Multivariační detekce anomálií
Obecné informace o detekci vícevariátových anomálií v sadě Real-Time Intelligence najdete v tématu Vícevariát detekce anomálií v Microsoft Fabric – přehled. V tomto kurzu použijete ukázková data k trénování vícevariátového modelu detekce anomálií pomocí modulu Spark v poznámkovém bloku Pythonu. Následně předpovídáte anomálie, když použijete natrénovaný model na nová data pomocí motoru Eventhouse. Několik prvních kroků nastaví vaše prostředí a následující kroky vytrénuje model a předpovídá anomálie.
Požadavky
- Pracovní prostor s kapacitou s podporou Microsoft Fabric
- Role správce, přispěvatele nebo členav pracovním prostoru Tato úroveň oprávnění je nutná k vytvoření položek, jako je prostředí.
- Eventhouse ve vašem pracovním prostoru s databází.
- Stažení ukázkových dat z úložiště GitHub
- Stažení poznámkového bloku z úložiště GitHub
Část 1 – Povolení dostupnosti OneLake
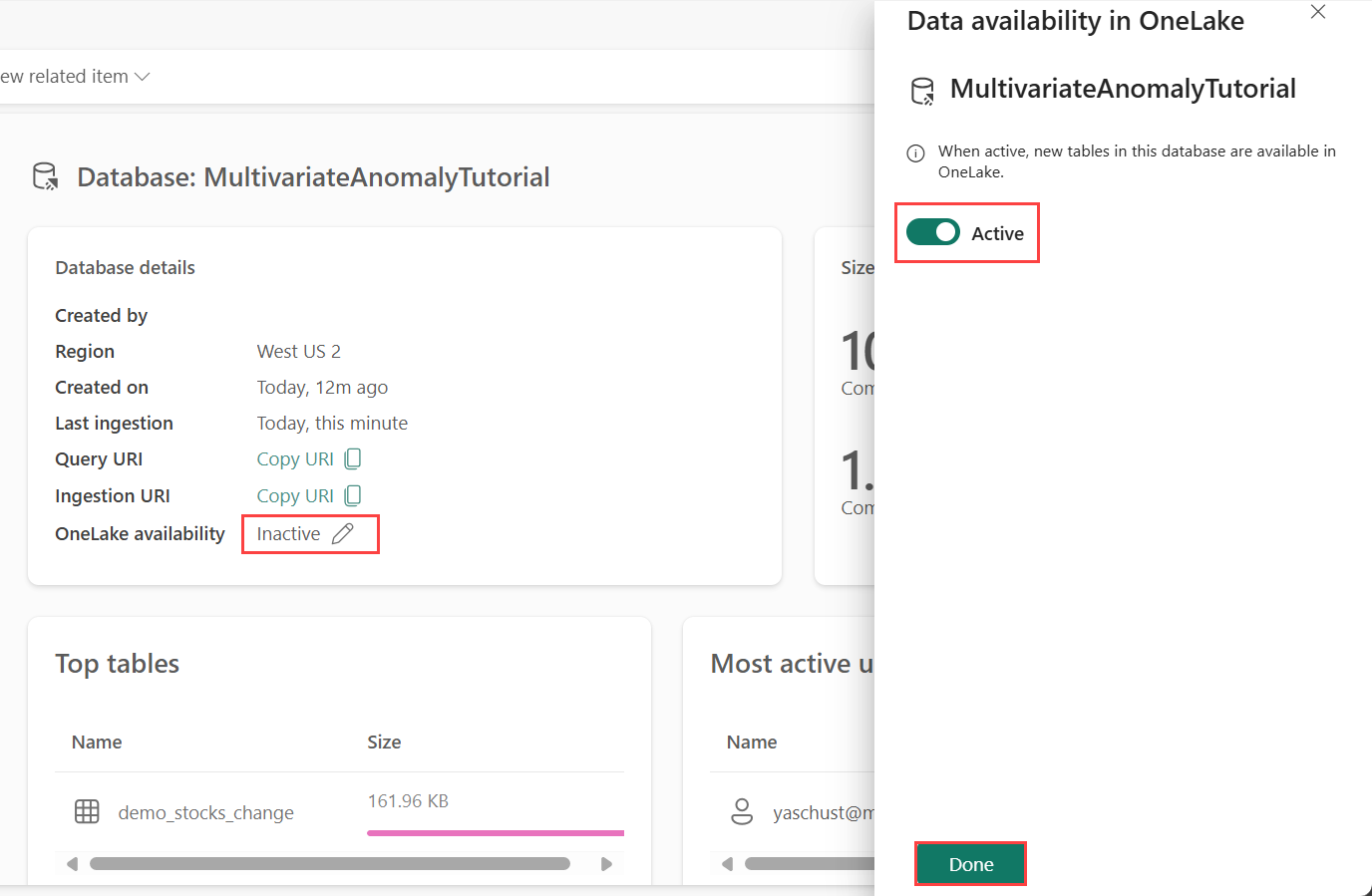
