Operátor make-series
Platí pro: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
Vytvořte řadu zadaných agregovaných hodnot na zadané ose.
Syntaxe
T [MakeSeriesParameters] [Column =] Aggregation [default = DefaultValue] [, ...] on | make-seriesAxisColumn [from start] [to end] step krok [by [Sloupec =] GroupExpression [, ...]]
Přečtěte si další informace o konvencích syntaxe.
Parametry
| Název | Type | Požadováno | Popis |
|---|---|---|---|
| Sloupec | string |
Název sloupce výsledků Výchozí hodnota je název odvozený z výrazu. | |
| DefaultValue | skalární | Výchozí hodnota, která se má použít místo chybějících hodnot. Pokud neexistuje žádný řádek s konkrétními hodnotami AxisColumn a GroupExpression, přiřadí se odpovídající prvek pole DefaultValue. Výchozí hodnota je 0. | |
| Agregace | string |
✔️ | Volání agregační funkce, například count() nebo avg(), s názvy sloupců jako argumenty. Podívejte se na seznam agregačních funkcí. S operátorem make-series lze použít pouze agregační funkce, které vracejí číselné výsledky. |
| AxisColumn | string |
✔️ | Sloupec, podle kterého bude řada seřazena. Hodnoty sloupců obvykle budou typu datetime nebo timespan všechny číselné typy jsou přijímány. |
| start | skalární | ✔️ | Nízká hodnota AxisColumn pro každou řadu, která se má sestavit. Pokud není zadané spuštění , bude to první interval nebo krok, který obsahuje data v jednotlivých řadách. |
| konec | skalární | ✔️ | Hodnota AxisColumn s vysokou vazbou, která není inkluzivní. Poslední index časové řady je menší než tato hodnota a začne plus celočíselnou násobek kroku, který je menší než konec. Pokud není zadaný konec , bude to horní mez posledního intervalu nebo kroku, který obsahuje data pro každou řadu. |
| krok | skalární | ✔️ | Rozdíl nebo velikost intervalu mezi dvěma po sobě jdoucími prvky matice AxisColumn . Seznam možných časových intervalů najdete v časovém rozsahu. |
| GroupExpression | Výraz nad sloupci, které poskytují sadu jedinečných hodnot. Obvykle se jedná o název sloupce, který již poskytuje omezenou sadu hodnot. | ||
| MakeSeriesParameters | Nula nebo více parametrů oddělených mezerami ve formě Hodnoty názvu = , které řídí chování. Viz podporované parametry řady. |
Poznámka:
Parametry začátku, konce a kroku slouží k vytvoření pole hodnot AxisColumn . Pole se skládá z hodnot mezi začátkem a koncem, přičemž hodnota kroku představuje rozdíl mezi jedním prvkem pole k dalšímu. Všechny hodnoty agregace jsou seřazené podle tohoto pole.
Podporované parametry řady
| Název | Popis |
|---|---|
kind |
Vytvoří výchozí výsledek, pokud je vstup operátoru make-series prázdný. Hodnota: nonempty |
hint.shufflekey=<key> |
Dotaz shufflekey sdílí zatížení dotazu na uzly clusteru pomocí klíče pro dělení dat. Zobrazit dotaz náhodného prohazování |
Poznámka:
Pole vygenerovaná řadou make-series jsou omezena na 1048576 hodnoty (2^20). Při pokusu o vygenerování většího pole s make-series dojde k chybě nebo zkrácené matici.
Alternativní syntaxe
T | make-series [Sloupec =] Agregace [ =default DefaultValue] [, ...] on AxisColumn range(instart, stop, step) [by [Column =] GroupExpression [, ...]]
Vygenerovaná řada z alternativní syntaxe se liší od hlavní syntaxe ve dvou aspektech:
- Hodnota stop je inkluzivní.
- Binning osy indexu se vygeneruje pomocí bin() a ne bin_at(), což znamená, že začátek nemusí být zahrnut do vygenerované řady.
Doporučujeme použít hlavní syntaxi make-series, nikoli alternativní syntaxi.
