Detekce objektů pomocí rychlého R-CNN
Obsah
- Souhrn
- Nastavení
- Spuštění ukázky toy
- Spuštění PascalU VOC
- Trénování CNTK Fast R-CNN na vlastních datech
- Technické podrobnosti
- Podrobnosti algoritmu
Souhrn

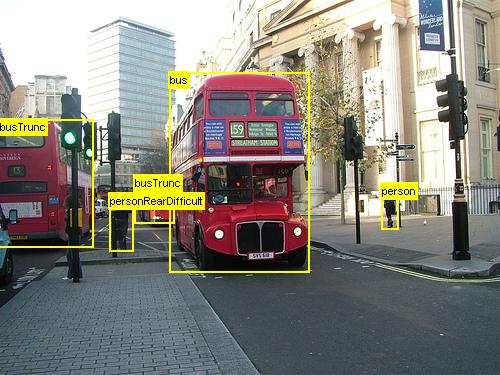
Tento kurz popisuje, jak používat CNTK Fast R-CNN s BrainScriptem a cntk.exe. Rychlé připojení R-CNN pomocí rozhraní API Pythonu CNTK je popsáno tady.
Výše uvedené příklady jsou obrázky a poznámky k objektům pro datovou sadu potravin (první obrázek) a sadu dat Pascal VOC (druhý obrázek) použitou v tomto kurzu.
Fast R-CNN je algoritmus detekce objektů navržený Rossem Girshickem v roce 2015. Papír je přijat na ICCV 2015 a archivován na https://arxiv.org/abs/1504.08083. Rychlá síť R-CNN vychází z předchozí práce, která efektivně klasifikuje návrhy objektů pomocí hlubokých konvolučních sítí. V porovnání s předchozí prací využívá Fast R-CNN oblast schématu sdružování zájmů , která umožňuje opakovaně používat výpočty z konvolučních vrstev.
Další materiál: podrobný kurz pro detekci objektů pomocí CNTK Fast R-CNN s BrainScriptem (včetně volitelného trénování SVM a publikování vytrénovaného modelu jako rozhraní REST API) najdete tady.
Nastavení
Ke spuštění kódu v tomto příkladu potřebujete prostředí Pythonu CNTK ( nápovědu k nastavení najdete tady ). Dále je potřeba nainstalovat několik dalších balíčků. Přejděte do složky FastRCNN a spusťte:
pip install -r requirements.txt
Známý problém: Pokud chcete nainstalovat scikit-learn, možná budete muset spustit conda install scikit-learn , pokud používáte Anaconda Python.
K provedení těchto příkladů budete dále potřebovat Scikit-Image a OpenCV.
Stáhněte si odpovídající balíčky kol a nainstalujte je ručně. V Linuxu můžete conda install scikit-image opencv.
Pro uživatele Windows navštivte http://www.lfd.uci.edu/~gohlke/pythonlibs/a stáhněte:
- Python 3.5
- scikit_image-0.12.3-cp35-cp35m-win_amd64.whl
- opencv_python-3.2.0-cp35-cp35m-win_amd64.whl
Jakmile stáhnete příslušné binární soubory kol, nainstalujte je s:
pip install your_download_folder/scikit_image-0.12.3-cp35-cp35m-win_amd64.whl
[! POZNÁMKA]: Pokud se při spuštění skriptů pip install futurezobrazí zpráva Žádný modul s názvem Ne.
Tento kód kurzu předpokládá, že používáte 64bitovou verzi Pythonu 3.5 nebo 3.6, protože požadované soubory DLL fast R-CNN v rámci nástrojů jsou předem připravené pro tyto verze. Pokud vaše úloha vyžaduje použití jiné verze Pythonu, překompilujte tyto soubory DLL sami ve správném prostředí (viz níže).
