Export dat Dataverse ve formátu Delta Lake
Pomocí Azure Synapse Link for Dataverse exportujte svá data Microsoft Dataverse do Azure Synapse Analytics ve formátu Delta Lake. Poté prozkoumejte svá data a urychlete čas potřebný k získání přehledu. Tento článek obsahuje následující informace a ukazuje, jak provést následující úkoly:
- Vysvětluje Delta Lake a Parquet a proč byste měli exportovat data v tomto formátu.
- Exportujte svá data Dataverse do svého Azure Synapse Analytics workspace ve formátu Delta Lake pomocí Azure Synapse Link.
- Sledujte svou Azure Synapse Link a konverzi dat.
- Zobrazení vašich dat z Azure Data Lake Storage Gen2.
- Prohlédněte si svá data ze Synapse Workspace.
Důležité
- Pokud upgradujete z CSV na Delta Lake se stávajícími vlastními zobrazeními, doporučujeme aktualizovat skript, aby nahradil všechny partitioned tabulky na non_partitioned. Provedete to vyhledáním instancí
_partitioneda jejich nahrazením prázdným řetězcem. - Pro konfiguraci Dataverse je ve výchozím nastavení zapnuto pouze připojení pro export dat CSV v režimu
appendonly. Tabulka Delta Lake však bude mít strukturu aktualizace na místě, protože konverze Delta Lake má proces pravidelného slučování. - S vytvořením fondů úloh Spark nevznikají žádné náklady. Poplatky se účtují až po provedení úlohy Spark na cílovém fondu úloh Spark a vytvoření instance Spark na vyžádání. Tyto náklady souvisejí s používáním Spark Azure Synapse workspace a jsou účtovány měsíčně. Náklady na provádění výpočtů Spark závisí především na časovém intervalu přírůstkové aktualizace a objemu dat. Další informace: Ceny Azure Synapse Analytics
- Při rozhodování o použití této funkce je důležité vzít v úvahu tyto dodatečné náklady, protože nejsou volitelné a je třeba je zaplatit, abyste mohli tuto funkci nadále používat.
-
- ledna 2023 byl ohlášen konec životnosti (EOLA) modulu runtime Azure Synapse pro Apache Spark 3.1. V souladu se zásadami životního cyklu modulu runtime Synapse pro Apache Spark bude k 26. lednu 2024 ukončen a deaktivován modul runtime Azure Synapse pro Apache Spark 3.1. Po datu EOL nejsou vyřazené moduly runtime k dispozici pro nové fondy Spark a stávající pracovní postupy nelze spustit. Metadata dočasně zůstanou v pracovním prostoru Synapse. Další informace: Modul runtime Azure Synapse pro Apache Spark 3.1 (EOLA). Chcete-li mít svůj odkaz na Synapse pro Dataverse s exportem do formátu Delta Lake upgradován na Spark 3.3, proveďte místní upgrade existujících profilů. Další informace: Místní upgrade na Apache Spark 3.3 s Delta Lake 2.2.
- Od 4. ledna 2024 bude při počátečním vytváření odkazu podporována pouze Spark Pool verze 3.3.
Poznámka
Stav Azure Synapse Link v Power Apps (make.powerapps.com) odráží stav převodu Delta Lake:
Countzobrazuje celkový počet záznamů v tabulce Delta Lake.Last synchronized onDatetime představuje poslední úspěšné časové razítko převodu.Sync statusse po synchronizaci dat a převodu dat do Delta Lake zobrazí jako aktivní, což znamená, že data jsou připravena ke spotřebě.
Co je Delta Lake?
Delta Lake je projekt s otevřeným zdrojovým kódem, který umožňuje vybudovat architekturu Lakehouse na datových jezerech. Delta Lake poskytuje transakce ACID (atomicita, konzistence, izolace a trvanlivost), škálovatelné zpracování metadat a sjednocuje streamování a dávkové zpracování dat nad stávajícími datovými jezery. Azure Synapse Analytics je kompatibilní s Linux Foundation Delta Lake. Současná verze Delta Lake, která je součástí Azure Synapse, má jazykovou podporu pro Scala, PySpark a .NET. Další informace: Co je Delta Lake?. Více se také můžete dozvědět z videa Úvod do tabulek Delta.
Apache Parquet je základní formát pro Delta Lake, který vám umožňuje využít efektivní schémata komprese a kódování, která jsou pro tento formát nativní. Formát souboru Parquet používá kompresi po sloupcích. Je efektivní a šetří úložný prostor. Dotazy, které načítají konkrétní hodnoty sloupců, nemusejí číst celá data řádku, čímž se zvyšuje výkon. Bezserverový fond SQL proto potřebuje ke čtení dat méně času a méně požadavků na úložiště.
Proč používat Delta Lake?
- Škálovatelnost: Delta Lake je postaveno na licenci open-source Apache, která je navržena tak, aby splňovala průmyslové standardy pro zpracování rozsáhlých úloh zpracování dat.
- Spolehlivost: Delta Lake poskytuje transakce ACID, čímž zajišťuje konzistenci a spolehlivost dat i v případě selhání nebo souběžného přístupu.
- Výkon: Delta Lake využívá sloupcový formát úložiště Parquet, poskytuje lepší techniky komprese a kódování, což může vést k lepšímu výkonu dotazů ve srovnání s dotazovanými soubory CSV.
- Nákladově efektivní: Formát souboru Delta Lake je vysoce komprimovaná technologie ukládání dat, která podnikům nabízí významné potenciální úspory úložiště. Tento formát je speciálně navržen tak, aby optimalizoval zpracování dat a potenciálně snižoval celkové množství zpracovávaných dat nebo dobu běhu vyžadovanou pro výpočty na vyžádání.
- Soulad s ochranou dat: Delta Lake s Azure Synapse Link poskytuje nástroje a funkce včetně soft-delete a hard-delete pro zajištění souladu s různými nařízeními o ochraně osobních údajů, včetně General Data Protection Regulation (GDPR).
Jak Delta Lake funguje s Azure Synapse Link for Dataverse?
Při nastavování Azure Synapse Link for Dataverse můžete zapnout funkci exportu do Delta Lake a připojit se Synapse workspace a fondem úloh Spark. Azure Synapse Link exportuje vybrané tabulky Dataverse ve formátu CSV v určených časových intervalech a zpracovává je prostřednictvím úlohy Spark konverze Delta Lake. Po dokončení tohoto procesu převodu jsou data CSV vyčištěna pro uložení do úložiště. Kromě toho je naplánováno každodenní spouštění řady úloh údržby, které automaticky provádějí procesy zhutňování a vysávání za účelem sloučení a vyčištění datových souborů, aby se dále optimalizovalo úložiště a zlepšil výkon dotazů.
Předpoklady
- Dataverse: Musíte mít roli zabezpečení Správce systému Dataverse. Navíc tabulky, které chcete exportovat přes Azure Synapse Link, musí mít zapnutou vlastnost Sledování změn. Více informací: Rozšířené možnosti
- Azure Data Lake Storage Gen2: Musíte mít Účet Azure Data Lake Storage Gen2 a přístup role Vlastník a Přispěvatel dat objektu blob úložiště. Váš účet úložiště musí umožňovat hierarchický jmenný prostor a přístup k veřejné síti pro počáteční nastavení i delta synchronizaci Povolit přístup klíče účtu úložiště je vyžadováno pouze pro počáteční nastavení.
- Pracovní prostor Synapse: Musíte mít pracovní prostor Synapse a roli Vlastník v řízení přístupu (IAM) a přístup k roli Správce Synapse v Synapse Studio. Pracovní prostor Synapse musí být ve stejné oblasti jako váš Účet Azure Data Lake Storage Gen2. Účet úložiště musí být přidán jako propojená služba v rámci Synapse Studio. Chcete-li vytvořit pracovní prostor Synapse, přejděte na Vytvoření pracovního prostoru Synapse.
- Apache Spark pool v připojeném Azure Synapse pracovním prostoru s Apache Spark verzí 3.3 používá tuto doporučenou konfiguraci Spark Pool. Pro informace, jak vytvořit fond úloh Sparku, přejděte do části Vytvoření nového fondu úloh Apache Spark.
- Minimální požadavek na verzi Microsoft Dynamics 365 pro použití této funkce je 9.2.22082. Další informace: Registrace k aktualizacím dřívějšího přístupu
Doporučená konfigurace fondu úloh Spark
Tato konfigurace může být považována za krok bootstrap pro případy průměrného použití.
- Velikost uzlu: malá (4 virtuální jádra / 32 GB)
- Automatické škálování: zapnuto
- Počet vybraných uzlů: 5 až 10
- Automatické pozastavení: zapnuto
- Počet minut nečinnosti: 5
- Apache Spark: 3.3
- Dynamicky přidělit exekutory: Povoleno
- Výchozí počet exekutorů: 1 až 9
Důležité
Používejte fond Spark výhradně pro operace konverzace Delta Lake pomocí Synapse Link pro Dataverse. Chcete-li dosáhnout optimální spolehlivosti a výkonu, nespouštějte jiné úlohy Spark pomocí stejného fondu Spark.
Připojení Dataverse do Synapse workspace a export dat ve formátu Delta Lake
Přihlaste se do Power Apps a vyberte požadované prostředí.
V levém navigačním podokně vyberte Azure Synapse Link. Pokud se položka nenachází v bočním podokně, vyberte možnost …Více a poté vyberte požadovanou položku.
Na panelu příkazů zvolte tlačítko + Nový odkaz
Vyberte Připojit k Azure Synapse Analytics workspace a poté vyberte Předplatné, Skupina prostředků a Název pracovního prostoru.
Vyberte Použít fond úloh Sparku pro zpracování a poté vyberte předem vytvořený fond úloh Sparku a Účet úložiště.
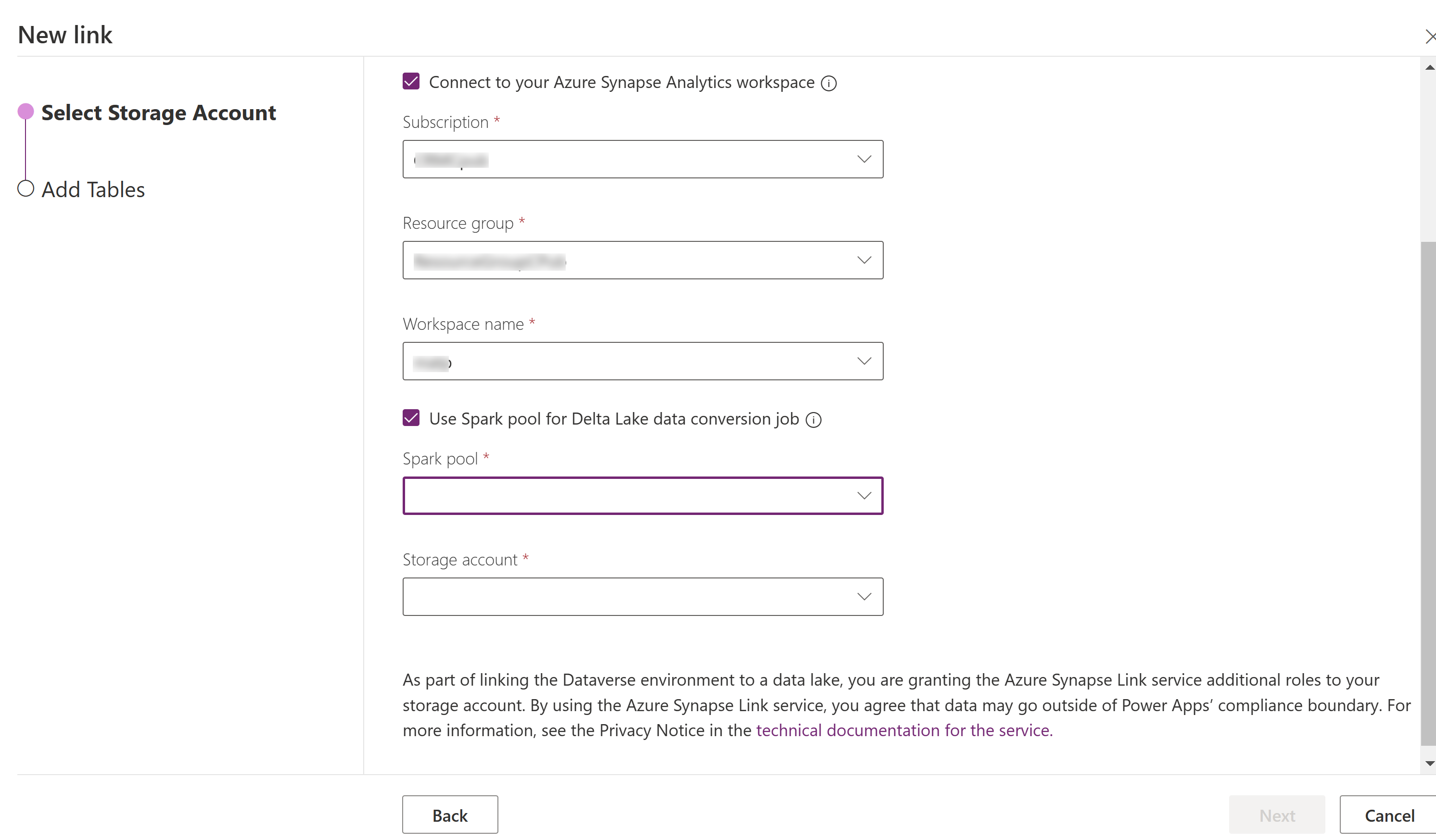
Vyberte Další.
Přidejte tabulky, které chcete exportovat, a poté vyberte Pokročilý.
Volitelně vyberte Zobrazit pokročilá nastavení konfigurace a zadejte časový interval v minutách, jak často mají být přírůstkové aktualizace zachycovány.
Vyberte Uložit.
Monitorování Azure Synapse Link a konverze dat
- Vyberte požadované propojení Azure Synapse Link a v příkazů vyberte Přejít do pracovního prostoru Azure Synapse Analytics.
- Vyberte Monitorování > Aplikace Apache Spark. Další informace: Použití Synapse Studio ke sledování aplikací Apache Spark.
Zobrazení svá data ze Synapse workspace
- Vyberte požadované propojení Azure Synapse Link a v příkazů vyberte Přejít do pracovního prostoru Azure Synapse Analytics.
- Rozbalte Databáze jezera v levém podokně, vyberte dataverse-environmentNameorganizationUniqueName pak rozbalte Tabulky. Všechny tabulky Parquet dat téměř v reálném čase jsou uvedeny a dostupné pro analýzu s konvencí pojmenování DataverseTableName. (Non_partitioned Table).
Poznámka
Nepoužívejte tabulky s konvencí pojmenování _partitioned. Když jako formát zvolíte Delta Parquet, tabulky s konvencí pojmenování _partition se použijí jako pracovní tabulky a po použití systémem se odstraní.
Zobrazení vašich dat z Azure Data Lake Storage Gen2
- Vyberte požadovaný Azure Synapse Link a pak na panelu příkazů vyberte Přejít na datové jezero Azure.
- Vyberte Kontejnery pod Úložiště dat.
- Vyberte *dataverse- *environmentName-organizationUniqueName. Všechny soubory parquet jsou uloženy ve složce deltalake.
Místní upgrade na Apache Spark 3.3 s Delta Lake 2.2
Předpoklady
- Musíte mít existující profil Delta Lake pro Azure Synapse Link for Dataverse běžící se Synapse Spark verze 3.1.
- Musíte vytvořit nový fond Synapse Spark verze 3.3 s použitím stejné nebo vyšší hardwarové konfigurace uzlů ve stejném pracovním prostoru Synapse. Pro informace, jak vytvořit fond úloh Sparku, přejděte do části Vytvoření nového fondu úloh Apache Spark. Tento fond Spark by měl být vytvořen nezávisle na aktuálním fondu 3.1.
Místní upgrade na Spark 3.3:
- Přihlaste se k Power Apps a vyberte preferované prostředí.
- V levém navigačním podokně vyberte Azure Synapse Link. Pokud se položka nenachází v levém podokně navigace, vyberte možnost …Více a poté vyberte požadovanou položku.
- Otevřete profil Azure Synapse Link a poté vyberte Upgradovat na Apache Spark 3.3 s Delta Lake 2.2.
- Ze seznamu vyberte dostupný fond Spark a poté vyberte Aktualizovat.
Poznámka
K upgradu fondu Spark dojde pouze při spuštění nové úlohy Spark konverze Delta Lake. Ujistěte se, že máte po výběru možnosti Aktualizovat alespoň jednu změnu dat.