Návraty
Vstupní řádky jsou uspořádány do skupin se stejnými hodnotami by výrazů a počátečním) výrazembin_at( kroku,AxisColumn., Pak se zadané agregační funkce počítají přes každou skupinu a vytvoří řádek pro každou skupinu. Výsledek obsahuje by sloupce, sloupec AxisColumn a také alespoň jeden sloupec pro každou vypočítanou agregaci. (Agregace ve více sloupcích nebo nečíselných výsledcích nejsou podporované.)
Tento průběžný výsledek má tolik řádků, kolik existuje jedinečných kombinací počátečních bybin_at(hodnot kroku,) AxisColumn.,
Nakonec řádky z přechodného výsledku uspořádané do skupin se stejnými hodnotami by výrazů a všechny agregované hodnoty jsou uspořádány do polí (hodnoty typu dynamic ). Pro každou agregaci je jeden sloupec, který obsahuje pole se stejným názvem. Poslední sloupec je matice obsahující hodnoty AxisColumn binned podle zadaného kroku.
Poznámka:
I když pro agregační i seskupovací výrazy můžete zadat libovolné výrazy, je efektivnější používat jednoduché názvy sloupců.
Seznam agregačních funkcí
| Function | Popis |
|---|---|
| avg() | Vrátí průměrnou hodnotu ve skupině. |
| avgif() | Vrátí průměr s predikátem skupiny. |
| count() | Vrátí počet skupin. |
| countif() | Vrátí počet s predikátem skupiny. |
| dcount() | Vrátí přibližný počet jedinečných prvků skupiny. |
| dcountif() | Vrátí přibližný počet jedinečných hodnot s predikátem skupiny. |
| max() | Vrátí maximální hodnotu ve skupině. |
| maxif() | Vrátí maximální hodnotu s predikátem skupiny. |
| min() | Vrátí minimální hodnotu ve skupině. |
| minif() | Vrátí minimální hodnotu s predikátem skupiny. |
| percentil() | Vrátí hodnotu percentilu ve skupině. |
| take_any() | Vrátí náhodnou neprázdnou hodnotu pro skupinu. |
| stdev() | Vrátí směrodatnou odchylku ve skupině. |
| sum() | Vrátí součet prvků ve skupině. |
| sumif() | Vrátí součet prvků s predikátem skupiny. |
| variance() | Vrátí odchylku napříč skupinou. |
Seznam funkcí analýzy řad
| Function | Popis |
|---|---|
| series_fir() | Použije filtr konečných impulsových odpovědí . |
| series_iir() | Použije filtr nekonečná odezva impulsu. |
| series_fit_line() | Najde přímku, která je nejlepší aproximací vstupu. |
| series_fit_line_dynamic() | Najde čáru, která je nejlepší aproximací vstupu a vrací dynamický objekt. |
| series_fit_2lines() | Najde dva řádky, které jsou nejlepší aproximací vstupu. |
| series_fit_2lines_dynamic() | Najde dva řádky, které jsou nejlepší aproximací vstupu a vrací dynamický objekt. |
| series_outliers() | Skóre bodů anomálií v řadě |
| series_periods_detect() | Najde nejvýznamnější období, která existují v časové řadě. |
| series_periods_validate() | Zkontroluje, jestli časová řada obsahuje pravidelné vzory daných délek. |
| series_stats_dynamic() | Vrácení více sloupců se společnými statistikami (min/max/variance/stdev/average) |
| series_stats() | Vygeneruje dynamickou hodnotu pomocí společné statistiky (min/max/variance/stdev/average). |
Úplný seznam analytických funkcí řady najdete v tématu: Funkce zpracování řad
Seznam interpolačních funkcí řad
| Function | Popis |
|---|---|
| series_fill_backward() | Provede interpolaci chybějících hodnot v řadě dozadu. |
| series_fill_const() | Nahradí chybějící hodnoty v řadě zadanou konstantní hodnotou. |
| series_fill_forward() | Provádí interpolaci chybějících hodnot v řadě vpřed. |
| series_fill_linear() | Provádí lineární interpolaci chybějících hodnot v řadě. |
- Poznámka: Funkce interpolace ve výchozím nastavení předpokládají
nulljako chybějící hodnotu. Proto zadejtedefault=double(null) vmake-seriespřípadě, že máte v úmyslu použít interpolační funkce pro řadu.
