Připojení ke zdrojům dat SAP HANA pomocí DirectQuery v Power BI
Ke zdrojům dat SAP HANA se můžete připojit přímo pomocí DirectQuery, což se často vyžaduje pro velké datové sady, které překračují dostupné prostředky pro podporu modelů importu. Existují dva přístupy pro připojení k SAP HANA v režimu DirectQuery, z nichž každá má různé možnosti:
považovat SAP HANA za multidimenzionální zdroj (výchozí): V tomto případě se chování podobá tomu, když se Power BI připojí k jiným multidimenzionálním zdrojům, jako je SAP Business Warehouse nebo Analysis Services. Když se připojíte k SAP HANA jako multidimenzionální zdroj, vybere se jedno zobrazení analýzy nebo výpočtu a v seznamu polí jsou k dispozici všechny míry, hierarchie a atributy tohoto zobrazení. V sémantickém modelu nelze přidat počítané sloupce ani jiná přizpůsobení dat. Při vytváření vizuálů se agregovaná data přímo načítají ze SAP HANA. Zacházet se SAP HANA jako s multidimenzionálním zdrojem je výchozím nastavením pro nové sestavy DirectQuery přes SAP HANA.
zacházet se SAP HANA jako s relačním zdrojem: V tomto případě Power BI považuje SAP HANA za relační zdroj dat. Tento přístup nabízí větší flexibilitu. Kromě jiného můžete přidat počítané sloupce a zahrnout data z jiných zdrojů, ale je potřeba zajistit, aby míry byly agregované podle očekávání. Vyhněte se neaditivním opatřením. Také se ujistěte, že používáte jednoduchá zobrazení s několika sloupci a spojeními, abyste se vyhnuli problémům s výkonem. Zvažte opětovné vytvoření měr v sémantickém modelu, ale mějte na paměti, že složité míry se nemusí skládat. Hierarchie SAP HANA nejsou při použití SAP HANA jako relačního zdroje k dispozici.
Metoda připojení je určena globální možností nástroje, která je nastavena výběrem možnosti Soubor>Možnosti a nastavení a poté Možnosti>DirectQuerya pak výběrem možnosti Považovat SAP HANA za relační zdroj, jak je znázorněno na následujícím obrázku.
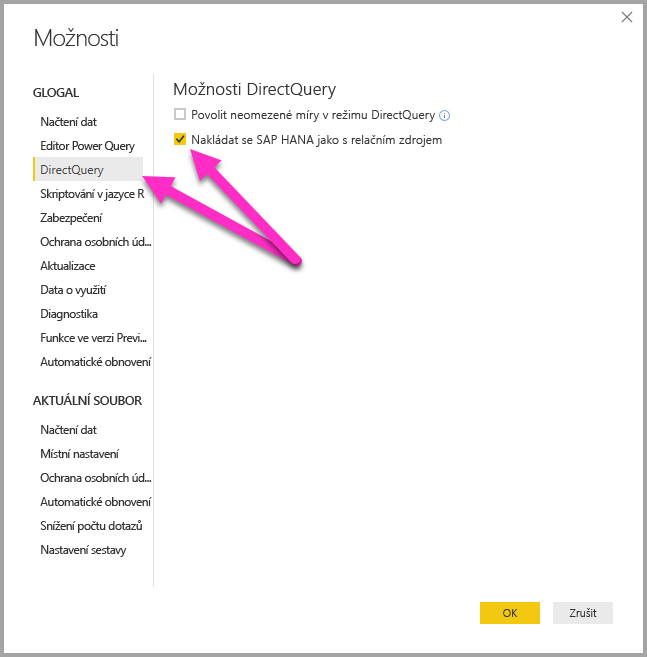
Možnost považovat SAP HANA za relační zdroj řídí metodu připojení pro všechny nové sestavy, které používají DirectQuery na SAP HANA. Nemá žádný vliv na žádná existující připojení SAP HANA v aktuální sestavě ani na připojení v jiných otevřených sestavách. Pokud je tato možnost aktuálně nezaškrtnutá, pak po přidání nového připojení k SAP HANA pomocí Získat datatoto připojení považuje SAP HANA za multidimenzionální zdroj. Pokud se ale otevře jiná sestava, která se také připojuje k SAP HANA, bude se tato sestava dál chovat podle možnosti, která byla nastavena v době, kdy byla vytvořena. To znamená, že všechny sestavy, které se připojují k SAP HANA jako relační zdroj, nadále považují SAP HANA za relační zdroj, i když je nyní tato možnost nezaškrtnutá.
