Vytvoření extraktoru v Microsoft Syntex
Platí pro: ✓ Nestrukturované zpracování dokumentů
Před nebo po vytvoření modelu klasifikátoru pro automatizaci identifikace a klasifikace konkrétních typů dokumentů můžete volitelně zvolit přidání extraktorů do modelu, aby se z těchto dokumentů vytáhly konkrétní informace. Můžete například chtít, aby váš model nejen identifikoval všechny dokumenty pro prodloužení smlouvy přidané do knihovny dokumentů, ale také zobrazoval datum zahájení služby pro každý dokument jako hodnotu sloupce v knihovně dokumentů.
Pro každou entitu v dokumentu, který chcete extrahovat, musíte vytvořit extraktor. V našem příkladu chceme extrahovat datum zahájení služby pro každý dokument prodloužení smlouvy , který je identifikován modelem. Chceme mít možnost zobrazit v knihovně dokumentů zobrazení všech dokumentů pro prodloužení platnosti smlouvy se sloupcem, který u každého dokumentu zobrazuje hodnotu data zahájení služby .
Poznámka
Chcete-li vytvořit extraktor, použijete stejné soubory, které jste předtím nahráli, abyste mohli klasifikátor vytrénovat.
Pojmenování extraktoru
Na domovské stránce modelu na dlaždici Vytvořit a vytrénovat extraktory vyberte Trénovat extraktor.
Na obrazovce Nový extraktor entit zadejte název extraktoru do pole Název nového extraktoru . Pokud například chcete extrahovat počáteční datum služby z každého dokumentu o prodloužení smlouvy, pojmenujte ho Datum zahájení služby. Můžete také použít dříve vytvořený sloupec (například sloupec spravovaných metadat).
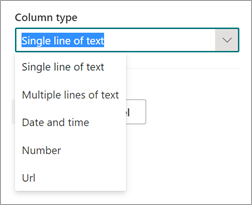
Ve výchozím nastavení je typ sloupce Jeden řádek textu. Pokud chcete změnit typ sloupce, vyberte Upřesnit nastavení>Typ sloupce a pak vyberte typ, který chcete použít.
Poznámka
U extraktorů s typem sloupce Jeden řádek textu je maximální počet znaků 255. Všechny znaky, které vyberete nad limit, se zkrátí. Pokud chcete vybrat více než 255 znaků, zvolte při vytváření extraktoru typ sloupce Více řádků textu .
Ve výchozím nastavení se vytvoří více řádků textových sloupců s omezením množství textu, které je možné přidat. V tomto případě se extrahovaný text může zdát zkrácený. Pokud k tomu dojde, můžete k odebrání limitu použít nastavení sloupce Povolit neomezenou délku v knihovnách dokumentů .
Až to budete hotovi, vyberte Vytvořit.
Přidání popisku
Dalším krokem je označení entity, kterou chcete extrahovat, v ukázkových trénovacích souborech.
Při vytváření extraktoru se otevře stránka extraktoru. Tady uvidíte seznam ukázkových souborů, přičemž první soubor v seznamu se zobrazí v prohlížeči.
V prohlížeči vyberte data, která chcete ze souborů extrahovat. Pokud například chcete extrahovat datum zahájení servisu, zvýrazněte hodnotu data v prvním souboru (pondělí 14. října 2022). a pak vyberte Uložit. Měla by se zobrazit hodnota ze souboru v seznamu Příklady s popisky ve sloupci Popisek .
Výběrem možnosti Další soubor automaticky uložte a otevřete další soubor v seznamu v prohlížeči. Nebo vyberte Uložit a pak vyberte jiný soubor ze seznamu Příklady s popisky .
V prohlížeči opakujte kroky 1 a 2 a pak opakujte, dokud popisek neuložíte do všech pěti souborů.