Příklady
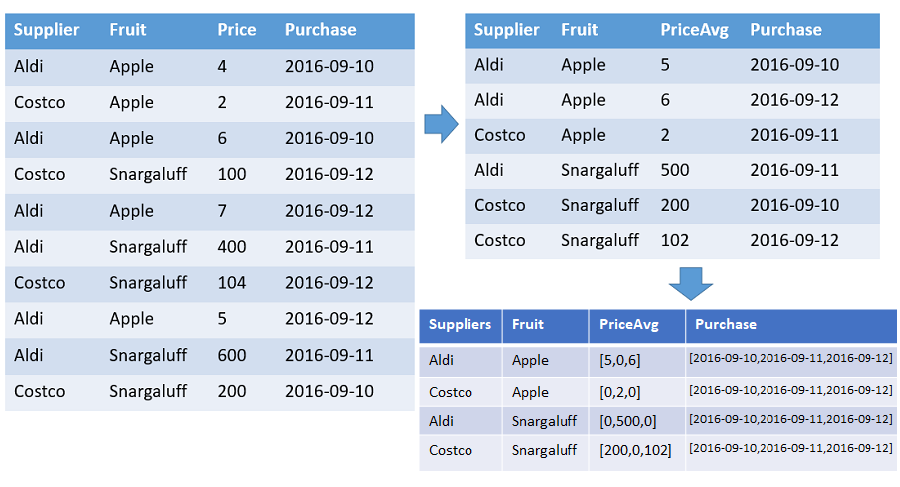
Tabulka, která zobrazuje pole čísel a průměrných cen každého ovoce od každého dodavatele objednaného podle časového razítka se zadaným rozsahem. Ve výstupu je řádek pro každou odlišnou kombinaci ovoce a dodavatele. Ve výstupních sloupcích se zobrazují ovoce, dodavatel a pole: count, average a celá časová osa (od 1. 1. 2016 do 10. 2016). Všechna pole jsou seřazená podle příslušného časového razítka a všechny mezery jsou vyplněné výchozími hodnotami (0 v tomto příkladu). Všechny ostatní vstupní sloupce se ignorují.
T | make-series PriceAvg=avg(Price) default=0
on Purchase from datetime(2016-09-10) to datetime(2016-09-13) step 1d by Supplier, Fruit
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| make-series avg(metric) on timestamp from stime to etime step interval
| avg_metric | časové razítko |
|---|---|
| [ 4.0, 3.0, 5.0, 0.0, 10.5, 4.0, 3.0, 8.0, 6.5 ] | [ "2017-01-01T00:00:00.0000000Z", "2017-01-02T00:00:00.0000000Z", "2017-01-03T00:00:00.0000000Z", "2017-01-04T00:00:00.0000000Z", "2017-01-05T00:00:00.0000000Z", "2017-01-06T00:00:00.0000000Z", "2017-01-07T00:00:00.0000000Z", "2017-01-08T00:00:00.0000000Z", "2017-01-09T00:00:00.0000000Z" ] |
Když je vstup make-series prázdný, výchozí chování make-series vytvoří prázdný výsledek.
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| take 0
| make-series avg(metric) default=1.0 on timestamp from stime to etime step interval
| count
Výstup
| Počet |
|---|
| 0 |
Použití kind=nonempty vygeneruje make-series neprázdný výsledek výchozích hodnot:
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| take 0
| make-series kind=nonempty avg(metric) default=1.0 on timestamp from stime to etime step interval
Výstup
| avg_metric | časové razítko |
|---|---|
| [ 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0 ] |
[ "2017-01-01T00:00:00.000000Z", "2017-01-02T00:00:00.000000Z", "2017-01-03T00:00:00.000000Z", "2017-01-04T00:00:00.000000Z", "2017-01-05T00:00:00.000000Z", "2017-01-06T00:00:00.000000Z", "2017-01-07T00:00:00.000000Z", "2017-01-08T00:00:00.000000Z", "2017-01-09T00:00:00.0000000Z" ] |