Brug den udvidede Apache Spark-oversigtsserver til at foretage fejlfinding og diagnosticere Apache Spark-programmer
Denne artikel indeholder en vejledning i, hvordan du bruger den udvidede Apache Spark-oversigtsserver til at foretage fejlfinding og diagnosticere fuldførte og kørende Apache Spark-programmer.
Få adgang til Apache Spark-oversigtsserveren
Apache Spark-oversigtsserveren er webbrugergrænsefladen til fuldførte og kørende Spark-programmer. Du kan åbne Apache Spark-brugergrænsefladen (UI) fra statusindikatornotesbogen eller siden med oplysninger om Apache Spark-programmet.
Åbn brugergrænsefladen i Spark-web fra notesbogen med statusindikator
Når et Apache Spark-job udløses, er knappen til at åbne Spark-webbrugergrænseflade inde i indstillingen Mere handling i statusindikatoren. Vælg Spark-webbrugergrænseflade , og vent et par sekunder, hvorefter siden med Spark-brugergrænsefladen vises.

Åbn spark-webbrugergrænsefladen fra siden med oplysninger om Apache Spark-programmet
Brugergrænsefladen i Spark-web kan også åbnes via siden med oplysninger om Apache Spark-programmet. Vælg Overvåg til venstre på siden, og vælg derefter et Apache Spark-program. Detaljesiden for programmet vises.

For et Apache Spark-program, hvis status kører, viser knappen Spark-brugergrænsefladen. Vælg Spark UI , hvorefter siden med Brugergrænsefladen i Spark vises.

For et Apache Spark-program, hvis status er afsluttet, kan statussen stoppes, mislykkes, annulleres eller fuldføres. Knappen viser Spark-oversigtsserveren. Vælg Spark-oversigtsserver , hvorefter siden med Brugergrænsefladen i Spark vises.

Fanen Graph på Apache Spark-oversigtsserveren
Vælg job-id'et for det job, du vil have vist. Vælg derefter Graph i værktøjsmenuen for at få jobdiagramvisningen.
Oversigt
Du kan se en oversigt over dit job i den genererede jobgraf. Grafen viser som standard alle job. Du kan filtrere denne visning efter job-id.

Skærm
Statusvisningen er som standard valgt. Du kan kontrollere dataflowet ved at vælge Læs eller Skrevet på rullelisten Vis .

Grafnoden viser de farver, der vises i heatmapforklaringen.

Afspilning
Hvis du vil afspille jobbet, skal du vælge Afspilning. Du kan når som helst vælge Stop for at stoppe. Opgavefarverne viser forskellige statusser, når der afspilles:
| Color | Betydning |
|---|---|
| Grøn | Fuldført: Jobbet er fuldført. |
| Orange | Forsøgt igen: Forekomster af opgaver, der mislykkedes, men som ikke påvirker det endelige resultat af jobbet. Disse opgaver havde duplikerede eller gentagne forekomster, der kan lykkes senere. |
| Blå | Kører: Opgaven kører. |
| Hvid | Venter eller sprunget over: Opgaven venter på at køre, eller fasen er sprunget over. |
| Rød | Mislykket: Opgaven mislykkedes. |
På følgende billede vises grønne, orange og blå statusfarver.

På følgende billede vises grønne og hvide statusfarver.

På følgende billede vises røde og grønne statusfarver.

Bemærk
Apache Spark-oversigtsserveren tillader afspilning for hvert fuldført job (men tillader ikke afspilning for ufuldstændige job).
Zoom
Brug musen til at zoome ind og ud på jobgrafen, eller vælg Zoom for at tilpasse den, så den passer til skærmen.

Værktøjstip
Peg på grafnoden for at se værktøjstippet, når der er mislykkede opgaver, og vælg en fase for at åbne dens faseside.

