Dotazování koncového bodu analýzy SQL vaší databáze SQL v prostředcích infrastruktury
Platí pro:✅SQL Database v Microsoft Fabric
Každá databáze SQL Fabric se vytvoří s spárovaným koncovým bodem analýzy SQL. To vám umožní spouštět všechny dotazy na vytváření sestav na kopii dat OneLake, aniž byste se museli starat o dopad na produkční prostředí. Všechny dotazy na vytváření sestav byste měli spouštět na koncovém bodu analýzy SQL. Dotazujte databázi SQL přímo jenom na ty sestavy, které vyžadují nejaktuálnější data.
Požadavky
- Potřebujete existující kapacitu Fabric. Pokud ne, spusťte zkušební verzi Fabric.
- Ujistěte se, že v prostředcích infrastruktury povolíte databázi SQL pomocí nastavení tenanta portálu pro správu.
- Vytvořte nový pracovní prostor nebo použijte existující pracovní prostor Fabric.
- Vytvořte novou databázi SQL nebo použijte existující databázi SQL.
- Zvažte načtení ukázkových dat AdventureWorks do nové databáze SQL.
Přístup ke koncovému bodu analýzy SQL
Koncový bod analýzy SQL je možné dotazovat pomocí T-SQL několika způsoby:
První je prostřednictvím pracovního prostoru. Každá databáze SQL je spárovaná s výchozím sémantickým modelem a koncovým bodem analýzy SQL. Sémantický model a koncový bod analýzy SQL se vždy zobrazují společně s databází SQL v seznamu položek pracovního prostoru. K libovolné z nich se dostanete tak, že je vyberete podle názvu ze seznamu.
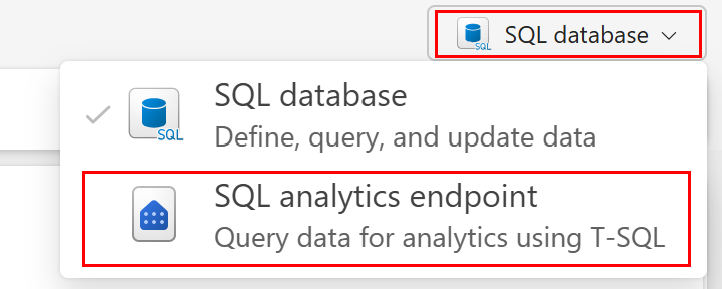
Koncový bod analýzy SQL je také přístupný z editoru dotazů SQL. To může být užitečné zejména při přepínání mezi databází a koncovým bodem analýzy SQL. Pomocí rozevíracího seznamu v pravém horním rohu přejděte z editoru na koncový bod analýzy.
Koncový bod analýzy SQL má také vlastní připojovací řetězec SQL, pokud ho chcete dotazovat přímo z nástrojů, jako je SQL Server Management Studio nebo rozšíření mssql pomocí nástroje Visual Studio Code. Pokud chcete získat připojovací řetězec, přečtěte si téma Vyhledání připojovací řetězec SQL.
Dotazování koncového bodu analýzy SQL
Otevřete existující databázi s některými daty nebo vytvořte novou databázi a načtěte ji s ukázkovými daty.
Rozbalte Průzkumník objektů a poznamenejte si tabulky v databázi.
Vyberte nabídku replikace v horní části editoru a vyberte Monitorovat replikaci.
Zobrazí se seznam obsahující tabulky v databázi. Pokud se jedná o novou databázi, budete chtít počkat na replikaci všech tabulek. Na panelu nástrojů je tlačítko aktualizovat. Pokud dojde k nějakým problémům s replikací dat, zobrazí se na této stránce.
Po replikaci tabulek zavřete stránku Monitorování replikace .
V rozevíracím seznamu v editoru dotazů SQL vyberte koncový bod analýzy SQL.
Teď vidíte, že se Průzkumník objektů změnily na prostředí skladu.
Vyberte některé z tabulek, aby se zobrazila data, která se čtou přímo z OneLake.
Vyberte místní nabídku (
...) pro libovolnou tabulku a v nabídce vyberte Vlastnosti . Tady uvidíte informace o OneLake aABFScestu k souboru.Zavřete stránku Vlastnosti a znovu vyberte místní nabídku (
...) pro jednu tabulku.Vyberte Nový dotaz a VYBERTE TOP 100. Spuštěním dotazu zobrazíte prvních 100 řádků dat, dotazovaných z koncového bodu sql Analytics, kopie databáze v OneLake.
