Přizpůsobení chování modelu pro dávkové vyhodnocování
Když jste model vytrénovali, chcete ho použít k vygenerování nových předpovědí. Představte si například, že jste natrénovali model prognózování. Každý týden použijete model na historická prodejní data a vygenerujete prognózu prodeje nadcházejícího týdne.
V Microsoft Fabric můžete použít uložený model a použít ho na data k vygenerování a uložení nových předpovědí. Model vezme nová data jako vstup, provede potřebné transformace a vypíše predikce.
Informace o očekávaných vstupech a výstupech modelu jsou uloženy v artefaktech modelu, které jsou vytvořeny během trénování modelu. Při sledování modelu pomocí MLflow můžete během dávkového vyhodnocování změnit očekávané chování modelu.
Tip
Přečtěte si další informace o trénování a sledování modelů strojového učení pomocí MLflow v Microsoft Fabric.
Přizpůsobení chování modelu
Pokud chcete použít natrénovaný model na nová data, musí model vědět, jaký je tvar očekávaného vstupu dat, a jak vytvořit výstup předpovědí. Informace o očekávaných vstupech a výstupech jsou uloženy společně s dalšími metadaty v MLmodel souboru.
Při sledování modelu strojového učení pomocí MLflow v Microsoft Fabric se odvozují očekávané vstupy a výstupy modelu. S automatickýmlogováním model MLflow se automaticky vytvoří složka a MLmodel soubor za vás.
Kdykoli chcete změnit očekávané vstupy nebo výstupy modelu, můžete změnit způsob MLmodel vytvoření souboru při sledování modelu v pracovním prostoru Microsoft Fabric. Schéma vstupu a výstupu dat je definováno v podpisu modelu.
Vytvoření podpisu modelu
Po sledování modelu pomocí MLflow během trénování modelu najdete MLmodel soubor ve model složce, který je uložený při spuštění experimentu:
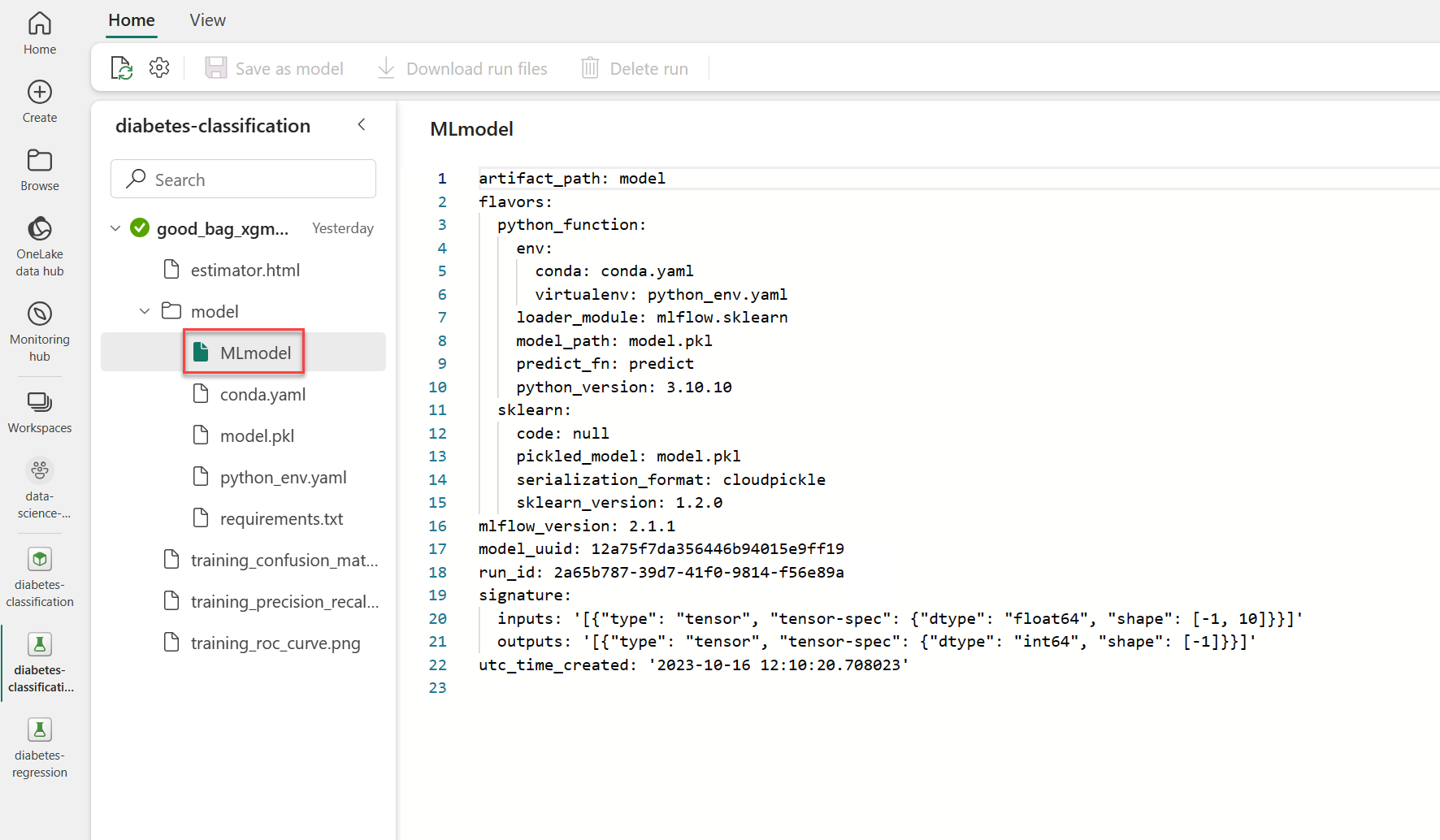
Při zkoumání ukázkového MLmodel souboru si všimnete, že očekávané vstupy a výstupy jsou definované jako tensory. Když model použijete prostřednictvím průvodce, zobrazí se pouze jeden vstupní sloupec, protože se očekává, že vstupní data budou pole.
