Vyvinout, vyhodnotit a skórovat model prognózování pro prodej superstoru
Tento kurz představuje kompletní příklad pracovního postupu pro datovou vědu Synapse v rámci Microsoft Fabric. Scénář sestaví model prognózování, který používá historická prodejní data k predikci prodeje kategorií produktů v superstore.
Prognózování je zásadním aktivem při prodeji. Kombinuje historická data a prediktivní metody, které poskytují přehled o budoucích trendech. Prognózování může analyzovat minulé prodeje a identifikovat vzory a učit se od chování spotřebitelů za účelem optimalizace inventarizace, produkce a marketingových strategií. Tento proaktivní přístup zlepšuje adaptabilitu, rychlost odezvy a celkový výkon firem na dynamickém marketplace.
Tento kurz se věnuje těmto krokům:
- Načtení dat
- Použití průzkumné analýzy dat k pochopení a zpracování dat
- Vytrénujte model strojového učení pomocí open-source softwarového balíčku a sledujte experimenty s MLflow a funkcí automatického protokolování Fabricu.
- Uložení konečného modelu strojového učení a vytváření předpovědí
- Zobrazení výkonu modelu pomocí vizualizací Power BI
Požadavky
Získejte předplatné Microsoft Fabric. Nebo si zaregistrujte bezplatnou zkušební verzi Microsoft Fabric.
Přihlaste se do Microsoft Fabric.
Pomocí přepínače zážitků v levém dolním rohu domovské stránky přepněte na Fabric.

- V případě potřeby vytvořte Microsoft Fabric lakehouse, jak je popsáno v tématu Vytvoření lakehouse v Microsoft Fabric.
Sledujte v poznámkovém bloku
V poznámkovém bloku můžete zvolit jednu z těchto možností:
- Otevření a spuštění integrovaného poznámkového bloku v prostředí Pro datové vědy Synapse
- Nahrajte svůj poznámkový blok z GitHubu do prostředí pro datové zpracování v Synapse
Otevření integrovaného poznámkového bloku
Tento kurz doprovází ukázka prognózování prodeje poznámkový blok.
Pokud chcete otevřít ukázkový poznámkový blok pro tento kurz, postupujte podle pokynů v Příprava systému na kurzy datových věd.
Nezapomeňte připojit lakehouse k poznámkovému bloku, než začnete spouštět kód.
Importujte notebook z GitHubu
AIsample - Superstore Forecast.ipynb poznámkový blok doprovází tento kurz.
Pokud chcete otevřít doprovodný poznámkový blok pro tento kurz, postupujte podle pokynů v tématu Příprava systému na kurzy datových věd, abyste importovali poznámkový blok do svého pracovního prostoru.
Pokud chcete raději zkopírovat a vložit kód z této stránky, můžete vytvořit nový poznámkový blok.
Než začnete spouštět kód, nezapomeňte k poznámkovému bloku připojit lakehouse.
