Implementace architektury medallion lakehouse v Microsoft Fabric
Tento článek představuje architekturu jezera medallion a popisuje, jak můžete implementovat lakehouse v Microsoft Fabric. Cílí na více cílových skupin:
- Datoví inženýři: Technický personál, který navrhuje, vytváří a udržuje infrastrukturu a systémy, které jejich organizaci umožňují shromažďovat, ukládat, zpracovávat a analyzovat velké objemy dat.
- Center of Excellence, IT a BI team: Týmy, které zodpovídají za dohled nad analýzou v celé organizaci.
- Správci prostředků infrastruktury: Správci, kteří jsou zodpovědní za dohled nad prostředky infrastruktury v organizaci.
Architektura medallion lakehouse, běžně označovaná jako architektura medallionu, je vzor návrhu, který organizace používají k logickému uspořádání dat v jezeře. Jedná se o doporučený přístup návrhu pro Prostředky infrastruktury.
Architektura medallionu se skládá ze tří různých vrstev – neboli zón. Každá vrstva označuje kvalitu dat uložených v jezeře s vyšší úrovní představující vyšší kvalitu. Tento přístup s více vrstvami vám pomůže vytvořit jeden zdroj pravdivých informací pro podnikové datové produkty.
Důležité je, že architektura medallionu zaručuje sadu vlastností atomicity, konzistence, izolace a stálosti (ACID) při procházení vrstev dat. Počínaje nezpracovanými daty připravuje řada ověření a transformací data optimalizovaná pro efektivní analýzu. Existují tři fáze medailiónu: bronzová (nezpracovaná), stříbro (ověřeno) a zlato (obohaceno).
Další informace najdete v tématu Co je architektura jezero medallion?.
OneLake a lakehouse v Fabric
Základem moderního datového skladu je datové jezero. Microsoft OneLake, což je jedno jednotné logické datové jezero pro celou organizaci. Automaticky se zřídí pro každého tenanta Fabric a je navržený tak, aby byl jediným umístěním pro všechna analytická data.
OneLake můžete použít k:
- Odeberte sila a snižte úsilí o správu. Všechna data organizace se ukládají, spravují a zabezpečí v rámci jednoho prostředku Data Lake. Vzhledem k tomu, že se OneLake zřizuje s vaším tenantem Fabric, neexistují žádné další prostředky, které by bylo potřeba zřídit ani spravovat.
- Omezte přesun a duplikaci dat. Cílem OneLake je uložit pouze jednu kopii dat. Méně kopií dat vede k menšímu počtu procesů přesunu dat a vede k nárůstu efektivity a snížení složitosti. V případě potřeby můžete vytvořit zástupce odkazující na data uložená v jiných umístěních a nekopírovat je do OneLake.
- Používá se s několika analytickými moduly. Data ve OneLake jsou uložená v otevřeném formátu. Data tak můžou být dotazována různými analytickými moduly, včetně Analysis Services (používá Power BI), T-SQL a Apache Spark. Další aplikace, které nejsou prostředky infrastruktury, můžou pro přístup k OneLake používat také rozhraní API a sady SDK.
Další informace najdete v tématu OneLake, OneDrive pro data.
Pokud chcete ukládat data ve OneLake, vytvoříte v Prostředcích infrastruktury jezero . Lakehouse je platforma architektury dat pro ukládání, správu a analýzu strukturovaných a nestrukturovaných dat v jednom umístění. Může se snadno škálovat na velké objemy dat všech typů a velikostí souborů a protože je uložená v jednom umístění, je snadno sdílená a opakovaně použitá v celé organizaci.
Každý lakehouse má integrovaný koncový bod analýzy SQL, který odemyká funkce datového skladu, aniž by bylo nutné přesouvat data. To znamená, že data v jezeře můžete dotazovat pomocí dotazů SQL a bez jakéhokoli zvláštního nastavení.
Další informace naleznete v tématu Co je lakehouse v Microsoft Fabric?.
Tabulky a soubory
Při vytváření jezerahouse v prostředcích infrastruktury se pro tabulky a soubory automaticky zřídí dvě umístění fyzického úložiště.
- Tabulky jsou spravovanou oblastí pro hostování tabulek všech formátů v Apache Sparku (CSV, Parquet nebo Delta). Všechny tabulky, ať už automaticky nebo explicitně vytvořené, se rozpoznají jako tabulky v jezeře. Všechny tabulky Delta, které jsou datové soubory Parquet s transakčním protokolem založeném na souborech, jsou také rozpoznány jako tabulky.
