Vytváření a používání zobrazení pomocí bezserverového fondu SQL ve službě Azure Synapse Analytics
V této části se dozvíte, jak vytvářet a používat zobrazení k zabalení dotazů bezserverového fondu SQL. Zobrazení vám umožní tyto dotazy znovu použít. Zobrazení jsou potřeba také v případě, že chcete používat nástroje, jako je Power BI, ve spojení s bezserverovým fondem SQL.
Požadavky
Prvním krokem je vytvoření databáze, ve které se vytvoří zobrazení a inicializuje objekty potřebné k ověření v úložišti Azure spuštěním instalačního skriptu v této databázi. Všechny dotazy v tomto článku se spustí ve vaší ukázkové databázi.
Zobrazení nad externími daty
Zobrazení můžete vytvářet stejným způsobem jako běžná zobrazení SQL Serveru. Následující dotaz vytvoří zobrazení, které načte population.csv soubor.
Poznámka:
Změňte první řádek v dotazu, tj. [mydbname], abyste používali databázi, kterou jste vytvořili.
USE [mydbname];
GO
DROP VIEW IF EXISTS populationView;
GO
CREATE VIEW populationView AS
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r];
Zobrazení používá EXTERNAL DATA SOURCE kořenovou adresu URL úložiště jako DATA_SOURCE a přidá k souborům relativní cestu k souboru.
Zobrazení Delta Lake
Pokud vytváříte zobrazení nad složkou Delta Lake, musíte místo zadání cesty k souboru zadat umístění kořenové složky.BULK
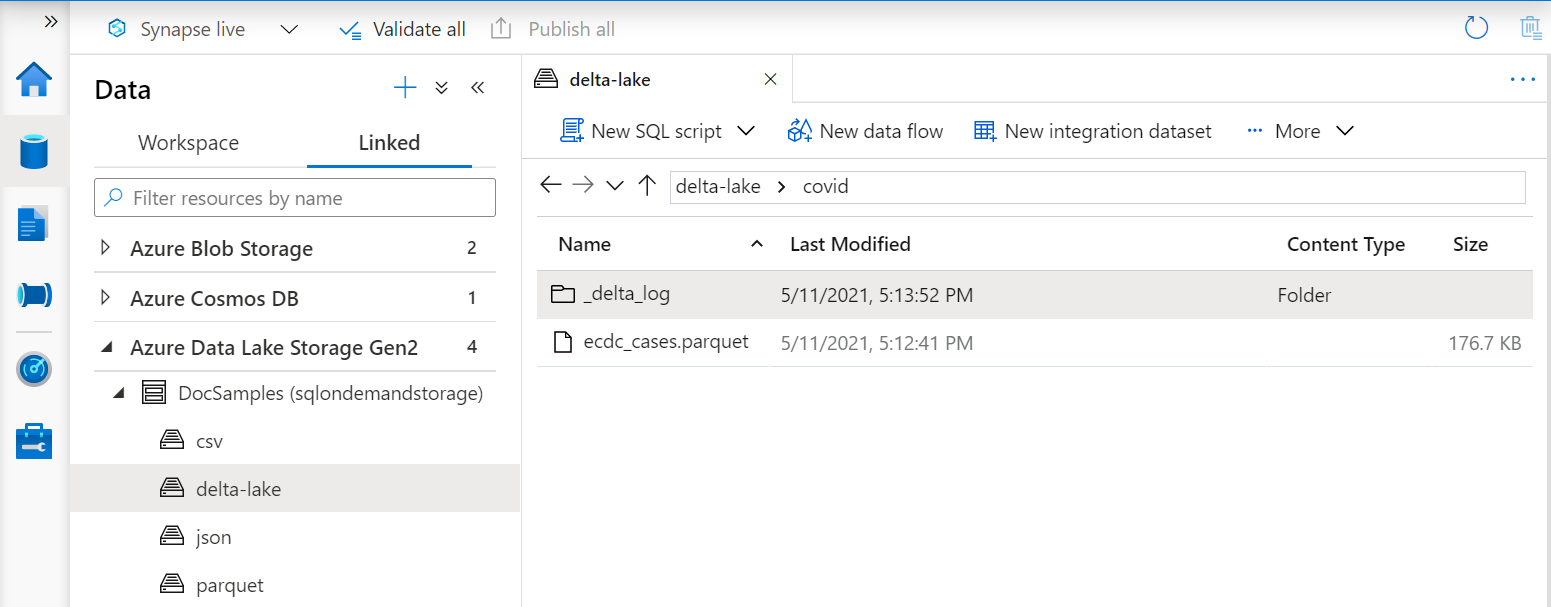
Funkce OPENROWSET , která čte data ze složky Delta Lake, prozkoumá strukturu složek a automaticky identifikuje umístění souborů.
