Brug Livy-API'en til at sende og udføre Livy-batchjob
Bemærk
Livy API til Fabric Dataudvikler ing er en prøveversion.
Gælder for:✅ Dataudvikler ing og datavidenskab i Microsoft Fabric
Indsend Spark-batchjob ved hjælp af Livy-API'en til Fabric Dataudvikler ing.
Forudsætninger
Fabric Premium - eller prøveversionskapacitet med lakehouse.
En ekstern klient, f.eks . Visual Studio Code med Jupyter Notebooks, PySpark og Microsoft Authentication Library (MSAL) til Python.
Der kræves et Microsoft Entra-apptoken for at få adgang til Fabric Rest-API'en. Registrer et program med Microsoft-identitetsplatform.
Nogle data i dit lakehouse bruger i dette eksempel NYC Taxi & Limousine Commission green_tripdata_2022_08 en parketfil, der er indlæst i lakehouse.
Livy-API'en definerer et samlet slutpunkt for handlinger. Erstat pladsholderne {Entra_TenantID}, {Entra_ClientID}, {Fabric_WorkspaceID} og {Fabric_LakehouseID} med de relevante værdier, når du følger eksemplerne i denne artikel.
Konfigurer Visual Studio Code for dit Livy API-batch
Vælg Lakehouse-indstillinger i Fabric Lakehouse.

Gå til sektionen Livy-slutpunkt .
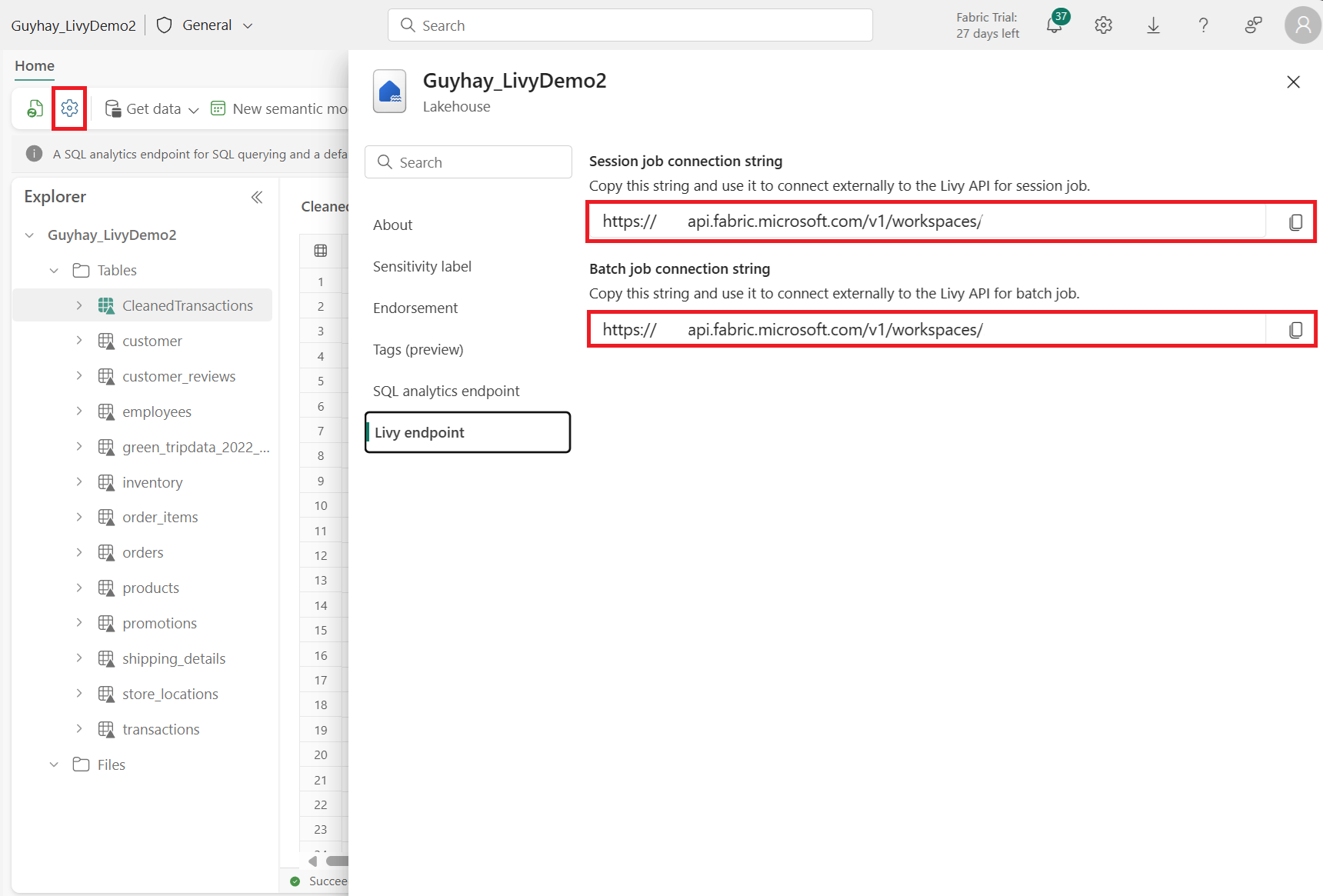
Kopiér batchjobbet forbindelsesstreng (det andet røde felt på billedet) til din kode.