Krok 1: Načtení dat
Datová sada obsahuje 9 995 instancí prodeje různých produktů. Obsahuje také 21 atributů. Tato tabulka pochází ze souboru Superstore.xlsx použitého v tomto poznámkovém bloku:
| ID řádku | ID objednávky | Datum objednávky | Datum expedice | Mód dopravy | ID zákazníka | Jméno zákazníka | Segment | Země | Město | Stát | PSČ | Oblast | ID produktu | Kategorie | Sub-Category | Název produktu | Prodej | Množství | Sleva | Zisk |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | US-2015-108966 | 2015-10-11 | 2015-10-18 | Standardní třída | SO-20335 | Sean O'Donnell | Spotřebitel | Spojené státy americké | Fort Lauderdale | Florida | 33311 | Jih | FUR-TA-10000577 | Nábytek | Tabulky | Bretford CR4500 Series Slim Obdélníkový stůl | 957,5775 | 5 | 0.45 | -383.0310 |
| 11 | CA-2014-115812 | 2014-06-09 | 2014-06-09 | Standardní třída | Standardní třída | Brosina Hoffman | Spotřebitel | Spojené státy americké | Los Angeles | Kalifornie | 90032 | Západ | FUR-TA-10001539 | Nábytek | Tabulky | Chromcraft obdélníkové konferenční stoly | 1706.184 | 9 | 0.2 | 85.3092 |
| 31 | US-2015-150630 | 2015-09-17 | 2015-09-21 | Standardní třída | TB-21520 | Tracy Blumstein | Spotřebitel | Spojené státy americké | Filadelfie | Pensylvánie | 19140 | Východ | OFF-EN-10001509 | Kancelářské potřeby | Obálky | Obálky s více provázky na zavázání | 3,264 | 2 | 0.2 | 1.1016 |
Definujte tyto parametry, abyste mohli tento poznámkový blok používat s různými datovými sadami:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/salesforecast" # Folder with data files
DATA_FILE = "Superstore.xlsx" # Data file name
EXPERIMENT_NAME = "aisample-superstore-forecast" # MLflow experiment name
Stáhněte si datovou sadu a nahrajte ji do lakehouse
Tento kód stáhne veřejně dostupnou verzi datové sady a pak ji uloží do objektu Fabric Lakehouse:
Důležitý
Než ho spustíte, nezapomeňte přidat lakehouse do poznámkového bloku . V opačném případě se zobrazí chyba.
import os, requests
if not IS_CUSTOM_DATA:
# Download data files into the lakehouse if they're not already there
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/Forecast_Superstore_Sales"
file_list = ["Superstore.xlsx"]
download_path = "/lakehouse/default/Files/salesforecast/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Nastavení sledování experimentů MLflow
Microsoft Fabric při trénování automaticky zaznamenává hodnoty vstupních parametrů a výstupních metrik modelu strojového učení. Tím se rozšiřují funkce automatického logování MLflow. Informace se pak zaprotokolují do pracovního prostoru, kde k němu máte přístup a vizualizovat je pomocí rozhraní API MLflow nebo odpovídajícího experimentu v pracovním prostoru. Další informace o automatickémlogování najdete v tématu Automatickélogování v Microsoft Fabric.
Pokud chcete vypnout automatické protokolování Microsoft Fabric v relaci poznámkového bloku, zavolejte mlflow.autolog() a nastavte disable=True:
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Turn off MLflow autologging
Načíst nezpracovaná data z lakehousu
Přečtěte nezpracovaná data z oddílu Files lakehouse. Přidejte další sloupce pro různé části kalendářních dat. Stejné informace slouží k vytvoření dělené tabulky delta. Vzhledem k tomu, že nezpracovaná data jsou uložená jako excelový soubor, musíte je přečíst pomocí knihovny pandas:
import pandas as pd
df = pd.read_excel("/lakehouse/default/Files/salesforecast/raw/Superstore.xlsx")
Krok 2: Provádění průzkumné analýzy dat
Import knihoven
Před jakoukoli analýzou naimportujte požadované knihovny:
# Importing required libraries
import warnings
import itertools
import numpy as np
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
plt.style.use('fivethirtyeight')
import pandas as pd
import statsmodels.api as sm
import matplotlib
matplotlib.rcParams['axes.labelsize'] = 14
matplotlib.rcParams['xtick.labelsize'] = 12
matplotlib.rcParams['ytick.labelsize'] = 12
matplotlib.rcParams['text.color'] = 'k'
from sklearn.metrics import mean_squared_error,mean_absolute_percentage_error
Zobrazení nezpracovaných dat
Ručně zkontrolujte podmnožinu dat, abyste lépe porozuměli samotné datové sadě, a pomocí funkce display vytiskněte datový rámec. Zobrazení Chart navíc můžou snadno vizualizovat podmnožiny datové sady.
display(df)
Tento poznámkový blok se primárně zaměřuje na prognózování prodeje kategorie Furniture. Tím se zrychlí výpočet a ukáže se výkon modelu. Tento poznámkový blok ale používá přizpůsobitelné techniky. Tyto techniky můžete rozšířit, abyste mohli předpovědět prodej dalších kategorií produktů.
# Select "Furniture" as the product category
furniture = df.loc[df['Category'] == 'Furniture']
print(furniture['Order Date'].min(), furniture['Order Date'].max())
Předběžné zpracování dat
Obchodní scénáře z reálného světa často potřebují předpovědět prodej ve třech různých kategoriích:
- Konkrétní kategorie produktů
- Konkrétní kategorie zákazníka
- Konkrétní kombinace kategorie produktů a kategorie zákazníků
Nejprve zahoďte nepotřebné sloupce pro předběžné zpracování dat. Některé sloupce (Row ID, Order ID,Customer IDa Customer Name) jsou zbytečné, protože nemají žádný vliv. Chceme pro konkrétní kategorii produktů (Furniture) předpovědět celkový prodej v celém státě a oblasti, abychom mohli vypustit sloupce State, Region, Country, Citya Postal Code. Pokud chcete předpovědět prodej pro konkrétní umístění nebo kategorii, možná budete muset odpovídajícím způsobem upravit krok předběžného zpracování.
# Data preprocessing
cols = ['Row ID', 'Order ID', 'Ship Date', 'Ship Mode', 'Customer ID', 'Customer Name',
'Segment', 'Country', 'City', 'State', 'Postal Code', 'Region', 'Product ID', 'Category',
'Sub-Category', 'Product Name', 'Quantity', 'Discount', 'Profit']
# Drop unnecessary columns
furniture.drop(cols, axis=1, inplace=True)
furniture = furniture.sort_values('Order Date')
furniture.isnull().sum()
Datová sada je strukturovaná každý den. Ve sloupci Order Datemusíme přepracovat údaje, jelikož chceme vytvořit model, který bude předpovídat prodeje na měsíční bázi.
Nejprve seskupte kategorii Furniture podle Order Date. Potom spočítejte součet sloupce Sales pro každou skupinu a určete celkový prodej pro každou jedinečnou Order Date hodnotu. Převzorkujte sloupec Sales s frekvencí MS a agregujte data podle měsíce. Nakonec vypočítejte průměrnou hodnotu prodeje pro každý měsíc.
# Data preparation
furniture = furniture.groupby('Order Date')['Sales'].sum().reset_index()
furniture = furniture.set_index('Order Date')
furniture.index
y = furniture['Sales'].resample('MS').mean()
y = y.reset_index()
y['Order Date'] = pd.to_datetime(y['Order Date'])
y['Order Date'] = [i+pd.DateOffset(months=67) for i in y['Order Date']]
y = y.set_index(['Order Date'])
maximim_date = y.reset_index()['Order Date'].max()
Předveďte dopad Order Date na Sales pro kategorii Furniture:
# Impact of order date on the sales
y.plot(figsize=(12, 3))
plt.show()
Před jakoukoli statistickou analýzou musíte importovat modul statsmodels Pythonu. Poskytuje třídy a funkce pro odhad mnoha statistických modelů. Poskytuje také třídy a funkce pro provádění statistických testů a statistického zkoumání dat.
import statsmodels.api as sm
Provádění statistické analýzy
Časová řada sleduje tyto datové prvky v nastavených intervalech, aby bylo možné určit variantu těchto prvků ve vzoru časové řady:
úroveň: Základní komponenta představující průměrnou hodnotu pro konkrétní časové období
Trend: Popisuje, jestli časová řada klesá, zůstává konstantní nebo se v průběhu času zvyšuje.
Sezónnost: Popisuje pravidelný signál časové řady a hledá cyklické výskyty, které mají vliv na vzestupné nebo klesající vzory časových řad.
šum a rezidua: Odkazuje na náhodné fluktuace a proměnlivost dat časových řad, které model nemůže vysvětlit.