create or alter view CovidDeltaLake
as
select *
from openrowset(
bulk 'covid',
data_source = 'DeltaLakeStorage',
format = 'delta'
) with (
date_rep date,
cases int,
geo_id varchar(6)
) as rows
Další informace najdete na stránce samoobslužné podpory bezserverového fondu SQL Synapse a známých problémech se službou Azure Synapse Analytics.
Dělené zobrazení
Pokud máte sadu souborů rozdělených do hierarchické struktury složek, můžete vzor oddílu popsat pomocí zástupných znaků v cestě k souboru.
FILEPATH Pomocí funkce zpřístupníte části cesty ke složce jako sloupce dělení.
CREATE VIEW TaxiView
AS SELECT *, nyc.filepath(1) AS [year], nyc.filepath(2) AS [month]
FROM
OPENROWSET(
BULK 'parquet/taxi/year=*/month=*/*.parquet',
DATA_SOURCE = 'sqlondemanddemo',
FORMAT='PARQUET'
) AS nyc
Dělená zobrazení můžou zvýšit výkon dotazů provedením odstranění oddílů při dotazování pomocí filtrů ve sloupcích dělení. Ne všechny dotazy ale podporují odstranění oddílů, takže je důležité postupovat podle některých osvědčených postupů.
Abyste zajistili odstranění oddílů, vyhněte se použití poddotazů ve filtrech, protože můžou kolidovat se schopností eliminovat oddíly. Místo toho předejte výsledek poddotazu jako proměnnou filtru.
Při použití JOIN v dotazech SQL deklarujte predikát filtru jako NVARCHAR, abyste snížili složitost plánu dotazu a zvýšili pravděpodobnost odstranění správného oddílu. Sloupce oddílů se obvykle odvozují jako NVARCHAR(1024), takže použití stejného typu pro predikát zabraňuje nutnosti implicitního přetypování, což může zvýšit složitost plánu dotazů.
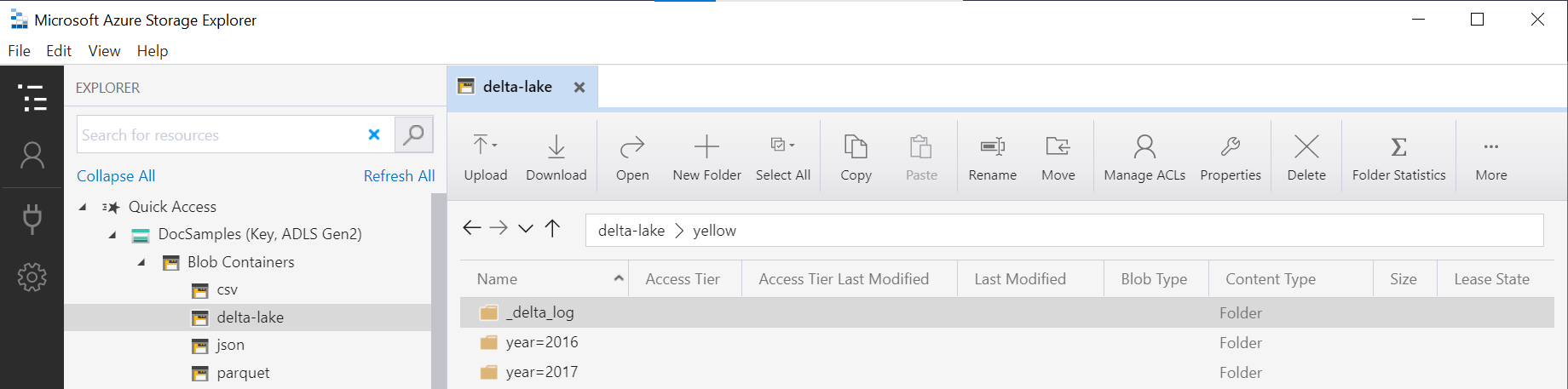
Rozdělená zobrazení Delta Lake
Pokud vytváříte rozdělená zobrazení nad úložištěm Delta Lake, můžete zadat jenom kořenovou složku Delta Lake a nemusíte explicitně zveřejňovat sloupce dělení pomocí FILEPATH funkce:
CREATE OR ALTER VIEW YellowTaxiView
AS SELECT *
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
Funkce OPENROWSET prozkoumá strukturu podkladové složky Delta Lake a automaticky identifikuje a zveřejní sloupce dělení. Odstranění oddílu se provede automaticky, pokud vložíte sloupec dělení do WHERE klauzule dotazu.
Název složky ve funkci (yellowv tomto příkladuOPENROWSET) zřetězený s identifikátorem LOCATION URI definovaným ve DeltaLakeStorage zdroji dat musí odkazovat na kořenovou složku Delta Lake, která obsahuje podsložku s názvem _delta_log.
Další informace najdete na stránce samoobslužné podpory bezserverového fondu SQL Synapse a známých problémech se službou Azure Synapse Analytics.
Zobrazení JSON
Zobrazení jsou dobrou volbou, pokud potřebujete provést další zpracování nad sadou výsledků, která se načte ze souborů. Jedním z příkladů může být analýza souborů JSON, kde potřebujeme použít funkce JSON k extrahování hodnot z dokumentů JSON:
CREATE OR ALTER VIEW CovidCases
AS
select
*
from openrowset(
bulk 'latest/ecdc_cases.jsonl',
data_source = 'covid',
format = 'csv',
fieldterminator ='0x0b',
fieldquote = '0x0b'
) with (doc nvarchar(max)) as rows
cross apply openjson (doc)
with ( date_rep datetime2,
cases int,
fatal int '$.deaths',
country varchar(100) '$.countries_and_territories')
Funkce OPENJSON analyzuje každý řádek ze souboru JSONL obsahujícího jeden dokument JSON na řádek v textovém formátu.
Zobrazení služby Azure Cosmos DB v kontejnerech
Zobrazení je možné vytvořit nad kontejnery Azure Cosmos DB, pokud je v kontejneru povolené analytické úložiště Azure Cosmos DB. Název účtu služby Azure Cosmos DB, název databáze a název kontejneru by se měly přidat jako součást zobrazení a přístupový klíč jen pro čtení by se měl umístit do přihlašovacích údajů s vymezeným oborem databáze, na které odkazuje zobrazení.
Tento ukázkový skript používá databázi a kontejner, které můžete nastavit podle těchto pokynů.
Důležité
Ve skriptu nahraďte tyto hodnoty vlastními hodnotami:
- your-cosmosdb – název účtu cosmos DB
- přístupový klíč – klíč účtu služby Cosmos DB
CREATE DATABASE SCOPED CREDENTIAL MyCosmosDbAccountCredential
WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = 'access-key';
GO
CREATE OR ALTER VIEW Ecdc
AS SELECT *
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=your-cosmosdb;Database=covid',
OBJECT = 'Ecdc',
CREDENTIAL = 'MyCosmosDbAccountCredential'
) with ( date_rep varchar(20), cases bigint, geo_id varchar(6) ) as rows
Další informace najdete v tématu Dotazování dat služby Azure Cosmos DB pomocí bezserverového fondu SQL ve službě Azure Synapse Link.
Použití zobrazení
Zobrazení můžete ve svých dotazech používat stejným způsobem, jako používáte pohledy v dotazech SQL Serveru.
Následující dotaz ukazuje použití population_csv zobrazení, které jsme vytvořili v zobrazení Vytvořit. V roce 2019 vrací názvy zemí a oblastí sestupným počtem obyvatel.
Poznámka:
Změňte první řádek v dotazu, tj. [mydbname], abyste používali databázi, kterou jste vytvořili.
USE [mydbname];
GO
SELECT
country_name, population
FROM populationView
WHERE
[year] = 2019
ORDER BY
[population] DESC;
Při dotazování zobrazení může dojít k chybám nebo neočekávaným výsledkům. To pravděpodobně znamená, že zobrazení odkazuje na sloupce nebo objekty, které byly změněny nebo již neexistují. Definici zobrazení je potřeba upravit ručně tak, aby odpovídala změnám základního schématu.
Související obsah
Informace o dotazování různých typů souborů najdete v článcích o dotazech na jeden soubor CSV, soubory Parquet dotazu a dotazy na soubory JSON.