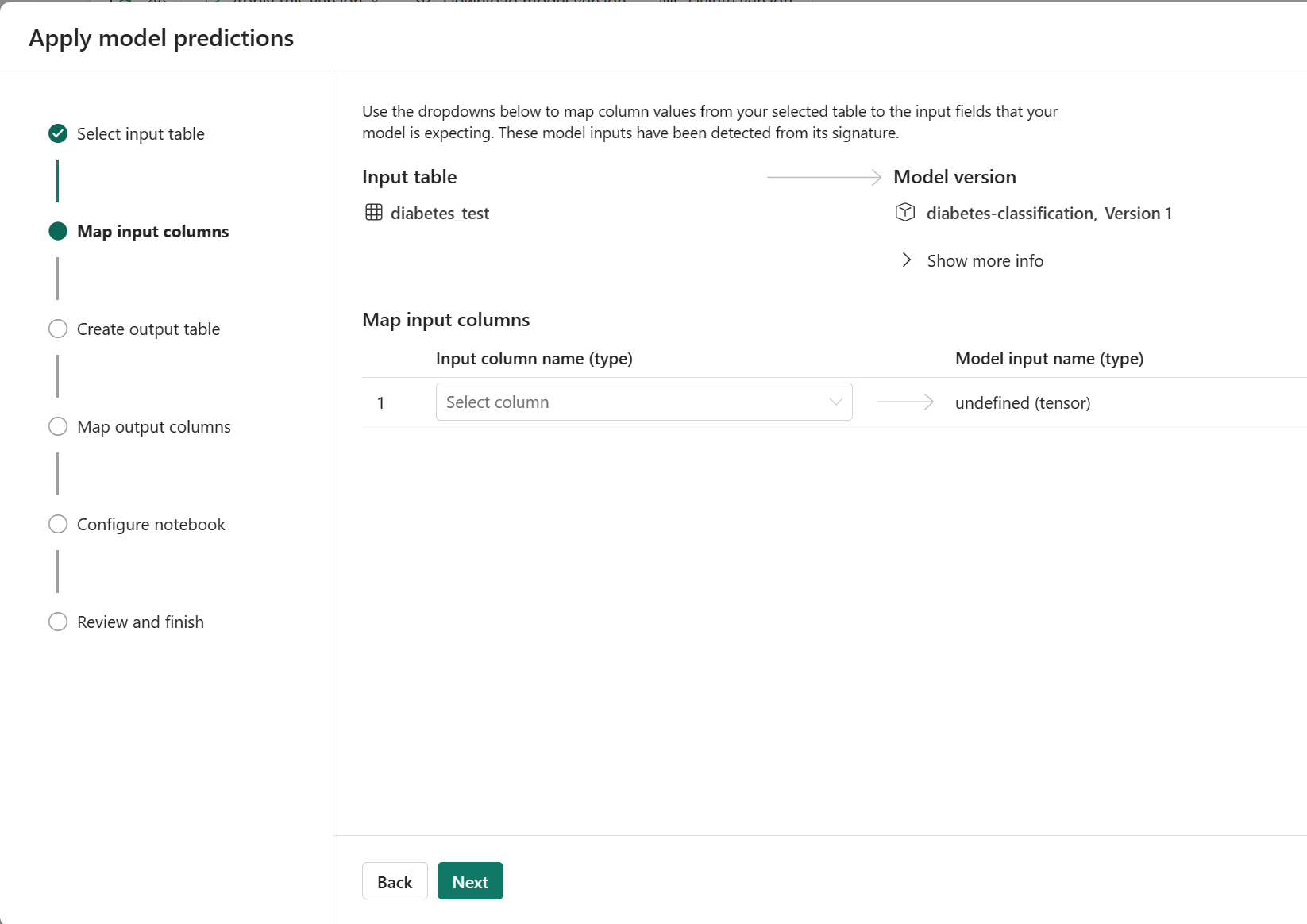
Pokud chcete změnit způsob použití modelu, můžete definovat různé očekávané vstupní a výstupní sloupce.
Pojďme se podívat na příklad trénování modelu scikit-learn a pomocí automatického protokolování MLflow protokolovat všechny ostatní parametry a metriky. Pokud chcete model protokolovat ručně, můžete nastavit log_models=False.
K definování vstupního schématu použijete třídu MLflow Schema . Můžete zadat očekávané vstupní sloupce, jejich datové typy a jejich názvy. Podobně můžete definovat výstupní schéma, které se obvykle skládá z jednoho sloupce, který představuje cílovou proměnnou.
Nakonec vytvoříte objekt podpisu modelu pomocí třídy MLflow ModelSignature .
from sklearn.tree import DecisionTreeRegressor
from mlflow.models.signature import ModelSignature
from mlflow.types.schema import Schema, ColSpec
with mlflow.start_run():
# Use autologging for all other parameters and metrics
mlflow.autolog(log_models=False)