V tomto kódu sledujete tyto prvky datové sady po předběžném zpracování:
# Decompose the time series into its components by using statsmodels
result = sm.tsa.seasonal_decompose(y, model='additive')
# Labels and corresponding data for plotting
components = [('Seasonality', result.seasonal),
('Trend', result.trend),
('Residual', result.resid),
('Observed Data', y)]
# Create subplots in a grid
fig, axes = plt.subplots(nrows=4, ncols=1, figsize=(12, 7))
plt.subplots_adjust(hspace=0.8) # Adjust vertical space
axes = axes.ravel()
# Plot the components
for ax, (label, data) in zip(axes, components):
ax.plot(data, label=label, color='blue' if label != 'Observed Data' else 'purple')
ax.set_xlabel('Time')
ax.set_ylabel(label)
ax.set_xlabel('Time', fontsize=10)
ax.set_ylabel(label, fontsize=10)
ax.legend(fontsize=10)
plt.show()
Grafy popisují sezónnost, trendy a šum v datech prognóz. Můžete zachytit základní vzory a vyvíjet modely, které provádějí přesné předpovědi odolné vůči náhodným výkyvům.
Krok 3: Trénování a sledování modelu
Teď, když máte k dispozici data, definujte model prognózy. V tomto poznámkovém bloku použijte model prognózy označovaný jako sezónní autoegresivní integrovaný klouzavý průměr s exogenními faktory (SARIMAX). SARIMAX kombinuje autoregresivní (AR) a klouzavé průměrné (MA) komponenty, sezónní diferencování a externí prediktory k vytváření přesných a flexibilních prognóz pro data časových řad.
K sledování experimentů také použijete automatické protokolování MLflow a Fabric. Tady načtěte tabulku delta z jezera. Můžete použít další tabulky delta, které považují lakehouse za zdroj.
# Import required libraries for model evaluation
from sklearn.metrics import mean_squared_error, mean_absolute_percentage_error
Ladění hyperparametrů
SARIMAX bere v úvahu parametry zahrnuté v běžném režimu autoregresivního integrovaného klouzavého průměru (ARIMA) (p, d, q), a přidává parametry sezónnosti (P, D, Q, s). Tyto argumenty modelu SARIMAX se nazývají pořadí (p, d, q) a sezónní pořadí (P, D, Q, s). Proto pro trénování modelu musíme nejprve vyladit sedm parametrů.
Parametry objednávky:
p: Pořadí komponenty AR představující počet minulých pozorování v časové řadě sloužící k predikci aktuální hodnoty.Obvykle by tento parametr měl být nezáporné celé číslo. Běžné hodnoty jsou v rozsahu
0až3, i když jsou možné vyšší hodnoty v závislosti na konkrétních charakteristikách dat. Vyššíphodnota označuje delší paměť minulých hodnot v modelu.d: Rozdílové pořadí představující počet, kolikrát je potřeba časové řady diferencovat, aby bylo dosaženo stacionarity.Tento parametr by měl být nezáporné celé číslo. Běžné hodnoty jsou v rozsahu
02. Hodnotad0znamená, že časová řada je již stabilní. Vyšší hodnoty označují počet rozdílových operací potřebných k tomu, aby byl statický.q: Pořadí komponenty MA představující počet minulých chybových termínů white-noise použitých k predikci aktuální hodnoty.Tento parametr by měl být nezáporné celé číslo. Běžné hodnoty jsou v rozsahu
03, ale vyšší hodnoty mohou být nezbytné pro určité časové řady. Vyšší hodnotaqoznačuje silnější závislost na minulých chybových termínech při tvorbě předpovědí.
Parametry sezónní objednávky:
-
P: Sezónní pořadí součásti AR, podobně jakop, ale pro sezónní část -
D: Sezónní pořadí rozdílových hodnot, podobně jako ud, ale pro sezónní část -
Q: Sezónní pořadí součásti MA, podobně jako uq, ale pro sezónní část -
s: Počet časových kroků na sezónní cyklus (například 12 pro měsíční data s roční sezónností)
# Hyperparameter tuning
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
print('Examples of parameter combinations for Seasonal ARIMA...')