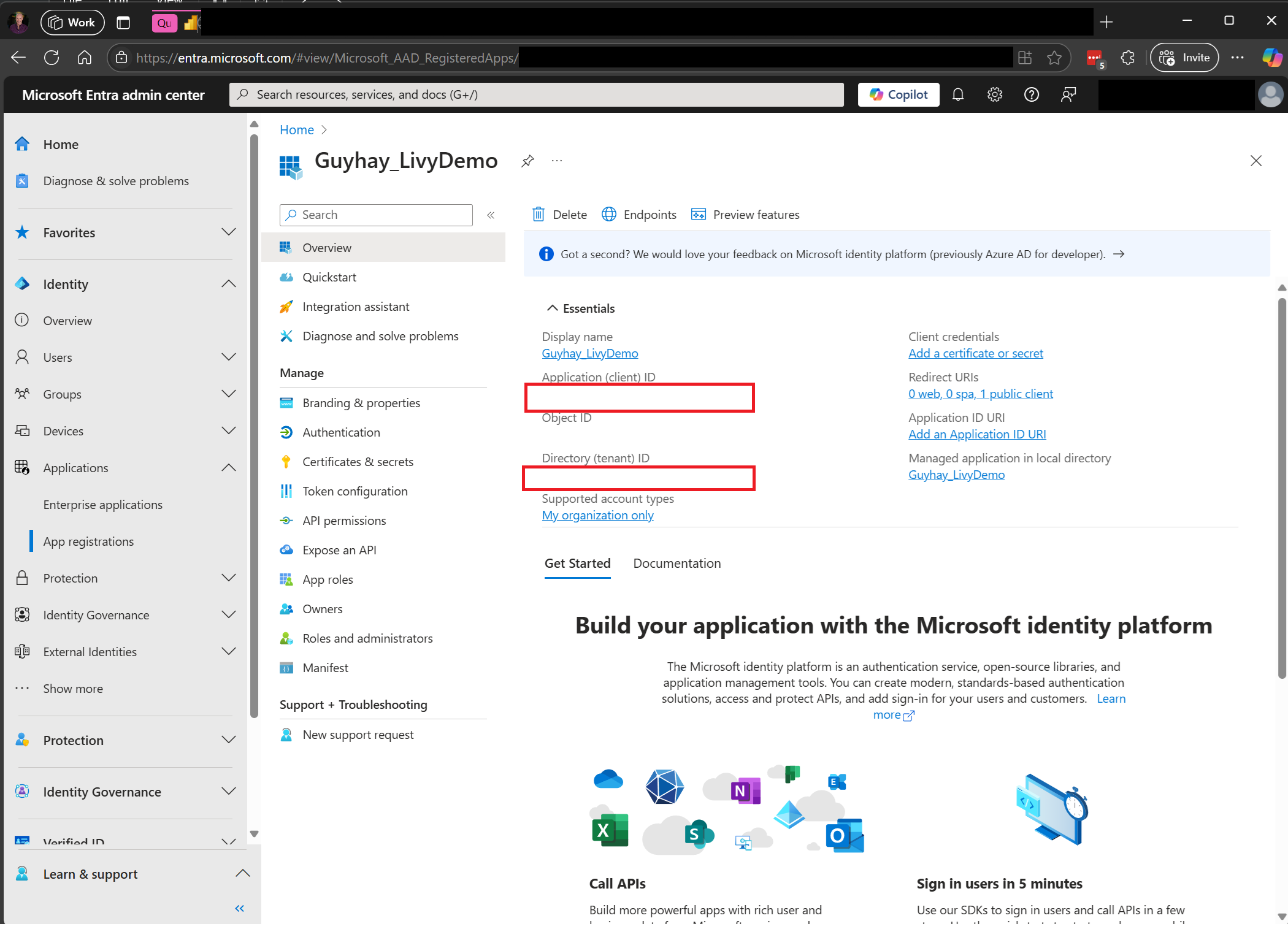
Gå til Microsoft Entra Administration , og kopiér både program-id'et (klient)-id'et og mappe-id'et (lejer) til din kode.



