Konektor Azure Synapse vyhrazeného fondu SQL pro Apache Spark
Úvod
Konektor vyhrazeného fondu SQL Azure Synapse pro Apache Spark v Azure Synapse Analytics umožňuje efektivní přenos velkých datových sad mezi modulem runtime Apache Spark a vyhrazeným fondem SQL. Konektor se dodává jako výchozí knihovna s Azure Synapse Workspace. Konektor se implementuje pomocí Scala jazyka. Konektor podporuje Scala a Python. Pokud chcete konektor použít s jinými volbami jazyka poznámkového bloku, použijte příkaz magic Sparku - %%spark.
Konektor na vysoké úrovni poskytuje následující funkce:
- Čtení z vyhrazeného fondu SQL Azure Synapse:
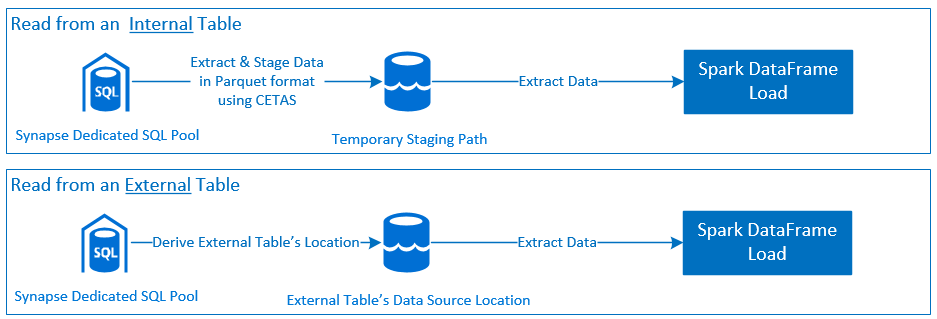
- Čtení velkých datových sad z tabulek vyhrazeného fondu SQL Synapse (interních a externích) a zobrazení
- Komplexní podpora nabízení predikátů, kde se filtry datového rámce mapují na odpovídající predikát SQL.
- Podpora pro vyřezávání sloupců
- Podpora nabízených dotazů
- Zápis do vyhrazeného fondu SQL Azure Synapse:
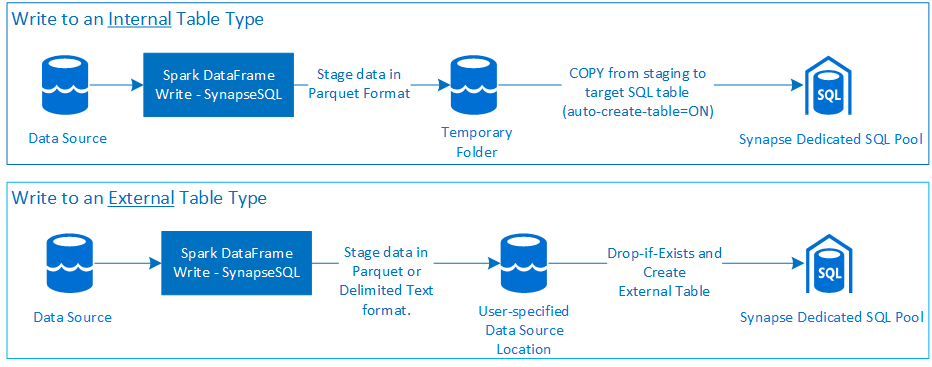
- Ingestování velkých objemů dat na interní a externí typy tabulek
- Podporuje následující předvolby režimu ukládání datového rámce:
AppendErrorIfExistsIgnoreOverwrite
- Typ zápisu do externí tabulky podporuje formát souboru Parquet a Text s oddělovači (příklad – CSV).
- K zápisu dat do interních tabulek teď konektor místo přístupu CETAS/CTAS používá příkaz COPY.
- Vylepšení pro optimalizaci výkonu komplexní propustnosti zápisu
- Představuje volitelný popisovač zpětného volání (argument funkce Scala), který můžou klienti použít k příjmu metrik po zápisu.
- Mezi příklady patří : počet záznamů, doba trvání dokončení určité akce a důvod selhání.