model = DecisionTreeRegressor(max_depth=5)
# When you fit the model, all other information will be logged
model.fit(X_train, y_train)
# Create the signature manually
input_schema = Schema([
ColSpec("integer", "AGE"),
ColSpec("integer", "SEX"),
ColSpec("double", "BMI"),
ColSpec("double", "BP"),
ColSpec("integer", "S1"),
ColSpec("double", "S2"),
ColSpec("double", "S3"),
ColSpec("double", "S4"),
ColSpec("double", "S5"),
ColSpec("integer", "S6"),
])
output_schema = Schema([ColSpec("integer")])
# Create the signature object
signature = ModelSignature(inputs=input_schema, outputs=output_schema)
# Manually log the model
mlflow.sklearn.log_model(model, "model", signature=signature)
Výsledkem je, že soubor uložený MLmodel ve model výstupní složce vypadá takto:
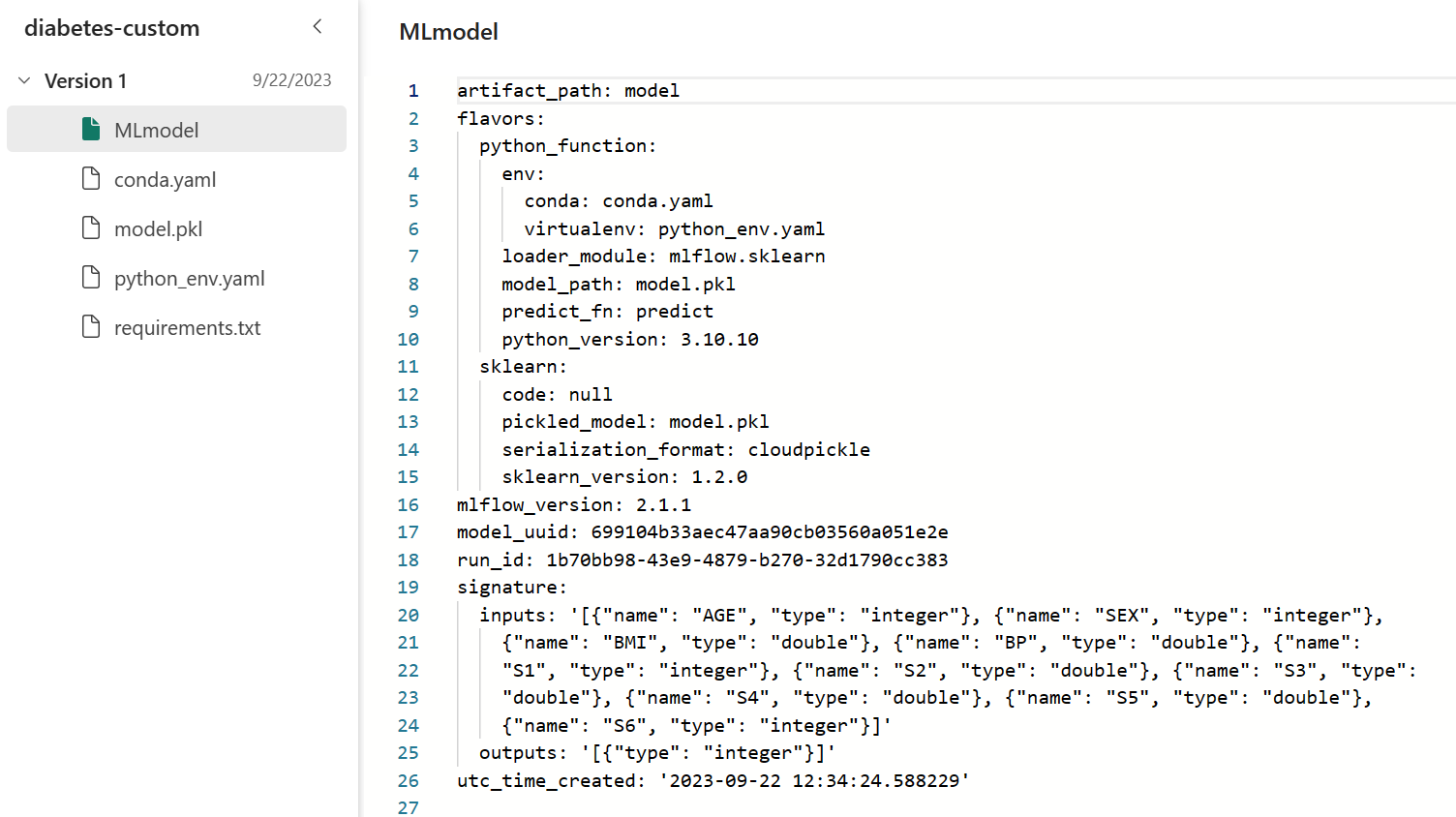
Při použití modelu v průvodci můžete najít jasně definované vstupní sloupce a usnadnit jejich sladění s datovou sadou, pro kterou chcete vygenerovat předpovědi.