Opret en Spark-nyttedata, og upload den til lakehouse
Opret en
.ipynbnotesbog i Visual Studio Code, og indsæt følgende kodeimport sys import os from pyspark.sql import SparkSession from pyspark.conf import SparkConf from pyspark.sql.functions import col if __name__ == "__main__": #Spark session builder spark_session = (SparkSession .builder .appName("livybatchdemo") .getOrCreate()) spark_context = spark_session.sparkContext spark_context.setLogLevel("DEBUG") targetLakehouse = spark_context.getConf().get("spark.targetLakehouse") if targetLakehouse is not None: print("targetLakehouse: " + str(targetLakehouse)) else: print("targetLakehouse is None") df_valid_totalPrice = spark_session.sql("SELECT * FROM <YourLakeHouseDataTableName>.transactions where TotalPrice > 0") df_valid_totalPrice_plus_year = df_valid_totalPrice.withColumn("transaction_year", col("TransactionDate").substr(1, 4)) deltaTablePath = "abfss:<YourABFSSpath>"+str(targetLakehouse)+".Lakehouse/Tables/CleanedTransactions" df_valid_totalPrice_plus_year.write.mode('overwrite').format('delta').save(deltaTablePath)Gem Python-filen lokalt. Denne Python-kodedata indeholder to Spark-sætninger, der fungerer på data i et Lakehouse og skal uploades til dit Lakehouse. Du skal bruge ABFS-stien for nyttedataene for at referere til den i dit Livy API-batchjob i Visual Studio Code og navnet på tabellen Lakehouse i Select SQL-sætningen.
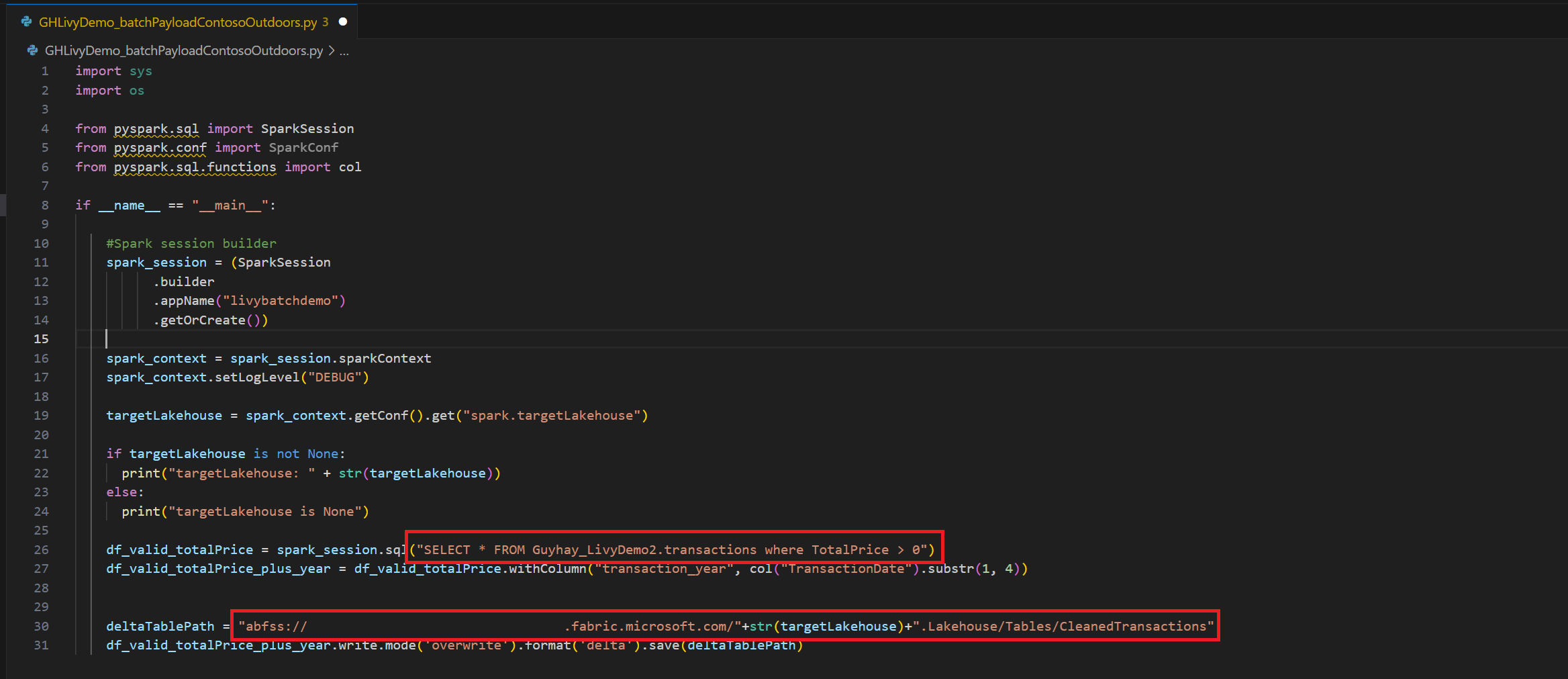
Upload Python-nyttedataene til filafsnittet i lakehouse. >Hent filer til overførsel af > data > klik i feltet Filer/input.
