra lagre som PyPI og Conda, som understøttes i øjeblikket.
- Brugerdefinerede biblioteker: Brugerdefinerede biblioteker refererer til kode, som du eller din organisation bygger. Fabric understøtter dem i formaterne .whl, .jar og .tar.gz . Fabric understøtter kun .tar.gz for R-sproget. I forbindelse med brugerdefinerede Python-biblioteker skal du bruge .whl-formatet .
Oversigt over bedste praksis for administration af biblioteker
I følgende scenarier beskrives de bedste fremgangsmåder, når du bruger biblioteker i Microsoft Fabric.
Scenarie 1: Administratorer angiver standardbiblioteker for arbejdsområdet
Hvis du vil angive standardbiblioteker, skal du være administrator af arbejdsområdet. Som administrator kan du udføre disse opgaver:
- Opret et nyt miljø
- Installér de påkrævede biblioteker i miljøet
- Vedhæft dette miljø som standard for arbejdsområdet
Når dine notesbøger og Spark-jobdefinitioner er knyttet til indstillingerne for arbejdsområdet, starter de sessioner med de biblioteker, der er installeret i arbejdsområdets standardmiljø.
Scenarie 2: Fasthold biblioteksspecifikationer for et eller flere kodeelementer
Hvis du har fælles biblioteker for forskellige kodeelementer og ikke kræver hyppige opdateringer, kan du installere bibliotekerne i et miljø og vedhæfte dem til kodeelementerne .
Det vil tage noget tid at få bibliotekerne i miljøer til at træde i kraft, når du publicerer. Det tager normalt 5-15 minutter, afhængigt af bibliotekernes kompleksitet. Under denne proces hjælper systemet med at løse de potentielle konflikter og downloade påkrævede afhængigheder.
En af fordelene ved denne fremgangsmåde er, at de korrekt installerede biblioteker er garanteret at være tilgængelige, når Spark-sessionen startes med et tilknyttet miljø. Det sparer kræfter på at vedligeholde almindelige biblioteker til dine projekter.
Det anbefales på det kraftigste til pipelinescenarier med dens stabilitet.
Scenarie 3: Indbygget installation i interaktiv kørsel
Hvis du bruger notesbøgerne til at skrive kode interaktivt, er det bedste praksis at bruge indbygget installation til at tilføje ekstra nye PyPI/conda-biblioteker eller validere dine brugerdefinerede biblioteker til engangsbrug. Indbyggede kommandoer i Fabric giver dig mulighed for at have biblioteket effektivt i den aktuelle Spark-session for notesbøger. Det gør det muligt at installere hurtigt, men det installerede bibliotek bevares ikke på tværs af forskellige sessioner.
Da %pip install der fra tid til anden genereres forskellige afhængighedstræer, hvilket kan føre til bibliotekskonflikter, er indbyggede kommandoer som standard deaktiveret i pipelinen, og det anbefales ikke, at de bruges i dine pipelines.
Oversigt over understøttede bibliotekstyper
| Bibliotekstype | Administration af miljøbiblioteker | Indbygget installation |
|---|---|---|
| Python Public (PyPI & Conda) | Understøttet | Understøttet |
| Brugerdefineret Python (.whl) | Understøttet | Understøttet |
| R Offentlig (CRAN) | Ikke understøttet | Understøttet |
| Brugerdefineret R (.tar.gz) | Understøttes som brugerdefineret bibliotek | Understøttet |
| Krukke | Understøttes som brugerdefineret bibliotek | Understøttet |
Indbygget installation
Indbyggede kommandoer understøtter administration af biblioteker i hver notesbogsession.
Indbygget Python-installation
Systemet genstarter Python-fortolkeren for at anvende ændringen af biblioteker. Alle variabler, der er defineret, før du kører kommandocellen, går tabt. Vi anbefaler på det kraftigste, at du placerer alle kommandoerne til tilføjelse, sletning eller opdatering af Python-pakker i starten af din notesbog.