Under fanen jobgraf vises der et værktøjstip i faserne, og der vises et lille ikon, hvis de har opgaver, der opfylder følgende betingelser:
| Betingelse | Beskrivelse |
|---|---|
| Dataforvrænget | Den gennemsnitlige datalæsningsstørrelse > for datalæsning for alle opgaver i denne fase * 2 og datalæsningsstørrelsen > 10 MB. |
| Tidsforvrænget | Den gennemsnitlige udførelsestid > for alle opgaver i denne fase * 2 og udførelsestid > 2 minutter. |
![]()
Beskrivelse af grafnode
Jobdiagramnoden viser følgende oplysninger om hver fase:
- Id
- Navn eller beskrivelse
- Samlet opgavenummer
- Læsning af data: summen af inputstørrelse og blandet læsestørrelse
- Dataskrivning: summen af outputstørrelsen og størrelsen af shuffle-skrivninger
- Udførelsestid: tiden mellem starttidspunktet for det første forsøg og afslutningstidspunktet for det sidste forsøg
- Rækkeantal: summen af inputposter, outputposter, bland læseposter og blandede skriveposter
- Status
Bemærk
Jobdiagramnoden viser som standard oplysninger fra det sidste forsøg på hver fase (undtagen tidspunktet for udførelse af fase). Under afspilningen viser grafnoden dog oplysninger om hvert forsøg.
Datastørrelsen for læsning og skrivning er 1 MB = 1000 KB = 1000 * 1000 byte.
Sende feedback
Send feedback med problemer ved at vælge Giv os feedback.

Grænse for fasenummer
Af hensyn til ydeevnen er grafen som standard kun tilgængelig, når Spark-programmet har mindre end 500 faser. Hvis der er for mange faser, mislykkes det med en fejl som denne:
The number of stages in this application exceeds limit (500), graph page is disabled in this case.
Før du starter et Spark-program, skal du anvende denne Spark-konfiguration for at øge grænsen:
spark.ui.enhancement.maxGraphStages 1000
Men bemærk, at dette kan medføre dårlig ydeevne for siden og API'en, fordi indholdet kan være for stort til, at browseren kan hente og gengive.
Udforsk fanen Diagnosticering på Apache Spark-oversigtsserveren
Hvis du vil have adgang til fanen Diagnosticering, skal du vælge et job-id. Vælg derefter Diagnosticering i værktøjsmenuen for at få jobdiagnosticeringsvisningen. Fanen Diagnosticering indeholder Data skew, Time Skew og Executor Usage Analysis.
Kontrollér dataforvrængelse, tidsforvrængelse og analyse af eksekveringsanvendelse ved at vælge fanerne.

Dataforvrænget
Når du vælger fanen Dataforvrænge , vises de tilsvarende skæve opgaver baseret på de angivne parametre.
Angiv parametre – I det første afsnit vises parametrene, som bruges til at registrere dataforvrænget. Standardreglen er: Læsning af opgavedata er større end tre gange den gennemsnitlige læsning af opgavedata, og opgavedataene er mere end 10 MB. Hvis du vil definere din egen regel for skæve opgaver, kan du vælge dine parametre. Sektionerne Skæv fase og Skævt tegn opdateres tilsvarende.
Skæv fase – I det andet afsnit vises faser, som har skæve opgaver, der opfylder de tidligere angivne kriterier. Hvis der er mere end én skæv opgave i en fase, viser tabellen med skæve faser kun den mest skæve opgave (f.eks. de største data for dataforvrænget).
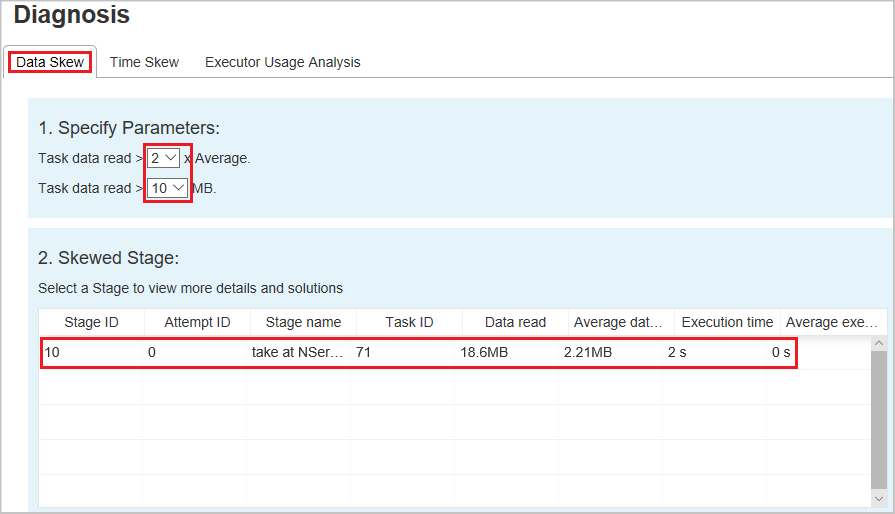
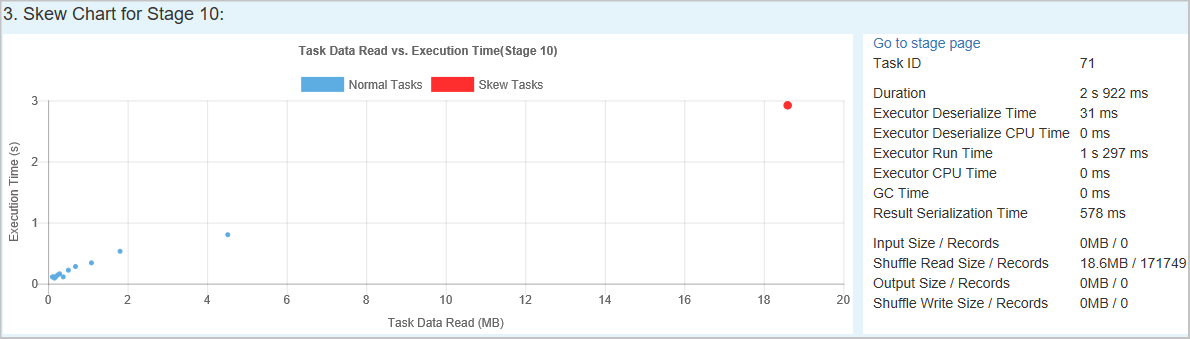
Skævt diagram – Når der vælges en række i tabellen med skæve faser, viser skævt diagrammet flere oplysninger om opgavefordeling baseret på datalæsnings- og udførelsestid. De skæve opgaver er markeret med rødt, og de normale opgaver er markeret med blåt. Diagrammet viser op til 100 eksempelopgaver, og opgavedetaljerne vises i højre nederste panel.


Tidsforvrænget
Under fanen Tidsforvrænget vises skæve opgaver baseret på opgavens udførelsestid.
Angiv parametre – I det første afsnit vises parametrene, som bruges til at registrere tidsforvrænget tid. Standardkriterierne for registrering af tidsforvrængelse er: Opgavens udførelsestid er større end tre gange den gennemsnitlige udførelsestid, og opgavens udførelsestid er større end 30 sekunder. Du kan ændre parametrene baseret på dine behov. Under Skæv fase og Skævt diagram vises de tilsvarende oplysninger om faser og opgaver på samme måde som fanen Dataforvrænget , der er beskrevet tidligere.
Vælg Tidsforvrænget, hvorefter filtreret resultat vises i sektionen Skæv fase i henhold til de parametre, der er angivet i afsnittet Angiv parametre. Vælg ét element i sektionen Skæv fase , derefter udarbejdes det tilsvarende diagram i sektion 3, og opgavedetaljerne vises i højre nederste panel.


Besøgsanalyse af eksekvering
Denne funktion frarådes i Fabric nu. Hvis du stadig vil bruge dette som en løsning, skal du få adgang til siden ved eksplicit at tilføje "/executorusage" bag stien "/diagnosticering" i URL-adressen på følgende måde:
