Rozpoznávání objektů pomocí rychlého připojení R-CNN
Obsah
- Souhrn
- Nastavení
- Spuštění příkladu toy
- Trénování dat Pascal VOC
- Trénování CNTK Fast R-CNN na vlastních datech
- Technické podrobnosti
- Podrobnosti o algoritmu
Souhrn

Tento kurz popisuje, jak používat fast R-CNN v rozhraní CNTK Python API. Rychlé R-CNN pomocí BrainScriptu a cnkt.exe je zde popsáno.
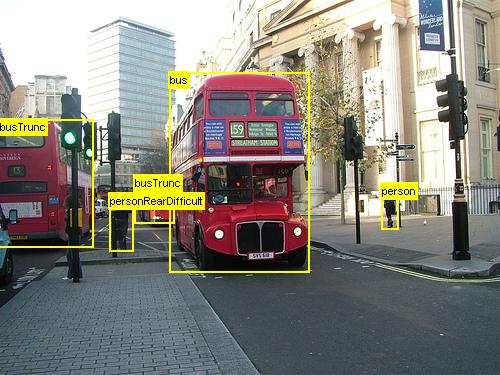
Výše uvedené příklady jsou obrázky a poznámky k objektům pro datnou sadu potravin (vlevo) a sadu dat Pascal VOC (vpravo) použitou v tomto kurzu.
Fast R-CNN je algoritmus detekce objektů navržený Rossem Girshickem v roce 2015. Dokument je přijat na ICCV 2015 a archivován na https://arxiv.org/abs/1504.08083adrese . Rychlá síť R-CNN vychází z předchozí práce na efektivní klasifikaci návrhů objektů pomocí hlubokých konvolučních sítí. V porovnání s předchozí prací využívá fast R-CNN oblast schématu sdružování zájmů , která umožňuje opakovaně používat výpočty z konvolučních vrstev.
Nastavení
Pokud chcete kód spustit v tomto příkladu, potřebujete prostředí PYTHONu CNTK (nápovědu k nastavení najdete tady ). Nainstalujte do prostředí Pythonu cntk následující další balíčky.
pip install opencv-python easydict pyyaml dlib
Předkompilované binární soubory pro regresi ohraničujícího rámečku a ne maximální potlačení
Složka Examples\Image\Detection\utils\cython_modules obsahuje předem zkompilované binární soubory, které jsou potřeba pro spuštění fast R-CNN. Verze, které jsou aktuálně obsažené v úložišti, jsou Python 3.5 pro Windows a Python 3.5, 3.6 pro Linux, všechny 64bitové verze. Pokud potřebujete jinou verzi, můžete ji zkompilovat podle kroků popsaných v tématu
- Linux: https://github.com/rbgirshick/py-faster-rcnn
- Windows: https://github.com/MrGF/py-faster-rcnn-windows
Zkopírujte vygenerované cython_bbox a cpu_nms (nebo gpu_nms) binární soubory od $FRCN_ROOT/lib/utils do $CNTK_ROOT/Examples/Image/Detection/utils/cython_modules.
Příklad modelu dat a směrného plánu
Jako základ pro trénování Fast-R-CNN používáme předem natrénovaný model AlexNet (pro VGG nebo jiné základní modely viz Použití jiného základního modelu. Ukázkovou datovou sadu i předem vytrénovaný model AlexNet si můžete stáhnout spuštěním následujícího příkazu Pythonu ze složky FastRCNN:
python install_data_and_model.py
- Naučte se používat jiný základní model.
- Naučte se spouštět rychlé R-CNN v datech Pascal VOC.
- Naučte se spouštět fast R-CNN na vlastních datech.