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[1]))
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[2]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[3]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[4]))
SARIMAX má další parametry:
enforce_stationarity: Zda by měl model vynutit staticitu na datech časových řad před přizpůsobením modelu SARIMAX.Pokud je
enforce_stationaritynastavena naTrue(výchozí), znamená to, že model SARIMAX by měl vynutit staticitu na datech časových řad. Model SARIMAX pak automaticky aplikuje rozdílování na data, aby byla stacionární, jak je specifikováno pořadímidaD, před přizpůsobením modelu. To je běžná praxe, protože mnoho modelů časových řad, včetně modelu SARIMAX, předpokládá, že data jsou stacionární.Pro nestacionární časovou řadu (například vykazuje trendy nebo sezónnost) je vhodné nastavit
enforce_stationaritynaTruea nechat model SARIMAX zpracovávat diferencování, aby dosáhl stacionarity. U stacionárních časových řad (například těch bez trendů nebo sezónnosti) nastavteenforce_stationaritynaFalse, aby nedocházelo k zbytečné diferenciaci.enforce_invertibility: Určuje, zda má model během procesu optimalizace vynutit invertibilitu u odhadovaných parametrů.Pokud je
enforce_invertibilitynastavená naTrue(výchozí), znamená to, že model SARIMAX by měl u odhadovaných parametrů vynutit invertibilitu. Invertibilita zajišťuje, že model je dobře definovaný a že odhadované koeficienty AR a MA se nacházejí v rozsahu stability.Zajištění invertibility pomáhá zajistit, aby model SARIMAX dodržoval teoretické požadavky na stabilní model časové řady. Pomáhá také předcházet problémům s odhadem a stabilitou modelu.
Výchozí hodnota je model AR(1). To se týká (1, 0, 0). Je ale běžné vyzkoušet různé kombinace parametrů objednávek a parametrů sezónních objednávek a vyhodnotit výkon modelu pro datovou sadu. Příslušné hodnoty se můžou lišit od jedné časové řady po druhé.
Stanovení optimálních hodnot často zahrnuje analýzu funkce automatické opravy (ACF) a částečné funkce automatické opravy (PACF) dat časových řad. Často se také používá kritéria výběru modelu – například kritérium Akaike information (AIC) nebo bayesovské kritérium informací (BIC).
Ladění hyperparametrů:
# Tune the hyperparameters to determine the best model
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(y,
order=param,
seasonal_order=param_seasonal,
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print('ARIMA{}x{}12 - AIC:{}'.format(param, param_seasonal, results.aic))
except:
continue
Po vyhodnocení předchozích výsledků můžete určit hodnoty pro parametry objednávky i parametry sezónní objednávky. Volba je order=(0, 1, 1) a seasonal_order=(0, 1, 1, 12), které nabízejí nejnižší AIC (například 279,58). Tyto hodnoty použijte k trénování modelu.
Trénování modelu
# Model training
mod = sm.tsa.statespace.SARIMAX(y,
order=(0, 1, 1),
seasonal_order=(0, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print(results.summary().tables[1])
Tento kód vizualizuje prognózu časových řad pro data prodeje nábytku. Vynesené výsledky zobrazují pozorovaná data i prognózu o jednom kroku dopředu se stínovanou oblastí pro interval spolehlivosti.
