Dotazování souborů Delta Lake (v1) pomocí bezserverového fondu SQL ve službě Azure Synapse Analytics
V tomto článku se dozvíte, jak napsat dotaz pomocí bezserverového fondu Synapse SQL ke čtení souborů Delta Lake. Delta Lake je opensourcová vrstva úložiště, která přináší transakce ACID (atomicity, konzistence, izolace a stálosti) do úloh Apache Sparku a velkých objemů dat. Další informace najdete ve videu s dotazem na tabulky Delta Lake.
Důležité
Bezserverové fondy SQL se můžou dotazovat na Delta Lake verze 1.0. Změny, které byly zavedeny od verze Delta Lake 1.2 (například přejmenování sloupců), nejsou v bezserverové verzi podporované. Pokud používáte vyšší verze Delta s vektory odstranění, kontrolními body v2 a dalšími, měli byste zvážit použití jiného dotazovacího stroje, jako je koncový bod SQL Microsoft Fabric pro Lakehouses.
Bezserverový fond SQL v pracovním prostoru Synapse umožňuje číst data uložená ve formátu Delta Lake a obsluhovat je v nástrojích pro vytváření sestav. Bezserverový fond SQL může číst soubory Delta Lake vytvořené pomocí Apache Sparku, Azure Databricks nebo jakéhokoli jiného producenta formátu Delta Lake.
Fondy Apache Sparku v Azure Synapse umožňují datovým inženýrům upravovat soubory Delta Lake pomocí Scala, PySpark a .NET. Bezserverové fondy SQL pomáhají datovým analytikům vytvářet sestavy souborů Delta Lake vytvořených datovými inženýry.
Důležité
Dotazování formátu Delta Lake pomocí bezserverového fondu SQL je obecně dostupné funkce. Dotazování tabulek Spark Delta je ale stále ve verzi Public Preview a není připravené pro produkční prostředí. Při dotazování tabulek Delta vytvořených pomocí fondů Sparku se můžou vyskytnout známé problémy. Podívejte se na známé problémy v bezserverovém fondu SQL– samoobslužná nápověda.
Požadavky
Důležité
Zdroje dat je možné vytvářet jenom ve vlastních databázích (ne v hlavní databázi nebo v databázích replikovaných z fondů Apache Spark).
Pokud chcete použít ukázky v tomto článku, budete muset provést následující kroky:
- Vytvořte databázi se zdroji dat, který odkazuje na účet úložiště Taxi žlutá NYC.
- Inicializace objektů spuštěním instalačního skriptu v databázi, kterou jste vytvořili v kroku 1. Tento instalační skript vytvoří zdroje dat, přihlašovací údaje s oborem databáze a formáty externích souborů, které se používají v těchto ukázkách.
Pokud jste vytvořili databázi a přepnuli kontext do databáze (pomocí USE database_name příkazu nebo rozevíracího seznamu pro výběr databáze v některém editoru dotazů), můžete vytvořit externí zdroj dat obsahující kořenový identifikátor URI do sady dat a použít ho k dotazování souborů Delta Lake. Příklad:
CREATE EXTERNAL DATA SOURCE DeltaLakeStorage
WITH ( LOCATION = 'https://<yourstorageaccount>.blob.core.windows.net/delta-lake/' );
GO
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
) as rows;
Pokud je zdroj dat chráněný klíčem SAS nebo vlastní identitou, můžete zdroj dat nakonfigurovat s přihlašovacími údaji v oboru databáze.
Můžete vytvořit externí zdroj dat s umístěním, které odkazuje na kořenovou složku úložiště. Po vytvoření externího zdroje dat použijte zdroj dat a relativní cestu k souboru ve OPENROWSET funkci. Tímto způsobem nemusíte k souborům používat úplný absolutní identifikátor URI. Můžete také definovat vlastní přihlašovací údaje pro přístup k umístění úložiště.
Čtení složky Delta Lake
Důležité
Pomocí instalačního skriptu v požadavcích nastavte ukázkové zdroje dat a tabulky.
Funkce OPENROWSET umožňuje číst obsah souborů Delta Lake zadáním adresy URL kořenové složky.
Nejjednodušší způsob, jak zobrazit obsah DELTA souboru, je zadat adresu URL souboru funkci OPENROWSET a zadat DELTA formát. Pokud je soubor veřejně dostupný nebo pokud má vaše identita Microsoft Entra přístup k tomuto souboru, měli byste být schopni zobrazit obsah souboru pomocí dotazu, jako je ten zobrazený v následujícím příkladu:
SELECT TOP 10 *
FROM OPENROWSET(
BULK '/covid/',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta') as rows;
Názvy sloupců a datové typy se automaticky čtou ze souborů Delta Lake. Funkce OPENROWSET pro řetězcové sloupce používá nejlepší typy odhadů, jako je VARCHAR(1000).
Identifikátor URI ve OPENROWSET funkci musí odkazovat na kořenovou složku Delta Lake, která obsahuje podsložku s názvem _delta_log.
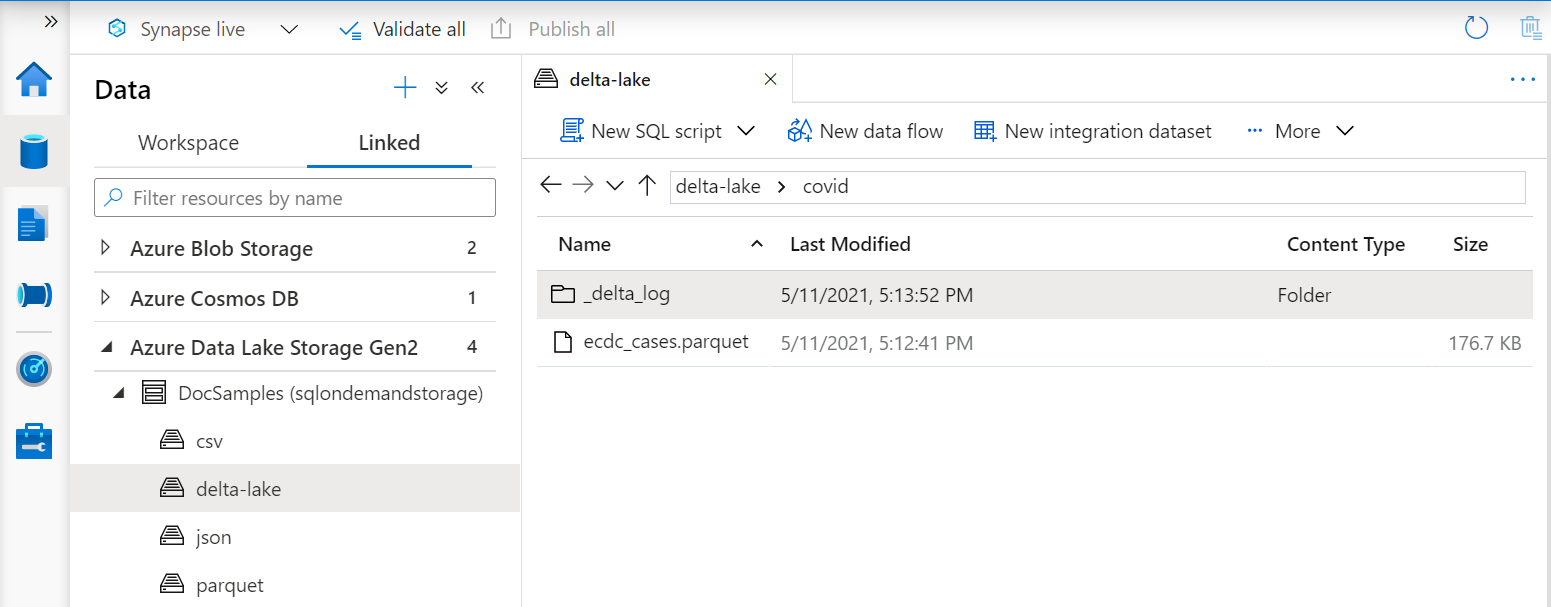
Pokud tuto podsložku nemáte, nepoužíváte formát Delta Lake. Prosté soubory Parquet ve složce můžete převést do formátu Delta Lake pomocí skriptu, jako je následující příklad skriptu Apache Spark Python:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/covid`")
Pokud chcete zlepšit výkon dotazů, zvažte určení explicitních typů v klauzuliWITH.
Poznámka:
Bezserverový fond Synapse SQL používá k automatickému určení sloupců a jejich typů odvození schématu. Pravidla pro odvozování schématu jsou stejná jako pro soubory Parquet. Mapování typu Delta Lake na mapování nativního typu SQL pro Parquet.
Ujistěte se, že máte přístup k souboru. Pokud je váš soubor chráněný klíčem SAS nebo vlastní identitou Azure, budete muset pro přihlášení SQL nastavit přihlašovací údaje na úrovni serveru.
Důležité
Ujistěte se, že používáte kolaci databáze UTF-8 (například Latin1_General_100_BIN2_UTF8), protože řetězcové hodnoty v souborech Delta Lake jsou kódovány pomocí kódování UTF-8.
Neshoda mezi kódováním textu v souboru Delta Lake a kolací může způsobit neočekávané chyby převodu.
Výchozí kolaci aktuální databáze můžete snadno změnit pomocí následujícího příkazu T-SQL:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_BIN2_UTF8; Další informace o kolacích najdete v tématu Typy kolace podporované pro Synapse SQL.
Explicitní zadání schématu
OPENROWSET umožňuje explicitně určit, které sloupce chcete ze souboru číst pomocí WITH klauzule:
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
)
WITH ( date_rep date,
cases int,
geo_id varchar(6)
) as rows;
Pomocí explicitní specifikace schématu sady výsledků můžete minimalizovat velikosti typů a použít přesnější typy VARCHAR(6) pro řetězcové sloupce místo pesimistické VARCHAR(1000). Minimalizace typů může výrazně zvýšit výkon dotazů.
Důležité
Ujistěte se, že explicitně zadáváte kolaci UTF-8 (například Latin1_General_100_BIN2_UTF8) pro všechny řetězcové sloupce v WITH klauzuli nebo nastavte kolaci UTF-8 na úrovni databáze.
Neshoda mezi kódováním textu v kolaci sloupců souborů a řetězců může způsobit neočekávané chyby převodu.
Výchozí kolaci aktuální databáze můžete snadno změnit pomocí následujícího příkazu T-SQL:
alter database current collate Latin1_General_100_BIN2_UTF8 Kolaci u typů sloupců můžete snadno nastavit pomocí následující definice: geo_id varchar(6) collate Latin1_General_100_BIN2_UTF8
Datová sada
V této ukázce se používá datová sada NYC Yellow Taxi . Původní datová PARQUET sada se převede na DELTA formát a DELTA verze se používá v příkladech.
Dotazování na dělená data
Datová sada poskytnutá v této ukázce je rozdělena (rozdělena) do samostatných podsložek.
Na rozdíl od Parquet nemusíte cílit na konkrétní oddíly pomocí FILEPATH této funkce. Identifikuje OPENROWSET sloupce dělení ve struktuře složek Delta Lake a umožní přímé dotazování dat pomocí těchto sloupců. Tento příklad ukazuje částky jízdného podle roku, měsíce a payment_type pro první tři měsíce roku 2017.
SELECT
YEAR(pickup_datetime) AS year,
passenger_count,
COUNT(*) AS cnt
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
WHERE
nyc.year = 2017
AND nyc.month IN (1, 2, 3)
AND pickup_datetime BETWEEN CAST('1/1/2017' AS datetime) AND CAST('3/31/2017' AS datetime)
GROUP BY
passenger_count,
YEAR(pickup_datetime)
ORDER BY
YEAR(pickup_datetime),
passenger_count;
Funkce OPENROWSET eliminuje oddíly, které neodpovídají year klauzuli where a month do klauzule where. Tato technika vyřazení souborů nebo oddílů výrazně sníží vaši sadu dat, zlepší výkon a sníží náklady na dotaz.
Název složky ve funkci (v tomto příkladuOPENROWSET) je zřetězen pomocí LOCATIONDeltaLakeStorage zdroje dat a musí odkazovat na kořenovou složku Delta Lake, která obsahuje podsložku s názvem _delta_log.yellow
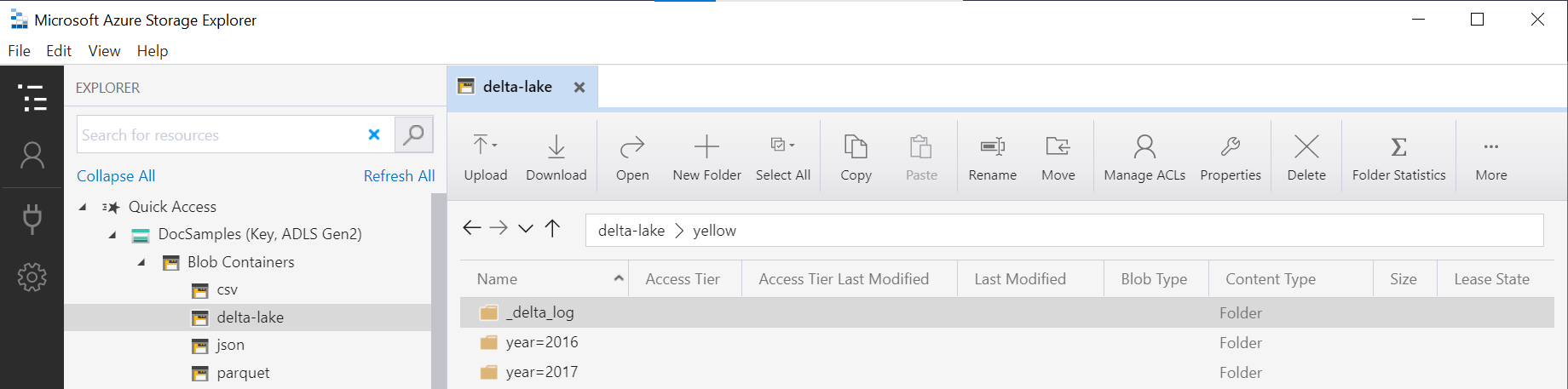
Pokud tuto podsložku nemáte, nepoužíváte formát Delta Lake. Prosté soubory Parquet ve složce můžete převést do formátu Delta Lake pomocí následujícího skriptu Apache Spark Pythonu:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/yellow`", "year INT, month INT")
Druhý argument DeltaTable.convertToDeltaLake funkce představuje sloupce dělení (rok a měsíc), které jsou součástí vzoru složek (year=*/month=* v tomto příkladu) a jejich typy.
Omezení
- Projděte si omezení a známé problémy na stránce samoobslužné podpory bezserverového fondu SQL Synapse.
Související obsah
V dalším článku se dozvíte, jak dotazovat vnořené typy Parquet. Pokud chcete pokračovat v sestavování řešení Delta Lake, naučte se vytvářet zobrazení nebo externí tabulky ve složce Delta Lake.