Spuštění příkladu toy
Trénování a vyhodnocení rychlého spuštění R-CNN
python run_fast_rcnn.py
Výsledky pro trénování s návratností 2000 ROI pro potraviny pomocí AlexNetu by měly vypadat přibližně takto:
AP for gerkin = 1.0000
AP for butter = 1.0000
AP for joghurt = 1.0000
AP for eggBox = 1.0000
AP for mustard = 1.0000
AP for champagne = 1.0000
AP for orange = 1.0000
AP for water = 0.5000
AP for avocado = 1.0000
AP for tomato = 1.0000
AP for pepper = 1.0000
AP for tabasco = 1.0000
AP for onion = 1.0000
AP for milk = 1.0000
AP for ketchup = 0.6667
AP for orangeJuice = 1.0000
Mean AP = 0.9479
Vizualizace předpovídané ohraničující rámečky a popisky na obrázcích otevřených FastRCNN_config.py ze FastRCNN složky a nastavení
__C.VISUALIZE_RESULTS = True
Obrázky se uloží do FastRCNN/Output/Grocery/ složky, pokud spustíte python run_fast_rcnn.py.
Train on Pascal VOC
Pokud chcete stáhnout data Pascal a vytvořit soubory poznámek pro Pascal ve formátu CNTK, spusťte následující skripty:
python Examples/Image/DataSets/Pascal/install_pascalvoc.py
python Examples/Image/DataSets/Pascal/mappings/create_mappings.py
dataset_cfg Změna metody get_configuration()run_fast_rcnn.py na
from utils.configs.Pascal_config import cfg as dataset_cfg
Teď jste nastavili trénování dat Pascal VOC 2007 pomocí python run_fast_rcnn.py. Pozor na to, že trénování může chvíli trvat.
Trénování vlastních dat
Příprava vlastní datové sady
Možnost č. 1: Nástroj pro označování vizuálních objektů (doporučeno)
Nástroj VOTT (Visual Object Tagging Tool) je nástroj pro označování videí a obrázků pro označování videí a obrázků pomocí nástroje pro poznámky mezi platformami.

VOTT poskytuje následující funkce:
- Označování a sledování objektů ve videích s asistencí počítače pomocí sledovacího algoritmu Camshiftu
- Export značek a prostředků do formátu CNTK Fast-RCNN pro trénování modelu detekce objektů
- Spuštění a ověření vytrénovaného modelu detekce objektů CNTK na nových videích za účelem generování silnějších modelů
Jak anotovat pomocí VOTT:
- Stažení nejnovější verze
- Pokud chcete spustit úlohu označování, postupujte podle readme .
- Po označení značky Exportovat značky do adresáře datové sady
Možnost č. 2: Použití skriptů poznámek
Pro trénování modelu CNTK Fast R-CNN ve vaší vlastní sadě dat poskytujeme dva skripty pro přidávání poznámek k obdélníkovým oblastem na obrázcích a přiřazování popisků k těmto oblastem.
Skripty uloží poznámky ve správném formátu podle potřeby v prvním kroku spuštění sítě Fast R-CNN (A1_GenerateInputROIs.pyFast R-CNN).
Nejprve uložte obrázky do následující struktury složek.
<your_image_folder>/negative– obrázky používané pro trénování, které neobsahují žádné objekty<your_image_folder>/positive– obrázky používané pro trénování, které obsahují objekty<your_image_folder>/testImages– obrázky používané k testování, které obsahují objekty
U negativních obrázků nemusíte vytvářet žádné poznámky. Pro ostatní dvě složky použijte poskytnuté skripty:
- Spuštěním nakreslete
C1_DrawBboxesOnImages.pyohraničující rámečky na obrázcích.- V sadě
imgDir = <your_image_folder>skriptů (/positivenebo/testImages) před spuštěním. - Přidejte poznámky pomocí kurzoru myši. Jakmile jsou všechny objekty v obrázku opatřeny poznámkami, stisknutím klávesy n zapíšete soubor .bboxes.txt a pak přejdete k dalšímu obrázku, vrátí se zpět (tj. odebere) poslední obdélník a funkce q nástroj poznámek ukončí.