# Plot the forecasting results
pred = results.get_prediction(start=maximim_date, end=maximim_date+pd.DateOffset(months=6), dynamic=False) # Forecast for the next 6 months (months=6)
pred_ci = pred.conf_int() # Extract the confidence intervals for the predictions
ax = y['2019':].plot(label='observed')
pred.predicted_mean.plot(ax=ax, label='One-step ahead forecast', alpha=.7, figsize=(12, 7))
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('Date')
ax.set_ylabel('Furniture Sales')
plt.legend()
plt.show()
# Validate the forecasted result
predictions = results.get_prediction(start=maximim_date-pd.DateOffset(months=6-1), dynamic=False)
# Forecast on the unseen future data
predictions_future = results.get_prediction(start=maximim_date+ pd.DateOffset(months=1),end=maximim_date+ pd.DateOffset(months=6),dynamic=False)
Pomocí predictions můžete vyhodnotit výkon modelu tím, že ho naopak použijete k porovnání se skutečnými hodnotami. Hodnota predictions_future označuje budoucí prognózování.
# Log the model and parameters
model_name = f"{EXPERIMENT_NAME}-Sarimax"
with mlflow.start_run(run_name="Sarimax") as run:
mlflow.statsmodels.log_model(results,model_name,registered_model_name=model_name)
mlflow.log_params({"order":(0,1,1),"seasonal_order":(0, 1, 1, 12),'enforce_stationarity':False,'enforce_invertibility':False})
model_uri = f"runs:/{run.info.run_id}/{model_name}"
print("Model saved in run %s" % run.info.run_id)
print(f"Model URI: {model_uri}")
mlflow.end_run()
# Load the saved model
loaded_model = mlflow.statsmodels.load_model(model_uri)
Krok 4: Určení skóre modelu a uložení předpovědí
Vytvořte sestavu Power BI tím, že integrujete skutečné hodnoty s předpovídanými hodnotami. Tyto výsledky uložte do tabulky v lakehouse.
# Data preparation for Power BI visualization
Future = pd.DataFrame(predictions_future.predicted_mean).reset_index()
Future.columns = ['Date','Forecasted_Sales']
Future['Actual_Sales'] = np.NAN
Actual = pd.DataFrame(predictions.predicted_mean).reset_index()
Actual.columns = ['Date','Forecasted_Sales']
y_truth = y['2023-02-01':]
Actual['Actual_Sales'] = y_truth.values
final_data = pd.concat([Actual,Future])
# Calculate the mean absolute percentage error (MAPE) between 'Actual_Sales' and 'Forecasted_Sales'
final_data['MAPE'] = mean_absolute_percentage_error(Actual['Actual_Sales'], Actual['Forecasted_Sales']) * 100
final_data['Category'] = "Furniture"
final_data[final_data['Actual_Sales'].isnull()]
input_df = y.reset_index()
input_df.rename(columns = {'Order Date':'Date','Sales':'Actual_Sales'}, inplace=True)
input_df['Category'] = 'Furniture'
input_df['MAPE'] = np.NAN
input_df['Forecasted_Sales'] = np.NAN
# Write back the results into the lakehouse
final_data_2 = pd.concat([input_df,final_data[final_data['Actual_Sales'].isnull()]])
table_name = "Demand_Forecast_New_1"
spark.createDataFrame(final_data_2).write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Krok 5: Vizualizace v Power BI
Sestava Power BI zobrazuje průměrnou absolutní procentuální chybu (MAPE) ve výši 16,58. Metrika MAPE definuje přesnost metody prognózování. Představuje přesnost předpovídaného množství ve srovnání se skutečnými množstvími.
MAPE je jednoduchá metrika. A 10% MAPE představuje, že průměrná odchylka mezi předpovídané a skutečné hodnoty je 10%, bez ohledu na to, zda byla odchylka kladná nebo záporná. Standardy žádoucích hodnot MAPE se liší v různých odvětvích.
Světle modrá čára v tomto grafu představuje skutečné hodnoty prodeje. Tmavě modrá čára představuje předpokládané hodnoty prodeje. Porovnání skutečných a předpokládaných prodejů ukazuje, že model efektivně predikuje prodeje pro Furniture kategorii během prvních šesti měsíců roku 2023.