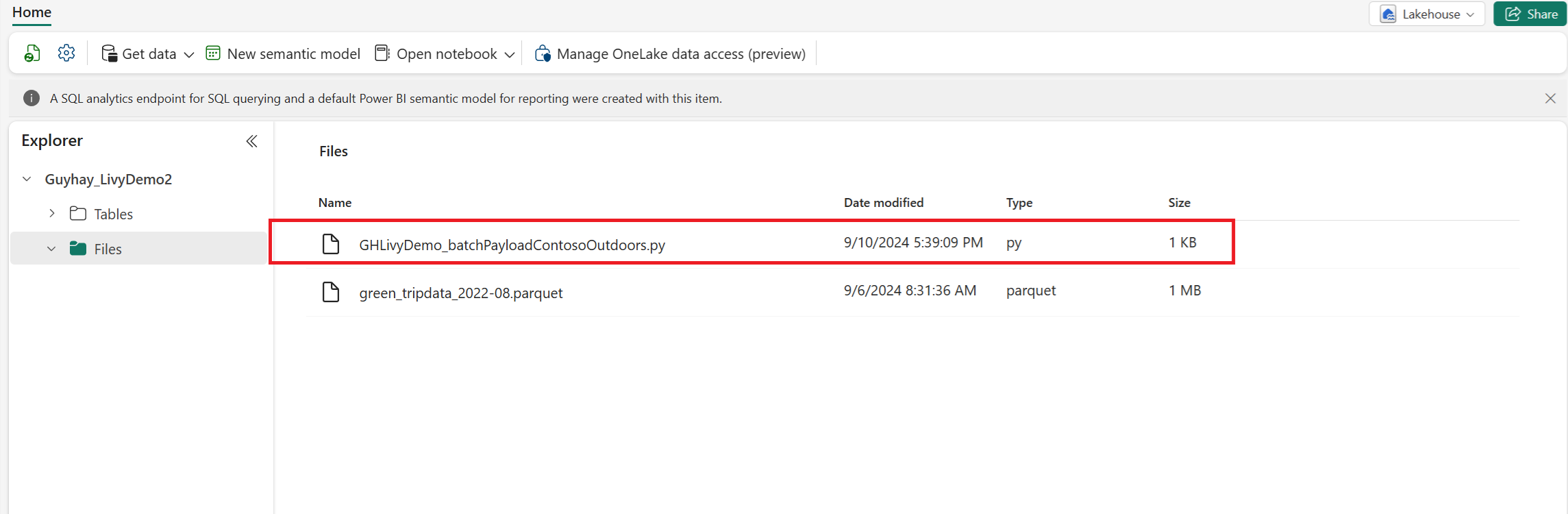
Når filen er i afsnittet Filer i Lakehouse, skal du klikke på de tre prikker til højre for dit payloadfilnavn og vælge Egenskaber.
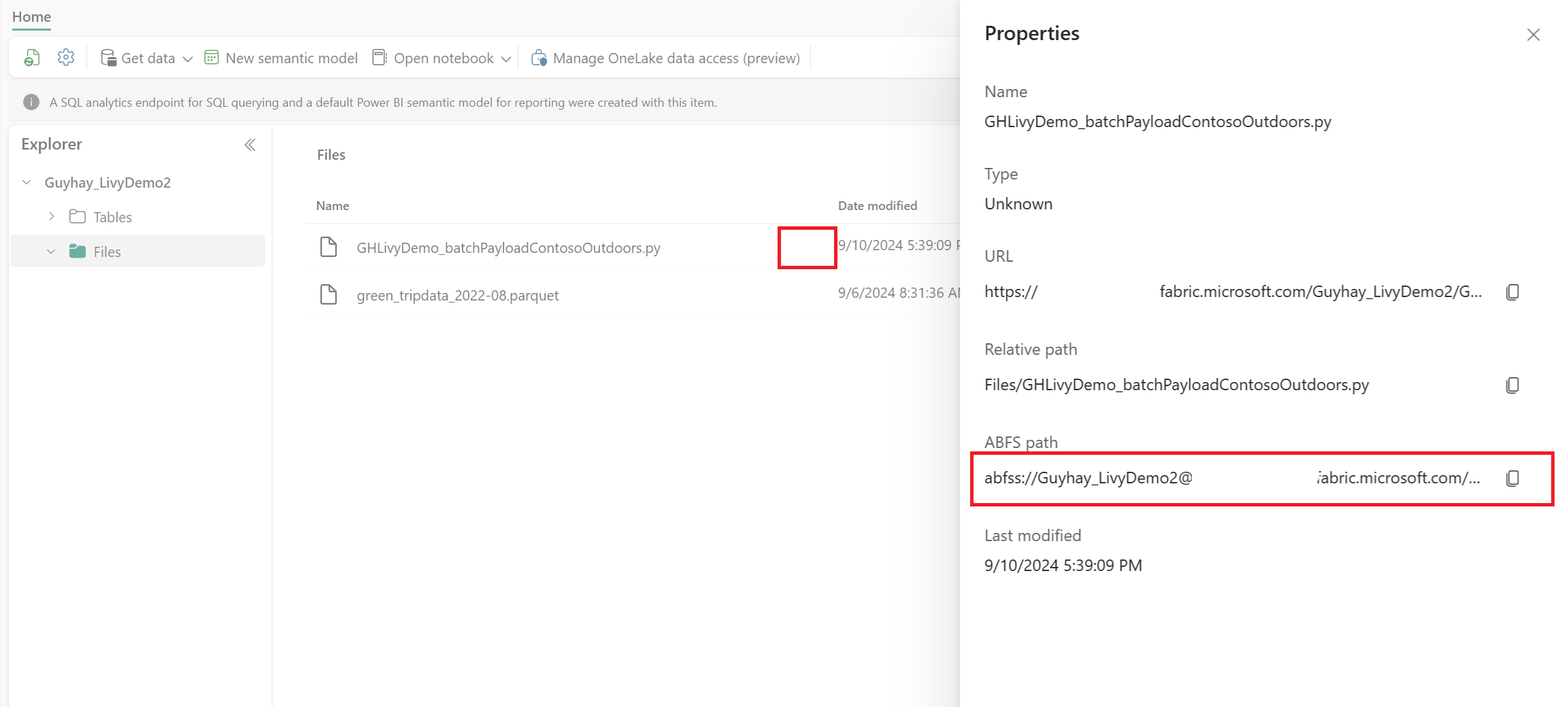
Kopiér denne ABFS-sti til din notesbogcelle i trin 1.