- Soubory jsou nespravovanou oblastí pro ukládání dat v libovolném formátu souboru. Všechny soubory Delta uložené v této oblasti se automaticky nerozpoznají jako tabulky. Pokud chcete vytvořit tabulku přes složku Delta Lake v nespravované oblasti, budete muset explicitně vytvořit zástupce nebo externí tabulku s umístěním, které odkazuje na nespravovanou složku, která obsahuje soubory Delta Lake v Apache Sparku.
Hlavním rozdílem mezi spravovanou oblastí (tabulkami) a nespravovanou oblastí (soubory) je proces automatického zjišťování a registrace tabulek. Tento proces běží pouze přes libovolnou složku vytvořenou v spravované oblasti, ale ne v nespravované oblasti.
Průzkumník Lakehouse v Microsoft Fabric poskytuje jednotnou grafickou reprezentaci celého Lakehouse, aby uživatelé mohli procházet, přistupovat k nim a aktualizovat jejich data.
Další informace o automatickém zjišťování tabulek najdete v tématu Automatické zjišťování a registrace tabulek.
Delta Lake Storage
Delta Lake je optimalizovaná vrstva úložiště, která poskytuje základ pro ukládání dat a tabulek. Podporuje transakce ACID pro úlohy s velkými objemy dat a z tohoto důvodu je výchozím formátem úložiště v úložišti Fabric Lakehouse.
Důležité je, že Delta Lake poskytuje spolehlivost, zabezpečení a výkon v lakehouse pro streamování i dávkové operace. Interně ukládá data ve formátu souborů Parquet, ale také udržuje transakční protokoly a statistiky, které poskytují funkce a zlepšení výkonu oproti standardnímu formátu Parquet.
Formát Delta Lake oproti obecným formátům souborů přináší následující hlavní výhody.
- Podpora vlastností ACID, a zejména stálost, aby se zabránilo poškození dat.
- Rychlejší čtení dotazů.
- Zvýšená aktuálnost dat
- Podpora dávkových i streamovaných úloh
- Podpora vrácení dat zpět pomocí časového cestování Delta Lake
- Vylepšené dodržování právních předpisů a audit pomocí historie tabulek Delta Lake.
Prostředky infrastruktury standardizují formát souboru úložiště s Delta Lake a ve výchozím nastavení každý modul úloh v Prostředcích infrastruktury vytvoří tabulky Delta při zápisu dat do nové tabulky. Další informace najdete v tabulkách Lakehouse a Delta Lake.
Architektura medailionu v Fabric
Cílem architektury medailonu je přírůstkově a postupně zlepšit strukturu a kvalitu dat při procházení jednotlivých fází.
Architektura medallionu se skládá ze tří různých vrstev (neboli zón).
- Bronzová: Tato první vrstva také označuje nezpracovanou zónu, ukládá zdrojová data v původním formátu. Data v této vrstvě jsou obvykle jen pro připojení a neměnná.
- Silver: Tato vrstva také označuje jako rozšířená zóna, ukládá data zdrojová z bronzové vrstvy. Nezpracovaná data byla vyčištěna a standardizována a nyní je strukturovaná jako tabulky (řádky a sloupce). Může být také integrována s dalšími daty, aby poskytovala podnikové zobrazení všech obchodních entit, jako je zákazník, produkt a další.
- Gold: Tato konečná vrstva také označuje jako kurátorovaná zóna, ukládá data zdrojová ze stříbrné vrstvy. Data jsou zpřesněná tak, aby splňovala konkrétní požadavky na obchodní a analytickou činnost v podřízené oblasti. Tabulky obvykle odpovídají návrhu hvězdicového schématu, který podporuje vývoj datových modelů, které jsou optimalizované pro výkon a použitelnost.
Důležité
Protože fabric lakehouse představuje jednu zónu, vytvoříte jeden lakehouse pro každou ze tří zón.