Tento kurz dále předpokládá, že složka, ve které se nachází cntk.exe, je ve vaší proměnné prostředí PATH. (Chcete-li přidat složku do cesty, můžete spustit následující příkaz z příkazového řádku (za předpokladu, že složka, ve které je na vašem počítači cntk.exe, je C:\src\CNTK\x64\Release): set PATH=C:\src\CNTK\x64\Release;%PATH%.)
Předkompilované binární soubory pro regresi ohraničujícího rámečku a ne maximální potlačení
Složka Examples\Image\Detection\FastRCNN\BrainScript\fastRCNN\utils obsahuje předem zkompilované binární soubory, které jsou nutné pro spuštění služby Fast R-CNN. Verze, které jsou aktuálně obsažené v úložišti, jsou Python 3.5 a 3.6, všechny 64bitové. Pokud potřebujete jinou verzi, můžete ji zkompilovat následujícím postupem:
git clone --recursive https://github.com/rbgirshick/fast-rcnn.gitcd $FRCN_ROOT/libmakemakeMísto toho můžete spustitpython setup.py build_ext --inplaceze stejné složky. Ve Windows možná budete muset zakomentovat extra kompilační args v knihovně lib/setup.py:
ext_modules = [ Extension( "utils.cython_bbox", ["utils/bbox.pyx"], #extra_compile_args=["-Wno-cpp", "-Wno-unused-function"], ), Extension( "utils.cython_nms", ["utils/nms.pyx"], #extra_compile_args=["-Wno-cpp", "-Wno-unused-function"], ) ]zkopírujte vygenerované
cython_bboxacython_nmsbinární soubory z$FRCN_ROOT/lib/utilsdo$CNTK_ROOT/Examples/Image/Detection/fastRCNN/utils.
Příklad modelu dat a směrného plánu
Jako základ pro trénování Fast-R-CNN používáme předem natrénovaný model AlexNet. Předem vytrénovaný AlexNet je k dispozici na adrese https://www.cntk.ai/Models/AlexNet/AlexNet.model. Uložte prosím model na adrese $CNTK_ROOT/PretrainedModels. Pokud chcete stáhnout data, spusťte
python install_grocery.py
Examples/Image/DataSets/Grocery ze složky.
Spuštění ukázky toy
V příkladu toy natrénujeme model CNTK Fast R-CNN k detekci potravinových položek v ledničce.
Všechny požadované skripty jsou v $CNTK_ROOT/Examples/Image/Detection/FastRCNN/BrainScript.
Rychlá příručka
Pokud chcete spustit příklad toy, ujistěte se, že PARAMETERS.pydataset je nastavená hodnota "Grocery".
- Spuštěním
A1_GenerateInputROIs.pyvygenerujte vstupní roI pro trénování a testování. - Spusťte
A2_RunWithBSModel.pytrénování a testování pomocí cntk.exe a BrainScriptu. - Spusťte
A3_ParseAndEvaluateOutput.pyvýpočet mAP (průměrná přesnost) natrénovaného modelu.
Výstup skriptu A3 by měl obsahovat následující:
Evaluating detections
AP for avocado = 1.0000
AP for orange = 1.0000
AP for butter = 1.0000
AP for champagne = 1.0000
AP for eggBox = 0.7500
AP for gerkin = 1.0000
AP for joghurt = 1.0000
AP for ketchup = 0.6667
AP for orangeJuice = 1.0000
AP for onion = 1.0000
AP for pepper = 1.0000
AP for tomato = 0.7600
AP for water = 0.5000
AP for milk = 1.0000
AP for tabasco = 1.0000
AP for mustard = 1.0000
Mean AP = 0.9173
DONE.
Pokud chcete vizualizovat ohraničující pole a předpovězené popisky, můžete spustit B3_VisualizeOutputROIs.py (kliknutím na obrázky zvětšete):





Podrobnosti o kroku
A1: Skript A1_GenerateInputROIs.py nejprve vygeneruje kandidáty na návratnost dat pro každý obrázek pomocí selektivního vyhledávání.
Pak je ukládá ve formátu TEXTU CNTK jako vstup pro cntk.exe.
