Konfigurace služby Azure SQL Database v aktivitě kopírování
Tento článek popisuje, jak pomocí aktivity kopírování v datovém kanálu kopírovat data z a do Azure SQL Database.
Podporovaná konfigurace
Konfigurace každé karty v aktivitě kopírování najdete v následujících částech.
Obecné
Informace o konfiguraci karty nastavení Obecné najdete v pokynech k nastavení Obecné.
Zdroj
Následující vlastnosti jsou podporované pro Azure SQL Database na kartě Zdroj kopírovací aktivity.

Následující vlastnosti jsou požadované:
- typ úložiště dat: Vyberte Externí.
- připojení: Ze seznamu připojení vyberte připojení ke službě Azure SQL Database. Pokud připojení neexistuje, vytvořte nové připojení ke službě Azure SQL Database tak, že vyberete Nový.
- Typ připojení: Vyberte Azure SQL Database.
- tabulka: Vyberte tabulku v databázi z rozevíracího seznamu. Nebo zaškrtněte Upravit a zadejte název tabulky ručně.
- náhled dat: Zvolte náhled dat pro zobrazení dat ve vaší tabulce.
V části Pokročilýmůžete zadat následující pole:
Použijtedotaz: Můžete zvolit tabulku, dotaz, nebo uloženou proceduru. Následující seznam popisuje konfiguraci jednotlivých nastavení:
Tabulka: Data z tabulky, kterou jste zadali v Tabulce, načtete při výběru tohoto tlačítka.
dotaz: Zadejte vlastní dotaz SQL pro čtení dat. Příkladem je
select * from MyTable. Nebo vyberte ikonu tužky, která se má upravit v editoru kódu.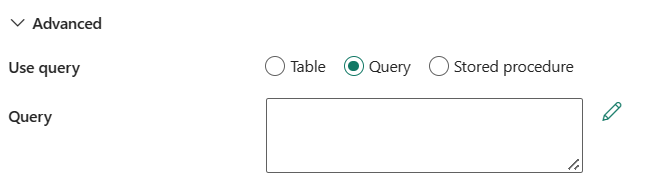
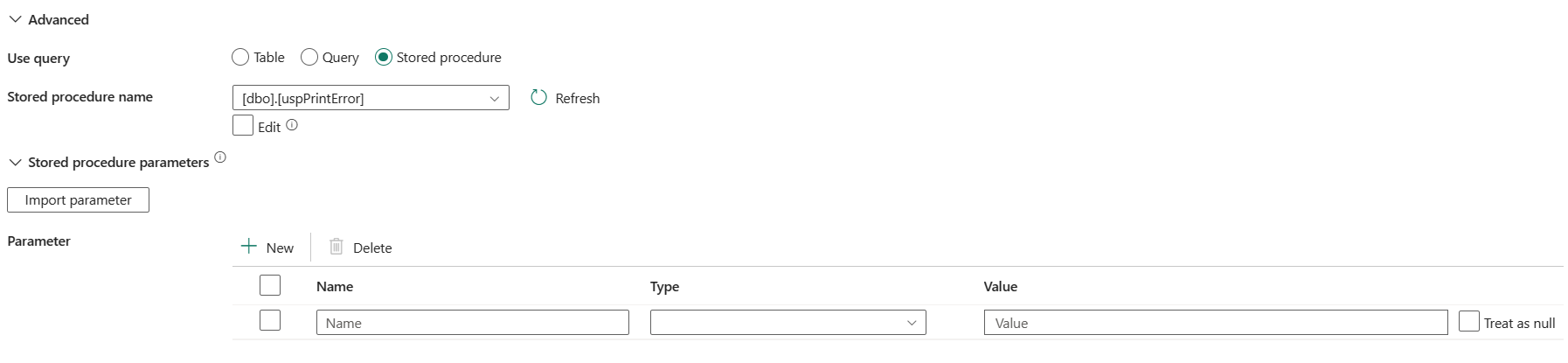
Uložená procedura: Použijte uloženou proceduru, která čte data ze zdrojové tabulky. Poslední příkaz SQL musí být příkaz SELECT v uložené proceduře.