Pokud máte v pracovním prostoru jiné databáze, můžete také spouštět dotazy s propojeními mezi databázemi. Výběrem tlačítka + Sklad v Průzkumník objektů přidejte koncový bod analýzy SQL pro jinou databázi. Dotazy T-SQL můžete zapsat podobně jako v následujících dotazech, které spojují různá úložiště dat Infrastruktury:
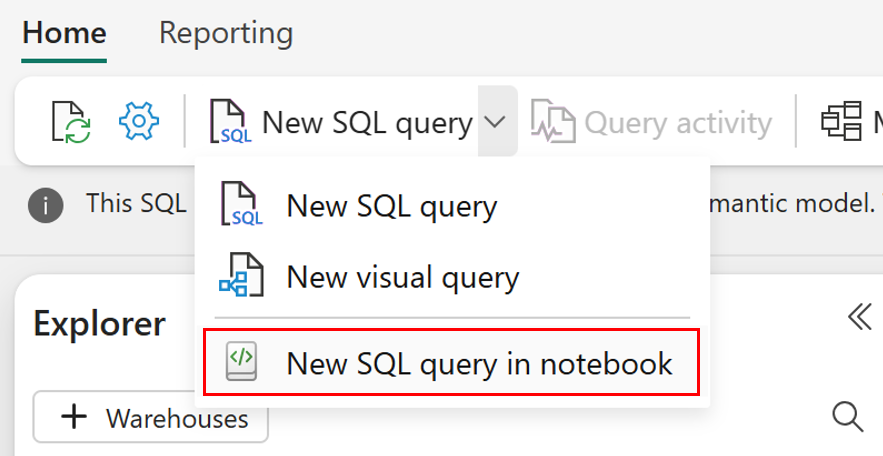
SELECT TOP (100) [a.AccountID], [a.Account_Name], [o.Order_Date], [o.Order_Amount] FROM [Contoso Sales Database].[dbo].[dbo_Accounts] a INNER JOIN [Contoso Order History Database].[dbo].[dbo_Orders] o ON a.AccountID = o.AccountID;Potom na panelu nástrojů vyberte rozevírací seznam Nový dotaz a v poznámkovém bloku zvolte Nový dotaz SQL.
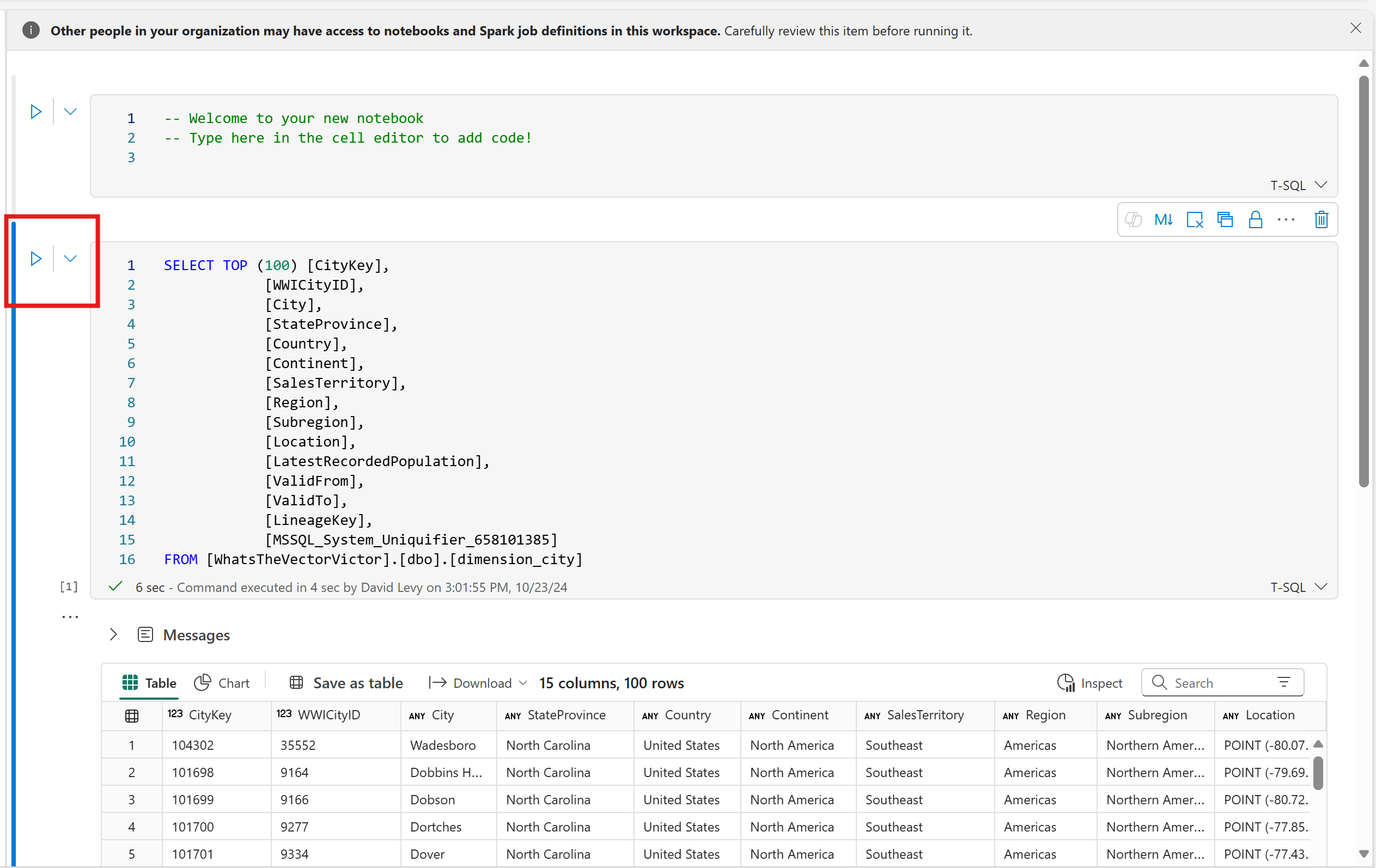
V prostředí poznámkového bloku vyberte místní nabídku (
...) vedle tabulky a pak vyberte SELECT TOP 100.
Pokud chcete spustit dotaz T-SQL, vyberte tlačítko přehrát vedle buňky dotazu v poznámkovém bloku.