- V sadě
- Spusťte
C2_AssignLabelsToBboxes.pypřiřazení popisků k ohraničujícím polím.- V sadě
imgDir = <your_image_folder>skriptů (/positivenebo/testImages) před spuštěním... - ... a přizpůsobte třídy ve skriptu tak, aby odrážely vaše kategorie objektů, například
classes = ("dog", "cat", "octopus"). - Skript načte tyto ručně anotované obdélníky pro každý obrázek, zobrazí je 1:1 a požádá uživatele, aby zadal třídu objektu kliknutím na příslušné tlačítko vlevo od okna. Uzemněné poznámky pravdy označené jako "nedecidované" nebo "vyloučení" jsou zcela vyloučeny z dalšího zpracování.
- V sadě
Trénování na vlastní datové sadě
Po uložení obrázků do popsané struktury složek a jejich přidávání poznámek spusťte
python Examples/Image/Detection/utils/annotations/annotations_helper.py
po změně složky v daném skriptu na složku s daty. Nakonec vytvořte MyDataSet_config.py ve utils\configs složce následující existující příklady:
__C.CNTK.DATASET == "YourDataSet":
__C.CNTK.MAP_FILE_PATH = "../../DataSets/YourDataSet"
__C.CNTK.CLASS_MAP_FILE = "class_map.txt"
__C.CNTK.TRAIN_MAP_FILE = "train_img_file.txt"
__C.CNTK.TEST_MAP_FILE = "test_img_file.txt"
__C.CNTK.TRAIN_ROI_FILE = "train_roi_file.txt"
__C.CNTK.TEST_ROI_FILE = "test_roi_file.txt"
__C.CNTK.NUM_TRAIN_IMAGES = 500
__C.CNTK.NUM_TEST_IMAGES = 200
__C.CNTK.PROPOSAL_LAYER_SCALES = [8, 16, 32]
Všimněte si, že __C.CNTK.PROPOSAL_LAYER_SCALES se nepoužívá pro fast R-CNN, pouze pro Rychlejší R-CNN.
Trénování a vyhodnocení rychlé sítě R-CNN u dat změní metodu dataset_cfgget_configuration()run_fast_rcnn.py na
from utils.configs.MyDataSet_config import cfg as dataset_cfg
a spusťte python run_fast_rcnn.py.
Technické podrobnosti
Algoritmus Fast R-CNN je vysvětlený v části Podrobnosti algoritmu společně s přehledem o tom, jak se implementuje v rozhraní API Pythonu CNTK. Tato část se zaměřuje na konfiguraci sítě Fast R-CNN a o tom, jak používat různé základní modely.
Parametry
Parametry jsou seskupené do tří částí:
- Parametry detektoru (viz
FastRCNN/FastRCNN_config.py) - Parametry sady dat (viz například
utils/configs/Grocery_config.py) - Parametry základního modelu (viz příklad
utils/configs/AlexNet_config.py)
Tři části jsou načteny a sloučeny v get_configuration() metodě v run_fast_rcnn.py. V této části probereme parametry detektoru. Parametry sady dat jsou zde popsány, základní parametry modelu zde. V následujícím příkladu projdeme nejdůležitější parametry v FastRCNN_config.py. Všechny parametry jsou v souboru také komentovány. Konfigurace používá EasyDict balíček, který umožňuje snadný přístup k vnořeným slovníkům.
# Number of regions of interest [ROIs] proposals
__C.NUM_ROI_PROPOSALS = 200 # use 2000 or more for good results
# the minimum IoU (overlap) of a proposal to qualify for training regression targets
__C.BBOX_THRESH = 0.5
# Maximum number of ground truth annotations per image
__C.INPUT_ROIS_PER_IMAGE = 50
__C.IMAGE_WIDTH = 850
__C.IMAGE_HEIGHT = 850
# Use horizontally-flipped images during training?
__C.TRAIN.USE_FLIPPED = True
# If set to 'True' conv layers weights from the base model will be trained, too
__C.TRAIN_CONV_LAYERS = True
Návrhy ROI se počítají za běhu v první epochě pomocí selektivní implementace vyhledávání z dlib balíčku. Počet vygenerovaných návrhů je řízen parametrem __C.NUM_ROI_PROPOSALS . Doporučujeme použít přibližně 2000 návrhů. Regresní hlava je vytrénována pouze na těch ROI, které mají překrývání (IoU) s uzemněnou pravdou alespoň __C.BBOX_THRESH.