Opret en Livy API Spark-batchsession
Opret en
.ipynbnotesbog i Visual Studio Code, og indsæt følgende kode.from msal import PublicClientApplication import requests import time tenant_id = "<Entra_TenantID>" client_id = "<Entra_ClientID>" workspace_id = "<Fabric_WorkspaceID>" lakehouse_id = "<Fabric_LakehouseID>" app = PublicClientApplication( client_id, authority="https://login.microsoftonline.com/43a26159-4e8e-442a-9f9c-cb7a13481d48" ) result = None # If no cached tokens or user interaction needed, acquire tokens interactively if not result: result = app.acquire_token_interactive(scopes=["https://api.fabric.microsoft.com/Lakehouse.Execute.All", "https://api.fabric.microsoft.com/Lakehouse.Read.All", "https://api.fabric.microsoft.com/Item.ReadWrite.All", "https://api.fabric.microsoft.com/Workspace.ReadWrite.All", "https://api.fabric.microsoft.com/Code.AccessStorage.All", "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All", "https://api.fabric.microsoft.com/Code.AccessFabric.All"]) # Print the access token (you can use it to call APIs) if "access_token" in result: print(f"Access token: {result['access_token']}") else: print("Authentication failed or no access token obtained.") if "access_token" in result: access_token = result['access_token'] api_base_url_mist='https://api.fabric.microsoft.com/v1' livy_base_url = api_base_url_mist + "/workspaces/"+workspace_id+"/lakehouses/"+lakehouse_id +"/livyApi/versions/2023-12-01/batches" headers = {"Authorization": "Bearer " + access_token}Kør notesbogcellen. Der vises et pop op-vindue i browseren, så du kan vælge den identitet, du vil logge på med.

Når du har valgt den identitet, du vil logge på med, bliver du også bedt om at godkende API-tilladelserne til Microsoft Entra-appregistrering.
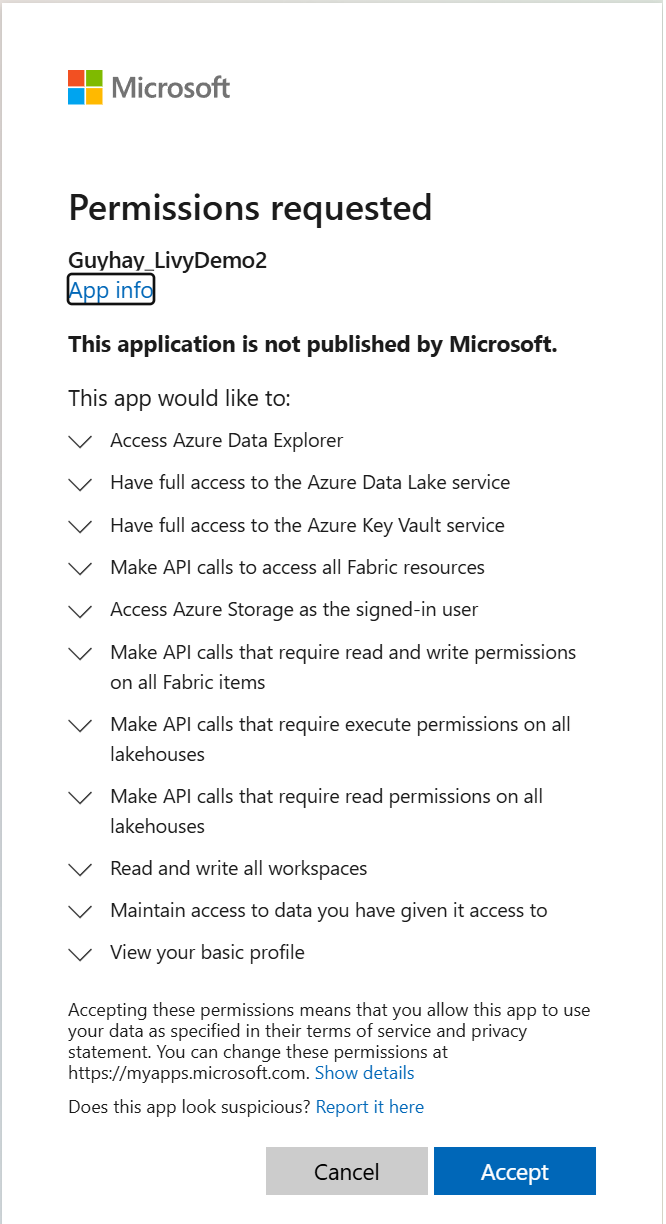
Luk browservinduet, når godkendelsen er fuldført.