Název uložené procedury: Vyberte uloženou proceduru nebo zadejte název uložené procedury ručně při kontrole pole Upravit pro čtení dat ze zdrojové tabulky.
parametry uložené procedury: Zadejte hodnoty pro parametry uložené procedury. Povolené hodnoty jsou dvojice názvů nebo hodnot. Názvy a velikost písmen parametrů musí odpovídat názvům a velikostem písmen parametrů uložené procedury.
vypršení časového limitu dotazu (minuty): Zadejte časový limit pro spuštění příkazu dotazu, výchozí hodnota je 120 minut. Pokud je pro tuto vlastnost nastaven parametr, jsou povolené hodnoty časový rozsah, například 02:00:00 (120 minut).
úroveň izolace: Určuje chování uzamčení transakce pro zdroj SQL. Povolené hodnoty jsou: None, ReadCommitted, ReadUncommitted, RepeatableRead, Serializableanebo Snapshot. Pokud není zadaný, použije se úroveň izolace Žádné. Další podrobnosti najdete v výčtu IsolationLevel.
možnost oddílu: Zadejte možnosti dělení dat používané k načtení dat ze služby Azure SQL Database. Povolené hodnoty jsou: None (výchozí), fyzické oddíly tabulkya dynamický rozsah. Pokud je povolena možnost oddílu (to znamená, že není None), stupeň paralelismu pro souběžné načítání dat ze služby Azure SQL Database je řízen nastavením paralelní kopie u aktivity kopírování.

Žádné: Toto nastavení vyberte, pokud nechcete oddíl používat.
fyzické oddíly tabulky: Při použití fyzického oddílu se sloupec a mechanismus oddílu automaticky určí na základě definice fyzické tabulky.
dynamického rozsahu: Pokud používáte dotaz s povoleným paralelním zpracováním, je potřeba parametr oddílu rozsahu(
?DfDynamicRangePartitionCondition). Ukázkový dotaz:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.-
Název sloupce oddílu: Zadejte název zdrojového sloupce v celočíselném nebo typu data a data a času (
int,smallint,bigint,date,smalldatetime,datetime,datetime2nebodatetimeoffset), který se používá při dělení rozsahu pro paralelní kopírování. Pokud není specifikován, index nebo primární klíč tabulky se automaticky detekuje a použije jako sloupec oddílu. - horní mez oddílu: Zadejte maximální hodnotu sloupce oddílu pro dělení rozsahu oddílu. Tato hodnota se používá k určení kroku oddílu, nikoli pro filtrování řádků v tabulce. Všechny řádky v tabulce nebo výsledku dotazu se rozdělí a zkopírují.
- Oddíl dolní mez: Zadejte minimální hodnotu sloupce oddílu pro rozdělení rozsahu oddílů. Tato hodnota se používá pro určení kroku oddílu, nikoli k filtrování řádků v tabulce. Všechny řádky v tabulce nebo výsledku dotazu se rozdělí a zkopírují.
-
Název sloupce oddílu: Zadejte název zdrojového sloupce v celočíselném nebo typu data a data a času (
Další sloupce: Přidejte další sloupce dat pro ukládání relativní cesty nebo statické hodnoty zdrojových souborů. U druhého výrazu se podporuje. Pro více informací přejděte na Přidání dalších sloupců při kopírování.


Cíl
Pod následujícími kartami Cíl v aktivitě kopírování jsou pro Azure SQL Database podporovány následující vlastnosti.

Následující vlastnosti jsou požadované:
- typ úložiště dat: Vyberte Externí.
- Připojení: Ze seznamu připojení vyberte Azure SQL Database. Pokud připojení neexistuje, vytvořte nové připojení ke službě Azure SQL Database tak, že vyberete Nový.
- Typ připojení: Vyberte Azure SQL Database.
- tabulka: Z rozevíracího seznamu vyberte tabulku v databázi. Nebo zaškrtněte Upravit a zadejte název tabulky ručně.
- Náhled dat: Kliknutím na Náhled dat zobrazíte data ve své tabulce.
V části Pokročilémůžete zadat následující pole:
chování při zápisu: Definuje chování zápisu, pokud je zdrojem soubory ze souborového úložiště dat. Můžete zvolit Vložit, Upsert nebo Uložená procedura.
 kartou chování při zápisu
kartou chování při zápisu
Vložit: Tuto možnost zvolte, pokud zdrojová data obsahují vložky.
Upsert: Tuto možnost zvolte, pokud jsou ve vašich zdrojových datech obsaženy jak vložení, tak aktualizace.
Použít databázi tempDB: Určete, zda chcete použít globální dočasnou tabulku nebo fyzickou tabulku jako dočasnou tabulku pro upsert. Ve výchozím nastavení služba používá jako dočasnou tabulku globální dočasnou tabulku a toto políčko je zaškrtnuté.
Vyberte schéma databáze uživatelů: Pokud není zaškrtnuté políčko Použít databázi TempDB, zadejte dočasné schéma pro vytvoření dočasné tabulky, pokud se použije fyzická tabulka.
Poznámka
Musíte mít oprávnění k vytváření a odstraňování tabulek. Ve výchozím nastavení bude dočasná tabulka sdílet stejné schéma jako cílová tabulka.
Klíčové sloupce: Zadejte názvy sloupců pro jedinečnou identifikaci řádků. Můžete použít jeden klíč nebo řadu klíčů. Pokud není zadaný, použije se primární klíč.
Uložená procedura: Použijte uloženou proceduru, která definuje, jak použít zdrojová data do cílové tabulky. Tato uložená procedura je vyvolána pro každou dávku.
Název uložené procedury: Vyberte uloženou proceduru nebo zadejte název uložené procedury ručně při kontrole pole Upravit pro čtení dat ze zdrojové tabulky.
parametry uložené procedury: Zadejte hodnoty pro parametry uložené procedury. Povolené hodnoty jsou dvojice názvů nebo hodnot. Názvy a velikost písmen parametrů musí odpovídat názvům a velikostem písmen parametrů uložené procedury.
Hromadné vložení zámku tabulky: Zvolte Ano nebo Ne. Toto nastavení použijte ke zlepšení výkonu kopírování během hromadné operace vložení v tabulce bez indexu z více klientů. Pro více informací přejděte na BULK INSERT (Transact-SQL)
možnost Tabulka: Určuje, jestli se má automaticky vytvořit cílovou tabulku, pokud tabulka neexistuje na základě zdrojového schématu. Zvolte Žádné nebo Automaticky vytvořit tabulku. Automatické vytváření tabulek není podporováno, pokud cíl určuje uloženou proceduru.
skript předběžného kopírování: Zadejte skript pro aktivitu kopírování, který se má spustit před zápisem dat do cílové tabulky v každém spuštění. Tuto vlastnost můžete použít k vyčištění předem načtených dat.
vypršení časového limitu dávkového zápisu: Zadejte dobu čekání na dokončení operace dávkového zápisu, než vyprší časový limit. Povolená hodnota je časový interval. Výchozí hodnota je 00:30:00 (30 minut).
Nastavení dávkové velikosti: Zadejte počet řádků, které se mají vložit do tabulky SQL na dávku. Povolená hodnota je celé číslo (počet řádků). Ve výchozím nastavení služba dynamicky určuje odpovídající velikost dávky na základě velikosti řádku.
maximální počet souběžných připojení: Zadejte horní limit souběžných připojení vytvořených k úložišti dat během spuštění aktivity. Zadejte hodnotu pouze v případech, kdy chcete omezit souběžná připojení.