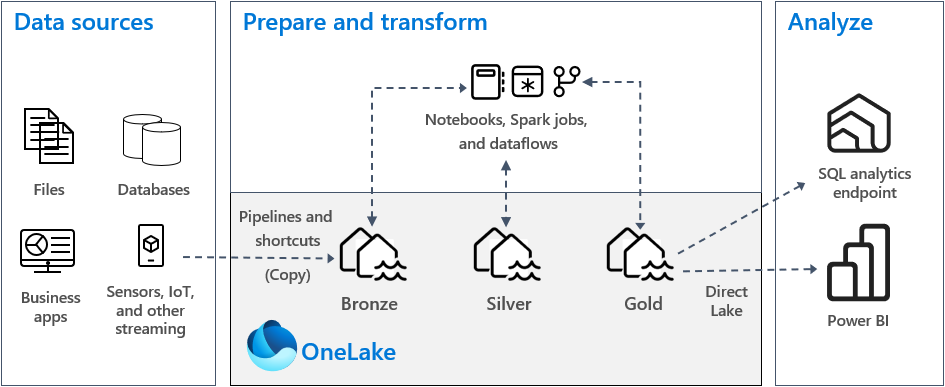
V typické implementaci architektury medallionu v Fabric ukládá bronzová zóna data ve stejném formátu jako zdroj dat. Pokud je zdrojem dat relační databáze, jsou tabulky Delta dobrou volbou. Stříbrné a zlaté zóny obsahují tabulky Delta.
Tip
Pokud chcete zjistit, jak vytvořit lakehouse, projděte si kompletní kurz scénáře Lakehouse.
Pokyny k fabric lakehouse
Tato část obsahuje pokyny související s implementací infrastruktury lakehouse pomocí architektury medailiónu.
Model nasazení
K implementaci architektury medailiónu v Fabric můžete použít buď jezerahouse (jednu pro každou zónu), datový sklad nebo kombinaci obou. Vaše rozhodnutí by mělo vycházet z vašich preferencí a odborných znalostí vašeho týmu. Mějte na paměti, že Prostředky infrastruktury poskytují flexibilitu: Můžete použít různé analytické moduly, které pracují na jedné kopii vašich dat v OneLake.
Tady jsou dva vzory, které je potřeba vzít v úvahu.
- Vzor 1: Vytvořte každou zónu jako jezero. V tomto případě podnikoví uživatelé přistupují k datům pomocí koncového bodu analýzy SQL.
- Vzor 2: Vytvořte bronzovou a stříbrnou zónu jako lakehouses a zlatou zónu jako datový sklad. V tomto případě podnikoví uživatelé přistupují k datům pomocí koncového bodu datového skladu.
I když můžete vytvořit všechny objekty lakehouse v jednom pracovním prostoru Fabric, doporučujeme, abyste každý z nich vytvořili ve vlastním samostatném samostatném pracovním prostoru Fabric. Tento přístup poskytuje větší kontrolu a lepší zásady správného řízení na úrovni zóny.
Pro bronzovou zónu doporučujeme uložit data v původním formátu nebo použít Parquet nebo Delta Lake. Pokud je to možné, udržujte data v původním formátu. Pokud zdrojová data pocházejí z OneLake, Azure Data Lake Store Gen2 (ADLS Gen2), Amazon S3 nebo Google, místo kopírování dat do bronzové zóny vytvořte zástupce v bronzové zóně.
Pro stříbrné a zlaté zóny doporučujeme používat tabulky Delta kvůli dalším funkcím a vylepšením výkonu, které poskytují. Prostředky infrastruktury standardizují formát Delta Lake a ve výchozím nastavení každý modul v Prostředcích infrastruktury zapisuje data v tomto formátu. Tyto moduly navíc používají optimalizaci doby zápisu V-Order do formátu souboru Parquet. Tato optimalizace umožňuje extrémně rychlé čtení výpočetními moduly Fabric, jako jsou Power BI, SQL, Apache Spark a další. Další informace najdete v tématu Optimalizace tabulek Delta Lake a pořadí V-Order.
A konečně, dnes mnoho organizací čelí masivnímu růstu objemů dat, spolu s rostoucí potřebou uspořádat a spravovat tato data logickým způsobem a zároveň usnadnit cílenější a efektivnější použití a zásady správného řízení. To může vést k vytvoření a správě decentralizované nebo federované organizace dat pomocí zásad správného řízení.
Pokud chcete tento cíl splnit, zvažte implementaci architektury datových sítí. Datová síť je model architektury, který se zaměřuje na vytváření datových domén, které nabízejí data jako produkt.