Dvě metody připojení SAP HANA představují odlišné chování a není možné přepnout existující sestavu z jedné metody připojení na druhou.
Považujte SAP HANA za multidimenzionální zdroj (výchozí)
Všechna nová připojení k SAP HANA používají tuto metodu připojení ve výchozím nastavení a považují SAP HANA za multidimenzionální zdroj. Při připojování k SAP HANA jako multidimenzionálnímu zdroji platí následující aspekty:
V Navigátoru datlze vybrat jedno zobrazení SAP HANA. Není možné vybrat jednotlivé míry nebo atributy. Při připojení není definovaný žádný dotaz, což se liší od importu dat nebo při používání DirectQuery při používání SAP HANA jako relačního zdroje. To také znamená, že při výběru této metody připojení není možné přímo použít dotaz SAP HANA SQL.
V seznamu polí se zobrazí všechny míry, hierarchie a atributy vybraného zobrazení.
Při použití míry ve vizuálu se SAP HANA dotazuje, aby načetla hodnotu míry na úrovni agregace potřebné pro vizuál. Při práci s neaditivními mírami, jako jsou čítače a poměry, provádí SAP HANA všechny agregace a Power BI žádnou další neprovádí.
Aby se zajistilo, že správné agregační hodnoty je možné vždy získat ze SAP HANA, musí být stanovena určitá omezení. Například není možné vložit vypočítané sloupce ani sloučit data z více zobrazení SAP HANA ve stejné sestavě. Není také možné odstranit sloupce nebo změnit jejich datové typy.
Zpracování SAP HANA jako multidimenzionálního zdroje nabízí menší flexibilitu než alternativní relační přístup, ale je to jednodušší. Tato metoda připojení zajišťuje správné agregační hodnoty při práci se složitějšími mírami SAP HANA a obecně vede k vyššímu výkonu.
Seznam Pole obsahuje všechny míry, atributy a hierarchie ze zobrazení SAP HANA. Všimněte si následujících chování, které platí při použití této metody připojení:
Každý atribut, který je součástí alespoň jedné hierarchie, je ve výchozím nastavení skrytý. Pokud je to ale potřeba, můžete je zobrazit tak, že v seznamu polí vyberete Zobrazit skryté. Ze stejné místní nabídky je lze v případě potřeby učinit viditelnými.
V SAP HANA lze atribut definovat tak, aby jako popisek používal jiný atribut. Například Produkt, s hodnotami
1,2,3atd., by mohl použít ProductName, s hodnotamiBike,Shirt,Glovesatd., jako svůj popisek. V tomto případě se v seznamu polí zobrazí jedno pole Produkt, jehož hodnoty jsou popiskyBike,Shirt,Glovesatd., ale které jsou seřazeny podle, a s jedinečností určenou hodnotami klíče1,2,3. Vytvoří se také skrytý sloupec Product.Key, který v případě potřeby umožní přístup k hodnotám podkladového klíče.
Všechny proměnné definované v podkladovém zobrazení SAP HANA se zobrazí v době připojení a je možné zadat potřebné hodnoty. Tyto hodnoty můžete později změnit tak, že na pásu karet vyberete Transformovat data a pak Upravit parametry v rozevírací nabídce.
Povolené operace modelování jsou více omezující než v obecném případě při použití DirectQuery vzhledem k tomu, že je potřeba zajistit, aby se správná agregovaná data dala vždy získat ze SAP HANA. Je však stále možné provést některé dodatky a změny, včetně definování měr, přejmenování a skrytí polí a definování formátů zobrazení. Všechny tyto změny se při aktualizaci zachovají a použijí se všechny nekonfliktní změny provedené v zobrazení SAP HANA.