Dostupnost OneLake musí být povolená před získáním dat v Eventhouse. Tento krok je důležitý, protože umožňuje, aby data, která ingestujete, byla dostupná ve OneLake. V pozdějším kroku budete ke stejným datům přistupovat z poznámkového bloku Spark, abyste mohli model trénovat.
V pracovním prostoru vyberte eventhouse, který jste vytvořili v požadavcích. Zvolte databázi, do které chcete ukládat data.
V podokně podrobností o databáze přepněte tlačítko dostupnosti OneLake na Zapnuto.
Část 2 – Povolení modulu plug-in KQL Python
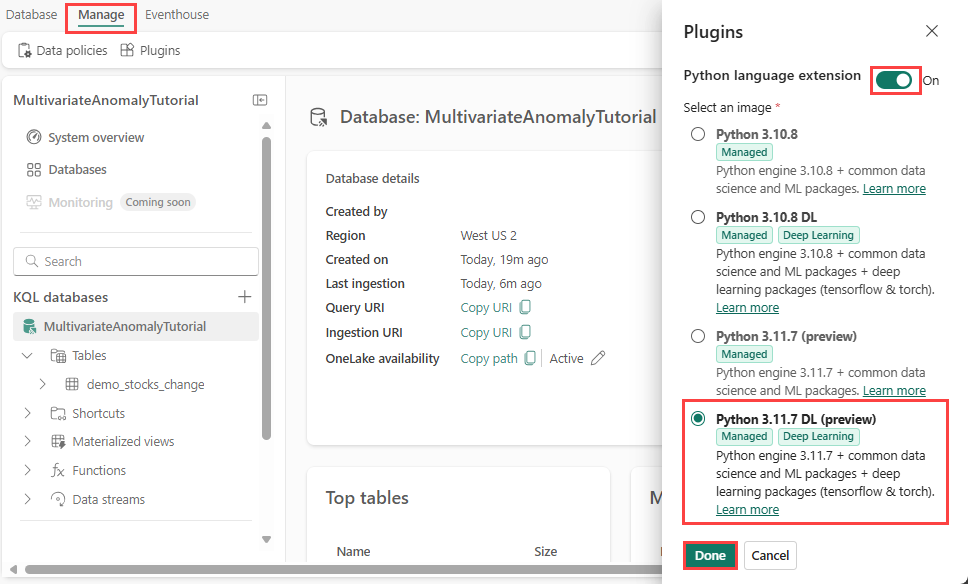
V tomto kroku povolíte modul plug-in Python ve službě Eventhouse. Tento krok je nutný ke spuštění kódu Pythonu predikce anomálií v sadě dotazů KQL. Je důležité zvolit správný obrázek, který obsahuje balíček detektoru anomálií časových řad .
Na obrazovce Eventhouse vyberte z pásu karet >plug-iny.
V podokně Moduly plug-in přepněte rozšíření jazyka Python naZapnuto.
Vyberte Python 3.11.7 DL (Preview).
Vyberte Hotovo.