I Visual Studio Code kan du se, at Microsoft Entra-tokenet returneres.
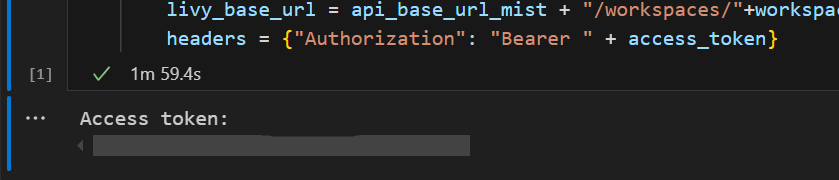
Tilføj en anden notesbogcelle, og indsæt denne kode.
# call get batch API get_livy_get_batch = livy_base_url get_batch_response = requests.get(get_livy_get_batch, headers=headers) if get_batch_response.status_code == 200: print("API call successful") print(get_batch_response.json()) else: print(f"API call failed with status code: {get_batch_response.status_code}") print(get_batch_response.text)Kør notesbogcellen. Du kan se to linjer udskrevet, når livy-batchjobbet oprettes.
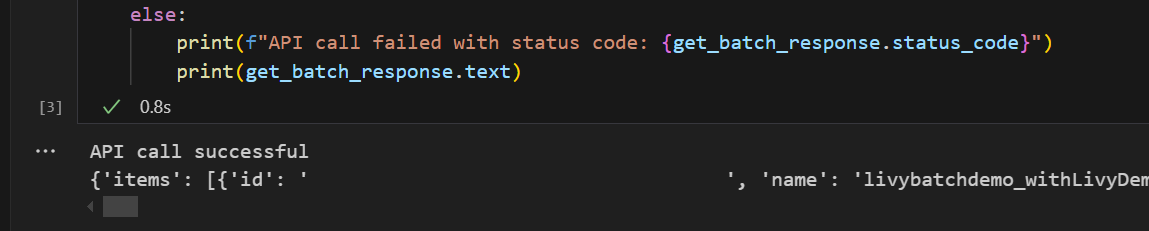





Send en spark.sql-sætning ved hjælp af Livy API-batchsessionen
Tilføj en anden notesbogcelle, og indsæt denne kode.
# submit payload to existing batch session print('Submit a spark job via the livy batch API to ') newlakehouseName = "YourNewLakehouseName" create_lakehouse = api_base_url_mist + "/workspaces/" + workspace_id + "/items" create_lakehouse_payload = { "displayName": newlakehouseName, "type": 'Lakehouse' } create_lakehouse_response = requests.post(create_lakehouse, headers=headers, json=create_lakehouse_payload) print(create_lakehouse_response.json()) payload_data = { "name":"livybatchdemo_with"+ newlakehouseName, "file":"abfss://YourABFSPathToYourPayload.py", "conf": { "spark.targetLakehouse": "Fabric_LakehouseID" } } get_batch_response = requests.post(get_livy_get_batch, headers=headers, json=payload_data) print("The Livy batch job submitted successful") print(get_batch_response.json())Kør notesbogcellen. Du kan se flere linjer udskrevet, når Livy-batchjobbet oprettes og køres.

Gå tilbage til lakehouse for at se ændringerne.

Få vist dine job i overvågningshubben
Du kan få adgang til overvågningshubben for at få vist forskellige Apache Spark-aktiviteter ved at vælge Overvåg i navigationslinkene til venstre.
Når batchjobbet er fuldført, kan du få vist sessionsstatussen ved at gå til Overvågning.