Přístup k orchestraci
Čteno
Write
Požadavky
Požadavky, jako je nastavení požadovaných prostředků Azure a postup jejich konfigurace, jsou popsány v této části.
Prostředky Azure
Zkontrolujte a nastavte následující závislé prostředky Azure:
- Azure Data Lake Storage – používá se jako primární účet úložiště pro pracovní prostor Azure Synapse.
- Pracovní prostor Azure Synapse – vytváření poznámkových bloků, sestavování a nasazování pracovních postupů příchozího přenosu dat založené na datových rámcích
- Vyhrazený fond SQL (dříve SQL DW) – poskytuje funkce podnikového Skladování Dat.
- Bezserverový fond Sparku Azure Synapse – modul runtime Spark, ve kterém se úlohy spouštějí jako aplikace Spark.
Příprava databáze
Připojte se k databázi vyhrazeného fondu SYNApse SQL a spusťte následující instalační příkazy:
Vytvořte uživatele databáze, který je namapovaný na identitu uživatele Microsoft Entra sloužící k přihlášení k pracovnímu prostoru Azure Synapse.
CREATE USER [username@domain.com] FROM EXTERNAL PROVIDER;Vytvořte schéma, ve kterém budou definovány tabulky, aby konektor mohl úspěšně zapisovat a číst z příslušných tabulek.
CREATE SCHEMA [<schema_name>];
Ověřování
Ověřování na základě ID Microsoft Entra
Ověřování na základě ID microsoftu je integrovaný přístup k ověřování. Uživatel se musí úspěšně přihlásit k pracovnímu prostoru Azure Synapse Analytics.
Základní ověřování
Základní přístup ověřování vyžaduje, aby uživatel nakonfigurovali a password volbyusername. Informace o relevantních parametrech konfigurace pro čtení a zápis do tabulek ve vyhrazeném fondu SQL Azure Synapse najdete v části Možnosti konfigurace.
Autorizace
Azure Data Lake Storage Gen2
Přístupová oprávnění ke službě Azure Data Lake Storage Gen2 – Účet úložiště můžete udělit dvěma způsoby:
- Role řízení přístupu na základě role – Role Přispěvatel dat v objektech blob úložiště
- Přiřazením oprávnění uživatele ke čtení, zápisu
Storage Blob Data Contributor Rolea odstranění z kontejnerů objektů blob služby Azure Storage - RBAC nabízí hrubou kontrolu na úrovni kontejneru.
- Přiřazením oprávnění uživatele ke čtení, zápisu
-
Seznamy řízení přístupu (ACL)
- Přístup ACL umožňuje jemně odstupňovanou kontrolu nad konkrétními cestami nebo soubory v dané složce.
- Kontroly seznamu ACL se nevynucuje, pokud už má uživatel udělená oprávnění pomocí přístupu RBAC.
- Existují dva široké typy oprávnění seznamu ACL:
- Přístupová oprávnění (použitá na konkrétní úrovni nebo objektu)
- Výchozí oprávnění (automaticky použita pro všechny podřízené objekty v době jejich vytvoření).
- Typ oprávnění zahrnuje:
-
Executeumožňuje procházet hierarchie složek nebo procházet je. -
Readumožňuje číst. -
Writeumožňuje psát.
-
- Je důležité nakonfigurovat seznamy ACL tak, aby konektor mohl úspěšně zapisovat a číst z umístění úložiště.
Poznámka:
Pokud chcete spouštět poznámkové bloky pomocí kanálů pracovního prostoru Synapse, musíte také udělit výše uvedená přístupová oprávnění výchozí spravované identitě pracovního prostoru Synapse. Výchozí název spravované identity pracovního prostoru je stejný jako název pracovního prostoru.
Pokud chcete používat pracovní prostor Synapse se zabezpečenými účty úložiště, musí být spravovaný privátní koncový bod nakonfigurovaný z poznámkového bloku. Spravovaný privátní koncový bod musí být schválen v části účtu
Private endpoint connectionsúložiště ADLS Gen2 vNetworkingpodokně.
