Doporučení pro reakci na bezpečnostní incidenty
Platí pro Power Platform Doporučení kontrolního seznamu s dobrou architekturou:
| SE:11 | Definujte a otestujte efektivní postupy reakce na incidenty, které pokrývají spektrum incidentů, od lokalizovaných problémů až po zotavení po havárii. Jasně definujte, který tým nebo jednotlivec provádí proceduru. |
|---|
Tato příručka popisuje doporučení pro implementaci reakce na bezpečnostní incident pro úlohu. Pokud dojde k ohrožení zabezpečení systému, přístup systematické odezvy na incidenty pomáhá zkrátit čas potřebný k identifikaci, správě a řešení bezpečnostních incidentů. Tyto incidenty mohou ohrozit důvěrnost, integritu a dostupnost softwarových systémů a dat.
Většina podniků má centrální bezpečnostní operační tým (označovaný také jako Security Operations Center [SOC] nebo SecOps). Odpovědností bezpečnostního provozního týmu je rychle odhalit, stanovit priority a třídit potenciální útoky. Tým také monitoruje telemetrická data související se zabezpečením a vyšetřuje narušení bezpečnosti.
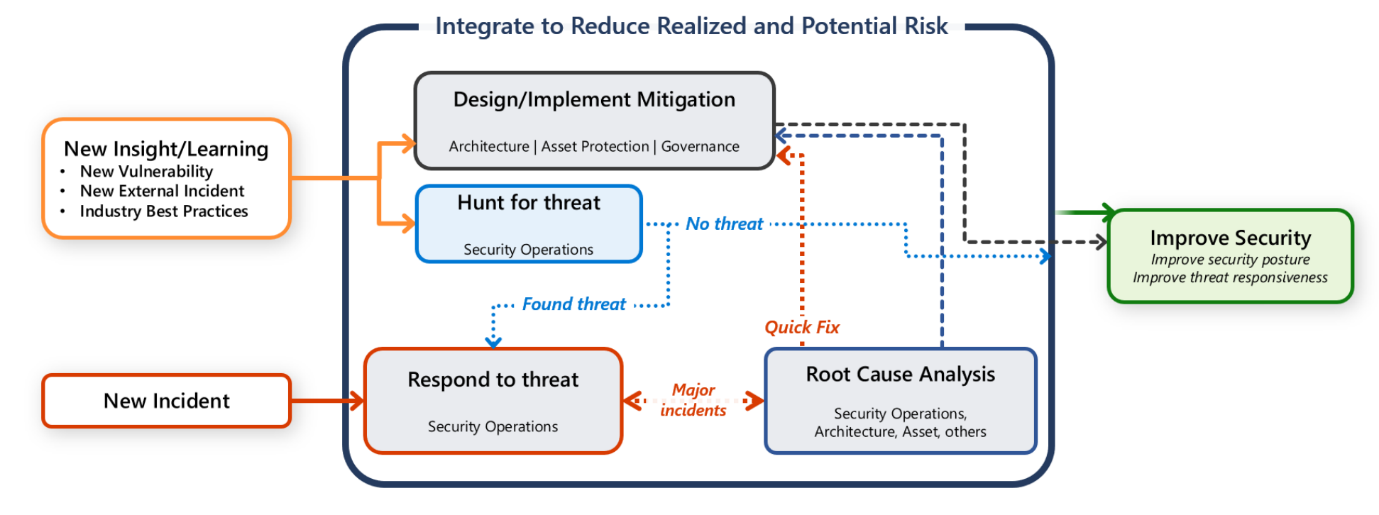
Máte však také odpovědnost za ochranu své úlohy. Je důležité, aby veškerá komunikace, vyšetřování a aktivity proaktivního vyhledávání byly výsledkem spolupráce mezi týmem pro pracovní zátěž a týmem SecOps.
Tato příručka obsahuje doporučení pro vás a váš tým pro úlohu, která vám pomohou rychle odhalit, třídit a vyšetřovat útoky.
Definice
| Pojem | definice |
|---|---|
| Výstraha | Oznámení, které obsahuje informace o incidentu. |
| Věrnost upozornění | Přesnost údajů, které určují výstrahu. Vysoce věrné výstrahy obsahují kontext zabezpečení, který je nutný k provedení okamžitých akcí. Výstrahy s nízkou věrností postrádají informace nebo obsahují šum. |
| Falešně pozitivní | Upozornění, které označuje incident, který se nestal. |
| Incident | Událost, která označuje neoprávněný přístup do systému. |
| Reakce na incident | Proces, který detekuje, reaguje a řeší rizika spojená s incidentem. |
| Posouzení | Operace reakce na incidenty, která analyzuje bezpečnostní problémy a upřednostňuje jejich řešení. |
Klíčové strategie návrhu
Vy a váš tým provádíte operace reakce na incidenty, když signál nebo výstraha naznačuje potenciální bezpečnostní incident. Vysoce věrné výstrahy obsahují rozsáhlý bezpečnostní kontext, který analytikům usnadňuje rozhodování. Vysoce věrné výstrahy mají za následek nízký počet falešně pozitivních výsledků. Tato příručka předpokládá, že výstražný systém filtruje signály s nízkou přesností a zaměřuje se na výstrahy s vysokou přesností, které mohou naznačovat skutečný incident.