Další omezení modelování
Kromě výše uvedených omezení mějte na paměti následující omezení modelování při připojování k SAP HANA jako multidimenzionální zdroj:
- Žádná podpora počítaných sloupců: Možnost vytvářet počítané sloupce je zakázaná. Tato skutečnost také znamená, že seskupení a klastry, které spoléhají na počítané sloupce, nejsou k dispozici.
- Další omezení pro míry: Pro výrazy DAX, které je možné použít v mírách, platí další omezení, aby odrážela úroveň podpory, kterou nabízí SAP HANA. Například není možné použít agregační funkci v tabulce.
- Žádná podpora pro definování relací: V sestavě lze dotazovat pouze jedno zobrazení, takže není podpora pro definování relací.
- Žádné zobrazení tabulky: Zobrazení tabulky obvykle zobrazuje data na úrovni podrobností v tabulkách. Vzhledem k povaze multidimenzionálních zdrojů není toto zobrazení dostupné při použití SAP HANA jako multidimenzionálního zdroje.
- Podrobnosti o sloupcích a mírách jsou opravené: Sloupce a míry v seznamu polí jsou určeny podkladovým zdrojem a nelze je upravit. Například sloupec není možné odstranit ani změnit jeho datový typ. Dá se ale přejmenovat.
Další omezení vizualizace
Při připojování k SAP HANA jako multidimenzionálního zdroje existují omezení ve vizuálech:
- Žádná agregace sloupců: Není možné změnit agregaci pro sloupec na vizuálu a je to vždy Nevytvářet souhrn.
Zpracování SAP HANA jako relačního zdroje
Pokud se chcete připojit k SAP HANA jako relační zdroj, musíte vybrat Možnosti a nastavení>Soubor a pak Možnosti>DirectQuerya pak vybrat možnost Nakládat se SAP HANA jako s relačním zdrojem.
Při použití SAP HANA jako relačního zdroje je k dispozici další flexibilita. Můžete například vytvořit počítané sloupce, zahrnout data z více zobrazení SAP HANA a vytvořit relace mezi výslednými tabulkami. Existují však rozdíly od chování při připojování k SAP HANA jako multidimenzionálního zdroje, zejména v případě, že zobrazení SAP HANA obsahuje nesoučtové míry, například jedinečné počty nebo průměry, nikoli jednoduché součty. Neaditivní míry mohou vést k nesprávným výsledkům. Míry také můžou snížit efektivitu optimalizace plánu dotazů v SAP HANA a vést k nízkému výkonu dotazů a vypršení časových limitů.
Principy SAP HANA jako relačního zdroje
Je užitečné začít objasněním chování relačního zdroje, jako je SQL Server, když dotaz definovaný v Získat data nebo Editor Power Query provede agregaci. V následujícím příkladu vrátí dotaz definovaný v Editoru Power Query průměrnou cenu podle ID produktu.
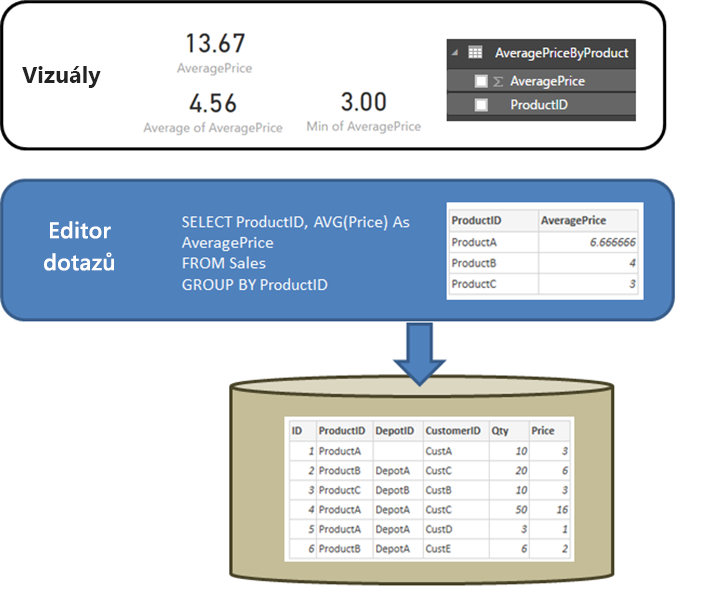
Pokud se data naimportovala do Power BI místo directQuery, výsledkem by byla následující situace:
- Data se importují na úrovni agregace definované dotazem vytvořeným v Editoru Power Query. Například průměrná cena podle produktu. Výsledkem této skutečnosti je tabulka se dvěma sloupci ProductID a AveragePrice, které je možné použít ve vizuálech.