Zakázat analýzu metrik výkonu: Toto nastavení slouží ke shromažďování metrik, jako jsou DTU, DWU, RU atd., pro optimalizaci výkonu kopírování a doporučení. Pokud máte obavy o toto chování, zaškrtněte toto políčko.
Mapování
V případě konfigurace Mapování, pokud jako cíl nepoužíváte službu Azure SQL Database s automatickým vytvořením tabulky, přejděte na Mapování.
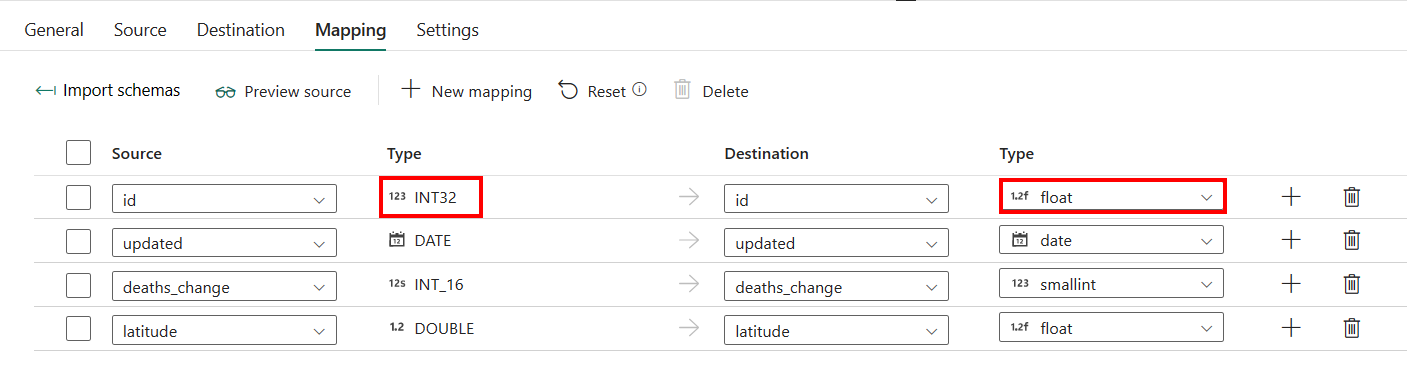
Pokud použijete Azure SQL Database s automatickým vytvořením tabulky jako svůj cíl a neupravujete konfiguraci v mapování, můžete upravit typ cílových sloupců. Po výběru import schématmůžete zadat typ sloupce v cíli.
Například typ sloupce ID ve zdroji je int a můžete jej přiřadit jako typ float do cílového sloupce.
Nastavení
Pro konfiguraci záložky Nastavení přejděte na Upravit další nastavení v záložce Nastavení.
Paralelní kopírování ze služby Azure SQL Database
Konektor Služby Azure SQL Database v aktivitě kopírování poskytuje integrované dělení dat pro paralelní kopírování dat. Na kartě Zdroj aktivity kopírování najdete možnosti rozdělení dat.
Když povolíte dělené kopírování, aktivita kopírování spouští paralelní dotazy na zdroj služby Azure SQL Database, aby načetla data podle oddílů. Paralelní stupeň je řízen Stupně paralelismu kopírování na kartě nastavení aktivity kopírování. Pokud například nastavíte Stupeň paralelismu kopírování na čtyři, služba současně generuje a spouští čtyři dotazy na základě zadané možnosti a nastavení oddílu a každý dotaz načte část dat z vaší služby Azure SQL Database.