Kromě toho se vygenerují požadované vstupní soubory CNTK pro obrázky a popisky základní pravdy.
Skript vygeneruje následující složky a soubory ve FastRCNN složce:
proc– kořenová složka pro vygenerovaný obsah.grocery_2000– obsahuje všechny vygenerované složky a soubory, napříkladgrocerypomocí2000roI. Pokud znovu spustíte s jiným počtem roI, název složky se odpovídajícím způsobem změní.rois– obsahuje nezpracované souřadnice ROI pro každý obrázek uložený v textových souborech.cntkFiles- obsahuje formátované vstupní soubory CNTK pro obrázky (train.txtatest.txt), souřadnice ROI (xx.rois.txt) a popisky ROI (xx.roilabels.txt) protrainatest. (Níže jsou uvedeny podrobnosti formátu.)
Všechny parametry jsou obsaženy PARAMETERS.py, například změna cntk_nrRois = 2000 nastavení počtu roI používaných pro trénování a testování. Parametry popisujeme v části Parametry níže.
A2: Skript A2_RunWithBSModel.py spustí cntk pomocí cntk.exe a konfiguračního souboru BrainScriptu (podrobnosti konfigurace).
Trénovaný model je uložen ve složce odpovídající proc podsložkycntkFiles/Output.
Trénovaný model se testuje samostatně na trénovací sadě i testovací sadě.
Během testování jednotlivých imagí a každé odpovídající roI je popisek předpovězen a uložen v souborech test.z a train.z ve cntkFiles složce.
A3: Krok vyhodnocení analyzuje výstup CNTK a vypočítá mAP porovnává předpovězené výsledky s podkladovými poznámkami pravdy.
K sloučení překrývajících se roI se používá ne maximální potlačení. Můžete nastavit prahovou hodnotu pro ne maximální potlačení (PARAMETERS.pypodrobnosti).
Další skripty
Existují tři volitelné skripty, které můžete spustit pro vizualizaci a analýzu dat:
B1_VisualizeInputROIs.pyvizualizuje kandidátské vstupní roI.B2_EvaluateInputROIs.pyvypočítá odvolání základní pravdy ROI s ohledem na kandidátské ROI.B3_VisualizeOutputROIs.pyvizualizovat ohraničující pole a predikované popisky.
Spuštění PascalU VOC
Data Pascal VOC (Visual Object Class) jsou dobře známou sadou standardizovaných obrázků pro rozpoznávání tříd objektů. Trénování nebo testování CNTK Fast R-CNN na datech Pascal VOC vyžaduje GPU s alespoň 4 GB paměti RAM. Alternativně můžete spouštět pomocí procesoru, což ale nějakou dobu trvá.
Získání dat Pascal VOC
Potřebujete data z roku 2007 (trainval and test) a 2012 (trainval) a také předem propočítané roI použité v původním dokumentu.
Musíte postupovat podle struktury složek popsaných níže.
Skripty předpokládají, že data Pascalu se nacházejí v $CNTK_ROOT/Examples/Image/DataSets/Pascal.
Pokud používáte jinou složku, nastavte pascalDataDirPARAMETERS.py ji odpovídajícím způsobem.
- Stažení a rozbalení dat trénování 2012 do
DataSets/Pascal/VOCdevkit2012 - Stažení a rozbalení dat trénování 2007 do
DataSets/Pascal/VOCdevkit2007 - Stažení a rozbalení testovacích dat 2007 do stejné složky
DataSets/Pascal/VOCdevkit2007 - Stažení a rozbalení předem připravených roI do
DataSets/Pascal/selective_search_data* http://dl.dropboxusercontent.com/s/orrt7o6bp6ae0tc/selective_search_data.tgz?dl=0
Složka VOCdevkit2007 by měla vypadat takto (podobně jako v roce 2012):
VOCdevkit2007/VOC2007
VOCdevkit2007/VOC2007/Annotations
VOCdevkit2007/VOC2007/ImageSets
VOCdevkit2007/VOC2007/JPEGImages
Spuštění CNTK na Pascal VOC
Chcete-li běžet na datech Pascal VOC, ujistěte se, že PARAMETERS.pydataset je nastavena na "pascal"hodnotu .