Vyhrazený fond SQL služby Azure Synapse
Pokud chcete povolit úspěšnou interakci s vyhrazeným fondem SQL Azure Synapse, je nutné provést následující autorizaci, pokud nejste uživatelem, který je také nakonfigurovaný jako Active Directory Admin vyhrazený koncový bod SQL:
Scénář čtení
Udělte uživateli
db_exportersystém uloženou procedurusp_addrolemember.EXEC sp_addrolemember 'db_exporter', [<your_domain_user>@<your_domain_name>.com];
Scénář zápisu
- Konektor používá příkaz COPY k zápisu dat z přípravného prostředí do spravovaného umístění interní tabulky.
Nakonfigurujte požadovaná oprávnění popsaná tady.
Následuje fragment kódu rychlého přístupu stejného:
--Make sure your user has the permissions to CREATE tables in the [dbo] schema GRANT CREATE TABLE TO [<your_domain_user>@<your_domain_name>.com]; GRANT ALTER ON SCHEMA::<target_database_schema_name> TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has ADMINISTER DATABASE BULK OPERATIONS permissions GRANT ADMINISTER DATABASE BULK OPERATIONS TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has INSERT permissions on the target table GRANT INSERT ON <your_table> TO [<your_domain_user>@<your_domain_name>.com]
- Konektor používá příkaz COPY k zápisu dat z přípravného prostředí do spravovaného umístění interní tabulky.
Dokumentace k rozhraní API
Konektor vyhrazeného fondu SQL Azure Synapse pro Apache Spark – Dokumentace k rozhraní API
Možnosti konfigurace
Pokud chcete úspěšně spustit a orchestrovat operaci čtení nebo zápisu, konektor očekává určité konfigurační parametry. Definice objektu – com.microsoft.spark.sqlanalytics.utils.Constants poskytuje seznam standardizovaných konstant pro každý klíč parametru.
Následuje seznam možností konfigurace na základě scénáře použití:
-
Čtení s využitím ověřování na základě ID Microsoft Entra
- Přihlašovací údaje se automaticky namapují a uživatel nemusí poskytovat konkrétní možnosti konfigurace.
- Argument názvu třídílné tabulky v
synapsesqlmetodě se vyžaduje ke čtení z příslušné tabulky ve vyhrazeném fondu SQL Azure Synapse.
-
Čtení pomocí základního ověřování
- Vyhrazený koncový bod SQL služby Azure Synapse
-
Constants.SERVER– Koncový bod vyhrazeného fondu SQL Synapse (plně kvalifikovaný název domény serveru) -
Constants.USER– Uživatelské jméno SQL. -
Constants.PASSWORD– Heslo uživatele SQL.
-
- Koncový bod služby Azure Data Lake Storage (Gen 2) – Pracovní složky
-
Constants.DATA_SOURCE– Cesta k úložišti nastavená pro parametr umístění zdroje dat se používá pro přípravu dat.
-
- Vyhrazený koncový bod SQL služby Azure Synapse
-
Zápis pomocí ověřování založeného na MICROSOFT Entra ID
- Vyhrazený koncový bod SQL služby Azure Synapse
- Ve výchozím nastavení konektor odvodí koncový bod Synapse Dedicated SQL pomocí názvu databáze nastaveného
synapsesqlna parametru názvu tabulky se třemi částmi metody. - Případně můžou uživatelé použít
Constants.SERVERmožnost zadat koncový bod SQL. Ujistěte se, že koncový bod hostuje odpovídající databázi s příslušným schématem.
- Ve výchozím nastavení konektor odvodí koncový bod Synapse Dedicated SQL pomocí názvu databáze nastaveného
- Koncový bod služby Azure Data Lake Storage (Gen 2) – Pracovní složky
- Pro interní typ tabulky:
- Nakonfigurujte jednu
Constants.TEMP_FOLDERneboConstants.DATA_SOURCEmožnost. - Pokud se uživatel rozhodl zadat
Constants.DATA_SOURCEmožnost, pracovní složka bude odvozena pomocílocationhodnoty z DataSource. - Pokud jsou k dispozici obě možnosti,
Constants.TEMP_FOLDERpoužije se hodnota možnosti. - Pokud není k dispozici možnost pracovní složky, konektor se odvozí na základě konfigurace modulu runtime -
spark.sqlanalyticsconnector.stagingdir.prefix.
- Nakonfigurujte jednu
- Pro externí typ tabulky:
-
Constants.DATA_SOURCEje požadovaná možnost konfigurace. - Konektor používá cestu k úložišti nastavenou pro parametr umístění zdroje dat v kombinaci s argumentem
locationsynapsesqlmetody a odvozuje absolutní cestu k zachování dat externí tabulky. -
locationPokud není zadaný argument metodysynapsesql, konektor odvodí hodnotu umístění jako<base_path>/dbName/schemaName/tableName.
-
- Pro interní typ tabulky:
- Vyhrazený koncový bod SQL služby Azure Synapse
-
Zápis pomocí základního ověřování
- Vyhrazený koncový bod SQL služby Azure Synapse
-
Constants.SERVER- – Koncový bod vyhrazeného fondu SQL Synapse (plně kvalifikovaný název domény serveru). -
Constants.USER– Uživatelské jméno SQL. -
Constants.PASSWORD– Heslo uživatele SQL. -
Constants.STAGING_STORAGE_ACCOUNT_KEYpřidružený k účtu úložiště, který hostujeConstants.TEMP_FOLDERS(pouze interní typy tabulek) neboConstants.DATA_SOURCE.
-
- Koncový bod služby Azure Data Lake Storage (Gen 2) – Pracovní složky
- Přihlašovací údaje základního ověřování SQL se nevztahují na přístup ke koncovým bodům úložiště.
- Proto se ujistěte, že chcete přiřadit relevantní přístupová oprávnění k úložišti, jak je popsáno v části Azure Data Lake Storage Gen2.
- Vyhrazený koncový bod SQL služby Azure Synapse
Šablony kódu
Tato část obsahuje referenční šablony kódu, které popisují použití a vyvolání konektoru vyhrazeného fondu SQL Azure Synapse pro Apache Spark.
Poznámka:
Použití konektoru v Pythonu
- Konektor se podporuje jenom v Pythonu pro Spark 3. Pro Spark 2.4 (nepodporované) můžeme použít rozhraní API konektoru Scala k interakci s obsahem z datového rámce v PySpark pomocí objektu DataFrame.createOrReplaceTempView nebo DataFrame.createOrReplaceGlobalTempView. Viz část – Použití materializovaných dat napříč buňkami.
- Popisovač zpětného volání není v Pythonu dostupný.
Čtení z vyhrazeného fondu SQL Azure Synapse
Read Request – synapsesql podpis metody
Čtení z tabulky pomocí ověřování na základě ID Microsoft Entra
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Čtení z dotazu pomocí ověřování založeného na Microsoft Entra ID
Poznámka:
Omezení při čtení z dotazu:
- Název tabulky a dotaz nelze zadat současně.
- Jsou povoleny pouze výběrové dotazy. Seznamy DDL a DML SQLs nejsou povoleny.
- Možnosti výběru a filtru datového rámce se při zadání dotazu neodsouvají do vyhrazeného fondu SQL.
- Čtení z dotazu je dostupné jenom ve Sparku 3.
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.option(Constants.QUERY, "select <column_name>, count(*) as cnt from <schema_name>.<table_name> group by <column_name>")
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>")
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Čtení z tabulky pomocí základního ověřování
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the table will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Čtení z dotazu pomocí základního ověřování
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config or as a Constant - Constants.DATABASE
spark.conf.set("spark.sqlanalyticsconnector.dw.database", "<database_name>")
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
option(Constants.QUERY, "select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>" ).
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Zápis do vyhrazeného fondu SQL Azure Synapse
Žádost o zápis – synapsesql podpis metody
synapsesql(tableName:String,
tableType:String = Constants.INTERNAL,
location:Option[String] = None,
callBackHandle=Option[(Map[String, Any], Option[Throwable])=>Unit]):Unit
Zápis pomocí ověřování založeného na MICROSOFT Entra ID
Následuje komplexní šablona kódu, která popisuje použití konektoru pro scénáře zápisu:
//Add required imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Define read options for example, if reading from CSV source, configure header and delimiter options.
val pathToInputSource="abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_folder>/<some_dataset>.csv"
//Define read configuration for the input CSV
val dfReadOptions:Map[String, String] = Map("header" -> "true", "delimiter" -> ",")
//Initialize DataFrame that reads CSV data from a given source
val readDF:DataFrame=spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(1000) //Reads first 1000 rows from the source CSV input.
//Setup and trigger the read DataFrame for write to Synapse Dedicated SQL Pool.
//Fully qualified SQL Server DNS name can be obtained using one of the following methods:
// 1. Synapse Workspace - Manage Pane - SQL Pools - <Properties view of the corresponding Dedicated SQL Pool>
// 2. From Azure Portal, follow the bread-crumbs for <Portal_Home> -> <Resource_Group> -> <Dedicated SQL Pool> and then go to Connection Strings/JDBC tab.
//If `Constants.SERVER` is not provided, the value will be inferred by using the `database_name` in the three-part table name argument to the `synapsesql` method.
//Like-wise, if `Constants.TEMP_FOLDER` is not provided, the connector will use the runtime staging directory config (see section on Configuration Options for details).
val writeOptionsWithAADAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Setup optional callback/feedback function that can receive post write metrics of the job performed.
var errorDuringWrite:Option[Throwable] = None
val callBackFunctionToReceivePostWriteMetrics: (Map[String, Any], Option[Throwable]) => Unit =
(feedback: Map[String, Any], errorState: Option[Throwable]) => {
println(s"Feedback map - ${feedback.map{case(key, value) => s"$key -> $value"}.mkString("{",",\n","}")}")
errorDuringWrite = errorState
}
//Configure and submit the request to write to Synapse Dedicated SQL Pool (note - default SaveMode is set to ErrorIfExists)
//Sample below is using AAD-based authentication approach; See further examples to leverage SQL Basic auth.
readDF.
write.
//Configure required configurations.
options(writeOptionsWithAADAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Optional parameter that is used to specify external table's base folder; defaults to `database_name/schema_name/table_name`
location = None,
//Optional parameter to receive a callback.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
//If write request has failed, raise an error and fail the Cell's execution.
if(errorDuringWrite.isDefined) throw errorDuringWrite.get
Zápis pomocí základního ověřování
Následující fragment kódu nahrazuje definici zápisu popsanou v části Ověřování na základě id Microsoft Entra, která odešle požadavek na zápis pomocí přístupu základního ověřování SQL:
//Define write options to use SQL basic authentication
val writeOptionsWithBasicAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
//Set database user name
Constants.USER -> "<user_name>",
//Set database user's password
Constants.PASSWORD -> "<user_password>",
//Required only when writing to an external table. For write to internal table, this can be used instead of TEMP_FOLDER option.
Constants.DATA_SOURCE -> "<Name of the datasource as defined in the target database>"
//To be used only when writing to internal tables. Storage path will be used for data staging.
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Configure and submit the request to write to Synapse Dedicated SQL Pool.
readDF.
write.
options(writeOptionsWithBasicAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Not required for writing to an internal table
location = None,
//Optional parameter.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
Pokud chcete číst data ze zdrojové cesty k úložišti, vyžadují se základní metody ověřování. Následující fragment kódu poskytuje příklad pro čtení ze zdroje dat Azure Data Lake Storage Gen2 pomocí přihlašovacích údajů instančního objektu:
//Specify options that Spark runtime must support when interfacing and consuming source data
val storageAccountName="<storageAccountName>"
val storageContainerName="<storageContainerName>"
val subscriptionId="<AzureSubscriptionID>"
val spnClientId="<ServicePrincipalClientID>"
val spnSecretKeyUsedAsAuthCred="<spn_secret_key_value>"
val dfReadOptions:Map[String, String]=Map("header"->"true",
"delimiter"->",",
"fs.defaultFS" -> s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net",
s"fs.azure.account.auth.type.$storageAccountName.dfs.core.windows.net" -> "OAuth",
s"fs.azure.account.oauth.provider.type.$storageAccountName.dfs.core.windows.net" ->
"org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id" -> s"$spnClientId",
"fs.azure.account.oauth2.client.secret" -> s"$spnSecretKeyUsedAsAuthCred",
"fs.azure.account.oauth2.client.endpoint" -> s"https://login.microsoftonline.com/$subscriptionId/oauth2/token",
"fs.AbstractFileSystem.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.Abfs",
"fs.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.SecureAzureBlobFileSystem")
//Initialize the Storage Path string, where source data is maintained/kept.
val pathToInputSource=s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net/<base_path_for_source_data>/<specific_file (or) collection_of_files>"
//Define data frame to interface with the data source
val df:DataFrame = spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(100)
Podporované režimy ukládání datového rámce
Při zápisu zdrojových dat do cílové tabulky ve vyhrazeném fondu SQL Azure Synapse se podporují následující režimy ukládání:
- ErrorIfExists (výchozí režim ukládání)
- Pokud cílová tabulka existuje, zápis se přeruší s výjimkou vrácenou volaným. V opačném případě se vytvoří nová tabulka s daty z pracovních složek.
- Ignorovat
- Pokud cílová tabulka existuje, bude zápis ignorovat požadavek na zápis bez vrácení chyby. V opačném případě se vytvoří nová tabulka s daty z pracovních složek.
- Přepsat
- Pokud cílová tabulka existuje, nahradí se stávající data v cíli daty z pracovních složek. V opačném případě se vytvoří nová tabulka s daty z pracovních složek.
- Připojit
- Pokud cílová tabulka existuje, připojí se k ní nová data. V opačném případě se vytvoří nová tabulka s daty z pracovních složek.
Popisovač zpětného volání žádosti zápisu
Nové rozhraní API cest zápisu zavedlo experimentální funkci, která klientovi poskytuje mapu klíč-hodnota> metrik po zápisu. Klíče pro metriky jsou definovány v nové definici objektu - Constants.FeedbackConstants. Metriky je možné načíst jako řetězec JSON předáním popisovače zpětného volání (a Scala Function). Následuje podpis funkce:
//Function signature is expected to have two arguments - a `scala.collection.immutable.Map[String, Any]` and an Option[Throwable]
//Post-write if there's a reference of this handle passed to the `synapsesql` signature, it will be invoked by the closing process.
//These arguments will have valid objects in either Success or Failure case. In case of Failure the second argument will be a `Some(Throwable)`.
(Map[String, Any], Option[Throwable]) => Unit
Tady jsou některé velmi srozumitelné metriky (uvedené v camel case):
WriteFailureCauseDataStagingSparkJobDurationInMillisecondsNumberOfRecordsStagedForSQLCommitSQLStatementExecutionDurationInMillisecondsrows_processed
Následuje ukázkový řetězec JSON s metrikami po zápisu:
{
SparkApplicationId -> <spark_yarn_application_id>,
SQLStatementExecutionDurationInMilliseconds -> 10113,
WriteRequestReceivedAtEPOCH -> 1647523790633,
WriteRequestProcessedAtEPOCH -> 1647523808379,
StagingDataFileSystemCheckDurationInMilliseconds -> 60,
command -> "COPY INTO [schema_name].[table_name] ...",
NumberOfRecordsStagedForSQLCommit -> 100,
DataStagingSparkJobEndedAtEPOCH -> 1647523797245,
SchemaInferenceAssertionCompletedAtEPOCH -> 1647523790920,
DataStagingSparkJobDurationInMilliseconds -> 5252,
rows_processed -> 100,
SaveModeApplied -> TRUNCATE_COPY,
DurationInMillisecondsToValidateFileFormat -> 75,
status -> Completed,
SparkApplicationName -> <spark_application_name>,
ThreePartFullyQualifiedTargetTableName -> <database_name>.<schema_name>.<table_name>,
request_id -> <query_id_as_retrieved_from_synapse_dedicated_sql_db_query_reference>,
StagingFolderConfigurationCheckDurationInMilliseconds -> 2,
JDBCConfigurationsSetupAtEPOCH -> 193,
StagingFolderConfigurationCheckCompletedAtEPOCH -> 1647523791012,
FileFormatValidationsCompletedAtEPOCHTime -> 1647523790995,
SchemaInferenceCheckDurationInMilliseconds -> 91,
SaveModeRequested -> Overwrite,
DataStagingSparkJobStartedAtEPOCH -> 1647523791993,
DurationInMillisecondsTakenToGenerateWriteSQLStatements -> 4
}
Další ukázky kódu
Použití materializovaných dat napříč buňkami
Datový rámec createOrReplaceTempView Sparku lze použít k přístupu k datům načteným v jiné buňce registrací dočasného zobrazení.
- Buňka, kde se načítají data (řekněme s předvolbou jazyka poznámkového bloku jako
Scala)
//Necessary imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Configure options and read from Synapse Dedicated SQL Pool.
val readDF = spark.read.
//Set Synapse Dedicated SQL End Point name.
option(Constants.SERVER, "<synapse-dedicated-sql-end-point>.sql.azuresynapse.net").
//Set database user name.
option(Constants.USER, "<user_name>").
//Set database user's password.
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
option(Constants.DATA_SOURCE,"<data_source_name>").
//Set the three-part table name from which the read must be performed.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Optional - specify number of records the DataFrame would read.
limit(10)
//Register the temporary view (scope - current active Spark Session)
readDF.createOrReplaceTempView("<temporary_view_name>")
- Teď změňte předvolbu jazyka v poznámkovém bloku na
PySpark (Python)a načtěte data z registrovaného zobrazení.<temporary_view_name>
spark.sql("select * from <temporary_view_name>").show()
Zpracování odpovědí
Vyvolání synapsesql má dva možné koncové stavy – úspěch nebo stav selhání. Tato část popisuje, jak zpracovat odpověď na žádost pro jednotlivé scénáře.
Odpověď na žádost o čtení
Po dokončení se fragment odpovědi pro čtení zobrazí ve výstupu buňky. Selhání v aktuální buňce také zruší následné provádění buněk. Podrobné informace o chybách jsou k dispozici v protokolech aplikací Sparku.
Odpověď na žádost o zápis
Ve výchozím nastavení se do výstupu buňky vytiskne odpověď zápisu. Při selhání je aktuální buňka označena jako neúspěšná a následné provádění buněk bude přerušeno. Druhým přístupem je předání možnosti popisovače zpětného volání metoděsynapsesql. Popisovač zpětného volání poskytne programový přístup k odpovědi zápisu.
Ostatní úvahy
- Při čtení z tabulek vyhrazeného fondu SQL Azure Synapse:
- Zvažte použití nezbytných filtrů v datovém rámci, abyste mohli využít funkci vyřazení sloupců konektoru.
- Scénář čtení nepodporuje
TOP(n-rows)klauzuli při vytvářeníSELECTrámců příkazů dotazu. Volba pro omezení dat spočívá v použití klauzule Limit(.) datového rámce.- Podívejte se na příklad – použití materializovaných dat v oddílu buněk .
- Při zápisu do tabulek vyhrazeného fondu SQL Azure Synapse:
- Pro interní typy tabulek:
- Tabulky se vytvářejí s ROUND_ROBIN rozdělením dat.
- Typy sloupců se odvozují z datového rámce, který bude číst data ze zdroje. Řetězcové sloupce jsou mapovány na
NVARCHAR(4000).
- Pro externí typy tabulek:
- Počáteční paralelismus datového rámce řídí organizaci dat pro externí tabulku.
- Typy sloupců se odvozují z datového rámce, který bude číst data ze zdroje.
- Lepší distribuci dat mezi exekutory je možné dosáhnout vyladěním
spark.sql.files.maxPartitionBytesparametru datového rámce a datovéhorepartitionrámce. - Při psaní velkých datových sad je důležité při rozhodování o dopadu nastavení úrovně výkonu DWU, které omezuje velikost transakce.
- Pro interní typy tabulek:
- Monitorujte trendy využití Azure Data Lake Storage Gen2 a sledujte chování omezování, které může mít vliv na výkon čtení a zápisu.