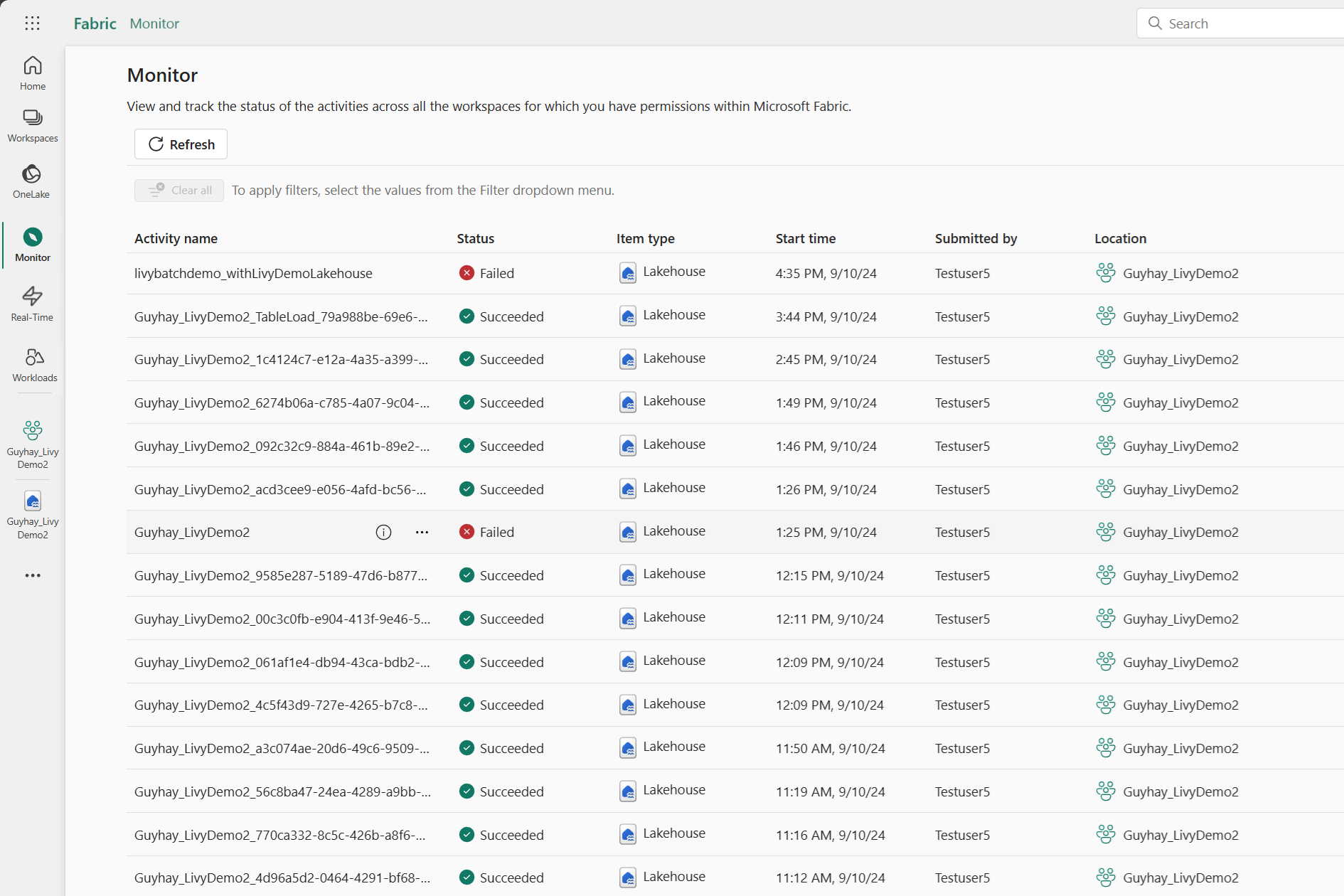
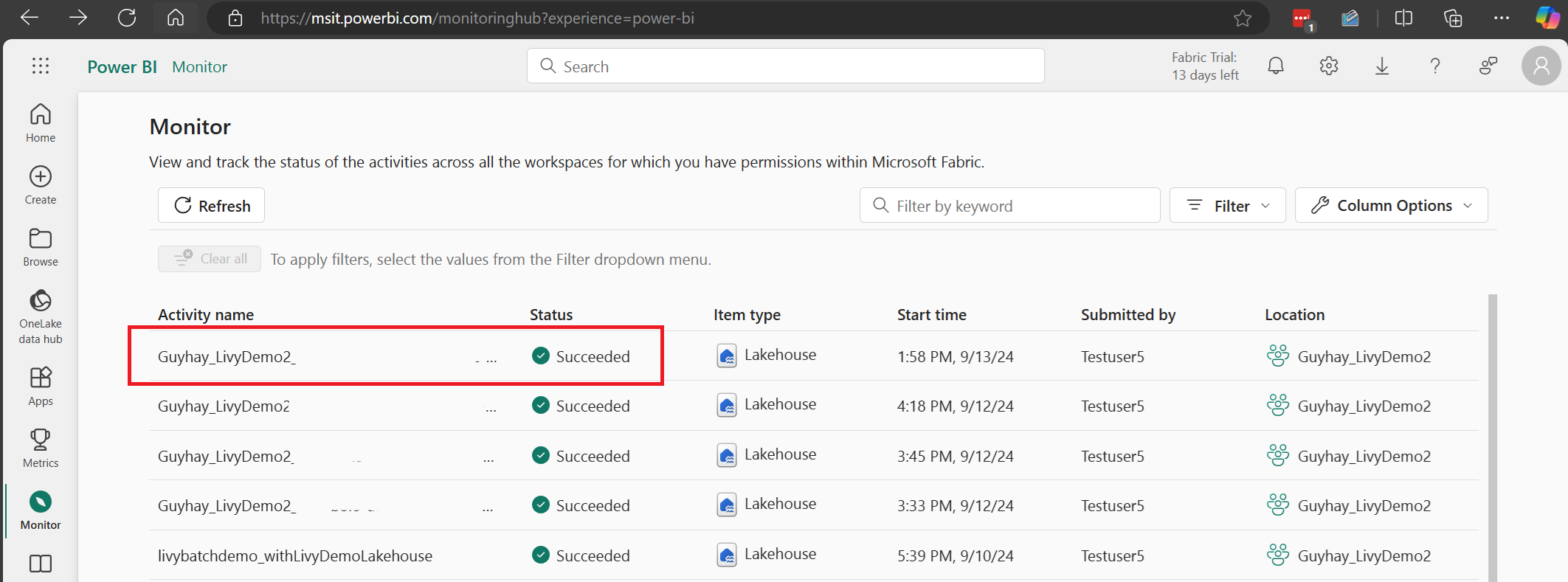
Vælg og åbn det seneste aktivitetsnavn.