Část 3 – Vytvoření prostředí Sparku
V tomto kroku vytvoříte prostředí Spark pro spuštění poznámkového bloku Pythonu, který trénuje model detekce anomálií s využitím modulu Spark. Další informace o vytváření prostředí najdete v tématu Vytváření a správa prostředí.
V pracovním prostoru vyberte + Nová položka pak Prostředí.
Zadejte název MVAD_ENV prostředí a pak vyberte Vytvořit.
Na záložce Domovská prostředí vyberte Runtime>1.2 (Spark 3.4, Delta 2.4).
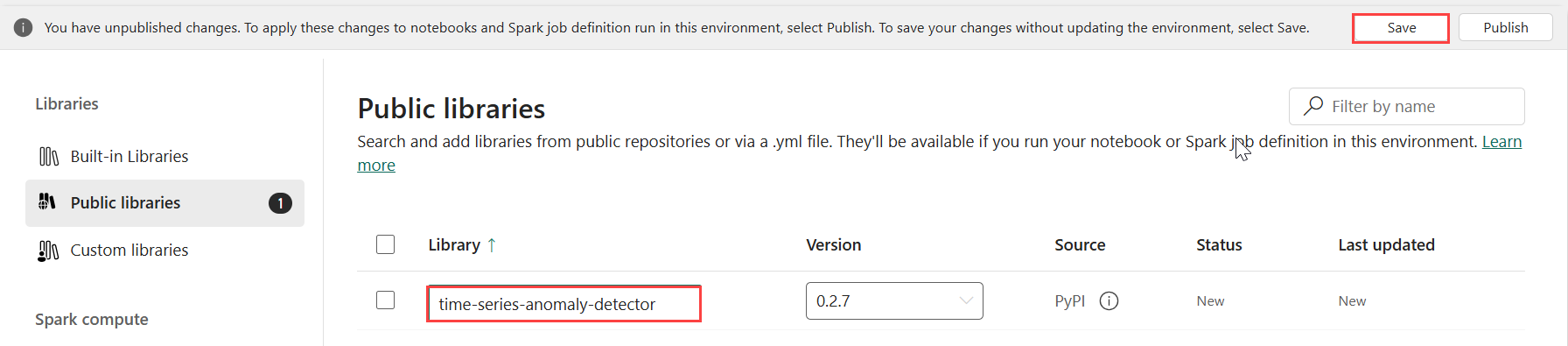
V části Knihovny vyberte Veřejné knihovny.
Vyberte Přidat z PyPI.
Do vyhledávacího pole zadejte detektor časových řad anomálií. Verze se automaticky naplní nejnovější verzí. Tento kurz byl vytvořen pomocí verze 0.3.2.
Zvolte Uložit.
Vyberte kartu Domů v prostředí.
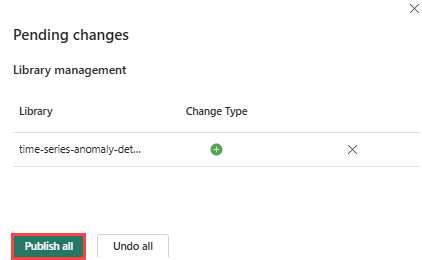
Na pásu karet vyberte ikonu Publikovat.

Zvolte Publikovat vše. Dokončení tohoto kroku může trvat několik minut.