__C.INPUT_ROIS_PER_IMAGE určuje maximální počet poznámek základní pravdy na obrázek. CNTK v současné době vyžaduje nastavení maximálního počtu. Pokud existuje méně poznámek, budou interně vycpané. __C.IMAGE_WIDTH a __C.IMAGE_HEIGHT jsou rozměry, které slouží ke změně velikosti a vkládání vstupních obrázků.
__C.TRAIN.USE_FLIPPED = True rozšíří trénovací data tak, že překlopí všechny obrázky každé druhé epochy, tj. první epocha bude mít všechny běžné obrázky, druhý má všechny obrázky překlopené atd. __C.TRAIN_CONV_LAYERS určuje, zda budou konvoluční vrstvy ze vstupu do konvoluční mapy funkcí natrénovány nebo opraveny. Oprava hmotností konvové vrstvy znamená, že váhy ze základního modelu se při trénování neupravují a nemění. (Můžete také určit, kolik konv vrstev chcete trénovat, viz část Použití jiného základního modelu).
# NMS threshold used to discard overlapping predicted bounding boxes
__C.RESULTS_NMS_THRESHOLD = 0.5
# If set to True the following two parameters need to point to the corresponding files that contain the proposals:
# __C.DATA.TRAIN_PRECOMPUTED_PROPOSALS_FILE
# __C.DATA.TEST_PRECOMPUTED_PROPOSALS_FILE
__C.USE_PRECOMPUTED_PROPOSALS = False
__C.RESULTS_NMS_THRESHOLD je prahová hodnota NMS použitá k zahození překrývajícího se predikovaného ohraničujícího rámečku při vyhodnocování. Nižší prahová hodnota přináší méně odebrání a tím více předpovídané ohraničující rámečky v konečném výstupu. Pokud nastavíte __C.USE_PRECOMPUTED_PROPOSALS = True čtečku, přečte předpočítaná roI z textových souborů. Používá se například pro trénování dat Pascal VOC. Názvy souborů __C.DATA.TRAIN_PRECOMPUTED_PROPOSALS_FILE a __C.DATA.TEST_PRECOMPUTED_PROPOSALS_FILE jsou zadány v Examples/Image/Detection/utils/configs/Pascal_config.py.
# The basic segmentation is performed kvals.size() times. The k parameter is set (from, to, step_size)
__C.roi_ss_kvals = (10, 500, 5)
# When doing the basic segmentations prior to any box merging, all
# rectangles that have an area < min_size are discarded. Therefore, all outputs and
# subsequent merged rectangles are built out of rectangles that contain at
# least min_size pixels. Note that setting min_size to a smaller value than
# you might otherwise be interested in using can be useful since it allows a
# larger number of possible merged boxes to be created
__C.roi_ss_min_size = 9
# There are max_merging_iterations rounds of neighboring blob merging.
# Therefore, this parameter has some effect on the number of output rectangles
# you get, with larger values of the parameter giving more output rectangles.
# Hint: set __C.CNTK.DEBUG_OUTPUT=True to see the number of ROIs from selective search
__C.roi_ss_mm_iterations = 30
# image size used for ROI generation
__C.roi_ss_img_size = 200
Výše uvedené parametry konfigurují selektivní vyhledávání knihovny dlib. Podrobnosti najdete na domovské stránce knihovny dlib. Následující další parametry se používají k filtrování generovaných ROI w.r.t. minimální a maximální boční délky, oblasti a poměru stran.