- Spusťte
A1_GenerateInputROIs.pygenerování vstupních souborů CNTK pro trénování a testování ze stažených dat ROI. - Spusťte
A2_RunWithBSModel.pytrénování modelu Fast R-CNN a výsledků výpočetního testu. - Spusťte
A3_ParseAndEvaluateOutput.pyvýpočet mAP (průměrná přesnost) natrénovaného modelu.- Upozorňujeme, že probíhá práce a výsledky jsou předběžné, protože trénujeme nové standardní modely.
- Ujistěte se, že máte nejnovější verzi z hlavního serveru CNTK pro soubory fastRCNN/pascal_voc.py a fastRCNN/voc_eval.py , abyste se vyhnuli chybám kódování.
Trénování vlastních dat
Příprava vlastní datové sady
Možnost č. 1: Nástroj pro označování vizuálních objektů (doporučeno)
Nástroj pro označování vizuálních objektů (VOTT) je nástroj pro poznámky napříč platformami pro označování prostředků videa a obrázků.

VOTT poskytuje následující funkce:
- Označování a sledování objektů ve videích s asistencí počítače pomocí algoritmu sledování Camshift
- Export značek a prostředků do formátu CNTK Fast-RCNN pro trénování modelu detekce objektů
- Spuštění a ověření vytrénovaného modelu detekce objektů CNTK na nových videích za účelem generování silnějších modelů
Jak anotovat pomocí VOTT:
- Stáhněte si nejnovější verzi.
- Pokud chcete spustit úlohu označování, postupujte podle readme .
- Po označení značek Export značek do adresáře datové sady
Možnost č. 2: Použití skriptů poznámek
K trénování modelu CNTK Fast R-CNN ve vaší vlastní sadě dat poskytujeme dva skripty pro přidávání poznámek obdélníkových oblastí na obrázcích a přiřazování popisků k těmto oblastem.
Skripty uloží poznámky ve správném formátu podle potřeby při prvním kroku spuštění fast R-CNN (A1_GenerateInputROIs.py).
Nejprve uložte obrázky do následující struktury složek.
<your_image_folder>/negative– obrázky používané pro trénování, které neobsahují žádné objekty<your_image_folder>/positive– obrázky používané pro trénování, které obsahují objekty<your_image_folder>/testImages– obrázky používané k testování, které obsahují objekty
U záporných obrázků nemusíte vytvářet žádné poznámky. Pro ostatní dvě složky použijte zadané skripty:
- Spuštěním
C1_DrawBboxesOnImages.pynakreslete ohraničující pole na obrázcích.- Před spuštěním sady
imgDir = <your_image_folder>skriptů (/positivenebo/testImages) - Přidejte poznámky pomocí kurzoru myši. Jakmile jsou všechny objekty na obrázku označené poznámkami, stisknutím klávesy n zapíšete soubor .bboxes.txt a pak přejdete na další obrázek " u" zpět (tj. odebere) poslední obdélník a "q" ukončí nástroj pro poznámky.
- Před spuštěním sady
- Spusťte
C2_AssignLabelsToBboxes.pypřiřazení popisků k ohraničujícím polím.- V sadě skriptů
imgDir = <your_image_folder>(/positivenebo/testImages) před spuštěním... - ... a přizpůsobte třídy ve skriptu tak, aby odrážely vaše kategorie objektů, například
classes = ("dog", "cat", "octopus"). - Skript načte tyto ručně označené obdélníky pro každý obrázek, zobrazí je 1:1 a požádá uživatele, aby zadal třídu objektu kliknutím na příslušné tlačítko vlevo od okna. Podkladové poznámky pravdy označené jako "nedecidované" nebo "vyloučení" jsou zcela vyloučeny z dalšího zpracování.
