Overvågning af detaljer om Apache Spark-program
Med Microsoft Fabric kan du bruge Apache Spark til at køre notesbøger, job og andre typer programmer i dit arbejdsområde. I denne artikel forklares det, hvordan du overvåger dit Apache Spark-program, så du kan holde øje med den seneste kørselsstatus, problemer og status for dine job.
Vis Apache Spark-programmer
Du kan få vist alle Apache Spark-programmer fra Spark-jobdefinitionen, eller genvejsmenuen for notesbogelementet viser den seneste kørselsindstilling –> Seneste kørsler.

Du kan vælge navnet på det program, du vil have vist, på programlisten. På siden med programoplysninger kan du få vist programoplysningerne.
Overvåg Programstatus for Apache Spark
Åbn siden Seneste kørsler i notesbogen eller Spark-jobdefinitionen. Du kan få vist status for Apache-programmet.
- Vellykket

- I kø

- Stoppet

- Annullerede

- Mislykket

Job
Åbn et Apache Spark-programjob fra Spark-jobdefinitionen eller genvejsmenuen for notesbogelementet, der viser indstillingen Seneste kørsel –> Seneste kørsler –> vælg et job på siden seneste kørsler.
På siden med oplysninger om overvågning af Apache Spark-programmet vises listen over jobkørsler under fanen Job. Du kan få vist detaljerne for hvert job her, herunder job-id, Beskrivelse, Status, Faser, Opgaver, Varighed, Behandlet, Datalæsning, Dataskrevet og Kodestykke.
- Hvis du klikker på Job-id, kan du udvide/skjule jobbet.
- Klik på jobbeskrivelsen. Du kan gå til job- eller fasesiden i spark-brugergrænsefladen.
- Klik på kodestykket for jobbet. Du kan kontrollere og kopiere den kode, der er relateret til jobbet.

Ressourcer (prøveversion)
Grafen over eksekveringsanvendelse viser visuelt allokeringen af Spark-job-eksekvering og ressourceforbrug. I øjeblikket er det kun kørselsoplysningerne for spark 3.4 og nyere, der viser denne funktion. Vælg Ressourcer (prøveversion), hvorefter der udarbejdes fire typer kurver om eksekveringsforbrug, herunder Running, Idled, Allocated, Maximum instances.

For Allokeret henviser til den kernesituation, der allokeres under kørsel af Spark-programmet.
I forbindelse med Maksimalt antal forekomster henviser til det maksimale antal kerner, der er allokeret til Spark-programmet.
For Running refererer til det faktiske antal kerner, der bruges af Spark-programmet, når det kører. Klik på et tidspunkt, mens spark-programmet kører. Du kan se de løbende oplysninger om allokering af eksekveringskerne nederst i grafen.
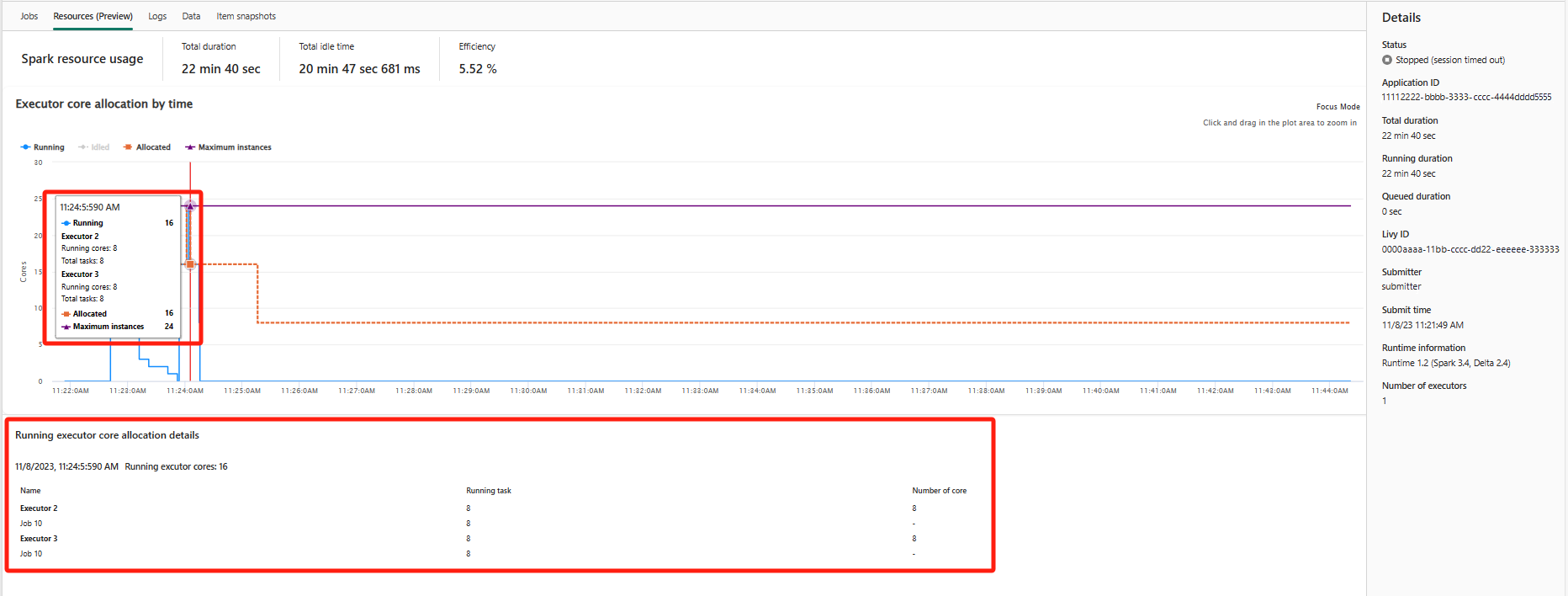
For Idled er det antallet af ubrugte kerner, mens Spark-programmet kører.