Přiřazení oznámení o incidentu
Bezpečnostní výstrahy se musí dostat k příslušným lidem ve vašem týmu a ve vaší organizaci. Vytvořte si ve svém týmu pro úlohu určený kontaktní bod, který bude dostávat oznámení o incidentech. Tato oznámení by měla obsahovat co nejvíce informací o ohroženém zdroji a systému. Upozornění musí obsahovat další kroky, aby váš tým mohl urychlit akce.
Doporučujeme, abyste protokolovali a spravovali oznámení a akce o incidentech pomocí specializovaných nástrojů, které uchovávají auditní záznam. Pomocí standardních nástrojů můžete uchovat důkazy, které mohou být vyžadovány pro případná právní vyšetřování. Hledejte příležitosti k implementaci automatizace, která může zasílat upozornění na základě odpovědnosti odpovědných stran. Udržujte jasný řetězec komunikace a hlášení během incidentu.
Využijte řešení bezpečnostních informací správa akcí (SIEM) a řešení pro automatizovanou odezvu SOAR (SOAR), které vaše organizace poskytuje. Případně si můžete pořídit nástroje pro správu incidentů a povzbudit svou organizaci, aby je standardizovala pro všechny týmy úlohy.
Vyšetřování s týmem určujícím priority
Člen týmu, který obdrží oznámení o incidentu, je odpovědný za nastavení procesu stanovení priority, který zahrnuje příslušné osoby na základě dostupných dat. Tým pro stanovení priority, často označovaný překlenovací tým, se musí dohodnout na způsobu a procesu komunikace. Vyžaduje tento incident asynchronní diskuse nebo přemostěná volání? Jak by měl tým sledovat a sdělovat průběh vyšetřování? Kde má tým přístup k prostředkům, kterých se incident týká?
Reakce na incidenty je zásadním důvodem pro udržování aktuální dokumentace, jako je architektonické uspořádání systému, informace na úrovni komponent, klasifikace ochrany osobních údajů nebo zabezpečení, vlastníci a klíčové kontaktní body. Pokud jsou informace nepřesné nebo zastaralé, překlenovací tým ztrácí drahocenný čas snahou porozumět tomu, jak systém funguje, kdo je odpovědný za jednotlivé oblasti a jaký by mohl být účinek události.
Pro další vyšetřování zapojte příslušné osoby. Můžete zahrnout manažera incidentů, bezpečnostního pracovníka nebo vedoucí zaměřené na úlohu. Aby zůstalo stanovování prioritu zaměřené, vylučte lidi, kteří jsou mimo rozsah problému. Někdy incident vyšetřují samostatné týmy. Může existovat tým, který zpočátku problém vyšetřuje a pokusí se incident vyřešit, a další specializovaný tým, který by mohl provádět forenzní vyšetřování za účelem hloubkového vyšetřování, aby zjistil rozsáhlé problémy. Prostředí úlohy můžete umístit do karantény, a umožnit tak forenznímu týmu provádět vyšetřování. V některých případech může celé vyšetřování zvládnout stejný tým.
V počáteční fázi je tým pro určování priorit zodpovědný za určení potenciálního vektoru a jeho vlivu na důvěrnost, integritu a dostupnost (nazývané také CIA) systému.
V rámci kategorií CIA přiřaďte počáteční úroveň závažnosti, která udává hloubku poškození a naléhavost nápravy. Očekává se, že se tato úroveň časem změní, jak bude v úrovních stanovování priorit objeveno více informací.
Ve fázi objevování je důležité určit okamžitý postup a komunikační plány. Došlo k nějakým změnám v provozním stavu systému? Jak lze útok potlačit, aby se zastavilo další poškozování? Potřebuje tým odesílat interní nebo externí komunikaci, jako je zodpovědné zveřejnění? Zvažte dobu detekce a odezvy. Můžete být ze zákona povinni nahlásit některé typy porušení regulačnímu úřadu během určitého časového období, což jsou často hodiny nebo dny.
Pokud se rozhodnete vypnout systém, vedou další kroky k procesu obnovy po havárii (DR) úlohy.
Pokud systém nevypnete, určete, jak incident napravit, aniž by to ovlivnilo funkčnost systému.
Obnova z incidentu
Zacházejte s bezpečnostním incidentem jako s katastrofou. Pokud náprava vyžaduje úplnou obnovu, použijte z hlediska zabezpečení správné mechanismy DR. Proces obnovy musí zabránit možnosti opakování. V opačném případě obnova z poškozené zálohy znovu zavede problém. Opětovné nasazení systému se stejnou zranitelností vede ke stejnému incidentu. Ověřte kroky a procesy převzetí služeb při selhání a navrácení služeb při selhání.
Pokud systém zůstane funkční, zhodnoťte vliv na běžící části systému. Pokračujte v monitorování systému, abyste se ujistili, že jsou splněny další cíle spolehlivosti a výkonu nebo je znovu upravte implementací správných degradačních procesů. Neohrožujte osobní údaje kvůli nápravě.
Diagnostika je interaktivní proces, dokud není identifikován vektor a potenciální oprava a záložní řešení. Po diagnostice tým pracuje na nápravě, která identifikuje a aplikuje požadovanou opravu v přijatelné lhůtě.
Metriky obnovy měří, jak dlouho trvá vyřešení problému. V případě odstávky může dojít k naléhavosti ohledně doby nápravy. Stabilizace systému vyžaduje čas na použití oprav, záplat a testů a nasazení aktualizací. Určete strategie zabránění šíření, abyste zabránili dalším škodám a šíření incidentu. Vyviňte eradikační postupy k úplnému odstranění hrozby z prostředí.
Kompromis: Existuje kompromis mezi cíli spolehlivosti a dobou nápravy. Během incidentu je pravděpodobné, že nesplňujete další nefunkční nebo funkční požadavky. Můžete například potřebovat deaktivovat části vašeho systému, když vyšetřujete incident, nebo dokonce budete muset přepnout celý systém do režimu offline, dokud nezjistíte rozsah incidentu. Osoby s rozhodovací pravomocí musí během incidentu výslovně rozhodnout, jaké jsou přijatelné cíle. Jasně uveďte osobu, která je za toto rozhodnutí odpovědná.
Poučení z incidentu
Incident odhaluje mezery nebo zranitelná místa v návrhu nebo implementaci. Je to příležitost ke zlepšení, která vychází z lekcí technických aspektů návrhu, automatizace, procesů vývoje produktů, které zahrnují testování, a efektivity procesu reakce na incidenty. Udržujte podrobné záznamy o incidentech, včetně přijatých akcí, časových plánů a zjištění.
Důrazně doporučujeme, abyste provedli strukturované kontroly po incidentu, jako je analýza hlavních příčin a retrospektivy. Sledujte a stanovte priority výsledků těchto revizí a zvažte použití toho, co se naučíte, v budoucích návrzích úlohy.
Plány vylepšení by měly zahrnovat aktualizace bezpečnostních cvičení a testování, jako jsou cvičení pro kontinuitu provozu a zotavení po havárii (BCDR). Použijte bezpečnostní narušení jako scénář pro provedení cvičení BCDR. Cvičení mohou ověřit, jak zdokumentované procesy fungují. Nemělo by existovat více příruček pro reakce na incidenty. Použijte jeden zdroj, který můžete upravit na základě velikosti incidentu a toho, jak rozšířený nebo lokalizovaný je účinek. Cvičení jsou založena na hypotetických situacích. Provádějte cvičení v prostředí s nízkým rizikem a zahrňte do cvičení fázi učení.
Provádějte kontroly po incidentu nebo pitvu, abyste identifikovali slabá místa v procesu reakce a oblasti pro zlepšení. Na základě lekcí, které se z incidentu dozvíte, aktualizujte plán reakce na incident (IRP) a bezpečnostní kontroly.
Odešlete potřebnou komunikaci
Implementujte komunikační plán, který upozorní uživatele na narušení a informuje interní zainteresované strany o nápravě a zlepšení. Ostatní lidé ve vaší organizaci musí být informováni o všech změnách základní úrovně zabezpečení úlohy, aby se předešlo budoucím incidentům.
Vytvářejte zprávy o incidentech pro interní použití a v případě potřeby pro dodržování předpisů nebo právní účely. Přijměte také standardní formát zprávy (šablona dokumentu s definovanými sekcemi), kterou tým SOC používá pro všechny incidenty. Před uzavřením vyšetřování se ujistěte, že ke každému incidentu je přidružena zpráva.
Usnadnění díky Power Platform
Následující části popisují mechanismy, které můžete použít jako součást vašich postupů reakce na bezpečnostní incidenty.
Microsoft Sentinel
Řešení Microsoft Sentinel pro Microsoft Power Platform umožňuje zákazníkům detekovat různé podezřelé aktivity, jako jsou:
- Provádění Power Apps z neautorizovaných geografických oblastí
- Podezřelé zničení dat z Power Apps
- Hromadné odstranění Power Apps
- Phishingové útoky provedené přes Power Apps
- Aktivita toků Power Automate odcházejícími zaměstnanci
- Konektory Microsoft Power Platform používané do prostředí
- Aktualizace nebo odstranění zásad prevence ztráty dat Microsoft Power Platform
Další informace naleznete v části Přehled řešení Microsoft Sentinel pro Microsoft Power Platform.
Protokolování aktivit Microsoft Purview
Protokolování aktivity Power Apps, Power Automate, konektorů, prevence ztráty dat a správy Power Platformje sledováno a prohlíženo z portálu pro dodržování předpisů Microsoft Purview.
Další informace naleznete v tématu:
- Power Apps protokolování aktivity
- Power Automate protokolování aktivity
- Copilot Studio protokolování aktivity
- Power Pages protokolování aktivity
- Power Platform protokolování aktivity konektoru
- Protokolování aktivity prevence ztráty dat
- Power Platform protokolování činnosti administrativních akcí
- Microsoft Dataverse a protokolování aktivit aplikací řízených modelem
Customer Lockbox
Většina operací, podpory a řešení problémů prováděných pracovníky společnosti Microsoft (včetně dílčích zpracovatelů) nevyžaduje přístup k údajům zákazníka. S Power Platform Customer Lockbox Microsoft poskytuje rozhraní pro zákazníky, kde mohou kontrolovat a schvalovat (nebo zamítat) žádosti o přístup k údajům ve vzácných případech, kdy je potřeba získat přístup k údajům zákazníka. Používá se v případech, kdy technik společnosti Microsoft potřebuje získat přístup k zákaznickým datům, ať už v reakci na zákaznický lístek podpory nebo problém identifikovaný společností Microsoft. Další informace viz Bezpečný přístup k zákaznickým datům pomocí Customer Lockbox v Power Platform a Dynamics 365.
Aktualizace zabezpečení
Servisní týmy pravidelně provádějí následující pro zajištění zabezpečení systému:
- Kontrola služby za účelem identifikace slabých míst zabezpečení.
- Hodnocení služby pro zajištění efektivnosti důležitých ovládacích prvků zabezpečení.
- Hodnocení služby za účelem určení vystavení slabým stránkám identifikovaným střediskem Microsoft Security Response Center (MSRC), které pravidelně sleduje externí weby zabývajícími se informováním o slabých stránkách.
Tyto týmy také identifikují a sledují identifikované problémy a je-li třeba, snaží se o jejich rychlou nápravu a mírnění rizik.
Jak se dovím o aktualizacích zabezpečení?
Protože se servisní tým snaží zmírňovat rizika tak, aby nevyžadovaly výpadky služeb, správci obvykle neobdrží oznámení centra zpráv ohledně aktualizací zabezpečení. Pokud aktualizace zabezpečení vyžadují servisní zákrok, ten je považován za plánovanou údržbu a bude zveřejněn s odhadovanou dobou trvání a časovým rozsahem, kdy dojde k práci.
Další informace o zabezpečení získáte v části Centrum zabezpečení Microsoft.
Správa vašeho časového období údržby
Společnost Microsoft provádí aktualizace a údržbu, aby byla zajištěna jejich bezpečnost, výkon a dostupnost a bylo možné poskytovat nové vlastnosti a funkce. Tento proces aktualizace přináší zabezpečení a drobná vylepšení služeb na týdenní bázi, přičemž každá aktualizace zavádí region po regionu podle plánu bezpečného nasazení, uspořádaného ve stanicích. Informace o výchozím okně údržby pro prostředí naleznete v článku Zásady a komunikace při servisních incidentech. Viz také Správa časového období údržby.
Zajistěte, aby portál zavádění Azure obsahoval kontaktní informace správce, aby bylo možné o operacích zabezpečení informovat přímo prostřednictvím interního procesu. Další informace získáte v tématu Aktualizace nastavení oznámení.
Organizační sladění
Cloud Adoption Framework pro Azure poskytuje pokyny k plánování reakce na incidenty a operacím zabezpečení. Další informace najdete v článku Provoz zabezpečení.
Související informace
- Microsoft Řešení Sentinel pro Microsoft Power Platform přehled
- Automaticky vytvářet incidenty z Microsoft bezpečnostních výstrah
- Provádějte komplexní vyhledávání hrozeb pomocí funkce Hony
- Použijte Hunts k provádění komplexního proaktivního hledání hrozeb v Microsoft Sentinel
- Přehled události odpověď
Kontrolní seznam zabezpečení
Podívejte se na úplný soubor doporučení.