Doporučujeme povolit paralelní kopírování s dělením dat, zejména pokud načítáte velké množství dat ze služby Azure SQL Database. Následující konfigurace jsou navržené pro různé scénáře. Při kopírování dat do souborového úložiště dat se doporučuje zapisovat do složky jako více souborů (zadat pouze název složky), v takovém případě je výkon lepší než zápis do jednoho souboru.
| Scénář | Navrhovaná nastavení |
|---|---|
| Úplné načtení z velké tabulky s fyzickými oddíly. |
Volba oddílu: Fyzické oddíly tabulky. Během provádění služba automaticky rozpozná fyzické oddíly a kopíruje data podle oddílů. Pokud chcete zkontrolovat, jestli vaše tabulka má fyzický oddíl nebo ne, můžete použít tento dotaz. |
| Úplné načtení z velké tabulky bez fyzických oddílů, ale s celočíselným nebo sloupcem typu datetime pro dělení dat. |
Možnosti dělení: Dynamické rozdělení rozsahu. Sloupec oddílu (volitelné): Zadejte sloupec použitý k dělení dat. Pokud není zadaný, použije se sloupec indexu nebo primárního klíče. horní mez oddílu a dolní mez oddílu (volitelné): Určete, jestli chcete stanovit krok oddílu. To není pro filtrování řádků v tabulce, všechny řádky v tabulce budou rozděleny a zkopírovány. Pokud není zadáno, aktivity kopírování automaticky detekují hodnoty. Pokud má například sloupec oddílu ID hodnoty od 1 do 100 a dolní mez nastavíte jako 20 a horní mez jako 80, přičemž paralelní kopírování je 4, služba načte data podle 4 oddílů – ID v rozsahu <=20, [21, 50], [51, 80] a >=81. |
| Načtěte velké množství dat pomocí vlastního dotazu bez fyzických oddílů, ale s využitím celočíselného nebo datumového či datově-časového sloupce pro dělení dat. |
možnosti rozdělení: Dynamický rozsah. dotazu: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Oddílový sloupec: Zadejte sloupec použitý k dělení dat. horní mez oddílu a dolní mez oddílu (volitelné): Uveďte, zda chcete určit krok pro oddíl. To není pro filtrování řádků v tabulce, všechny řádky ve výsledku dotazu budou rozděleny a zkopírovány. Pokud není zadáno, aktivita kopírování automaticky rozpozná hodnotu. Pokud má například sloupec oddílu "ID" hodnoty v rozsahu od 1 do 100 a spodní hranici nastavíte na 20, horní hranici na 80 a paralelní kopírování nastavíte na 4, služba načte data ze 4 oddílů: ID v rozsahu <= 20, [21, 50], [51, 80] a >= 81. Tady jsou další ukázkové dotazy pro různé scénáře: • Zadejte dotaz na celou tabulku: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• Dotaz z tabulky s výběrem sloupce a dalšími filtry klauzule where: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Dotaz s poddotazy: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Dotaz s oddílem v dotazu: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Nejlepší postupy pro načtení dat s volbou rozdělení:
- Zvolte výrazný sloupec jako sloupec oddílu (například primární klíč nebo jedinečný klíč), abyste se vyhnuli nerovnoměrnému rozložení dat.
- Pokud má tabulka vestavěný oddíl, použijte možnost oddílu Fyzické oddíly tabulky, abyste dosáhli lepšího výkonu.
Ukázkový dotaz pro kontrolu fyzického oddílu
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Pokud má tabulka fyzický oddíl, „HasPartition“ se zobrazí jako „ano“, jak je uvedeno níže.

Souhrn tabulky
Následující tabulky obsahují další informace o aktivitě kopírování ve službě Azure SQL Database.