Část 4– Načtení dat do eventhouse
Najeďte myší na databázi KQL, do které chcete ukládat data. Vyberte nabídku Další [...]>Získání datového>místního souboru
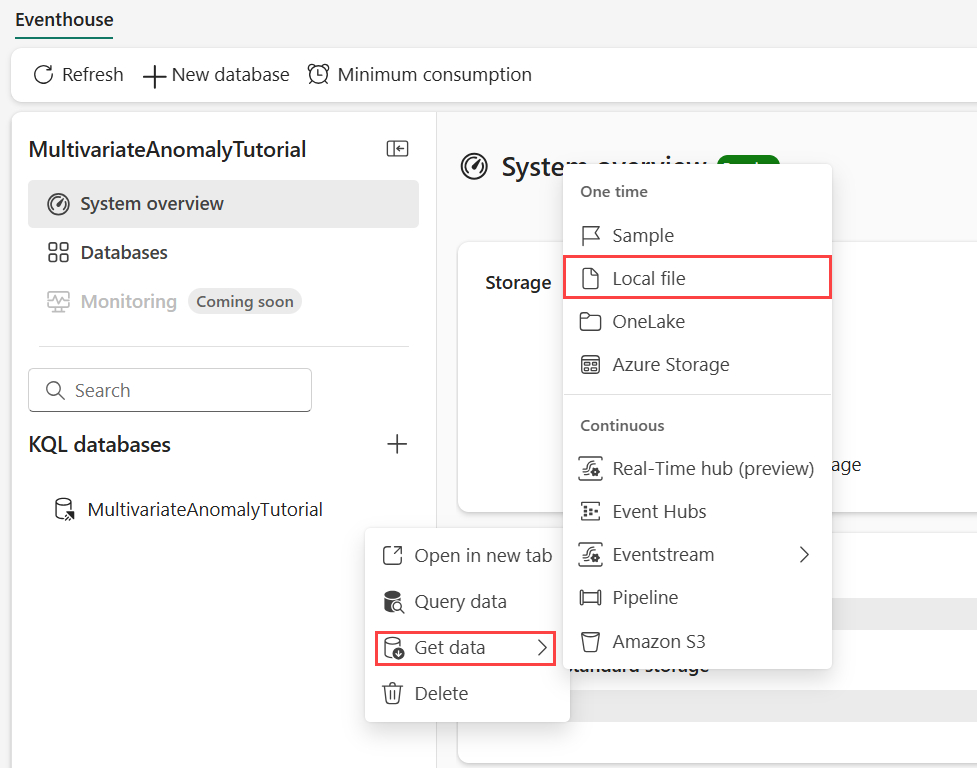
Vyberte + Nová tabulka a jako název tabulky zadejte demo_stocks_change .
V dialogovém okně nahrát data vyberte Vyhledat soubory a nahrajte ukázkový datový soubor stažený v části Požadavky.
Vyberte Další.
V části Kontrola dat přepněte první řádek záhlaví sloupce na Zapnuto.
Vyberte Dokončit.
Po nahrání dat vyberte Zavřít.
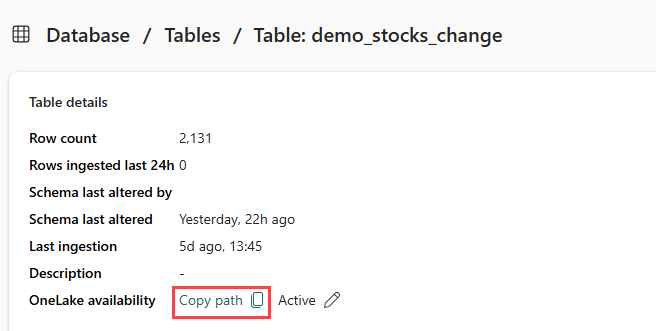
Část 5 – Zkopírování cesty OneLake do tabulky
Ujistěte se, že jste vybrali tabulku demo_stocks_change . V podokně s podrobnostmi tabulky vyberte složku OneLake, abyste zkopírovali cestu OneLake do schránky. Uložte tento zkopírovaný text do textového editoru, kam se má použít v pozdějším kroku.
Část 6 – Příprava poznámkového bloku
Vyberte váš pracovní prostor.
Vyberte Importovat, Poznámkový blok a pak Z tohoto počítače.
Vyberte Nahrát a zvolte poznámkový blok, který jste stáhli v požadavcích.
Po nahrání poznámkového bloku můžete poznámkový blok najít a otevřít z pracovního prostoru.
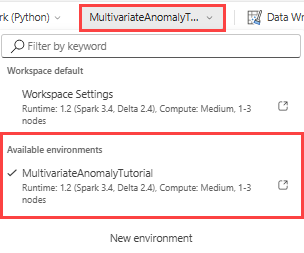
Na horním pásu karet vyberte výchozí rozevírací seznam Pracovní prostor a vyberte prostředí, které jste vytvořili v předchozím kroku.