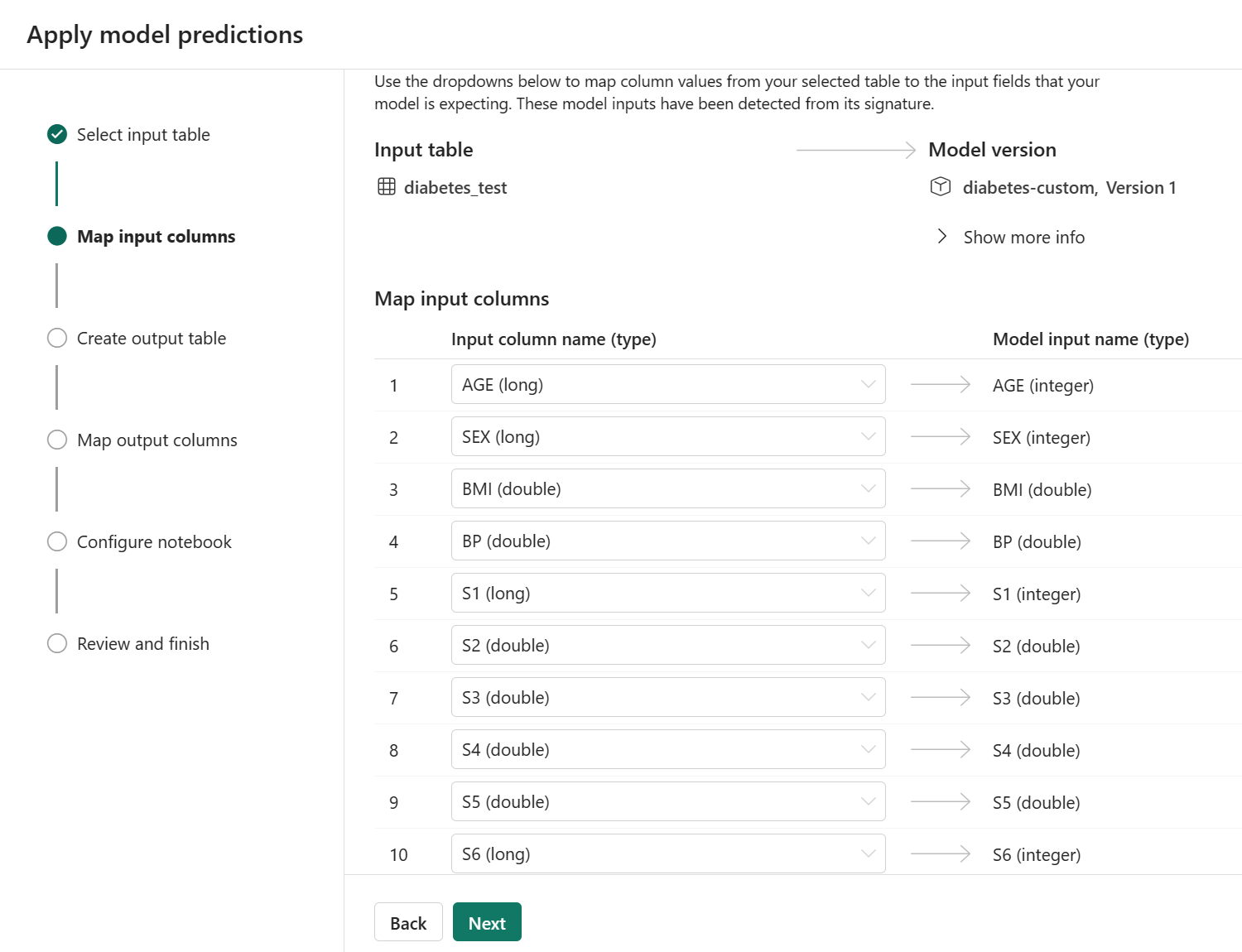
Uložení modelu do pracovního prostoru Microsoft Fabric
Po trénování a sledování modelu strojového učení pomocí MLflow v Microsoft Fabric můžete zkontrolovat obsah model výstupní složky při spuštění experimentu. Když MLmodel soubor prozkoumáte konkrétně, můžete se rozhodnout, jestli se váš model bude chovat podle očekávání během dávkového vyhodnocování.
Pokud chcete ke generování dávkových předpovědí použít sledovaný model, musíte ho uložit. Při ukládání modelu v Microsoft Fabric můžete:
- Vytvořte nový model.
- Přidejte novou verzi do existujícího modelu.
Pokud chcete model uložit, musíte zadat model výstupní složku, protože tato složka obsahuje všechny potřebné informace o chování modelu při dávkovém vyhodnocování a samotných artefaktů modelu. Vytrénovaný model se obvykle ukládá jako pickle soubor ve stejné složce.
Model můžete snadno uložit tak, že přejdete do příslušného experimentu spuštěného v uživatelském rozhraní.
Případně můžete model uložit prostřednictvím kódu:
# Get the experiment by name
exp = mlflow.get_experiment_by_name(experiment_name)
# List the last experiment run
last_run = mlflow.search_runs(exp.experiment_id, order_by=["start_time DESC"], max_results=1)
# Retrieve the run ID of the last experiment run
last_run_id = last_run.iloc[0]["run_id"]
# Create a path to the model output folder of the last experiment run
model_uri = "runs:/{}/model".format(last_run_id)
# Register or save the model by specifying the model folder and model name
mv = mlflow.register_model(model_uri, "diabetes-model")