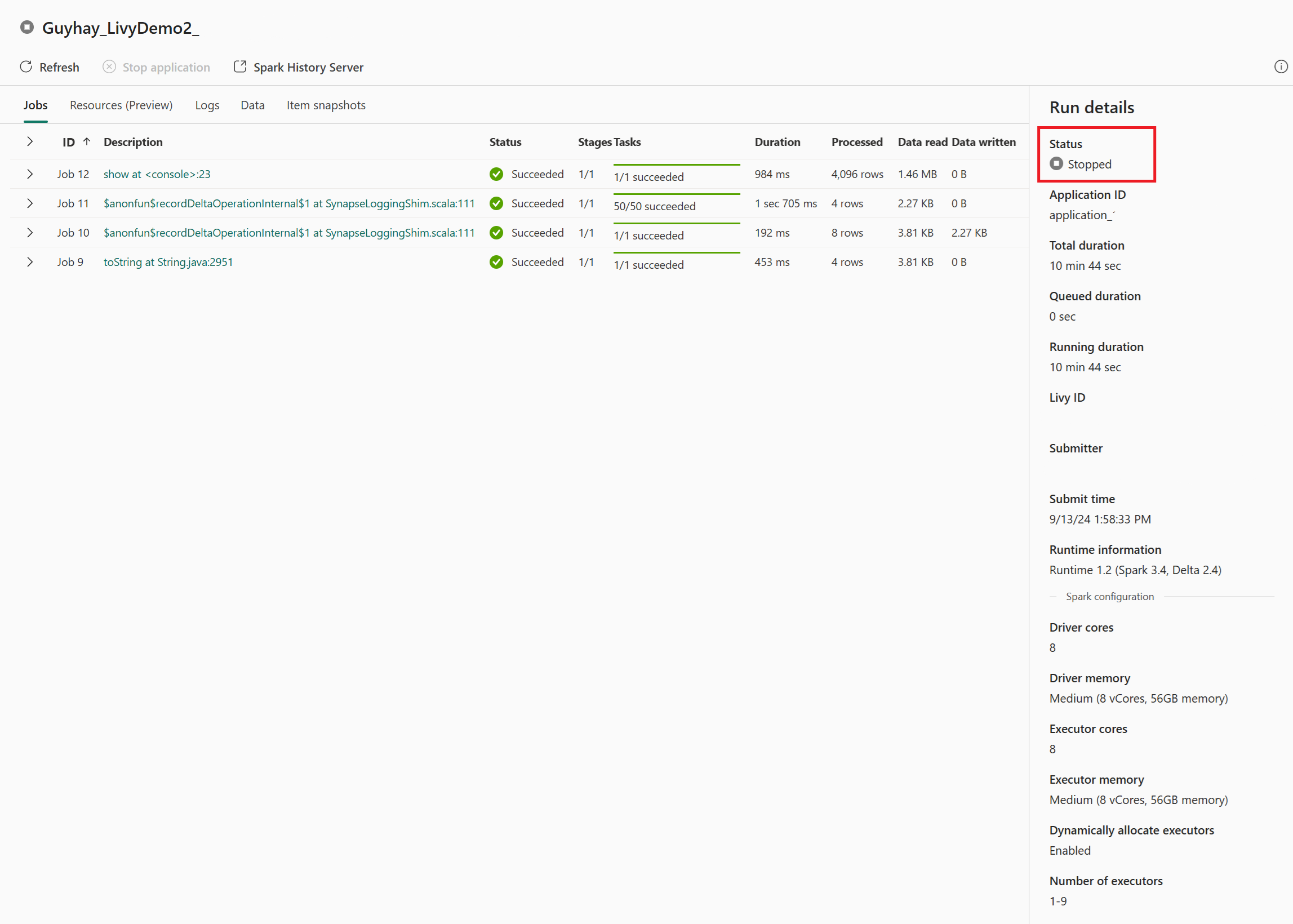
I denne Livy API-session kan du se din tidligere batchafsendelse, køre detaljer, Spark-versioner og konfiguration. Læg mærke til den stoppet status øverst til højre.



Hvis du vil opsummere hele processen, skal du bruge en fjernklient, f.eks . Visual Studio Code, et Microsoft Entra-app-token, URL-adressen til Livy API-slutpunktet, godkendelse mod lakehouse, en Spark-nyttedata i dit Lakehouse og endelig en batch Livy-API-session.