- Ve vizuálu se u importovaných dat provádí jakákoli následná agregace, například suma, Průměr, Mina další. Například AveragePrice na vizuálu standardně používá agregaci Sum, a proto vrátí součet přes AveragePrice pro každý ProductID, což je v tomto příkladu 13,67. Totéž platí pro jakoukoli alternativní agregační funkci, například Min nebo Průměr, která se používá ve vizuálu. Například Average of AveragePrice vrátí průměr 6,66, 4 a 3, který odpovídá 4,56, a nikoli průměr Cena na šesti záznamech v podkladové tabulce, což je 5,17.
Pokud se místo importu používá DirectQuery přes stejný relační zdroj, použije se stejná sémantika a výsledky by byly naprosto stejné:
Vzhledem ke stejnému dotazu se logicky přesně stejná data zobrazují do vrstvy vytváření sestav, i když se data ve skutečnosti neimportují.
Ve vizuálu se jakákoli následná agregace, jako je Součet, Průměra Min, znovu provádí přes tuto logickou tabulku z dotazu. A opět vizuál obsahující PrůměrAveragePrice vrátí stejnou hodnotu 4,56.
Zvažte SAP HANA, když se připojení považuje za relační zdroj. Power BI může pracovat s analytickými zobrazeními i zobrazeními výpočtů v SAP HANA, a obě mohou obsahovat míry. Přístup pro SAP HANA se v současné době řídí stejnými principy, jaké jsme popsali dříve v této části: dotaz definovaný v Načíst data nebo Editor Power Query určuje dostupná data a následná agregace ve vizuálu je přes tato data a totéž platí pro import i DirectQuery. Vzhledem k povaze SAP HANA je však dotaz definovaný v počátečním dialogovém okně Získat data nebo v Editoru Power Query vždy agregačním dotazem a obecně zahrnuje míry, u nichž jsou skutečné agregace definovány zobrazením SAP HANA.
Ekvivalentem předchozího příkladu SQL Serveru je, že existuje zobrazení SAP HANA obsahující ID, ProduktID, DepotIDa míry včetně Průměrná cena, definované v zobrazení jako průměr ceny.
Pokud jste v prostředí Získat data vybrali ProductID a míru AveragePrice, pak se v zobrazení definuje dotaz, který požaduje agregovaná data. V předchozím příkladu se pro jednoduchost používá pseudo-SQL, který neodpovídá přesné syntaxi SAP HANA SQL. Potom všechny další agregace definované ve vizuálu dále agregují výsledky takového dotazu. Znovu, jak je popsáno dříve pro SQL Server, tento výsledek platí pro případ Import i DirectQuery. V případě DirectQuery se dotaz z Získat data nebo Editoru Power Query používá v dílčím výběru v rámci jednoho dotazu odeslaného do SAP HANA, což znamená, že ve skutečnosti není nutné, aby byla všechna data přečtena před další agregací.
Všechny tyto aspekty a chování vyžadují následující důležité aspekty při použití DirectQuery přes SAP HANA jako relační zdroj:
Pozornost je třeba věnovat jakékoli další agregaci prováděné ve vizuálech, kdykoli je metrika v SAP HANA nesčitatelná, například není běžný Součet, Minimumnebo Maximum.
V Získat data nebo Editoru Power Query by měly být k načtení potřebných dat zahrnuty pouze požadované sloupce, které odrážejí skutečnost, že výsledkem je dotaz, který musí být rozumný dotaz, který se dá odeslat do SAP HANA. Pokud byly například vybrány desítky sloupců s myšlenkou, že by mohly být potřeba u následných vizuálů, znamená to, že i u jednoduchého vizuálu DirectQuery agregační dotaz použitý v dílčím výběru obsahuje tyto desítky sloupců, které obvykle fungují špatně a můžou narazit na časové limity.