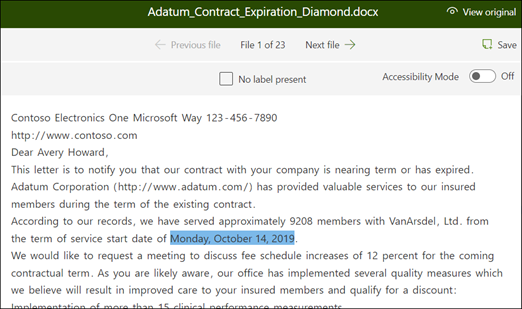
Jakmile označíte pět souborů, zobrazí se informační zpráva s informací o přechodu na trénování. Můžete zvolit další popisky více dokumentů nebo přejít na školení.
Hledání v souboru pomocí funkce Najít
Pomocí funkce Najít můžete v dokumentu vyhledat entitu, kterou chcete označit popiskem.
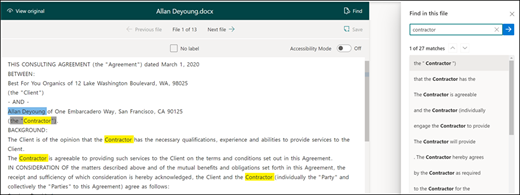
Funkce Najít je užitečná, pokud hledáte velký dokument nebo pokud je v dokumentu více instancí entity. Pokud najdete více instancí, můžete ve výsledcích hledání vybrat ten, který potřebujete, a přejít do daného umístění v prohlížeči a označit ho popiskem.
Přidat vysvětlení
V našem příkladu vytvoříme vysvětlení, které poskytne nápovědu k samotnému formátu entity a jeho variantám v ukázkových dokumentech. Například hodnota data může být v několika různých formátech, například:
- 10/14/2022
- úterý 14. října 2022
- pondělí 14. října 2022
S identifikací data zahájení služby můžete vytvořit vysvětlení vzoru.
- V části Vysvětlení vyberte Nový a zadejte název (například Datum).
- Jako Typ vyberte Seznam vzorů.
- Do pole Hodnota zadejte variantu data tak, jak se zobrazí v ukázkových souborech. Pokud máte například formáty kalendářních dat, které se zobrazují jako 0/00/0000, zadáte všechny varianty, které se zobrazí v dokumentech, například:
- 0/0/0000
- 0/00/0000
- 00/0/0000
- 00/00/0000
- Vyberte Uložit.
Poznámka
Další informace o typech vysvětlení najdete v tématu Typy vysvětlení.
Použití knihovny vysvětlení
Při vytváření vysvětlení pro položky, jako jsou kalendářní data, je jednodušší použít knihovnu vysvětlení než ručně zadat všechny varianty. Knihovna vysvětlení je sada předem připravených frází a vzorů vysvětlení. Knihovna se snaží poskytnout všechny formáty pro běžné seznamy frází nebo vzorů, jako jsou kalendářní data, telefonní čísla, PSČ a mnoho dalších.
Pro ukázku data zahájení služby je efektivnější použít předem připravené vysvětlení data v knihovně vysvětlení:
V části Vysvětlení vyberte Nový a pak vyberte Z knihovny vysvětlení.
V knihovně vysvětlení vyberte Datum. Můžete zobrazit všechny odchylky data, které jsou rozpoznány.
Vyberte možnost Přidat.
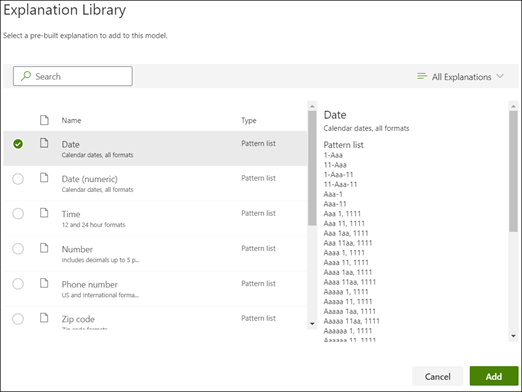
Na stránce Vytvořit vysvětlení vyplní pole automaticky informace o datu z knihovny vysvětlení. Vyberte Uložit.
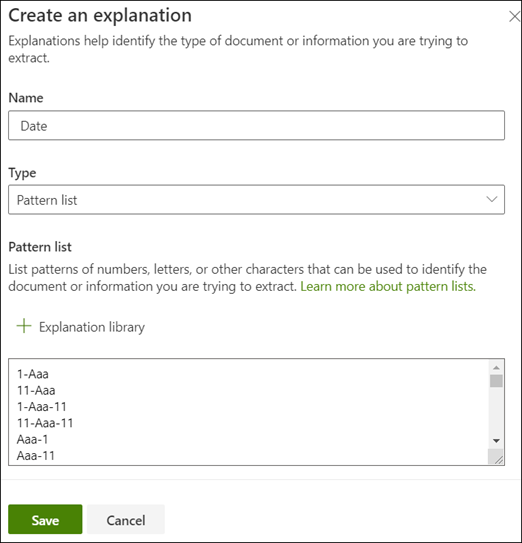
Trénování modelu
Uložení vysvětlení zahájí trénování. Pokud má váš model dostatek informací k extrahování dat z označených ukázkových souborů, zobrazí se každý soubor označený jako Shoda.
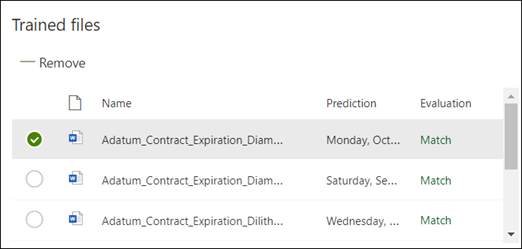
Pokud vysvětlení neobsahuje dostatek informací k vyhledání dat, která chcete extrahovat, bude každý soubor označený jako Neshoda. Pokud chcete zobrazit další informace o tom, proč došlo k neshodě, vyberte Neshodné soubory.
Přidat další vysvětlení
Neshoda často značí, že vysvětlení, které jsme poskytli, neposkytlo dostatek informací k extrahování hodnoty data zahájení služby tak, aby odpovídalo našim souborům s popiskem. Možná ho budete muset upravit nebo přidat další vysvětlení.
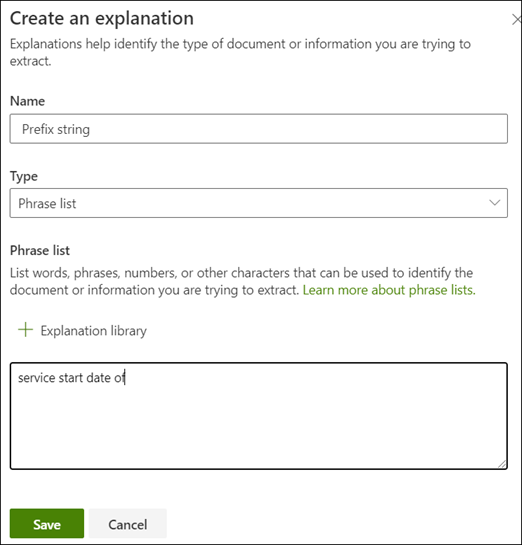
V našem příkladu si všimněte, že datum zahájení služby textového řetězce vždy předchází skutečné hodnotě. Pokud chcete pomoct s identifikací data zahájení služby, musíte vytvořit vysvětlení fráze.
V části Vysvětlení vyberte Nový a zadejte název (například Řetězec předpony).
Jako Typ vyberte Seznam frází.
Jako hodnotu použijte datum zahájení služby .
Vyberte Uložit.
Opětovné trénování modelu
Uložení vysvětlení zahájí trénování znovu, tentokrát s použitím obou vysvětlení v příkladu. Pokud má váš model dostatek informací k extrakci dat z označených ukázkových souborů, zobrazí se každý soubor označený jako Shoda.
Pokud se u označených souborů znovu zobrazí neshoda , budete pravděpodobně muset vytvořit další vysvětlení, abyste modelu poskytli další informace k identifikaci typu dokumentu, nebo zvažte provedení změn stávajících souborů.
Otestování modelu
Pokud se u ukázkových souborů s popiskem zobrazí shoda, můžete model otestovat na zbývajících neoznačené ukázkové soubory. Tento krok je nepovinný, ale je užitečný k vyhodnocení "kondice" nebo připravenosti modelu před jeho použitím tím, že ho otestujete na souborech, které model ještě neviděl.
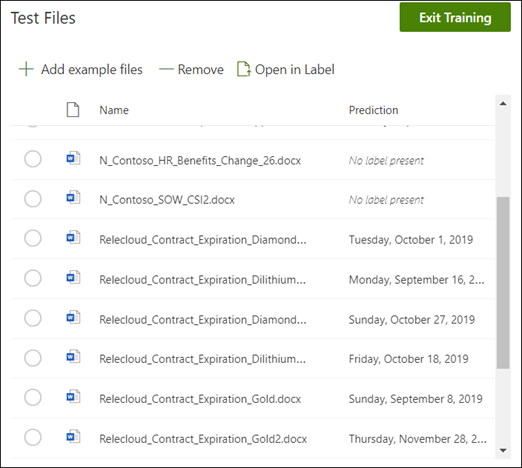
Na domovské stránce modelu vyberte kartu Test . Tím se model spustí na neoznačené ukázkové soubory.
V seznamu Testovací soubory se zobrazí ukázkové soubory, které ukazují, jestli model dokáže extrahovat informace, které potřebujete. Tyto informace vám pomůžou určit efektivitu klasifikátoru při identifikaci dokumentů.
Další upřesnění extraktoru
Pokud máte duplicitní entity a chcete extrahovat pouze jednu hodnotu nebo určitý počet hodnot, můžete nastavit pravidlo, které určí, jak se má zpracovat. Chcete-li přidat pravidlo pro upřesnění extrahovaných informací, postupujte takto:
Na domovské stránce modelu v části Extrakce entit vyberte extraktor, který chcete upřesnit, a pak vyberte Upřesnit extrahované informace.
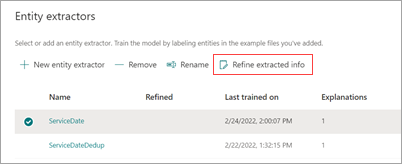
Na stránce Upřesnit extrahované informace vyberte jedno z následujících pravidel:
- Zachovat jednu nebo více prvních hodnot
- Zachovat jednu nebo více posledních hodnot
- Odebrat duplicitní hodnoty
- Zachovat jeden nebo více prvních řádků
- Zachovat jeden nebo více posledních řádků
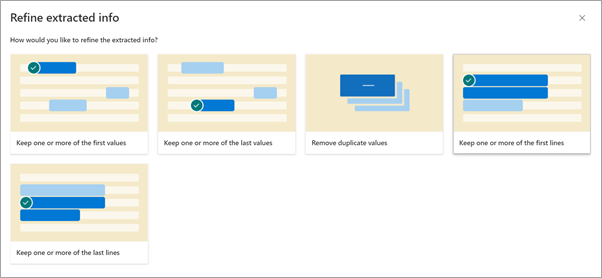
Zadejte počet řádků nebo hodnot, které chcete použít, a pak vyberte Upřesnit.
Pokud chcete pravidlo upravit změnou počtu řádků nebo hodnot, vyberte extraktor, který chcete upravit, vyberte Upřesnit extrahované informace, změňte číslo a pak vyberte Uložit.
Při testování extraktoru uvidíte upřesnění ve sloupci Výsledek upřesnění v seznamu Testovací soubory .
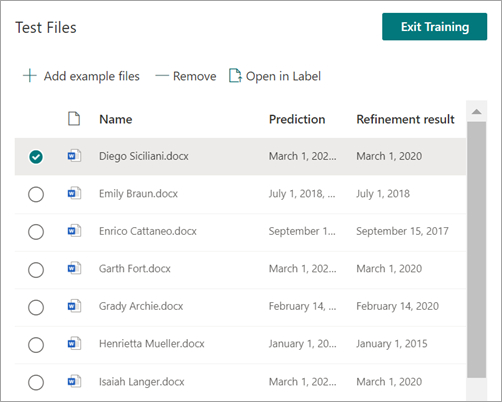
Pokud chcete odstranit pravidlo upřesnění u extraktoru, vyberte extraktor, ze kterého chcete pravidlo odebrat, vyberte Upřesnit extrahované informace a pak vyberte Odstranit.