Zdroj
| Jméno | Popis | Hodnota | Požadovaný | Vlastnost skriptu JSON |
|---|---|---|---|---|
| typ úložiště dat | Váš typ úložiště dat. | externí | Ano | / |
| připojení | Vaše připojení ke zdrojovému úložišti dat. | <vaše připojení> | Ano | připojení |
| Typ připojení | Typ připojení. Vyberte Azure SQL Database. | Azure SQL Database | Ano | / |
| tabulka | Vaše zdrojová datová tabulka | <název cílové tabulky> | Ano | schéma stůl |
| Použít dotaz | Vlastní dotaz SQL pro čtení dat. | •Žádný •Dotaz • Uložená procedura |
Ne | • sqlReaderQuery • sqlReaderStoredProcedureName, storedProcedureParameters |
| vypršení časového limitu dotazu | Časový limit spuštění příkazu dotazu je ve výchozím nastavení 120 minut. | časový rozsah | Ne | časový limit dotazu |
| úroveň izolace | Určuje chování uzamčení transakce pro zdroj SQL. | •Žádný • ReadCommitted • ReadUncommitted • RepeatableRead •Serializovatelný •Snímek |
Ne | úroveň izolace |
| možnost oddílu | Možnosti dělení dat používané k načtení dat ze služby Azure SQL Database. | •Žádný • Fyzické oddíly tabulky • Dynamický rozsah |
Ne | možnost rozdělení • Fyzické Dělení Tabulky • DynamicRange |
| Přídavné sloupce | Přidejte další datové sloupce pro ukládání relativní cesty ke zdrojovým souborům nebo statické hodnotě. U druhého výrazu se podporuje. | •Jméno •Hodnota |
Ne | dodatečnéSloupce •Jméno •hodnota |
Cíl
| Jméno | Popis | Hodnota | Povinný | Vlastnost skriptu JSON |
|---|---|---|---|---|
| typ úložiště dat | Váš typ úložiště dat. | externí | Ano | / |
| připojení | Vaše připojení k cílovému úložišti dat. | <připojení > | Ano | připojení |
| Typ připojení | Typ připojení. Vyberte Azure SQL Database. | Azure SQL Database | Ano | / |
| tabulky | Tabulka dat pro cíl | <název cílové tabulky> | Ano | schéma stůl |
| chování při zápisu | Definuje chování zápisu, když zdroj je soubory ze souborového úložiště dat. | •Vložit • Vložení nebo aktualizace • Uložená procedura |
Ne | writeBehavior: •vložit • vložení nebo aktualizace • sqlWriterStoredProcedureName, sqlWriterTableType, parametry uložené procedury |
| Zamknutí tabulky pro hromadné vložení | Toto nastavení použijte ke zlepšení výkonu kopírování během hromadné operace vložení v tabulce bez indexu z více klientů. | Ano nebo ne | Ne | sqlWriterUseTableLock: pravda nebo nepravda |
| možnost Tabulka | Určuje, jestli se má cílová tabulka vytvořit automaticky, pokud neexistuje na základě zdrojového schématu. | •Žádný • Automaticky vytvořit tabulku |
Ne | tableOption: • automatické vytvoření |
| skript předběžného kopírování | Skript pro aktivitu kopírování, který se má spustit před zápisem dat do cílové tabulky v každém spuštění. Tuto vlastnost můžete použít k vyčištění předem načtených dat. |
<skript pro předkopírování> (řetězec) |
Ne | preCopyScript |
| časový limit dávkového zápisu | Doba čekání na dokončení operace dávkového vložení před vypršením časového limitu. Povolená hodnota je časový úsek. Výchozí hodnota je 00:30:00 (30 minut). | časový rozsah | Ne | writeBatchTimeout |
| velikost dávky zápisu | Počet řádků, které se mají vložit do tabulky SQL na dávku Ve výchozím nastavení služba dynamicky určuje odpovídající velikost dávky na základě velikosti řádku. |
<počet řádků> (celé číslo) |
Ne | writeBatchSize |
| maximální počet souběžných připojení | Horní limit souběžných připojení vytvořených k úložišti dat během spuštění aktivity. Zadejte hodnotu pouze v případech, kdy chcete omezit souběžná připojení. |
<horní limit souběžných připojení> (celé číslo) |
Ne | maximální počet současných připojení |
| Zakázání analýzy metrik výkonu | Toto nastavení slouží ke shromažďování metrik, jako jsou DTU, DWU, RU atd., pro optimalizaci výkonu kopírování a doporučení. Pokud máte obavy o toto chování, zaškrtněte toto políčko. | výběr nebo zrušení výběru | Ne | disableMetricsCollection: pravda nebo lež |