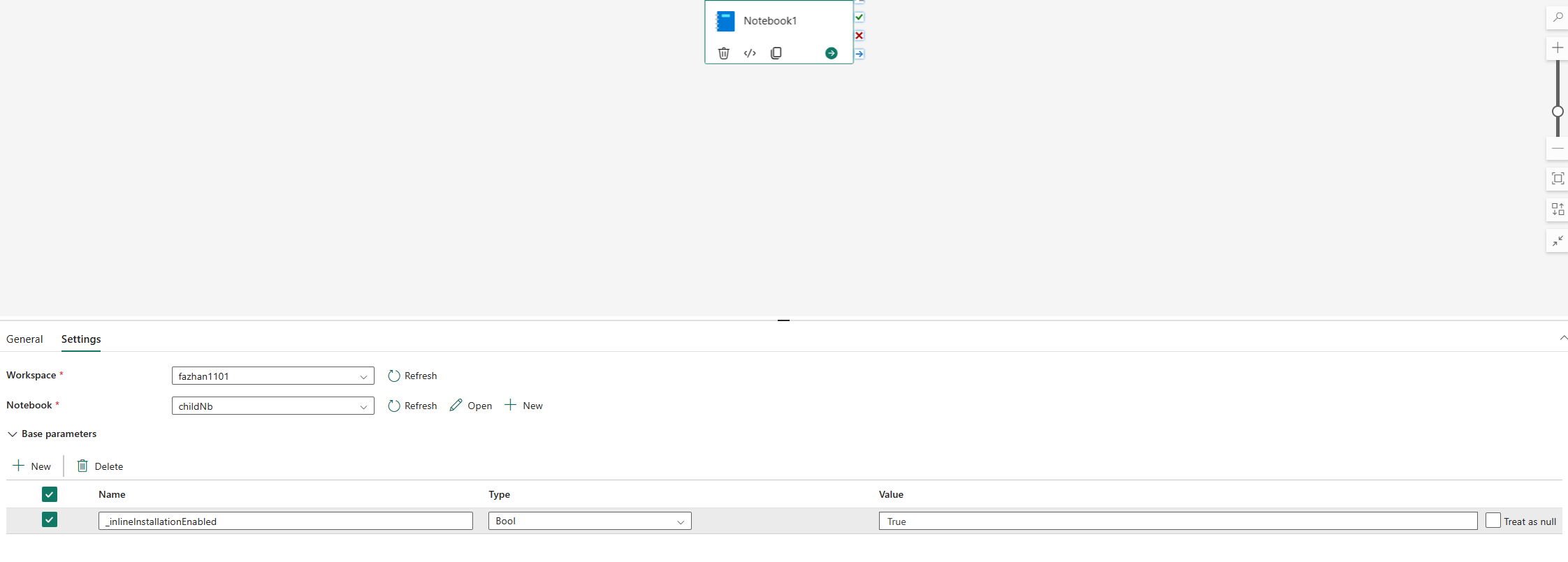
De indbyggede kommandoer til administration af Python-biblioteker er som standard deaktiveret i notesbogpipeline. Hvis du vil aktivere %pip install for pipeline, skal du tilføje "_inlineInstallationEnabled", da bool-parameteren er lig med Sand i parametrene for notesbogaktiviteten.
Bemærk
kan %pip install medføre inkonsekvente resultater fra tid til anden. Det anbefales at installere bibliotek i et miljø og bruge det i pipelinen.
I kørsler af notesbogreferencer understøttes indbyggede kommandoer til administration af Python-biblioteker ikke. For at sikre korrekt udførelse anbefales det at fjerne disse indbyggede kommandoer fra den notesbog, der refereres til.
Vi anbefaler %pip i stedet for !pip.
!pip er en indbygget shellkommando i IPython, som har følgende begrænsninger:
-
!pipinstallerer kun en pakke på drivernoden, ikke eksekveringsnoder. - Pakker, der installeres via
!pip, påvirker ikke konflikter med indbyggede pakker, eller om pakker allerede er importeret i en notesbog.
Håndterer dog %pip disse scenarier. Biblioteker, der er installeret via %pip , er tilgængelige på både driver- og eksekveringsnoder og er stadig effektive, selvom biblioteket allerede er importeret.