V následujícím příkladu výběr pěti sloupců (CalendarQuarter, Color, LastName, ProductLine, SalesOrderNumber) v dialogovém okně Získat data, spolu s metrikou OrderQuantity, znamená, že vytvoření jednoduchého vizuálu, který obsahuje Min OrderQuantity, má za následek následující SQL dotaz na SAP HANA. Stínovaný je dílčí výběr, který obsahuje dotaz z Získat data / Editor Power Query. Pokud má tento dílčí výběr vysoký výsledek kardinality, bude výsledný výkon SAP HANA pravděpodobně nízký nebo dojde k vypršení časového limitu. Dopad na výkon není způsoben tím, že Power BI požaduje všechna pole v dílčím výběru; většina těchto polí bude odfiltrována vnějším dotazem. Dopad je spíše způsoben opatřeními v podvýběru, které vynutí jeho materializaci na serveru HANA.

Vzhledem k tomuto chování doporučujeme omezit položky vybrané v Získat data nebo Editoru Power Query na ty, které jsou potřeba, zatímco stále jako výsledek vznikne rozumný dotaz pro SAP HANA. Pokud je to možné, zvažte opětovné vytvoření všech požadovaných měr v sémantickém modelu a použití SAP HANA spíše jako tradiční relační zdroj.
Osvědčené postupy
Pro obě metody připojení k SAP HANA postupujte podle obecných doporučení pro použití DirectQuery, zejména doporučení související s zajištěním dobrého výkonu dotazů. Další informace najdete v tématu použití DirectQuery v Power BI.
Důležité informace a omezení
Následující seznam popisuje všechny funkce SAP HANA, které nejsou plně podporované, nebo funkce, které se při používání Power BI chovají jinak.
- Hierarchie rodič-potomek: Hierarchie rodič-potomek nejsou v Power BI viditelné. Důvodem je to, že Power BI přistupuje k SAP HANA pomocí rozhraní SQL a nadřazené podřízené hierarchie nejsou plně přístupné pomocí SQL.
- Metadata jiné hierarchie: Základní struktura hierarchií se v Power BI zobrazuje, ale některá metadata hierarchie, jako je například řízení chování nepravidelných hierarchií, nemají žádný vliv. Opět je to způsobeno omezeními uloženými rozhraním SQL.
- Připojení pomocí PROTOKOLU SSL: Můžete se připojit pomocí importu a multidimenzionálního protokolu TLS, ale nemůžete se připojit k instancím SAP HANA nakonfigurovaným tak, aby používaly protokol TLS pro metodu relačního připojení.
- Podpora zobrazení atributů: Power BI se může připojit k zobrazením analýzy a výpočtů, ale nemůže se připojit přímo k zobrazení atributů.
- Podpora objektů katalogu: Se Power BI nemůže připojit k objektům katalogu.
- Změny v proměnných po publikování: Po publikování sestavy nemůžete přímo změnit hodnoty žádné proměnné SAP HANA ve službě Power BI.
Známé problémy
Následující seznam popisuje všechny známé problémy při připojování k SAP HANA (DirectQuery) pomocí Power BI.
problém se SAP HANA při dotazování na čítače a další míry: z SAP HANA se vrátí nesprávná data, pokud se připojujete k analytickému zobrazení, a míra čítače a některá další míra poměru jsou součástí stejného vizuálu. Tento problém řeší SAP Note 2128928 (neočekávané výsledky při dotazování počítaného sloupce a čítače). V tomto případě je míra poměru nesprávná.
více sloupců Power BI z jednoho sloupce SAP HANA: Pro některá zobrazení výpočtů, kde se sloupec SAP HANA používá ve více než jedné hierarchii, sap HANA sloupec zveřejňuje jako dva samostatné atributy. Výsledkem tohoto přístupu jsou dva sloupce vytvořené v Power BI. Tyto sloupce jsou ve výchozím nastavení skryté a všechny dotazy týkající se hierarchií nebo sloupců se chovají správně.
Související obsah
Další informace o DirectQuery najdete v následujících zdrojích informací: