Odstranění duplikátů v každé tabulce pro sjednocení dat
Odstranění duplicitních dat vyhledá a odebere duplicitní záznamy zákazníka ze zdrojové tabulky tak, aby každý zákazník byl v každé tabulce reprezentován jedním řádkem. Každá tabulka je deduplikována samostatně pomocí pravidel pro identifikaci záznamů pro daného zákazníka.
Každé pravidlo odstranění duplicit se spouští pro každý řádek. Pokud se první pravidlo shoduje s řádky 1 a 2 a pravidlo 2 se shoduje s řádky 2 a 3, budou se shodovat řádky 1, 2 a 3. Když jsou nalezeny shodné řádky, je vybrán vítězný řádek, který reprezentuje daného zákazníka na základě Předvoleb sloučení (Nejvíce vyplněný, Nejnovější nebo Nejstarší). Pomocí možnosti Rozšířené můžete vytvořit vítězný řádek výběrem polí z různých odpovídajících řádků, jako je například nejnovější e-mail, ale nejvíce vyplněná adresa.
Customer Insights - Data automaticky provede následující akce:
- Deduplikujte záznamy se stejnou hodnotou primárního klíče a jako vítěze vyberte první řádek v datové sadě.
- Odstraní duplicitu záznamů pomocí Pravidel párování definovaných pro tabulku při porovnávání řádků mezi tabulkami.
Definování odstranění duplicit
Dobré pravidlo identifikuje jedinečného zákazníka. Zvažte svá data. Může postačit identifikovat zákazníky na základě pole, jako je e-mail. Pokud však chcete odlišit zákazníky, kteří sdílejí e-mail, můžete zvolit pravidlo se dvěma podmínkami, které se shodují s e-mailem a křestním jménem. Další informace naleznete v tématu Osvědčené postupy deduplikace.
Na stránce Pravidla odstranění duplicit vyberte tabulku a vyberte Přidat pravidlo k definování pravidel odstranění duplicit.
Tip
Pokud jste rozšířili tabulky na úrovni zdroje dat, abyste pomohli zlepšit výsledky sjednocení, Použít rozšířené tabulky v horní části stránky. Další informace najdete v tématu Rozšíření zdrojů dat.

V podokně Přidat pravidlo zadejte následující informace:
Vyberte pole: Vyberte ze seznamu dostupných polí tabulky, u které chcete zkontrolovat duplikáty. Vyberte pole, která jsou potenciálně jedinečná pro každého jednotlivého zákazníka. Například e-mailová adresa nebo kombinace jména, města a telefonního čísla.
Normalizovat: Vyberte možnosti normalizace pro sloupec. Normalizace ovlivní pouze krok shody a nemění data.
Normalizace Příklady Číslice Převede mnoho symbolů Unicode, které představují čísla, na jednoduchá čísla.
Příklady: ❽ a Ⅷ jsou normalizovány na číslo 8.
Poznámka: Symboly musí být kódovány ve formátu Unicode Point.Symboly Odstraní všechny symboly a speciální znaky.
Příklady: !?"#$%&'( )+,.-/:;<=>@^~{}`[ ]Text na malá písmena Převádí velká písmena na malá
Příklad: „THIS Is aN EXamplE“ se převede na „this is an example“Typ - Telefon Převádí telefony v různých formátech na číslice a zohledňuje rozdíly v prezentaci kódů zemí a přípon. Symboly a prázdné znaky jsou ignorovány. Úvodní číslice "0" v kódech zemí jsou ignorovány a odpovídají +1 a +01. Přípony označené písmennou předponou jsou ignorovány (X 123). Normalizovaný kód země je významný, takže telefon s kódem země se nebude shodovat s telefonem bez kódu země.
Příklad: +01 425.555.1212 odpovídá 1 (425) 555-1212
+01 425.555.1212 se neshoduje s (425) 555-1212Typ - Název Převádí více než 500 běžných variant jmen a názvů.
Příklady: "debby" -> deborah" "prof" a "profesor" -> "Prof."Typ - adresa Převádí společné části adres
Příklady: "street" -> "st" a "northwest" -> "nw"Typ - Organizace Odstraňuje přibližně 50 „hlukových slov“ názvů společností, jako jsou „co“, „corp“, „corporation“ a „ltd“. Unicode na ASCII Převede znaky Unicode na jejich ekvivalent ASCII
Příklad: Znaky 'à,' 'á, 'â,' 'À, 'Á, 'Â, 'Ã, 'Ä, 'Ⓐ a 'A' jsou převedeny na 'a .'Prázdný znak Odebere všechny mezery Mapování aliasů Umožňuje nahrát vlastní seznam párů řetězců, které pak lze použít k označení řetězců, které by měly být vždy považovány za přesnou shodu.
Mapování aliasů použijte, pokud máte konkrétní příklady dat, o kterých si myslíte, že by se měly shodovat, a nejsou spárovány pomocí některého z jiných vzorů normalizace.
Příklad: Scott a Scooter nebo MSFT a Microsoft.Vlastní obejití Umožňuje nahrát vlastní seznam řetězců, které pak lze použít k označení řetězců, které by neměly být nikdy porovnávány.
Vlastní obejití je užitečné, když máte data s běžnými hodnotami, které by se měly ignorovat, jako je fiktivní telefonní číslo nebo fiktivní e-mail.
Příklad: Nikdy se neshodujte s telefonem 555-1212, nebo test@contoso.com
Přesnost: Nastavte úroveň přesnosti. Přesnost se používá pro přesnou shodu a přibližnou shodu a určuje, jak blízko musí být dva řetězce, aby se považovaly za shodu.
- Základní: Vyberte jednu z možností Nízká (30 %), Střední (60 %), Vysoká (80 %) a Přesná (100 %). Vyberte Přesný, aby se shodovaly pouze záznamy, které se stoprocentně shodují.
- Vlastní: Nastaví procento, kterému musí záznamy odpovídat. Systém páruje pouze záznamy splňující tuto prahovou hodnotu.
Název: Název pravidla.
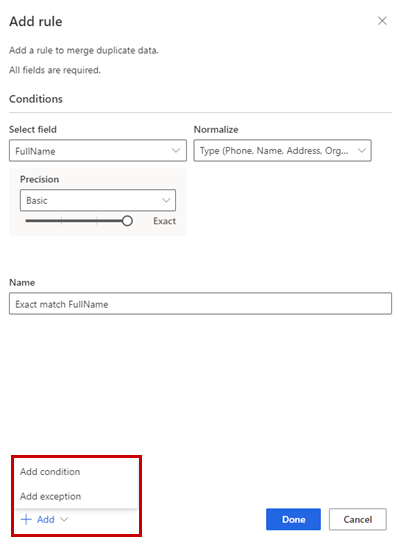
Volitelně vyberte Přidat>Přidat podmínku pro přidání dalších podmínek do pravidla. Podmínky jsou spojeny s logickým operátorem AND a jsou tedy prováděny pouze tehdy, jsou-li všechny splněny.
Volitelně Přidat>Přidat výjimku na přidat výjimky do pravidla. Výjimky se používají k řešení vzácných případů falešně pozitivních a falešně negativních výsledků.
Vyberte Hotovo pro vytvoření pravidla.
Volitelně přidejte další pravidla.

Výběr preference sloučení
Když jsou pravidla spuštěna a jsou identifikovány duplicitní záznamy pro zákazníka, je na základě zásad sloučení vybrán "vítězný řáde". Vítězný řádek představuje zákazníka v dalším kroku sjednocení, který porovnává záznamy mezi tabulkami. Data v nevítězných ("alternativních") řádcích se používají v kroku Sjednocení pravidel párování ke spárování záznamů z jiných tabulek s vítězným řádkem. Tento přístup zlepšuje výsledky párování tím, že umožňuje informace, jako jsou předchozí telefonní čísla, aby pomohly identifikovat odpovídající záznamy. Vítězný řáde lze nakonfigurovat tak, aby byl nejvíce vyplněný, nejnovější nebo nejméně poslední z nalezených duplicitních záznamů.
Vyberte tabulku a poté Upravit předvolby sloučení. Zobrazí se podokno Předvolby sloučení.
Vyberte jednu ze tří možností, jak určit, který záznam se má ponechat, pokud je nalezen duplikát:
- Nejvíce vyplněný: Identifikuje záznam s nejvíce vyplněnými sloupci jako vítězný. Toto je výchozí možnost sloučení.
- Nejnovější: Identifikuje vítězný záznam na základě největší aktuálnosti. Vyžaduje datum nebo číselné pole pro definování aktuálnosti.
- Nejdřívější: Identifikuje vítězný záznam na základě nejmenší aktuálnosti. Vyžaduje datum nebo číselné pole pro definování aktuálnosti.
V případě nerozhodného výsledku je vítězem záznam s hodnotou MAX(PK) nebo vyšší hodnotou primárního klíče.
Volitelně, chcete-li definovat předvolby sloučení pro jednotlivé sloupce tabulky, vyberte Rozšířené ve spodní části podokna. Můžete se například rozhodnout zachovat nejnovější e-mail A nejúplnější adresu z různých záznamů. Rozbalte tabulku, abyste viděli všechny její sloupce a definujte, kterou možnost mají použít jednotlivé sloupce. Pokud zvolíte možnost založenou na aktuálnosti, musíte také zadat pole data/času, které definuje aktuálnost.
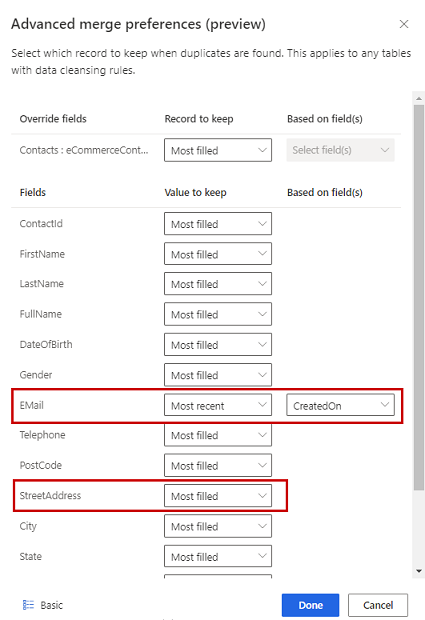
Výběrem možnosti Hotovo použijte předvolby sloučení.
Po definování pravidel deduplikace a předvoleb sloučení vyberte Další.