Tip
Kommandoen %conda install tager normalt længere tid end kommandoen %pip install til at installere nye Python-biblioteker. Den kontrollerer de fulde afhængigheder og løser konflikter.
Det kan være en god idé at bruge %conda install til mere pålidelighed og stabilitet. Du kan bruge %pip install , hvis du er sikker på, at det bibliotek, du vil installere, ikke er i konflikt med de forudinstallerede biblioteker i kørselsmiljøet.
Du kan se alle tilgængelige indbyggede Python-kommandoer og præciseringer under %pip-kommandoer og %conda-kommandoer.
Administrer offentlige Python-biblioteker via indbygget installation
I dette eksempel kan du se, hvordan du bruger indbyggede kommandoer til at administrere biblioteker. Lad os antage, at du vil bruge Altair, et effektivt visualiseringsbibliotek til Python, til en engangsudforskning af data. Lad os antage, at biblioteket ikke er installeret i dit arbejdsområde. I følgende eksempel bruges conda-kommandoer til at illustrere trinnene.
Du kan bruge indbyggede kommandoer til at aktivere altair i notesbogsessionen, uden at det påvirker andre sessioner i notesbogen eller andre elementer.
Kør følgende kommandoer i en notesbogkodecelle. Den første kommando installerer altair-biblioteket . Du skal også installere vega_datasets, som indeholder en semantisk model, som du kan bruge til at visualisere.
%conda install altair # install latest version through conda command %conda install vega_datasets # install latest version through conda commandOutputtet af cellen angiver resultatet af installationen.
Importér pakken og den semantiske model ved at køre følgende kode i en anden notesbogcelle.
import altair as alt from vega_datasets import dataNu kan du lege med altair-biblioteket, der er beregnet til sessionen.
# load a simple dataset as a pandas DataFrame cars = data.cars() alt.Chart(cars).mark_point().encode( x='Horsepower', y='Miles_per_Gallon', color='Origin', ).interactive()
Administrer brugerdefinerede Python-biblioteker via indbygget installation
Du kan uploade dine brugerdefinerede Python-biblioteker til ressourcemappen i notesbogen eller det tilknyttede miljø. Ressourcemapperne er det indbyggede filsystem, der leveres af hver notesbog og hvert miljø. Se Notesbogressourcer for at få flere oplysninger. Når du har uploadet, kan du trække og slippe det brugerdefinerede bibliotek til en kodecelle. Den indbyggede kommando til installation af biblioteket genereres automatisk. Eller du kan bruge følgende kommando til at installere.
# install the .whl through pip command from the notebook built-in folder
%pip install "builtin/wheel_file_name.whl"
Indbygget R-installation
Fabric understøtter kommandoerne , install.packages()og remove.packages() for devtools::at administrere R-biblioteker. Du kan se alle tilgængelige indbyggede R-kommandoer og præciseringer under install.packages command and remove.package command.
Administrer offentlige R-biblioteker via indbygget installation
Følg dette eksempel for at gennemgå trinnene til installation af et offentligt R-bibliotek.
Sådan installerer du et R-feedbibliotek:
Skift arbejdssproget til SparkR (R) på båndet i notesbogen.
Installér Cæsar-biblioteket ved at køre følgende kommando i en notesbogcelle.
install.packages("caesar")Nu kan du lege lidt med det sessionsområdede Cæsarbibliotek med et Spark-job.
library(SparkR) sparkR.session() hello <- function(x) { library(caesar) caesar(x) } spark.lapply(c("hello world", "good morning", "good evening"), hello)
Administrer Jar-biblioteker via indbygget installation
De .jar filer understøttes i notesbogsessioner med følgende kommando.
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<Lakehouse prefix>>.dfs.fabric.microsoft.com/<<path to JAR file>>/<<JAR file name>>.jar",
}
}
Kodecellen bruger Lakehouses lager som eksempel. I notesbogoversigten kan du kopiere den fulde fil-ABFS-sti og erstatte den i koden.