Část 7– Spuštění poznámkového bloku
Import standardních balíčků
import numpy as np import pandas as pdSpark potřebuje identifikátor URI ABFSS k zabezpečenému připojení k úložišti OneLake, takže další krok definuje tuto funkci pro převod identifikátoru URI OneLake na identifikátor URI ABFSS.
def convert_onelake_to_abfss(onelake_uri): if not onelake_uri.startswith('https://'): raise ValueError("Invalid OneLake URI. It should start with 'https://'.") uri_without_scheme = onelake_uri[8:] parts = uri_without_scheme.split('/') if len(parts) < 3: raise ValueError("Invalid OneLake URI format.") account_name = parts[0].split('.')[0] container_name = parts[1] path = '/'.join(parts[2:]) abfss_uri = f"abfss://{container_name}@{parts[0]}/{path}" return abfss_uriZástupný symbol OneLakeTableURI nahraďte identifikátorem URI OneLake zkopírovaným z části 5– Zkopírujte cestu OneLake do tabulky a načtěte tabulku demo_stocks_change do datového rámce pandas.
onelake_uri = "OneLakeTableURI" # Replace with your OneLake table URI abfss_uri = convert_onelake_to_abfss(onelake_uri) print(abfss_uri)df = spark.read.format('delta').load(abfss_uri) df = df.toPandas().set_index('Date') print(df.shape) df[:3]Spuštěním následujících buněk připravte trénovací a prediktivní datové rámce.
Poznámka:
Skutečné předpovědi budou spuštěny na datech eventhouse v části 9– Predict-anomalies-in-the-kql-queryset. Pokud byste v produkčním scénáři streamovali data do centra událostí, předpovědi by se prováděly na nových streamovaných datech. Pro účely kurzu byla datová sada rozdělena podle data do dvou částí pro trénování a predikci. Jedná se o simulaci historických dat a nových streamovaných dat.
features_cols = ['AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'] cutoff_date = pd.to_datetime('2023-01-01')train_df = df[df.Date < cutoff_date] print(train_df.shape) train_df[:3]train_len = len(train_df) predict_len = len(df) - train_len print(f'Total samples: {len(df)}. Split to {train_len} for training, {predict_len} for testing')Spuštěním buněk vytrénujte model a uložte ho do registru modelů Fabric MLflow.
import mlflow from anomaly_detector import MultivariateAnomalyDetector model = MultivariateAnomalyDetector()sliding_window = 200 param s = {"sliding_window": sliding_window}model.fit(train_df, params=params)with mlflow.start_run(): mlflow.log_params(params) mlflow.set_tag("Training Info", "MVAD on 5 Stocks Dataset") model_info = mlflow.pyfunc.log_model( python_model=model, artifact_path="mvad_artifacts", registered_model_name="mvad_5_stocks_model", )Spuštěním následující buňky extrahujte registrovanou cestu modelu, která se má použít k predikci pomocí sandboxu Kusto Python.
mi = mlflow.search_registered_models(filter_string="name='mvad_5_stocks_model'")[0] model_abfss = mi.latest_versions[0].source print(model_abfss)Zkopírujte identifikátor URI modelu z posledního výstupu buňky pro použití v pozdějším kroku.
Část 8 – Nastavení sady dotazů KQL
Obecné informace najdete v tématu Vytvoření sady dotazů KQL.
- V pracovním prostoru vyberte + Nová položka>KQL Queryset.
- Zadejte název MultivariateAnomalyDetectionTutoriala pak vyberte Vytvořit.
- V okně centra dat OneLake vyberte databázi KQL, do které jste data uložili.
- Vyberte Připojit.
