Příprava na použití Apache Sparku
Apache Spark je architektura pro distribuované zpracování dat, která umožňuje rozsáhlé analýzy dat tím, že koordinuje práci napříč několika uzly zpracování v clusteru, které se v Microsoft Fabric označují jako fond Sparku. Jednoduše řečeno, Spark používá k rychlému zpracování velkých objemů dat přístup "dělit a dobít" tím, že distribuuje práci napříč více počítači. Spark za vás zpracovává proces distribuce úkolů a kolace výsledků.
Spark může spouštět kód napsaný v široké škále jazyků, včetně Javy, Jazyka Scala (skriptovací jazyk založený na Javě), Spark R, Spark SQL a PySpark (varianta specifická pro Spark v Pythonu). V praxi se většina úloh přípravy a analýzy dat provádí pomocí kombinace PySpark a Spark SQL.
Fondy úloh Sparku
Fond Sparku se skládá z výpočetních uzlů, které distribuují úlohy zpracování dat. Obecná architektura je znázorněna v následujícím diagramu.
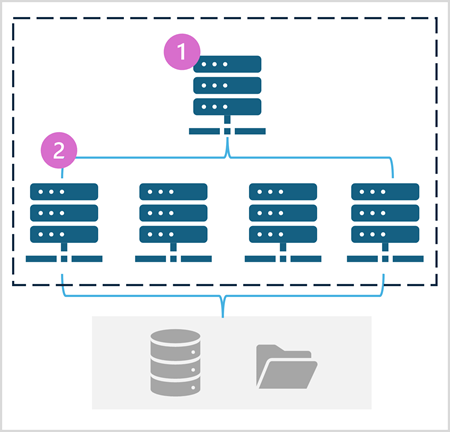
Jak je znázorněno v diagramu, fond Sparku obsahuje dva druhy uzlů:
- Hlavní uzel ve fondu Spark koordinuje distribuované procesy prostřednictvím programu ovladače.
- Fond obsahuje několik pracovních uzlů, na kterých exekutor provádí skutečné úlohy zpracování dat.
Fond Spark používá tuto distribuovanou výpočetní architekturu pro přístup k datům a zpracování dat v kompatibilním úložišti dat, jako je datové jezero založené na OneLake.
Fondy Sparku v Microsoft Fabric
Microsoft Fabric poskytuje počáteční fond v každém pracovním prostoru, který umožňuje spouštění úloh Sparku a rychlé spouštění s minimálním nastavením a konfigurací. Počáteční fond můžete nakonfigurovat tak, aby optimalizoval uzly, které obsahuje, v souladu s vašimi konkrétními potřebami úloh nebo nákladovými omezeními.
Kromě toho můžete vytvořit vlastní fondy Sparku s konkrétními konfiguracemi uzlů, které podporují vaše konkrétní potřeby zpracování dat.
Poznámka:
Možnost přizpůsobit nastavení fondu Sparku můžou správci prostředků infrastruktury zakázat na úrovni kapacity prostředků infrastruktury. Další informace najdete v tématu Nastavení správy kapacity pro Datoví technici a Datová Věda v dokumentaci k prostředkům infrastruktury.
Nastavení počátečního fondu můžete spravovat a vytvářet nové fondy Sparku v části Datoví technici/Věda v nastavení pracovního prostoru.
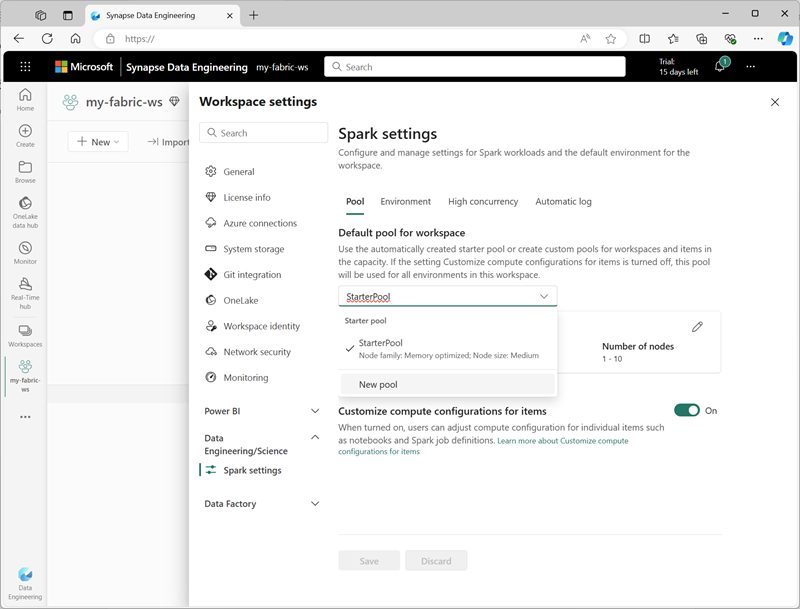
Mezi konkrétní nastavení konfigurace pro fondy Sparku patří:
- Řada uzlů: Typ virtuálních počítačů používaných pro uzly clusteru Spark. Ve většině případů poskytují uzly optimalizované pro paměť optimální výkon.
- Automatické škálování: Určuje, jestli se uzly automaticky zřizují podle potřeby, a pokud ano, počáteční a maximální počet uzlů, které se mají přidělit fondu.
- Dynamické přidělování: Zda dynamicky přidělovat exekutor procesy na pracovních uzlech na základě datových svazků.
Pokud v pracovním prostoru vytvoříte jeden nebo více vlastních fondů Sparku, můžete jeden z nich (nebo počáteční fond) nastavit jako výchozí fond, který se použije, pokud pro danou úlohu Sparku není zadaný konkrétní fond.
Tip
Další informace o správě fondů Sparku v Microsoft Fabric najdete v tématu Konfigurace počátečních fondů v Microsoft Fabric a postup vytvoření vlastních fondů Spark v Microsoft Fabric v dokumentaci k Microsoft Fabric.
Moduly runtime a prostředí
Opensourcový ekosystém Sparku obsahuje několik verzí modulu runtime Spark, který určuje verzi Apache Sparku, Delta Lake, Pythonu a dalších nainstalovaných základních softwarových komponent. Kromě toho můžete v modulu runtime nainstalovat a používat širokou škálu knihoven kódu pro běžné (a někdy velmi specializované) úlohy. Vzhledem k tomu, že se pomocí PySparku provádí velké množství zpracování Sparku, obrovská řada knihoven Pythonu zajišťuje, že jakýkoli úkol, který potřebujete provést, je pravděpodobně knihovna, která vám pomůže.
V některých případech mohou organizace potřebovat definovat více prostředí , aby podporovaly širokou škálu úloh zpracování dat. Každé prostředí definuje konkrétní verzi modulu runtime a knihovny, které je potřeba nainstalovat, aby bylo možné provádět konkrétní operace. Datoví inženýři a vědci pak můžou vybrat, které prostředí chcete použít s fondem Sparku pro konkrétní úlohu.
Moduly runtime Sparku v Microsoft Fabric
Microsoft Fabric podporuje více modulů runtime Spark a bude nadále přidávat podporu pro nové moduly runtime při jejich vydání. Rozhraní nastavení pracovního prostoru můžete použít k určení modulu runtime Spark, který se používá ve výchozím prostředí při spuštění fondu Sparku.
Tip
Další informace o modulech runtime Spark v Microsoft Fabric najdete v dokumentaci k Modulu runtime Apache Spark v prostředcích infrastruktury.
Prostředí v Microsoft Fabric
V pracovním prostoru Fabric můžete vytvářet vlastní prostředí, která umožňují používat konkrétní moduly runtime Sparku, knihovny a nastavení konfigurace pro různé operace zpracování dat.
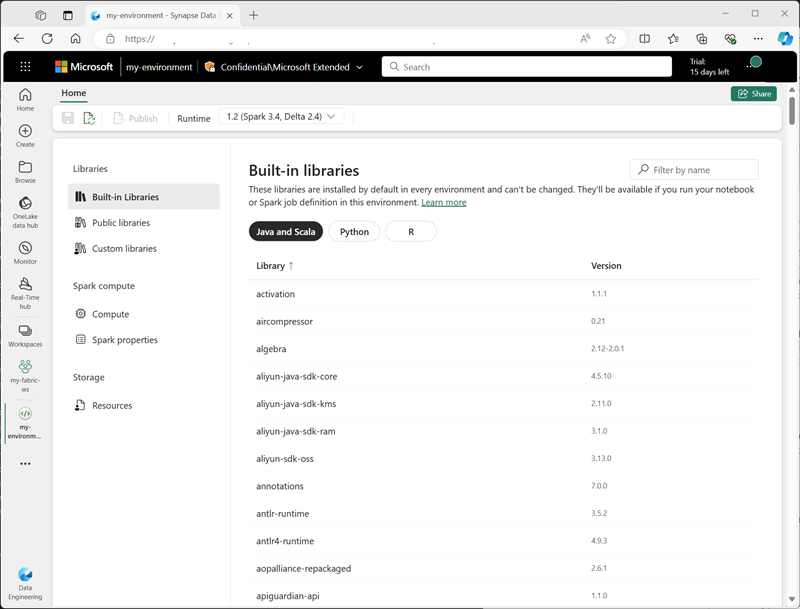
Při vytváření prostředí můžete:
- Zadejte modul runtime Sparku, který by měl použít.
- Prohlédněte si integrované knihovny, které jsou nainstalované v každém prostředí.
- Nainstalujte konkrétní veřejné knihovny z indexu balíčků Pythonu (PyPI).
- Nainstalujte vlastní knihovny tak, že nahrajete soubor balíčku.
- Zadejte fond Sparku, který má prostředí používat.
- Zadejte vlastnosti konfigurace Sparku pro přepsání výchozího chování.
- Nahrajte soubory prostředků, které musí být dostupné v prostředí.
Po vytvoření aspoň jednoho vlastního prostředí ho můžete zadat jako výchozí prostředí v nastavení pracovního prostoru.
Tip
Další informace o používání vlastních prostředí v Microsoft Fabric najdete v tématu Vytvoření, konfigurace a použití prostředí v Microsoft Fabric v dokumentaci k Microsoft Fabric.
Další možnosti konfigurace Sparku
Správa fondů a prostředí Sparku jsou primárními způsoby, kterými můžete spravovat zpracování Sparku v pracovním prostoru Prostředky infrastruktury. Existují však některé další možnosti, které můžete použít k další optimalizaci.
Nativní prováděcí modul
Nativní prováděcí modul v Microsoft Fabric je vektorizovaný modul pro zpracování, který spouští operace Sparku přímo na infrastruktuře lakehouse. Použití nativního prováděcího modulu může výrazně zlepšit výkon dotazů při práci s velkými datovými sadami ve formátech souborů Parquet nebo Delta.
Pokud chcete použít nativní prováděcí modul, můžete ho povolit na úrovni prostředí nebo v rámci jednotlivého poznámkového bloku. Pokud chcete povolit nativní spouštěcí modul na úrovni prostředí, nastavte v konfiguraci prostředí následující vlastnosti Sparku:
- spark.native.enabled: true
- spark.shuffle.manager: org.apache.spark.shuffle.sort.ColumnarShuffleManager
Pokud chcete povolit nativní prováděcí modul pro konkrétní skript nebo poznámkový blok, můžete tyto vlastnosti konfigurace nastavit na začátku kódu takto:
%%configure
{
"conf": {
"spark.native.enabled": "true",
"spark.shuffle.manager": "org.apache.spark.shuffle.sort.ColumnarShuffleManager"
}
}
Tip
Další informace o nativním prováděcím modulu naleznete v tématu Nativní prováděcí modul pro Fabric Spark v dokumentaci k Microsoft Fabric.
Režim vysoké souběžnosti
Když v Microsoft Fabric spustíte kód Sparku, zahájí se relace Sparku. Efektivitu využití prostředků Sparku můžete optimalizovat pomocí režimu vysoké souběžnosti ke sdílení relací Sparku mezi více souběžnými uživateli nebo procesy. Pokud je pro poznámkové bloky povolený režim vysoké souběžnosti, může několik uživatelů spouštět kód v poznámkových blocích, které používají stejnou relaci Sparku, a současně zajistit izolaci kódu, aby se zabránilo proměnným v jednom poznámkovém bloku, které mají vliv na kód v jiném poznámkovém bloku. Pro úlohy Sparku můžete také povolit režim vysoké souběžnosti a povolit podobné efektivity souběžného spouštění neinteraktivních skriptů Spark.
Pokud chcete povolit režim vysoké souběžnosti, použijte část Datoví technici/Science rozhraní nastavení pracovního prostoru.
Tip
Další informace o režimu vysoké souběžnosti najdete v tématu Režim vysoké souběžnosti v Apache Sparku for Fabric v dokumentaci k Microsoft Fabric.
Automatické protokolování MLFlow
MLFlow je opensourcová knihovna, která se používá v úlohách datových věd ke správě trénování strojového učení a nasazení modelu. Klíčovou schopností MLFlow je schopnost protokolování operací trénování a správy modelů. Microsoft Fabric ve výchozím nastavení používá MLFlow k implicitnímu protokolování aktivity experimentu strojového učení, aniž by to datový vědec musel zahrnout explicitní kód. Tuto funkci můžete zakázat v nastavení pracovního prostoru.
Správa Sparku pro kapacitu Prostředků infrastruktury
Správci můžou spravovat nastavení Sparku na úrovni kapacity Fabric, což jim umožní omezit a přepsat nastavení Sparku v pracovních prostorech v rámci organizace.
Tip
Další informace o správě konfigurace Sparku na úrovni kapacity Infrastruktury najdete v tématu Konfigurace a správa nastavení přípravy dat a datových věd pro kapacity Fabric v dokumentaci k Microsoft Fabric.