- V sadě skriptů
Trénování ve vlastní datové sadě
Před spuštěním CNTK Fast R-CNN pomocí skriptů A1-A3 je potřeba přidat datovou sadu do PARAMETERS.py:
- Nastavit
dataset = "CustomDataset" - Přidejte parametry pro sadu dat v rámci třídy
CustomDatasetPythonu . Můžete začít zkopírováním parametrů z webuGroceryParameters- Přizpůsobte třídy tak, aby odrážely vaše kategorie objektů. Podle výše uvedeného příkladu by to vypadalo jako
self.classes = ('__background__', 'dog', 'cat', 'octopus'). - Nastavit
self.imgDir = <your_image_folder>. - Volitelně můžete upravit další parametry, například pro generování roI a vyřazování (viz část Parametry ).
- Přizpůsobte třídy tak, aby odrážely vaše kategorie objektů. Podle výše uvedeného příkladu by to vypadalo jako
Připraveno k trénování na vlastních datech! (Použijte stejný postup jako v příkladu toy.)
Technické podrobnosti
Parametry
Hlavní parametry jsou v PARAMETERS.py
dataset- kterou datovou sadu použítcntk_nrRois– kolik roI se má použít pro trénování a testovánínmsThreshold- Ne maximální prahová hodnota potlačení (v rozsahu [0,1]). Čím nižší bude roI sloučeno. Používá se pro vyhodnocení i vizualizaci.
Všechny parametry pro generování ROI, například minimální a maximální šířku a výšku atd., jsou popsány v PARAMETERS.py rámci třídy ParametersPython . Všechny jsou nastavené na výchozí hodnotu, která je rozumná.
Můžete je přepsat v oddílu # project-specific parameters odpovídající sadě dat, kterou používáte.
Konfigurace CNTK
Konfigurační soubor CNTK BrainScript, který se používá k trénování a testování fast R-CNN, je fastrcnn.cntk.
Část, která vytváří síť, je BrainScriptNetworkBuilder oddíl v Train příkazu:
BrainScriptNetworkBuilder = {
network = BS.Network.Load ("../../../../../../../PretrainedModels/AlexNet.model")
convLayers = BS.Network.CloneFunction(network.features, network.conv5_y, parameters = "constant")
fcLayers = BS.Network.CloneFunction(network.pool3, network.h2_d)
model (features, rois) = {
featNorm = features - 114
convOut = convLayers (featNorm)
roiOut = ROIPooling (convOut, rois, (6:6))
fcOut = fcLayers (roiOut)
W = ParameterTensor{($NumLabels$:4096), init="glorotUniform"}
b = ParameterTensor{$NumLabels$, init = 'zero'}
z = W * fcOut + b
}.z
imageShape = $ImageH$:$ImageW$:$ImageC$ # 1000:1000:3
labelShape = $NumLabels$:$NumTrainROIs$ # 21:64
ROIShape = 4:$NumTrainROIs$ # 4:64
features = Input {imageShape}
roiLabels = Input {labelShape}
rois = Input {ROIShape}
z = model (features, rois)
ce = CrossEntropyWithSoftmax(roiLabels, z, axis = 1)
errs = ClassificationError(roiLabels, z, axis = 1)
featureNodes = (features:rois)
labelNodes = (roiLabels)
criterionNodes = (ce)
evaluationNodes = (errs)
outputNodes = (z)
}
Na prvním řádku je předem natrénovaný AlexNet načten jako základní model. Další dvě části sítě jsou klonovány: convLayers obsahuje konvoluční vrstvy s konstantními hmotnostmi, tj. nejsou natrénovány dále.
fcLayers obsahuje plně propojené vrstvy s předem natrénovanými hmotnostmi, které budou dále trénovány.
Názvy network.featuresuzlů atd network.conv5_y . lze odvodit z zobrazení výstupu protokolu volání cntk.exe (obsaženého ve výstupu A2_RunWithBSModel.py protokolu skriptu).
Definice modelu (model (features, rois) = ...) nejprve normalizuje funkce odečtením 114 pro každý kanál a pixel.
Normalizované funkce se pak prosadí convLayersROIPooling a nakonec fcLayers.
Výstupní obrazec (šířka:výška) vrstvy sdružování ROI je nastaven na (6:6) , protože se jedná o velikost obrazce, kterou předem vytrénovaný fcLayers z modelu AlexNet očekává. Výstupem je fcLayers hustota vrstvy, která predikuje jednu hodnotu na popisek (NumLabels) pro každou roI.
Následující šest řádků definuje vstup:
- obrázek velikosti 1000 x 1000 x 3 (
$ImageH$:$ImageW$:$ImageC$), - popisky základní pravdy pro každou roi (
$NumLabels$:$NumTrainROIs$) - a čtyři souřadnice na hodnotu ROI (
4:$NumTrainROIs$) odpovídající hodnotě (x, y, w, h), všechny relativní vzhledem k plné šířce a výšce obrázku.
z = model (features, rois)do definovaného síťového modelu předá vstupní image a roI a přiřadí výstup .z
Kritérium () i chyba (CrossEntropyWithSoftmaxClassificationError) se zadává axis = 1 tak, aby se zohlednila chyba předpovědi na hodnotu ROI.
Část čtenáře konfigurace CNTK je uvedena níže. Používá tři deserializery:
ImageDeserializerpro čtení dat obrázku. Vezme názvy souborů obrázku ztrain.txt, škáluje obrázek na požadovanou šířku a výšku při zachování poměru stran (odsazení prázdných oblastí s114) a transponuje tensor tak, aby měl správný vstupní obrazec.- Jeden
CNTKTextFormatDeserializerke čtení souřadnic ROI ztrain.rois.txt. - Sekunda
CNTKTextFormatDeserializerke čtení popisků ROI ztrain.roislabels.txt.
Formáty vstupních souborů jsou popsány v další části.
reader = {
randomize = false
verbosity = 2
deserializers = ({
type = "ImageDeserializer" ; module = "ImageReader"
file = train.txt
input = {
features = { transforms = (
{ type = "Scale" ; width = $ImageW$ ; height = $ImageW$ ; channels = $ImageC$ ; scaleMode = "pad" ; padValue = 114 }:
{ type = "Transpose" }
)}
ignored = {labelDim = 1000}
}
}:{
type = "CNTKTextFormatDeserializer" ; module = "CNTKTextFormatReader"
file = train.rois.txt
input = { rois = { dim = $TrainROIDim$ ; format = "dense" } }
}:{
type = "CNTKTextFormatDeserializer" ; module = "CNTKTextFormatReader"
file = train.roilabels.txt
input = { roiLabels = { dim = $TrainROILabelDim$ ; format = "dense" } }
})
}
Formát vstupního souboru CNTK
Existují tři vstupní soubory pro CNTK Fast R-CNN odpovídající třem deserializerům popsaným výše:
train.txtobsahuje v každém řádku první pořadové číslo, pak název souboru obrázku a nakonec a0(který je aktuálně potřeba z starších důvodů ImageReader).
0 image_01.jpg 0
1 image_02.jpg 0
...
train.rois.txt(Textový formát CNTK) obsahuje v každém řádku první pořadové číslo a potom|roisidentifikátor následovaný posloupností čísel. Jedná se o skupiny čtyř čísel odpovídajících hodnotám (x, y, w, h) roI, které jsou relativní vzhledem k celé šířce a výšce obrázku. Na řádek je celkem 4 * počet rois.
0 |rois 0.2185 0.0 0.165 0.29 ...
train.roilabels.txt(Textový formát CNTK) obsahuje v každém řádku první pořadové číslo a potom|roiLabelsidentifikátor následovaný posloupností čísel. Jedná se o skupiny čísel s čísly typu číslování (nula nebo jedna) na roI kódující základní třídu pravdy v jedné horké reprezentaci. Existuje celkový počet popisků * počet rois na řádek.