Část 9– Předpověď anomálií v sadě dotazů KQL
Spusťte následující dotaz '.create-or-alter function' pro definování uložené funkce
predict_fabric_mvad_fl():.create-or-alter function with (folder = "Packages\\ML", docstring = "Predict MVAD model in Microsoft Fabric") predict_fabric_mvad_fl(samples:(*), features_cols:dynamic, artifacts_uri:string, trim_result:bool=false) { let s = artifacts_uri; let artifacts = bag_pack('MLmodel', strcat(s, '/MLmodel;impersonate'), 'conda.yaml', strcat(s, '/conda.yaml;impersonate'), 'requirements.txt', strcat(s, '/requirements.txt;impersonate'), 'python_env.yaml', strcat(s, '/python_env.yaml;impersonate'), 'python_model.pkl', strcat(s, '/python_model.pkl;impersonate')); let kwargs = bag_pack('features_cols', features_cols, 'trim_result', trim_result); let code = ```if 1: import os import shutil import mlflow model_dir = 'C:/Temp/mvad_model' model_data_dir = model_dir + '/data' os.mkdir(model_dir) shutil.move('C:/Temp/MLmodel', model_dir) shutil.move('C:/Temp/conda.yaml', model_dir) shutil.move('C:/Temp/requirements.txt', model_dir) shutil.move('C:/Temp/python_env.yaml', model_dir) shutil.move('C:/Temp/python_model.pkl', model_dir) features_cols = kargs["features_cols"] trim_result = kargs["trim_result"] test_data = df[features_cols] model = mlflow.pyfunc.load_model(model_dir) predictions = model.predict(test_data) predict_result = pd.DataFrame(predictions) samples_offset = len(df) - len(predict_result) # this model doesn't output predictions for the first sliding_window-1 samples if trim_result: # trim the prefix samples result = df[samples_offset:] result.iloc[:,-4:] = predict_result.iloc[:, 1:] # no need to copy 1st column which is the timestamp index else: result = df # output all samples result.iloc[samples_offset:,-4:] = predict_result.iloc[:, 1:] ```; samples | evaluate python(typeof(*), code, kwargs, external_artifacts=artifacts) }Spusťte následující prediktivní dotaz a nahraďte identifikátor URI výstupního modelu identifikátorem URI zkopírovaným na konci kroku 7.
Dotaz zjistí vícevariátní anomálie na pěti akciích na základě natrénovaného modelu a vykreslí výsledky jako
anomalychart. Neobvyklé body se vykreslují u první akcie (AAPL), ale představují vícevariátní anomálie (jinými slovy anomálie společných změn pěti akcií v konkrétním datu).let cutoff_date=datetime(2023-01-01); let num_predictions=toscalar(demo_stocks_change | where Date >= cutoff_date | count); // number of latest points to predict let sliding_window=200; // should match the window that was set for model training let prefix_score_len = sliding_window/2+min_of(sliding_window/2, 200)-1; let num_samples = prefix_score_len + num_predictions; demo_stocks_change | top num_samples by Date desc | order by Date asc | extend is_anomaly=bool(false), score=real(null), severity=real(null), interpretation=dynamic(null) | invoke predict_fabric_mvad_fl(pack_array('AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'), // NOTE: Update artifacts_uri to model path artifacts_uri='enter your model URI here', trim_result=true) | summarize Date=make_list(Date), AAPL=make_list(AAPL), AMZN=make_list(AMZN), GOOG=make_list(GOOG), MSFT=make_list(MSFT), SPY=make_list(SPY), anomaly=make_list(toint(is_anomaly)) | render anomalychart with(anomalycolumns=anomaly, title='Stock Price Changest in % with Anomalies')
Výsledný graf anomálií by měl vypadat jako na následujícím obrázku:

Vyčištění prostředků
Po dokončení kurzu můžete odstranit prostředky, které jste vytvořili, abyste se vyhnuli dalším nákladům. Pokud chcete prostředky odstranit, postupujte takto:
- Přejděte na domovskou stránku pracovního prostoru.
- Odstraňte prostředí vytvořené v tomto kurzu.
- Odstraňte poznámkový blok vytvořený v tomto kurzu.
- Odstraňte eventhouse nebo databázi použitou v tomto kurzu.
- Odstraňte sadu dotazů KQL vytvořenou v tomto kurzu.