# minimum relative width/height of an ROI
__C.roi_min_side_rel = 0.01
# maximum relative width/height of an ROI
__C.roi_max_side_rel = 1.0
# minimum relative area of an ROI
__C.roi_min_area_rel = 0.0001
# maximum relative area of an ROI
__C.roi_max_area_rel = 0.9
# maximum aspect ratio of an ROI vertically and horizontally
__C.roi_max_aspect_ratio = 4.0
# aspect ratios of ROIs for uniform grid ROIs
__C.roi_grid_aspect_ratios = [1.0, 2.0, 0.5]
Pokud selektivní vyhledávání vrátí více ROI, než je požadováno, jsou náhodně vzorkovány. Pokud se v běžné mřížce vygeneruje méně ROI, vygenerují se další roI pomocí zadaného __C.roi_grid_aspect_ratios.
Použití jiného základního modelu
Chcete-li použít jiný základní model, musíte zvolit jinou konfiguraci modelu v get_configuration() metodě run_fast_rcnn.py. Hned se podporují dva modely:
# for VGG16 base model use: from utils.configs.VGG16_config import cfg as network_cfg
# for AlexNet base model use: from utils.configs.AlexNet_config import cfg as network_cfg
Ke stažení modelu VGG16 použijte skript pro stažení v :<cntkroot>/PretrainedModels
python download_model.py VGG16_ImageNet_Caffe
Pokud chcete použít jiný základní model, musíte zkopírovat například konfigurační soubor utils/configs/VGG16_config.py a upravit ho podle základního modelu:
# model config
__C.MODEL.BASE_MODEL = "VGG16"
__C.MODEL.BASE_MODEL_FILE = "VGG16_ImageNet_Caffe.model"
__C.MODEL.IMG_PAD_COLOR = [103, 116, 123]
__C.MODEL.FEATURE_NODE_NAME = "data"
__C.MODEL.LAST_CONV_NODE_NAME = "relu5_3"
__C.MODEL.START_TRAIN_CONV_NODE_NAME = "pool2" # __C.MODEL.FEATURE_NODE_NAME
__C.MODEL.POOL_NODE_NAME = "pool5"
__C.MODEL.LAST_HIDDEN_NODE_NAME = "drop7"
__C.MODEL.FEATURE_STRIDE = 16
__C.MODEL.RPN_NUM_CHANNELS = 512
__C.MODEL.ROI_DIM = 7
Pokud chcete prozkoumat názvy uzlů základního modelu, můžete použít metodu plot() z cntk.logging.graph. Upozorňujeme, že modely ResNet se v současné době nepodporují, protože sdružování roi v CNTK zatím nepodporuje průměrné sdružování roi.
Podrobnosti o algoritmu
Rychlé R-CNN
R-CNN pro detekci objektů byly poprvé prezentovány v roce 2014 RossEm Girshickem et al., a ukázaly se, že překonaly předchozí nejmodernější přístupy k jednomu z hlavních problémů rozpoznávání objektů v oblasti: Pascal VOC. Od té doby byly publikovány dva následné dokumenty, které obsahují významná vylepšení rychlosti: Fast R-CNN a Faster R-CNN.
Základní myšlenkou sítě R-CNN je vzít hlubokou neurální síť, která byla původně natrénována pro klasifikaci obrázků pomocí milionů obrázků s poznámkami a upravit ji pro účely detekce objektů. Základní myšlenka z prvního dokumentu R-CNN je znázorněna na obrázku níže (převzato z papíru): (1) Při zadání vstupního obrázku (2) v prvním kroku se vygenerují návrhy velkého počtu oblastí. (3) Tyto návrhy oblastí nebo oblasti zájmů (ROI) se pak každý nezávisle odesílá prostřednictvím sítě, která vypíše vektor například 4096 hodnot s plovoucí desetinou čárkou pro každou roI. Nakonec (4) se naučí klasifikátor, který přebírá reprezentaci 4096 float ROI jako vstup a vypíše popisek a spolehlivost každé NÁVRATNOSTI.

I když tento přístup funguje dobře z hlediska přesnosti, je velmi nákladné vypočítat, protože pro každou návratnost dat musí být vyhodnocena neurální síť. Rychlá síť R-CNN tuto nevýhodu řeší pouze vyhodnocením většiny sítě (aby byla specifická: konvoluční vrstvy) na jeden čas na obrázek. Podle autorů to vede k 213násobné zrychlení během testování a 9x zrychlení během trénování bez ztráty přesnosti. Toho dosáhnete pomocí vrstvy fondu ROI, která promítá NÁVRATNOSTI na konvoluční mapu funkcí a provede maximální sdružování, aby se vygenerovala požadovaná výstupní velikost, kterou očekává následující vrstva.
V příkladu AlexNetu použitém v tomto kurzu se vrstva sdružování ROI umístí mezi poslední konvoluční vrstvu a první plně propojenou vrstvu. V kódu rozhraní CNTK Python API zobrazeném níže je to realizováno klonováním dvou částí sítě, a conv_layers .fc_layers Vstupní obrázek se pak nejprve normalizuje, prosadí vrstvu conv_layers, vrstvu roipooling a fc_layers nakonec predikci a regresní hlavy se přidají, které predikují popisek třídy a regresní koeficienty na kandidátské ROI.
def create_fast_rcnn_model(features, roi_proposals, label_targets, bbox_targets, bbox_inside_weights, cfg):
# Load the pre-trained classification net and clone layers
base_model = load_model(cfg['BASE_MODEL_PATH'])
conv_layers = clone_conv_layers(base_model, cfg)
fc_layers = clone_model(base_model, [cfg["MODEL"].POOL_NODE_NAME], [cfg["MODEL"].LAST_HIDDEN_NODE_NAME], clone_method=CloneMethod.clone)
# Normalization and conv layers
feat_norm = features - Constant([[[v]] for v in cfg["MODEL"].IMG_PAD_COLOR])
conv_out = conv_layers(feat_norm)
# Fast RCNN and losses
cls_score, bbox_pred = create_fast_rcnn_predictor(conv_out, roi_proposals, fc_layers, cfg)
detection_losses = create_detection_losses(...)
pred_error = classification_error(cls_score, label_targets, axis=1)
return detection_losses, pred_error
def create_fast_rcnn_predictor(conv_out, rois, fc_layers, cfg):
# RCNN
roi_out = roipooling(conv_out, rois, cntk.MAX_POOLING, (6, 6), spatial_scale=1/16.0)
fc_out = fc_layers(roi_out)
# prediction head
cls_score = plus(times(fc_out, W_pred), b_pred, name='cls_score')
# regression head
bbox_pred = plus(times(fc_out, W_regr), b_regr, name='bbox_regr')
return cls_score, bbox_pred
Původní implementace Caffe použitá v dokumentech R-CNN najdete na GitHubu: RCNN, Fast R-CNN a Faster R-CNN.
Trénování SVM vs. NN
Patrick Buehler poskytuje pokyny, jak vytrénovat SVM na výstupu CNTK Fast R-CNN (pomocí funkcí 4096 z poslední plně připojené vrstvy), stejně jako diskuzi o pros a nevýhody zde.
Selektivní vyhledávání
Selektivní vyhledávání je metoda pro vyhledání velké sady možných umístění objektů na obrázku nezávisle na třídě skutečného objektu. Funguje tak, že seskupí obrazové pixely do segmentů a pak provede hierarchické clusteringy, aby zkombinoval segmenty ze stejného objektu do návrhů objektů.



Abychom doplnili zjištěné návratnosti z selektivního vyhledávání, přidáme roi, které uniformují obrázek v různých měřítkech a poměrech stran. Obrázek vlevo ukazuje příklad výstupu selektivního vyhledávání, kde je každé možné umístění objektu vizualizováno zeleným obdélníkem. ROI, které jsou příliš malé, příliš velké atd. jsou zahozeny (uprostřed) a nakonec roi, které rovnoměrně pokrývají obrázek, se přidají (vpravo). Tyto obdélníky se pak používají jako oblasti zájmu (ROI) v kanálu R-CNN.
Cílem generování ROI je najít malou sadu ROI, které však úzce pokrývají co nejvíce objektů na obrázku. Tento výpočet musí být dostatečně rychlý, zatímco současně vyhledá umístění objektů v různých měřítkech a poměrech stran. Selektivní vyhledávání bylo pro tuto úlohu zobrazeno dobře, s dobrou přesností pro urychlení kompromisů.
NMS (bez maximálního potlačení)
Metody detekce objektů často vypisují více detekcí, které plně nebo částečně pokrývají stejný objekt na obrázku.
Tyto návratnosti dat je potřeba sloučit, aby bylo možné spočítat objekty a získat jejich přesná umístění na obrázku.
To se tradičně provádí pomocí techniky, která se nazývá Non Maximum Potlačení (NMS). Verze NMS, kterou používáme (a která byla také použita v publikacích R-CNN), nesloučí roI, ale místo toho se snaží identifikovat, které roi nejlépe pokrývají skutečné umístění objektu a zahodí všechny ostatní ROI. To je implementováno iterativním výběrem roI s nejvyšší jistotou a odebráním všech ostatních ROI, které výrazně překrývají tuto NÁVRATNOSTI a jsou klasifikovány jako stejné třídy. Prahovou hodnotu pro překrytí je možné nastavit v PARAMETERS.py (podrobnosti).
Výsledky detekce před (vlevo) a za (vpravo) Bez maximálního potlačení:


mAP (střední průměrná přesnost)
Po vytrénování lze kvalitu modelu měřit pomocí různých kritérií, jako je přesnost, úplnost, přesnost, oblast podkřivení atd. Běžnou metrikou, která se používá pro výzvu rozpoznávání objektů Pascal VOC, je měřit průměrnou přesnost (AP) pro každou třídu. Následující popis průměrné přesnosti je převzat z Everingham et. al. Střední průměrná přesnost (mAP) se vypočítá tak, že převezme průměr nad APS všech tříd.
U daného úkolu a třídy se křivka přesnosti a úplnosti vypočítá z seřazeného výstupu metody. Úplnost je definována jako podíl všech pozitivních příkladů seřazených nad daným pořadím. Přesnost je podíl všech příkladů výše uvedených pořadí, které jsou z kladné třídy. Ap shrnuje tvar křivky přesnosti a úplnosti a je definován jako střední přesnost na sadě rovnoměrně rozmístěných úrovní úplnosti [0,0,1, . . . ,1]:
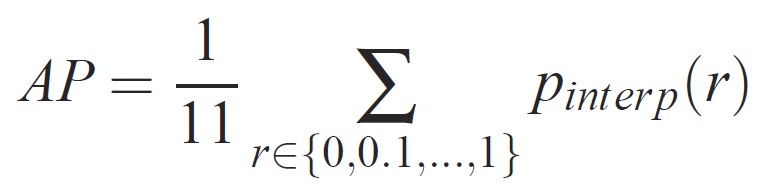
Přesnost na každé úrovni úplnosti r je interpolována pomocí maximální přesnosti měřené pro metodu, pro kterou odpovídající úplnost překračuje r:
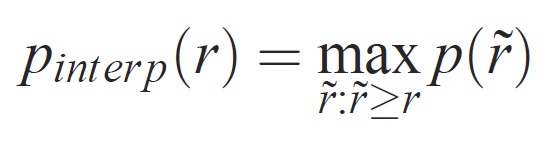
kde p( ̃r) je naměřená přesnost při úplnosti ̃r. Záměrem interpolace křivky přesnosti a úplnosti tímto způsobem je snížit dopad "vlnovek" v křivkě přesnosti a úplnosti způsobené malými variacemi v pořadí příkladů. Je třeba poznamenat, že pokud chcete získat vysoké skóre, musí mít metoda přesnost na všech úrovních úplnosti – tato penalizuje metody, které načítají pouze podmnožinu příkladů s vysokou přesností (např. zobrazení na straně automobilů).