0 |roiLabels 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ...
Podrobnosti algoritmu
Rychlé R-CNN
R-CNN pro detekci objektů byly poprvé prezentovány v roce 2014 RossEm Girshickem et al., a ukázaly se, že překonaly předchozí nejmodernější přístupy k jednomu z hlavních problémů rozpoznávání objektů v oblasti: Pascal VOC. Od té doby byly publikovány dva následné dokumenty, které obsahují významná vylepšení rychlosti: Fast R-CNN a Faster R-CNN.
Základní myšlenkou sítě R-CNN je vzít hlubokou neurální síť, která byla původně natrénována pro klasifikaci obrázků pomocí milionů obrázků s poznámkami a upravit ji pro účely detekce objektů. Základní myšlenka z prvního dokumentu R-CNN je znázorněna na obrázku níže (převzato z papíru): (1) Při zadání vstupního obrázku (2) v prvním kroku se vygenerují návrhy velkého počtu oblastí. (3) Tyto návrhy oblastí nebo oblasti zájmů (ROI) se pak každý nezávisle odesílá prostřednictvím sítě, která vypíše vektor například 4096 hodnot s plovoucí desetinou čárkou pro každou roI. Nakonec (4) se naučí klasifikátor, který přebírá reprezentaci 4096 float ROI jako vstup a vypíše popisek a spolehlivost každé NÁVRATNOSTI.
I když tento přístup funguje dobře z hlediska přesnosti, je velmi nákladné vypočítat, protože pro každou návratnost dat musí být vyhodnocena neurální síť. Rychlá síť R-CNN tuto nevýhodu řeší pouze vyhodnocením většiny sítě (aby byla specifická: konvoluční vrstvy) na jeden čas na obrázek. Podle autorů to vede k 213násobné zrychlení během testování a 9x zrychlení během trénování bez ztráty přesnosti. Toho dosáhnete pomocí vrstvy fondu ROI, která promítá NÁVRATNOSTI na konvoluční mapu funkcí a provede maximální sdružování, aby se vygenerovala požadovaná výstupní velikost, kterou očekává následující vrstva. V příkladu AlexNetu použitém v tomto kurzu se vrstva sdružování ROI umístí mezi poslední konvoluční vrstvu a první plně propojenou vrstvu (viz kód BrainScriptu).
Původní implementace Caffe použitá v dokumentech R-CNN najdete na GitHubu: RCNN, Fast R-CNN a Faster R-CNN. V tomto kurzu se používají některé kódy z těchto úložišť, zejména (ale ne výhradně) pro trénování a vyhodnocení modelu SVM.
Trénování SVM vs. NN
Patrick Buehler poskytuje pokyny, jak vytrénovat SVM na výstupu CNTK Fast R-CNN (pomocí funkcí 4096 z poslední plně připojené vrstvy), stejně jako diskuzi o pros a nevýhody zde.
Selektivní vyhledávání
Selektivní vyhledávání je metoda pro vyhledání velké sady možných umístění objektů na obrázku nezávisle na třídě skutečného objektu. Funguje tak, že seskupí obrazové pixely do segmentů a pak provede hierarchické clusteringy, aby zkombinoval segmenty ze stejného objektu do návrhů objektů.



Abychom doplnili zjištěné návratnosti z selektivního vyhledávání, přidáme roi, které uniformují obrázek v různých měřítkech a poměrech stran. První obrázek ukazuje příklad výstupu selektivního vyhledávání, kde je každé možné umístění objektu vizualizováno zeleným obdélníkem. RoI, které jsou příliš malé, příliš velké atd. jsou zahozeny (druhý obrázek) a nakonec roi, které rovnoměrně pokrývají obrázek, se přidají (třetí obrázek). Tyto obdélníky se pak používají jako oblasti zájmu (ROI) v kanálu R-CNN.