Architekturu datové sítě pro svá datová aktiva v Prostředcích infrastruktury můžete vytvořit vytvořením datových domén. Můžete vytvořit domény, které se mapují na vaše obchodní domény, například marketing, prodej, inventář, lidské zdroje a další. Architekturu medailonu pak můžete implementovat nastavením datových zón v rámci každé z vašich domén.
Další informace o doménách najdete v tématu Domény.
Principy úložiště dat tabulek Delta
Tato část popisuje další témata s pokyny souvisejícími s implementací architektury medallion lakehouse v prostředcích Fabric.
Velikost souboru
Obecně platí, že platforma pro velké objemy dat funguje lépe, když má malý počet velkých souborů, a ne velký počet malých souborů. Důvodem je to, že snížení výkonu nastane, když výpočetní modul musí spravovat mnoho metadat a operací se soubory. Pokud chcete dosáhnout lepšího výkonu dotazů, doporučujeme zaměřit se na datové soubory, které mají velikost přibližně 1 GB.
Delta Lake má funkci označovanou jako prediktivní optimalizace. Prediktivní optimalizace eliminuje potřebu ruční správy operací údržby pro tabulky Delta. Když je tato funkce povolená, Delta Lake automaticky identifikuje tabulky, které by mohly těžit z operací údržby, a pak optimalizuje jejich úložiště. Může transparentně shodovat mnoho menších souborů do velkých souborů a bez jakéhokoli dopadu na ostatní čtenáře a zapisovače dat. I když by tato funkce měla být součástí efektivity provozu a přípravy dat, má Fabric možnost optimalizovat tyto datové soubory i během zápisu dat. Další informace najdete v tématu Prediktivní optimalizace pro Delta Lake.
Historické uchovávání
Delta Lake ve výchozím nastavení udržuje historii všech provedených změn, což znamená, že velikost historických metadat v průběhu času roste. Na základě vašich obchodních požadavků byste se měli zaměřit na uchovávání historických dat pouze po určitou dobu, abyste snížili náklady na úložiště. Zvažte uchovávání historických dat pouze za poslední měsíc nebo jiné vhodné časové období.
Starší historická data můžete z tabulky Delta odebrat pomocí příkazu VACUUM. Mějte ale na paměti, že ve výchozím nastavení nemůžete odstranit historická data za posledních 7 dnů – to znamená zachovat konzistenci v datech. Výchozí počet dní je řízen vlastností delta.deletedFileRetentionDuration = "interval <interval>"tabulky . Určuje dobu, po kterou musí být soubor odstraněn dříve, než jej lze považovat za kandidáta na operaci vakua.
Oddíly tabulky
Při ukládání dat do každé zóny doporučujeme používat strukturu rozdělených složek, kdykoli je to možné. Tato technika pomáhá zlepšit možnosti správy dat a výkon dotazů. Obecně platí, že dělená data ve struktuře složek mají za následek rychlejší hledání konkrétních datových položek díky vyřazení nebo odstranění oddílů.
Při příchodu nových dat obvykle připojíte data k cílové tabulce. V některých případech ale můžete sloučit data, protože potřebujete aktualizovat stávající data současně. V takovém případě můžete provést operaci upsert pomocí příkazu MERGE. Pokud je cílová tabulka rozdělená na oddíly, nezapomeňte k urychlení operace použít filtr oddílů. Tímto způsobem může modul eliminovat oddíly, které nevyžadují aktualizaci.
Přístup k datům
Nakonec byste měli naplánovat a řídit, kdo potřebuje přístup k určitým datům v jezeře. Měli byste také porozumět různým vzorům transakcí, které budou používat při přístupu k datům. Pak můžete definovat správné schéma dělení tabulek a umístění dat pomocí indexů pořadí řazení Delta Lake.
Související obsah
Další informace o implementaci fabric lakehouse najdete v následujících zdrojích informací.
- Kurz: Kompletní scénář Lakehouse
- Tabulky Lakehouse a Delta Lake
- Průvodce rozhodováním Microsoft Fabric: Volba úložiště dat
- Optimalizace tabulek Delta Lake a pořadí V
- Potřeba optimalizace zápisu v Apache Sparku
- Otázky? Zkuste se zeptat komunity Fabric.
- Návrhy? Přispějte nápady ke zlepšení prostředků infrastruktury.