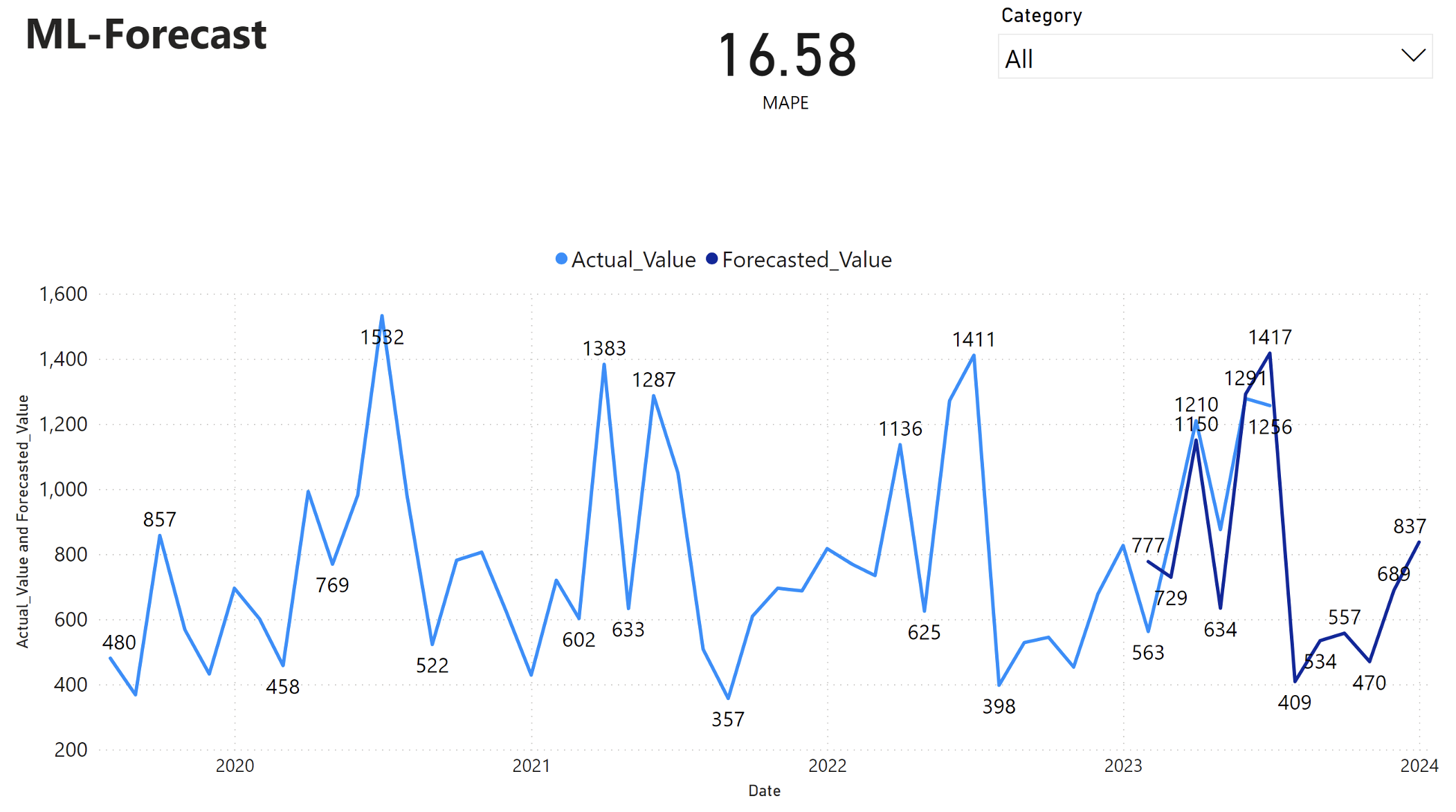
Na základě tohoto pozorování můžeme mít důvěru v schopnosti modelu prognózovat celkové prodeje jak za posledních šest měsíců roku 2023, tak i do roku 2024. Tato spolehlivost může informovat strategická rozhodnutí o řízení zásob, zajišťování surovin a dalších aspektech souvisejících s podnikáním.