Osvědčené postupy sjednocení dat
Při nastavování pravidel pro sjednocení dat do profilu zákazníka zvažte tyto osvědčené postupy:
Vyvážení času pro sjednocení oproti úplnému párování. Snaha zachytit každou možnou shodu vede k tomu, že mnoho pravidel a sjednocování trvá dlouho.
Postupně přidávejte pravidla a sledujte výsledky. Odstraňte pravidla, která nezlepšují výsledek shody.
Deduplikujte každou tabulku tak, aby byl každý zákazník reprezentován v jednom řádku.
Pomocí normalizace můžete standardizovat variace způsobu zadávání dat, například Street vs. St vs. St.
Používejte přibližnou shodu strategicky k opravě překlepů a chyb, jako je bob@contoso.com a bob@contoso.cm. Přibližné shody trvají déle než přesné shody. Vždy otestujte, zda čas navíc strávený přibližnou shodou stojí za další míru shody.
Zužte rozsah shod s přesnou shodou. Ujistěte se, že každé pravidlo s přibližnými podmínkami má alespoň jednu podmínku přesné shody.
Nevytvářejte shodu u sloupců, které obsahují silně se opakující data. Ujistěte se, že se ve sloupcích přibližné shody často neopakují hodnoty, jako je například výchozí hodnota formuláře „FirstName“.
Výkon sjednocování
Spuštění každého pravidla nějakou dobu trvá. Vzory, jako je porovnání každé tabulky se všemi ostatními tabulkami nebo pokus o zachycení všech možných shod záznamů, mohou vést k dlouhým časům zpracování sjednocení. Vrátí také několik dalších shod v plánu, který porovnává každou tabulku se základní tabulkou.
Nejlepším přístupem je začít se základní sadou pravidel, o kterých víte, že jsou potřeba, jako je například porovnání jednotlivých tabulek s primární tabulkou. Primární tabulka by měla být ta, která obsahuje nejúplnější a nejpřesnější data. Tato tabulka by měla být seřazena nahoře v kroku sjednocení pravidel párování.
Postupně přidávejte několik pravidel a sledujte, jak dlouho trvá, než změny proběhnou, a zda se vaše výsledky zlepší. Přejděte na Nastavení>Systém>Stav a vyberte Shoda , abyste viděli, jak dlouho trvalo odstranění duplicit a párování pro každé spuštění sjednocení.
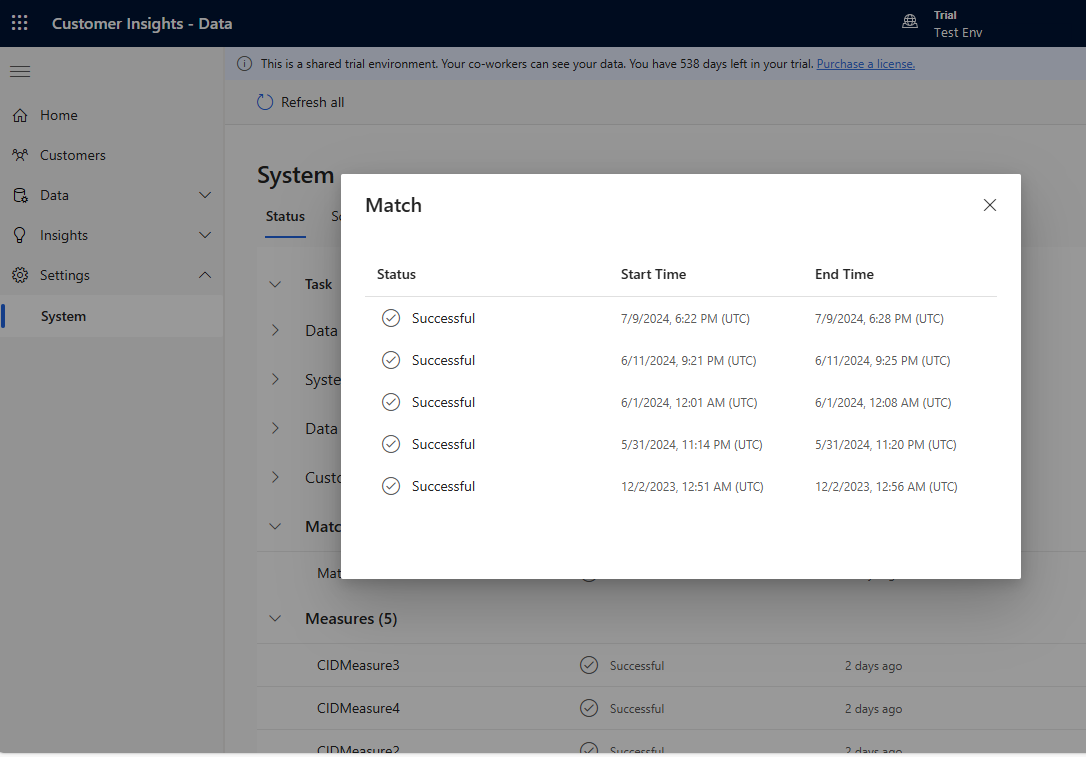
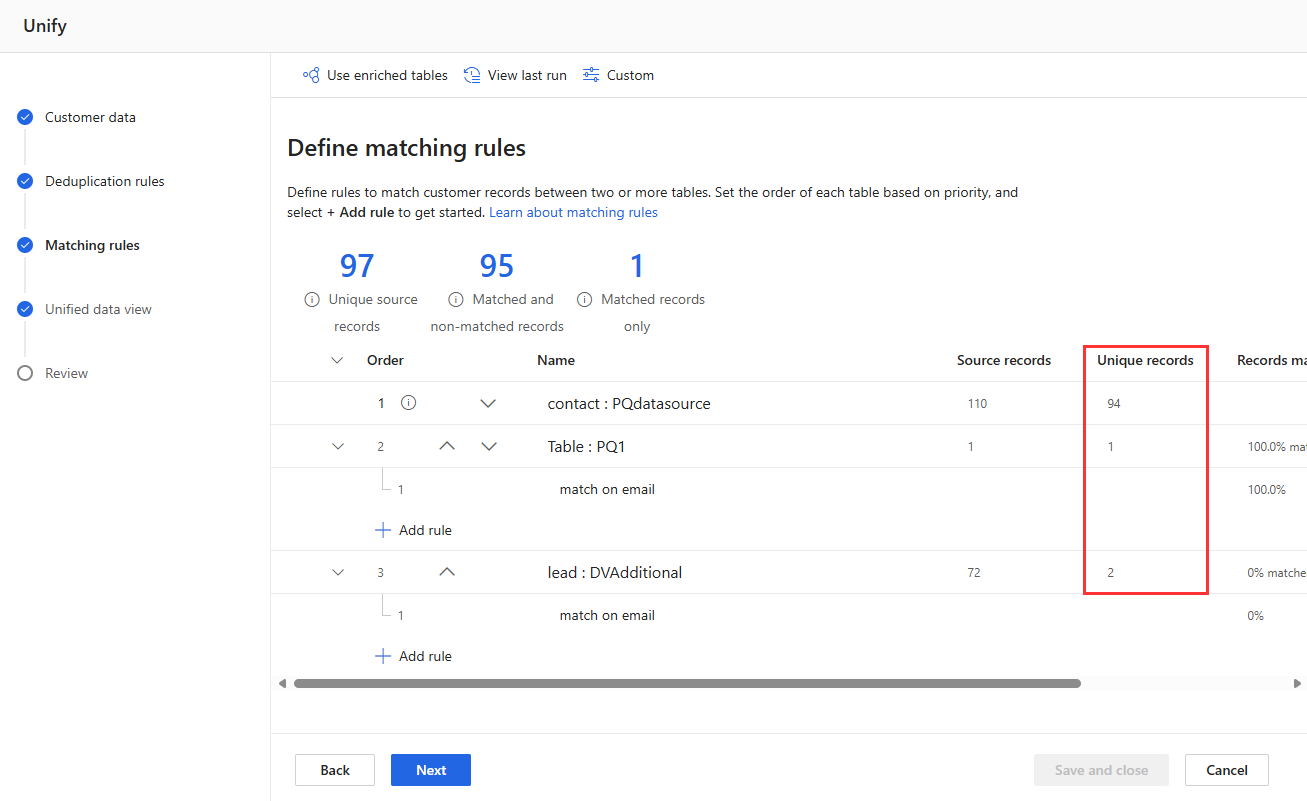
Zobrazte statistiky pravidel na stránkách Pravidla deduplikace a Pravidla párování, abyste zjistili, zda se počet jedinečných záznamů mění. Pokud nové pravidlo odpovídá některým záznamům a jedinečný počet záznamů se nezmění, pak předchozí pravidlo identifikuje tyto shody.
Data zákazníka
V kroku Zákaznická data:
Vylučte sloupce, které nejsou potřebné pro pravidla párování nebo které nechcete zahrnout do konečného profilu zákazníka.
Zkontrolujte popisy sloupců vybrané inteligentním mapováním.
Ne všechny sloupce je nutné mapovat. Mapování běžných sloupců, jako jsou pole e-mailu a adresy, umožňuje Customer Insights usnadnit následné procesy, ale sloupce s jedinečným ID nebo účelem pro vaši firmu mohou zůstat nenamapované.
Deduplikace
Pravidla odstranění duplicit slouží k odstranění duplicitních záznamů zákazníků v tabulce tak, aby jeden řádek v každé tabulce reprezentoval každého zákazníka. Dobré pravidlo identifikuje jedinečného zákazníka.
V tomto jednoduchém příkladu záznamy 1, 2 a 3 sdílejí e-mail nebo telefonní číslo a představují stejnou osobu.
| ID | Name | telefonní | |
|---|---|---|---|
| 01 | Osoba 1 | (425) 555-1111 | AAA@A.com |
| 2 | Osoba 1 | (425) 555-1111 | BBB@B.com |
| 3 | Osoba 1 | (425) 555-2222 | BBB@B.com |
| 4 | Osoba 2 | (206) 555-9999 | Person2@contoso.com |
Nechceme párovat pouze podle jména, protože by to odpovídalo různým lidem se stejným jménem.
Vytvořte pravidlo 1 pomocí Jména a Telefonu, které odpovídá záznamům 1 a 2.
Vytvořte pravidlo 2 pomocí E-mailu a Telefonu, které odpovídá záznamům 2 a 3.
Kombinace pravidla 1 a pravidla 2 vytvoří jednu skupinu párování, protože sdílejí záznam 2.
Vy rozhodujete o počtu pravidel a podmínek, které jednoznačně identifikují vaše zákazníky. Přesná pravidla závisí na datech, která máte k dispozici, na kvalitě vašich dat a na tom, jak vyčerpávající má být proces odstranění duplicit.
Normalizace
Pomocí normalizace můžete standardizovat data pro lepší shodu. Normalizace funguje dobře u velkých sad dat.
Normalizovaná data se používají pouze pro účely srovnání, aby bylo možné efektivněji spárovat záznamy zákazníků. Nemění data v konečném výstupu jednotného zákaznického profilu.
Přesná shoda
Pomocí přesnosti určete, jak blízko by měly být dva řetězce, aby se považovaly za shodu. Výchozí nastavení přesnosti vyžaduje přesnou shodu. Jakákoli jiná hodnota umožňuje přibližnou shodu pro tuto podmínku.
Přesnost lze nastavit na nízkou (30% shoda), střední (60% shoda) a vysokou (80% shoda). Nebo můžete přizpůsobit a nastavit přesnost v krocích po 1 %.
Přesné podmínky shody
Přesné podmínky shody se spustí jako první, aby se získala menší sada hodnot pro přibližné shody. Aby byly podmínky přesné shody účinné, měly by mít přiměřenou míru jedinečnosti. Pokud například všichni vaši zákazníci žijí ve stejné zemi nebo oblasti, přesná shoda v zemi nebo oblasti by nepomohla zúžit rozsah.
Sloupce jako celé jméno, e-mail, telefon nebo pole adresy mají dobrou jedinečnost a jsou skvělé pro použití jako přesná shoda.
Ujistěte se, že sloupec, který používáte pro podmínku přesné shody, nemá žádné hodnoty, které se často opakují, například výchozí hodnotu „FirstName“ zachycenou formulářem. Customer Insights může profilovat datové sloupce a poskytnout tak přehled o hlavních opakujících se hodnotách. Profilaci dat můžete zapnout u připojení Azure Data Lake (pomocí Common Data Model nebo rozdílového formátu) a Synapse. Profil dat se spustí při další aktualizaci zdroje dat. Další informace najdete v tématu Profilování dat.
Přibližná shoda
Použijte přibližnou shodu pro porovnávání řetězců, které jsou blízko, ale nejsou přesné kvůli překlepům nebo jiným malým variacím. Používejte přibližnou shodu strategicky, protože je pomalejší než přesné shody. Zajistěte alespoň jednu podmínku přesné shody v každém pravidle, které má podmínky přibližné shody.
Přibližná shoda není určena k zachycení variant jmen, jako jsou Suzzie a Suzanne. Tyto varianty jsou lépe zachyceny pomocí vzorce normalizace Typ: Název nebo vlastního porovnávání aliasů, kde zákazníci můžou zadat seznam variant názvů, které chtějí považovat za shody.
K pravidlu můžete přidat podmínky, jako je shoda jména a telefonu. Podmínky v rámci daného pravidla jsou podmínky „AND“. Každá podmínka se musí shodovat, aby se řádky shodovaly. Samostatnými pravidly jsou podmínky „OR“. Pokud Pravidlo 1 řádkům neodpovídá, řádky se porovnají s Pravidlem 2.
Poznámka:
Přibližnou shodu mohou používat pouze sloupce typu dat typu řetězec. U sloupců s jinými datovými typy, jako je celé číslo, double nebo datum a čas, je pole přesnosti jen pro čtení a nastavené na přesnou shodu.
Výpočty přibližné shody
Přibližné shody se určují výpočtem skóre vzdálenosti úprav mezi dvěma řetězci. Pokud skóre splňuje nebo překračuje prahovou hodnotu přesnosti, řetězce se považují za shodu.
Vzdálenost úprav je počet úprav potřebných k převedení jednoho řetězce na jiný přidáním, odstraněním nebo změnou znaku.
Například řetězce „robert2020@hotmail.com“ a „robrt2020@hotmail.cm“ mají editační vzdálenost dvě, když odstraníme znaky „e“ a „o“. Chcete-li vypočítat skóre vzdálenosti úprav, použijte tento vzorec: (Základní délka řetězce − Editační vzdálenost) / Základní délka řetězce.
| Základní řetězec | Srovnávací řetězec | Skóre |
|---|---|---|
| robert2020@hotmail.com | robrt2020@hotmail.cm | (20 − 2) / 20 = 0,9 |