Cílem generování ROI je najít malou sadu ROI, které však úzce pokrývají co nejvíce objektů na obrázku. Tento výpočet musí být dostatečně rychlý, zatímco současně vyhledá umístění objektů v různých měřítkech a poměrech stran. Selektivní vyhledávání bylo pro tuto úlohu zobrazeno dobře, s dobrou přesností pro urychlení kompromisů.
NMS (bez maximálního potlačení)
Metody detekce objektů často vypisují více detekcí, které plně nebo částečně pokrývají stejný objekt na obrázku.
Tyto návratnosti dat je potřeba sloučit, aby bylo možné spočítat objekty a získat jejich přesná umístění na obrázku.
To se tradičně provádí pomocí techniky, která se nazývá Non Maximum Potlačení (NMS). Verze NMS, kterou používáme (a která byla také použita v publikacích R-CNN), nesloučí roI, ale místo toho se snaží identifikovat, které roi nejlépe pokrývají skutečné umístění objektu a zahodí všechny ostatní ROI. To je implementováno iterativním výběrem roI s nejvyšší jistotou a odebráním všech ostatních ROI, které výrazně překrývají tuto NÁVRATNOSTI a jsou klasifikovány jako stejné třídy. Prahovou hodnotu pro překrytí je možné nastavit v PARAMETERS.py (podrobnosti).
Výsledky detekce před (první obrázek) a za (druhý obrázek) Non Maximum Potlačení:

mAP (střední průměrná přesnost)
Po vytrénování lze kvalitu modelu měřit pomocí různých kritérií, jako je přesnost, úplnost, přesnost, oblast podkřivení atd. Běžnou metrikou, která se používá pro výzvu rozpoznávání objektů Pascal VOC, je měřit průměrnou přesnost (AP) pro každou třídu. Následující popis průměrné přesnosti je převzat z Everingham et. al. Střední průměrná přesnost (mAP) se vypočítá tak, že převezme průměr nad APS všech tříd.
U daného úkolu a třídy se křivka přesnosti a úplnosti vypočítá z seřazeného výstupu metody. Úplnost je definována jako podíl všech pozitivních příkladů seřazených nad daným pořadím. Přesnost je podíl všech příkladů výše uvedených pořadí, které jsou z kladné třídy. Ap shrnuje tvar křivky přesnosti a úplnosti a je definován jako střední přesnost na sadě rovnoměrně rozmístěných úrovní úplnosti [0,0,1, . . . ,1]:
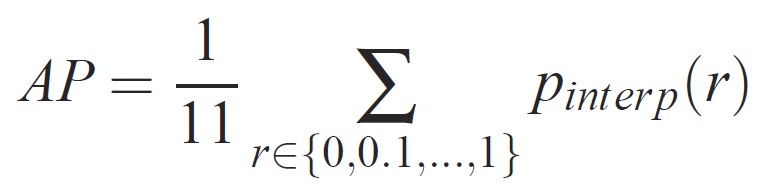
Přesnost na každé úrovni úplnosti r je interpolována pomocí maximální přesnosti měřené pro metodu, pro kterou odpovídající úplnost překračuje r:
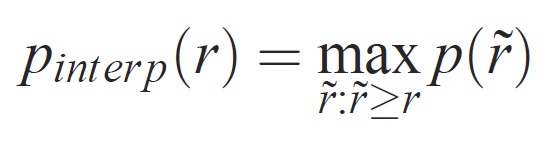
kde p( ̃r) je naměřená přesnost při úplnosti ̃r. Záměrem interpolace křivky přesnosti a úplnosti tímto způsobem je snížit dopad "vlnovek" v křivkě přesnosti a úplnosti způsobené malými variacemi v pořadí příkladů. Je třeba poznamenat, že pokud chcete získat vysoké skóre, musí mít metoda přesnost na všech úrovních úplnosti – tato penalizuje metody, které načítají pouze podmnožinu příkladů s vysokou přesností (např. zobrazení na straně automobilů).