I nogle tilfælde kan antallet af opgaver på et tidspunkt overstige eksekveringskernernes kapacitet (dvs. opgavenumrenes > samlede eksekveringskerner /spark.task.cpus). Dette er som forventet, fordi der er et tidsinterval mellem en opgave, der er markeret som kørende, og den faktisk kører på en eksekveringskerne. Så nogle opgaver kan blive vist som kørende, men de kører ikke på nogen kerne.
Vælg farveikonet for at vælge eller fjerne markeringen af det tilsvarende indhold i alle grafer.

Oversigtspanel
Klik på knappen Egenskaber på siden Overvågning af Apache Spark-program for at åbne/skjule oversigtspanelet. Du kan få vist detaljerne for dette program i Detaljer.
- Status for dette spark-program.
- Id'et for dette Spark-program.
- Samlet varighed.
- Kørselsvarighed for dette spark-program.
- Varighed i kø for dette spark-program.
- Livy ID
- Indsender til dette spark-program.
- Send tid til dette spark-program.
- Antal eksekutorer.

Logfiler
Under fanen Logs kan du få vist den fulde log over Livy, Prelaunch, Driver log med forskellige indstillinger valgt i venstre panel. Du kan også hente de påkrævede logoplysninger direkte ved at søge efter nøgleord og få vist loggene ved at filtrere logstatussen. Klik på Download log for at hente logoplysningerne til det lokale.
Nogle gange er der ingen tilgængelige logge, f.eks. status for jobbet er sat i kø, og klyngeoprettelse mislykkedes.
Livelogge er kun tilgængelige, når indsendelse af apps mislykkes, og der leveres også driverlogge.

Data
Under fanen Data kan du kopiere datalisten i Udklipsholder, downloade datalisten og enkelte data og kontrollere egenskaberne for de enkelte data.
- Det venstre panel kan udvides eller skjules.
- Input- og outputfilernes navn, læseformat, størrelse, kilde og sti vises på denne liste.
- Filerne i input og output kan downloades, kopiere stien og få vist egenskaber.

Øjebliksbilleder af elementer
Fanen Elementsnapshots giver dig mulighed for at gennemse og få vist elementer, der er knyttet til Apache Spark-programmet, herunder Notesbøger, Spark-jobdefinition og/eller Pipelines. På siden med øjebliksbilleder af elementer vises snapshottet af kode- og parameterværdierne på kørselstidspunktet for notesbøger. Det viser også snapshottet af alle indstillinger og parametre på tidspunktet for indsendelse af Spark-jobdefinitioner. Hvis Apache Spark-programmet er knyttet til en pipeline, viser den relaterede elementside også den tilsvarende pipeline og Spark-aktiviteten.
På skærmbilledet Elementsnapshots kan du:
- Gennemse og naviger i de relaterede elementer i det hierarkiske træ.
- Klik på ellipseikonet 'En liste over flere handlinger' for hvert element for at udføre forskellige handlinger.
- Klik på snapshotelementet for at få vist dets indhold.
- Få vist Brødkrumme for at se stien fra det valgte element til roden.

Bemærk
Funktionen Snapshots til notesbøger understøtter i øjeblikket ikke notesbøger, der kører eller er i en Spark-session med høj samtidighed.
Diagnosticering
Diagnosticeringspanelet giver brugerne anbefalinger og fejlanalyse i realtid, som genereres af Spark Advisor via en analyse af brugerens kode. Med indbyggede mønstre hjælper Apache Spark Advisor brugerne med at undgå almindelige fejl og analyserer fejl for at identificere deres rodårsag.

Relateret indhold
Det næste trin, når du har vist detaljerne for et Apache Spark-program, er at få vist status for Spark-job under cellen Notesbog. Du kan se flere oplysninger: