Pokyny ke složenému modelu v Power BI Desktopu
Tento článek se zaměřuje na modelátory dat, kteří vyvíjejí složené modely Power BI. Popisuje případy použití složeného modelu a poskytuje pokyny k návrhu. Konkrétně vám pokyny můžou pomoct určit, jestli je složený model vhodný pro vaše řešení. Pokud ano, pomůže vám tento článek také navrhnout optimální složené modely a sestavy.
Poznámka:
V tomto článku se nezabýváme úvodem ke složeným modelům. Pokud složené modely úplně neznáte, doporučujeme, abyste si nejdřív přečetli článek o použití složených modelů v Power BI Desktopu .
Vzhledem k tomu, že složené modely se skládají z alespoň jednoho zdroje DirectQuery, je také důležité, abyste důkladně porozuměli relacím modelů, modelům DirectQuery a pokynům k návrhu modelu DirectQuery.
Případy použití složeného modelu
Složený model podle definice kombinuje více zdrojových skupin. Zdrojová skupina může představovat importovaná data nebo připojení ke zdroji DirectQuery. Zdrojem DirectQuery může být relační databáze nebo jiný tabulkový model, což může být sémantický model Power BI nebo tabulkový model Analysis Services. Když se tabulkový model připojí k jinému tabulkovému modelu, označuje se jako řetězení. Další informace najdete v tématu Použití DirectQuery pro sémantické modely Power BI a Analysis Services.
Poznámka:
Když se model připojí k tabulkovému modelu, ale neprodlouží ho dalšími daty, nejedná se o složený model. V tomto případě se jedná o model DirectQuery, který se připojuje ke vzdálenému modelu, takže se skládá jenom z jedné zdrojové skupiny. Tento typ modelu můžete vytvořit pro úpravu vlastností objektu zdrojového modelu, jako je název tabulky, pořadí řazení sloupců nebo formátovací řetězec.
Připojení k tabulkovým modelům je zvlášť důležité při rozšiřování podnikového sémantického modelu (pokud se jedná o sémantický model Power BI nebo model Analysis Services). Podnikový sémantický model je zásadní pro vývoj a provoz datového skladu. Poskytuje abstrakční vrstvu nad daty v datovém skladu, která představuje definice a terminologii firmy. Běžně se používá jako propojení mezi fyzickými datovými modely a nástroji pro vytváření sestav, jako je Power BI. Ve většině organizací je spravován centrálním týmem a proto se popisuje jako podnik. Další informace najdete ve scénáři použití podnikového BI .
V následujících situacích můžete zvážit vývoj složeného modelu.
- Vaším modelem může být model DirectQuery a chcete zvýšit výkon. Ve složeného modelu můžete zvýšit výkon nastavením vhodného úložiště pro každou tabulku. Můžete také přidat uživatelem definované agregace. Obě tyto optimalizace jsou popsány dále v tomto článku.
- Chcete zkombinovat model DirectQuery s více daty, která se musí importovat do modelu. Importovaná data můžete načíst z jiného zdroje dat nebo z počítaných tabulek.
- Chcete zkombinovat dva nebo více zdrojů dat DirectQuery do jednoho modelu. Těmito zdroji můžou být relační databáze nebo jiné tabulkové modely.
Poznámka:
Složené modely nemůžou zahrnovat připojení k určitým externím analytickým databázím. Mezi tyto databáze patří SAP Business Warehouse a SAP HANA při zacházení se SAP HANA jako s multidimenzionálním zdrojem.
Vyhodnocení dalších možností návrhu modelu
Složené modely Power BI sice můžou řešit konkrétní problémy návrhu, ale můžou přispět k nízkému výkonu. V některých situacích může dojít také k neočekávaným výsledkům výpočtu (popsané dále v tomto článku). Z těchto důvodů vyhodnoťte další možnosti návrhu modelu, pokud existují.
Kdykoli je to možné, je nejlepší vyvíjet model v režimu importu. Tento režim poskytuje největší flexibilitu návrhu a nejlepší výkon.
Problémy související s velkými objemy dat nebo vytvářením sestav dat téměř v reálném čase ale nemusí být vždy vyřešeny modely importu. V některém z těchto případů můžete zvážit model DirectQuery, který poskytuje, že vaše data jsou uložená v jednom zdroji dat, který podporuje režim DirectQuery. Další informace najdete v tématu Modely DirectQuery v Power BI Desktopu.
Tip
Pokud vaším cílem je rozšířit existující tabulkový model o více dat, kdykoli je to možné, přidejte tato data do existujícího zdroje dat.
Režim úložiště tabulek
Ve složeného modelu můžete nastavit režim úložiště pro každou tabulku (kromě počítaných tabulek).
- DirectQuery: Doporučujeme nastavit tento režim pro tabulky, které představují velké objemy dat nebo které potřebují poskytovat výsledky téměř v reálném čase. Data se do těchto tabulek nikdy nenaimportují. Obvykle se jedná o tabulky typu fakta, což jsou tabulky, které jsou shrnuté.
- Import: Doporučujeme nastavit tento režim pro tabulky, které se nepoužívají k filtrování a seskupování tabulek faktů v režimu DirectQuery nebo Hybrid. Je to také jediná možnost pro tabulky založené na zdrojích, které režim DirectQuery nepodporuje. Počítané tabulky jsou vždy importované tabulky.
- Duální: Doporučujeme nastavit tento režim pro tabulky typu dimenze, pokud existuje možnost, že se budou dotazovat společně s tabulkami faktů DirectQuery ze stejného zdroje.
- Hybridní: Doporučujeme nastavit tento režim přidáním oddílů importu a jednoho oddílu DirectQuery do tabulky faktů, pokud chcete zahrnout nejnovější změny dat v reálném čase nebo když chcete zajistit rychlý přístup k nejčastěji používaným datům prostřednictvím oddílů importu a zároveň ponechat většinu zřídka používaných dat v datovém skladu.
Existuje několik možných scénářů, kdy Power BI dotazuje složený model.
- Dotazy importují pouze nebo duální tabulky: Power BI načte všechna data z mezipaměti modelu. Bude poskytovat nejrychlejší možný výkon. Tento scénář je běžný pro tabulky dimenzí dotazované filtry nebo vizuály průřezů.
- Dotazy se dvěma tabulkami nebo tabulkami DirectQuery ze stejného zdroje: Power BI načte všechna data odesláním jednoho nebo více nativních dotazů do zdroje DirectQuery. Bude poskytovat dobrý výkon, zejména pokud existují vhodné indexy ve zdrojových tabulkách. Tento scénář je běžný u dotazů, které souvisejí s tabulkami dvou dimenzí a tabulkami typu fakta DirectQuery. Tyto dotazy jsou uvnitř zdrojové skupiny, takže všechny relace 1:1 nebo 1:N se vyhodnocují jako běžné relace.
- Dotazy se dvěma tabulkami nebo hybridními tabulkami ze stejného zdroje: Tento scénář je kombinací předchozích dvou scénářů. Power BI načte data z mezipaměti modelu, když je k dispozici v oddílech importu, jinak odešle jeden nebo více nativních dotazů do zdroje DirectQuery. Bude poskytovat nejrychlejší možný výkon, protože ve zdrojové tabulce se dotazuje pouze řez dat, zejména pokud ve zdrojových tabulkách existují vhodné indexy. Pokud jde o tabulky typu duální dimenze a tabulky faktů DirectQuery, jsou tyto dotazy uvnitř zdrojové skupiny, takže všechny relace 1:1 nebo 1:N se vyhodnocují jako běžné relace.
- Všechny ostatní dotazy: Tyto dotazy zahrnují relace mezi zdrojovými skupinami. Je to buď proto, že tabulka importu souvisí s tabulkou DirectQuery, nebo se duální tabulka vztahuje k tabulce DirectQuery z jiného zdroje – v takovém případě se chová jako importovaná tabulka. Všechny relace se vyhodnocují jako omezené relace. Také to znamená, že seskupení použitá u tabulek bez DirectQuery musí být odeslána do zdroje DirectQuery jako materializované poddotazy (virtuální tabulky). V tomto případě může být nativní dotaz neefektivní, zejména pro velké sady seskupení.
V souhrnu doporučujeme:
- Pečlivě zvažte, že složený model je správným řešením – zatímco umožňuje integraci různých zdrojů dat na úrovni modelu, zavádí také složitost návrhu s možnými důsledky (popsané dále v tomto článku).
- Režim úložiště nastavte na DirectQuery , pokud je tabulka typu fakta, která ukládá velké objemy dat nebo kdy potřebuje poskytovat výsledky téměř v reálném čase.
- Zvažte použití hybridního režimu definováním zásad přírůstkové aktualizace a dat v reálném čase nebo rozdělením tabulky faktů pomocí TOM, TMSL nebo nástroje třetí strany. Další informace najdete v tématu Přírůstková aktualizace a data v reálném čase pro sémantické modely a scénář použití pokročilé správy datových modelů.
- Pokud je tabulka tabulka typu dimenze, nastavte režim úložiště na duální a dotazuje se společně s tabulkami DirectQuery nebo hybridními tabulkami faktů, které jsou ve stejné zdrojové skupině.
- Nastavte příslušné frekvence aktualizace, aby byla mezipaměť modelu pro duální a hybridní tabulky (a všechny závislé počítané tabulky) synchronizované se zdrojovými databázemi.
- Snažte se zajistit integritu dat napříč zdrojovými skupinami (včetně mezipaměti modelu), protože omezené relace eliminují řádky ve výsledcích dotazu, pokud se související hodnoty sloupců neshodují.
- Kdykoli je to možné, optimalizujte zdroje dat DirectQuery s příslušnými indexy pro efektivní spojení, filtrování a seskupení.
Uživatelem definované agregace
Do tabulek DirectQuery můžete přidat uživatelem definované agregace . Jejich účelem je zlepšit výkon dotazů s vyššími úrovněmi .
Když jsou agregace v modelu uložené v mezipaměti, chovají se jako importované tabulky (i když se nedají použít jako tabulka modelu). Přidání agregací importu do modelu DirectQuery způsobí složený model.
Poznámka:
Hybridní tabulky nepodporují agregace, protože některé oddíly fungují v režimu importu. Agregace není možné přidat na úrovni jednotlivého oddílu DirectQuery.
Doporučujeme agregaci použít základní pravidlo: Počet řádků by měl být alespoň faktor 10 menší než podkladová tabulka. Pokud například podkladová tabulka uchovává 1 miliardu řádků, neměla by tabulka agregace překročit 100 milionů řádků. Toto pravidlo zajišťuje, že vzhledem k nákladům na vytvoření a údržbu agregace dojde k přiměřenému zvýšení výkonu.
Vztahy mezi zdrojovými skupinami
Když relace modelu zahrnuje zdrojové skupiny, označuje se jako relace mezi zdrojovými skupinami. Relace mezi zdrojovými skupinami jsou také omezené , protože neexistuje žádná zaručená "jedna" strana. Další informace naleznete v tématu Vyhodnocení relace.
Poznámka:
V některých situacích se můžete vyhnout vytvoření relace mezi zdrojovými skupinami. Další informace najdete v tématu Použití synchronizačních průřezů dále v tomto článku.
Při definování relací mezi zdrojovými skupinami zvažte následující doporučení.
- Používejte sloupce relací s nízkou kardinalitou: Pro zajištění nejlepšího výkonu doporučujeme, aby sloupce relace měly mít nízkou kardinalitu, což znamená, že by měly obsahovat méně než 50 000 jedinečných hodnot. Toto doporučení platí zejména při kombinování tabulkových modelů a pro netextové sloupce.
- Nepoužívejte velké sloupce relace textu: Pokud je nutné použít textové sloupce v relaci, vypočítejte očekávanou délku textu filtru vynásobením kardinality průměrnou délkou textového sloupce. Možná délka textu by neměla překročit 1 000 000 znaků.
- Zvýšení členitosti relace: Pokud je to možné, vytvořte relace na vyšší úrovni členitosti. Místo použití tabulky kalendářních dat ve svém klíči kalendářního data použijte místo toho jeho klíč měsíce. Tento přístup k návrhu vyžaduje, aby související tabulka obsahovala klíčový sloupec měsíce a sestavy nebudou moct zobrazovat denní fakta.
- Snažte se dosáhnout jednoduchého návrhu relace: Vytvořte pouze relaci mezi zdrojovými skupinami v případě potřeby a pokuste se omezit počet tabulek v cestě relace. Tento přístup k návrhu pomůže zlepšit výkon a vyhnout se nejednoznačným cestám relací.
Upozorňující
Vzhledem k tomu, že Power BI Desktop důkladně neověřuje relace mezi zdrojovými skupinami, je možné vytvořit nejednoznačné relace.
Scénář vztahu mezi zdrojovými skupinami 1
Představte si scénář složitého návrhu relace a způsobu, jakým by mohl vést k různým ( ale platným) výsledkům.
V tomto scénáři má tabulka Oblast ve zdrojové skupině A relaci s tabulkou Date (Datum) a Sales (Prodej) ve zdrojové skupině B. Relace mezi tabulkou Oblast a tabulkou Date je aktivní, zatímco relace mezi tabulkou Oblast a tabulka Sales je neaktivní. Mezi tabulkou Oblast a tabulkou Sales je také aktivní relace, z nichž obě jsou ve zdrojové skupině B. Tabulka Sales obsahuje míru s názvem TotalSales a tabulka Region obsahuje dvě míry s názvem RegionalSales a RegionalSalesDirect.
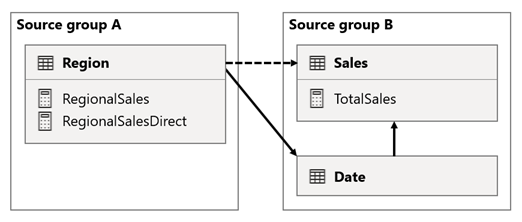
Tady jsou definice měr.
TotalSales = SUM(Sales[Sales])
RegionalSales = CALCULATE([TotalSales], USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
RegionalSalesDirect = CALCULATE(SUM(Sales[Sales]), USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
Všimněte si, jak míra RegionalSales odkazuje na míru TotalSales, zatímco míra RegionalSalesDirect ne. Místo toho míra RegionalSalesDirect používá výraz SUM(Sales[Sales]), což je výraz míry TotalSales.
Rozdíl ve výsledku je jemný. Když Power BI vyhodnotí míru RegionalSales, použije filtr z tabulky Region na tabulku Sales i Date (Datum). Proto se filtr rozšíří také z tabulky Date do tabulky Sales . Když Power BI vyhodnotí míru RegionalSalesDirect , rozšíří filtr pouze z tabulky Region do tabulky Sales . Výsledky vrácené mírou RegionalSales a míra RegionalSalesDirect se může lišit, i když jsou výrazy sémanticky ekvivalentní.
Důležité
Kdykoli funkci použijete CALCULATE s výrazem, který je mírou ve vzdálené zdrojové skupině, důkladně otestujte výsledky výpočtu.
Scénář vztahu mezi zdrojovými skupinami 2
Představte si scénář, kdy relace mezi zdrojovými skupinami obsahuje sloupce relací s vysokou kardinalitou.
V tomto scénáři se tabulka Date vztahuje k tabulce Sales ve sloupcích DateKey . Datový typ sloupců DateKey je celé číslo a ukládá celá čísla, která používají formát rrrrmmdd . Tabulky patří do různých zdrojových skupin. Jedná se o relaci s vysokou kardinalitou, protože nejstarší datum v tabulce Datum je 1. ledna 1900 a poslední datum je 31. prosince 2100, takže v tabulce je celkem 73 414 řádků (jeden řádek pro každé datum v časovém rozsahu 1900–2100).
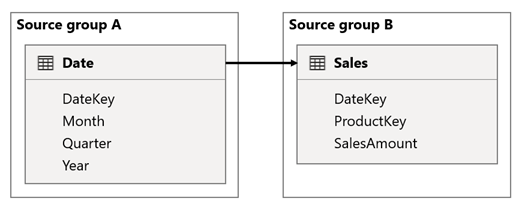
Existují dva případy zájmu.
Nejprve, když jako filtry použijete sloupce tabulky Date, šíření filtru vyfiltruje sloupec DateKey tabulky Sales k vyhodnocení měr. Při filtrování podle jednoho roku, například 2022, bude dotaz DAX obsahovat výraz filtru, jako je Sales[DateKey] IN { 20220101, 20220102, …20221231 }. Velikost textu dotazu se může zvětšit, aby se stala extrémně velkou, pokud je velký počet hodnot ve výrazu filtru nebo když jsou hodnoty filtru dlouhé řetězce. Power BI je nákladné vygenerovat dlouhý dotaz a zdroj dat spustit dotaz.
Za druhé, když jako seskupovací sloupce použijete sloupce tabulky Kalendářní datum, například Rok, Čtvrtletí nebo Měsíc, budou obsahovat filtry, které obsahují všechny jedinečné kombinace roků, čtvrtletí nebo měsíců a hodnot sloupců DateKey. Velikost řetězce dotazu, který obsahuje filtry sloupců seskupení a sloupce relace, se může stát extrémně velkými. To platí zejména v případech, kdy je velký počet sloupců seskupení nebo kardinality sloupce spojení ( sloupec DateKey ).
Pokud chcete vyřešit problémy s výkonem, můžete:
- Přidejte tabulku Date do zdroje dat, což vede k jednomu modelu zdrojové skupiny (to znamená, že už se nejedná o složený model).
- Zvyšte členitost relace. Můžete například přidat sloupec MonthKey do obou tabulek a vytvořit relaci s těmito sloupci. Když ale zvýšíte členitost relace, ztratíte možnost vykazovat denní prodejní aktivitu (pokud nepoužíváte sloupec DateKey z tabulky Sales ).
Scénář vztahu mezi zdrojovými skupinami 3
Představte si scénář, kdy mezi tabulkami v relaci mezi různými zdrojovými skupinami nejsou odpovídající hodnoty.
V tomto scénáři má tabulka Date ve zdrojové skupině B relaci s tabulkou Sales (Prodej ) v této zdrojové skupině a také s cílovou tabulkou ve zdrojové skupině A. Všechny relace jsou 1:N z tabulky Kalendářní datum vztahující se ke sloupcům Year . Tabulka Sales obsahuje sloupec SalesAmount , který ukládá částky prodeje, zatímco cílová tabulka obsahuje sloupec TargetAmount , který ukládá cílové částky.
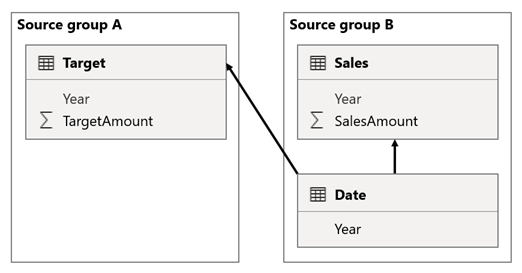
Tabulka Date ukládá roky 2021 a 2022. Tabulka Sales (Prodej ) ukládá částky prodeje za roky 2021 (100) a 2022 (200), zatímco v tabulce Target jsou uložené cílové částky pro rok 2021 (100), 2022 (200) a 2023 (300) – budoucí rok.
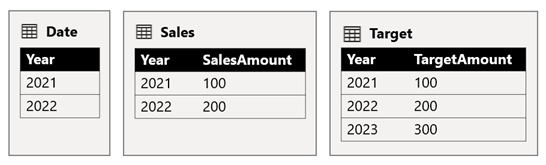
Když vizuál tabulky Power BI dotazuje složený model seskupením sloupce Year z tabulky Date a sečtováním sloupců SalesAmount a TargetAmount , nezobrazí se cílová částka pro rok 2023. Je to proto, že relace mezi zdrojovými skupinami je omezená, a proto používá INNER JOIN sémantiku, která eliminuje řádky, u kterých není na obou stranách žádná odpovídající hodnota. Vygeneruje ale správnou cílovou částku (600), protože filtr tabulky kalendářních dat se na vyhodnocení nevztahuje.
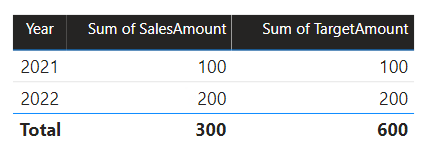
Pokud je relace mezi tabulkou Kalendářní data a cílovou tabulkou relace uvnitř zdrojové skupiny (za předpokladu , že cílová tabulka patří do zdrojové skupiny B), vizuál bude obsahovat (prázdný) rok, který zobrazí 2023 (a všechny ostatní nesrovnané roky) cílovou částku.
Důležité
Abyste se vyhnuli nesprávnému vytváření sestav, ujistěte se, že sloupce relací obsahují odpovídající hodnoty, pokud jsou tabulky dimenzí a faktů umístěny v různých zdrojových skupinách.
Další informace o omezených relacích naleznete v tématu Vyhodnocení relace.
Výpočty
Při přidávání počítaných sloupců a skupin výpočtů do složeného modelu byste měli zvážit konkrétní omezení.
Počítané sloupce
Počítané sloupce přidané do tabulky DirectQuery, které zdrojují data z relační databáze, jako je Microsoft SQL Server, jsou omezené na výrazy, které pracují na jednom řádku najednou. Tyto výrazy nemůžou používat funkce iterátoru DAX, jako jsou SUMXfunkce úprav kontextu nebo filtru, například CALCULATE.
Poznámka:
Počítané sloupce ani počítané tabulky, které závisí na zřetězených tabulkových modelech, není možné přidávat.
Výraz počítaného sloupce ve vzdálené tabulce DirectQuery je omezen pouze na vyhodnocení uvnitř řádků. Takový výraz ale můžete vytvořit, ale při použití ve vizuálu dojde k chybě. Pokud například přidáte počítaný sloupec do vzdálené tabulky DirectQuery s názvem DimProduct pomocí výrazu [Product Sales] / SUM (DimProduct[ProductSales]), budete moct výraz úspěšně uložit do modelu. Pokud se ale použije ve vizuálu, dojde k chybě, protože porušuje omezení vyhodnocení uvnitř řádků.
Počítané sloupce přidané do vzdálené tabulky DirectQuery, která je tabulkovým modelem, což je sémantický model Power BI nebo model Analysis Services, jsou naopak flexibilnější. V tomto případě jsou povoleny všechny funkce DAX, protože výraz se vyhodnotí ve zdrojovém tabulkovém modelu.
Mnoho výrazů vyžaduje, aby Power BI před použitím počítaného sloupce jako skupiny nebo filtru materializoval nebo agregoval. Pokud je počítaný sloupec materializován přes velkou tabulku, může být nákladný z hlediska procesoru a paměti v závislosti na kardinalitě sloupců, na kterých počítaný sloupec závisí. V tomto případě doporučujeme přidat tyto počítané sloupce do zdrojového modelu.
Poznámka:
Při přidávání počítaných sloupců do složeného modelu nezapomeňte otestovat všechny výpočty modelu. Upstreamové výpočty nemusí správně fungovat, protože nemyslely na jejich vliv na kontext filtru.
Skupiny výpočtů
Pokud ve zdrojové skupině existují skupiny výpočtů, které se připojí k sémantickému modelu Power BI nebo modelu Analysis Services, může Power BI vrátit neočekávané výsledky. Další informace naleznete v tématu Skupiny výpočtů, dotazování a vyhodnocení míry.
Návrh modelu
Model Power BI byste měli vždy optimalizovat přijetím návrhu hvězdicového schématu.
Tip
Další informace najdete v tématu Vysvětlení hvězdicového schématu a důležitosti pro Power BI.
Nezapomeňte vytvořit tabulky dimenzí, které jsou oddělené od tabulek faktů, aby Power BI mohl správně interpretovat spojení a vytvářet efektivní plány dotazů. I když jsou tyto pokyny pravdivé pro jakýkoli model Power BI, platí to zejména pro modely, které rozpoznáte, se stane zdrojovou skupinou složeného modelu. Umožní jednodušší a efektivnější integraci jiných tabulek v podřízených modelech.
Pokud je to možné, vyhněte se tabulkám dimenzí v jedné zdrojové skupině, které se vztahují k tabulce faktů v jiné zdrojové skupině. Je to proto, že je lepší mít relace uvnitř zdrojové skupiny než relace mezi zdrojovými skupinami, zejména pro sloupce relací s vysokou kardinalitou. Jak je popsáno výše, relace mezi zdrojovými skupinami závisí na tom, že mají odpovídající hodnoty ve sloupcích relací, jinak se ve vizuálech sestavy můžou zobrazit neočekávané výsledky.
Zabezpečení na úrovni řádků
Pokud váš model obsahuje uživatelem definované agregace, počítané sloupce u importovaných tabulek nebo počítaných tabulek, ujistěte se, že je správně a otestováno zabezpečení na úrovni řádků (RLS).
Pokud se složený model připojuje k jiným tabulkovým modelům, pravidla zabezpečení na úrovni řádků se použijí jenom u zdrojové skupiny (místního modelu), kde jsou definovány. Nepoužijí se u jiných zdrojových skupin (vzdálených modelů). Nemůžete také definovat pravidla zabezpečení na úrovni řádků v tabulce z jiné zdrojové skupiny ani nemůžete definovat pravidla zabezpečení na úrovni řádků v místní tabulce, která má relaci s jinou zdrojovou skupinou.
Návrh sestavy
V některých situacích můžete zlepšit výkon složeného modelu tak, že navrhnete optimalizované rozložení sestavy.
Vizuály jedné zdrojové skupiny
Kdykoli je to možné, vytvořte vizuály, které používají pole z jedné zdrojové skupiny. Je to proto, že dotazy vygenerované vizuály budou fungovat lépe, když se výsledek načte z jedné zdrojové skupiny. Zvažte vytvoření dvou vizuálů umístěných vedle sebe, které načítají data ze dvou různých zdrojových skupin.
Použití synchronizačních průřezů
V některých situacích můžete nastavit synchronizační průřezy , abyste se vyhnuli vytvoření relace mezi zdrojovými skupinami v modelu. Umožňuje vizuálně kombinovat zdrojové skupiny, které můžou lépe fungovat.
Představte si scénář, kdy má váš model dvě zdrojové skupiny. Každá zdrojová skupina obsahuje tabulku dimenzí produktů, která slouží k filtrování prodejců a internetových prodejů.
V tomto scénáři zdrojová skupina A obsahuje tabulku Product , která souvisí s tabulkou ResellerSales . Zdrojová skupina B obsahuje tabulku Product2, která souvisí s tabulkou InternetSales. Mezi zdrojovými skupinami nejsou žádné relace.
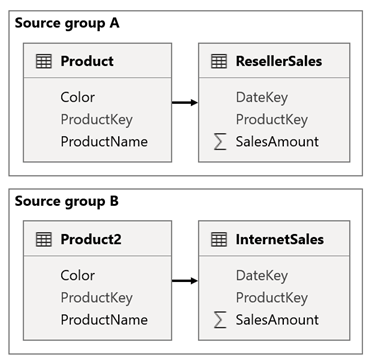
V sestavě přidáte průřez, který stránku filtruje pomocí sloupce Barva v tabulce Product. Průřez ve výchozím nastavení filtruje tabulku ResellerSales, ale ne tabulku InternetSales. Potom přidáte skrytý průřez pomocí sloupce Barva v tabulce Product2. Nastavením identického názvu skupiny (v rozšířených možnostech synchronizace průřezů) se filtry použité u viditelného průřezu automaticky rozšíří do skrytého průřezu.
Poznámka:
Použití synchronizačních průřezů se sice může vyhnout nutnosti vytvořit relaci mezi zdrojovými skupinami, ale zvyšuje složitost návrhu modelu. Nezapomeňte informovat ostatní uživatele o tom, proč jste model navrhli s duplicitními tabulkami dimenzí. Vyhněte se nejasnostem skrytím tabulek dimenzí, které nechcete, aby ostatní uživatelé používali. Můžete také přidat text popisu do skrytých tabulek a zdokumentovat jejich účel.
Další informace najdete v tématu Synchronizace samostatných průřezů.
Další pokyny
Tady jsou některé další pokyny, které vám pomůžou navrhovat a udržovat složené modely.
- Výkon a škálování: Pokud byly vaše sestavy dříve živě připojené k sémantickému modelu Power BI nebo modelu Analysis Services, služba Power BI by mohly opakovaně používat mezipaměti vizuálů mezi sestavami. Po převodu živého připojení na vytvoření místního modelu DirectQuery už sestavy nebudou z těchto mezipamětí těžit. V důsledku toho může dojít k pomalejšímu výkonu nebo dokonce selháním aktualizace. Úloha pro služba Power BI se také zvýší, což může vyžadovat vertikální navýšení kapacity nebo distribuci úlohy mezi další kapacity. Další informace o aktualizaci a ukládání dat do mezipaměti najdete v tématu Aktualizace dat v Power BI.
- Přejmenování: Nedoporučujeme přejmenovat sémantické modely používané složenými modely nebo přejmenovat jejich pracovní prostory. Je to proto, že se složené modely připojují k sémantickým modelům Power BI pomocí názvů pracovních prostorů a sémantických modelů (nikoli jejich interních jedinečných identifikátorů). Přejmenování sémantického modelu nebo pracovního prostoru může narušit připojení používaná složeným modelem.
- Zásady správného řízení: Nedoporučujeme, aby vaše jediná verze modelu pravdy byla složený model. Důvodem je to, že by to bylo závislé na jiných zdrojích dat nebo modelech, které by v případě aktualizace mohly vést k narušení složeného modelu. Místo toho doporučujeme publikovat podnikový sémantický model jako jedinou verzi pravdy. Zvažte tento model jako spolehlivý základ. Ostatní modelátoři dat pak můžou vytvářet složené modely, které rozšiřují základní model a vytvářejí specializované modely.
- Rodokmen dat: Před publikováním složených změn modelu použijte funkce analýzy dopadu rodokmenu dat a sémantických modelů. Tyto funkce jsou k dispozici v služba Power BI a můžou vám pomoct pochopit, jak sémantické modely souvisejí a používají. Je důležité si uvědomit, že nemůžete provádět analýzu dopadu na externí sémantické modely, které se zobrazují v zobrazení rodokmenu, ale ve skutečnosti se nacházejí v jiném pracovním prostoru. Pokud chcete provést analýzu dopadu na externí sémantický model, musíte přejít do zdrojového pracovního prostoru.
- Aktualizace schématu: Při změnách schématu v upstreamových zdrojích dat byste měli aktualizovat složený model v Power BI Desktopu. Pak budete muset model znovu publikovat do služba Power BI. Nezapomeňte důkladně testovat výpočty a závislé sestavy.
Související obsah
Další informace týkající se tohoto článku najdete v následujících zdrojích informací.
- Použití složených modelů v Power BI Desktop
- Relace modelu v Power BI Desktopu
- Modely DirectQuery v Power BI Desktopu
- Použití DirectQuery v Power BI Desktopu
- Použití DirectQuery pro sémantické modely Power BI a Analysis Services
- Režim úložiště v Power BI Desktopu
- Uživatelem definované agregace
- Otázky? Zkuste se zeptat Komunita Power BI
- Návrhy? Přispívání nápadů ke zlepšení Power BI