Osvědčené postupy pro používání služby Azure Data Lake Storage
Tento článek obsahuje doporučené postupy, které vám pomůžou optimalizovat výkon, snížit náklady a zabezpečit účet Služby Azure Storage s podporou služby Data Lake Storage.
Obecné návrhy týkající se strukturování datového jezera najdete v těchto článcích:
- Přehled služby Azure Data Lake Storage pro scénář správy a analýzy dat
- Zřízení tří účtů Azure Data Lake Storage pro každou cílovou zónu dat
Umožňuje najít dokumentaci.
Azure Data Lake Storage není vyhrazená služba ani typ účtu. Jedná se o sadu funkcí, které podporují analytické úlohy s vysokou propustností. Dokumentace ke službě Data Lake Storage poskytuje osvědčené postupy a pokyny k používání těchto funkcí. Všechny další aspekty správy účtů, jako je nastavení zabezpečení sítě, návrh pro zajištění vysoké dostupnosti a zotavení po havárii, najdete v dokumentaci k úložišti objektů blob.
Vyhodnocení podpory funkcí a známých problémů
Při konfiguraci účtu tak, aby používal funkce úložiště objektů blob, použijte následující vzor.
Projděte si podporu funkcí služby Blob Storage v článku o účtech Azure Storage a zjistěte, jestli je funkce ve vašem účtu plně podporovaná. Některé funkce ještě nejsou podporované nebo mají částečnou podporu v účtech s povolenými službami Data Lake Storage. Podpora funkcí se neustále rozšiřuje, proto nezapomeňte pravidelně kontrolovat aktualizace v tomto článku.
Projděte si článek o známých problémech se službou Azure Data Lake Storage a zjistěte, jestli existují nějaká omezení nebo zvláštní pokyny týkající se funkce, kterou chcete použít.
V článcích o funkcích najdete všechny pokyny specifické pro účty s povolenými službami Data Lake Storage.
Vysvětlení termínů použitých v dokumentaci
Při procházení mezi sadami obsahu si všimnete drobných rozdílů v terminologii. Například obsah doporučený v dokumentaci k úložišti objektů blob bude místo souboru používat objekt blobtermínu. Technicky vzato se soubory, které ingestujete do účtu úložiště, stanou objekty blob ve vašem účtu. Proto je termín správný. Objekt blob termínu ale může způsobit nejasnost, pokud jste zvyklí na soubor termínů. Uvidíte také kontejner termínů, který se používá pro odkaz na systém souborů. Zvažte tyto termíny jako synonymum.
Zvažte premium
Pokud vaše úlohy vyžadují nízkou konzistentní latenci nebo vyžadují vysoký počet vstupních výstupních operací za sekundu (IOP), zvažte použití účtu úložiště objektů blob bloku úrovně Premium. Tento typ účtu zpřístupňuje data prostřednictvím vysoce výkonného hardwaru. Data se ukládají na disky SSD (Solid-State Drive), které jsou optimalizované pro nízkou latenci. Disky SSD poskytují vyšší propustnost v porovnání s tradičními pevnými disky. Náklady na úložiště na výkon úrovně Premium jsou vyšší, ale náklady na transakce jsou nižší. Proto pokud vaše úlohy provádějí velký počet transakcí, může být účet objektů blob bloku s výkonem úrovně Premium ekonomický.
Pokud se váš účet úložiště bude používat pro analýzy, důrazně doporučujeme používat Azure Data Lake Storage spolu s účtem úložiště objektů blob bloku úrovně Premium. Tato kombinace použití účtů úložiště objektů blob bloku úrovně Premium spolu s povoleným účtem Data Lake Storage se označuje jako úroveň Premium pro Azure Data Lake Storage.
Optimalizace pro příjem dat
Při příjmu dat ze zdrojového systému může být kritickým bodem zdrojový hardware, zdrojový síťový hardware nebo síťové připojení k vašemu účtu úložiště.
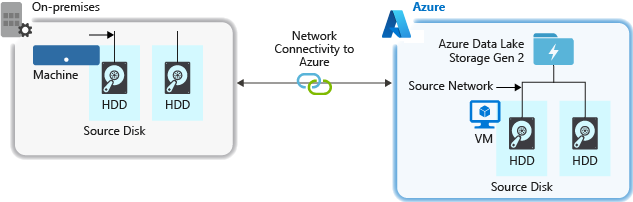
Zdrojový hardware
Bez ohledu na to, jestli používáte místní počítače nebo virtuální počítače v Azure, nezapomeňte pečlivě vybrat příslušný hardware. Pro diskový hardware zvažte použití jednotek SSD (Solid State Drive) a výběr hardwaru disku, který má rychlejší disková zařízení. Pro síťový hardware použijte co nejrychleji síťové adaptéry. V Azure doporučujeme virtuální počítače Azure D14, které mají správně výkonný disk a síťový hardware.
Síťové připojení k účtu úložiště
Připojení k síti mezi zdrojovými daty a účtem úložiště může někdy být kritickým bodem. Pokud jsou zdrojová data místní, zvažte použití vyhrazeného odkazu s Azure ExpressRoute. Pokud jsou zdrojová data v Azure, nejlepší je výkon, když jsou data ve stejné oblasti Azure jako váš účet s povoleným účtem Data Lake Storage.
Konfigurace nástrojů pro příjem dat pro maximální paralelizaci
Pokud chcete dosáhnout co nejlepšího výkonu, využijte veškerou dostupnou propustnost tak, že souběžně provádíte tolik čtení a zápisů.
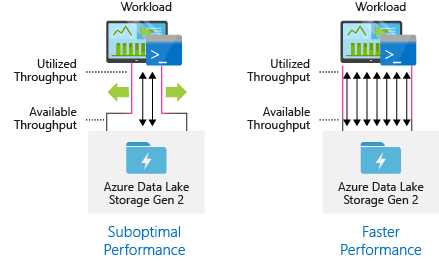
Následující tabulka shrnuje klíčové nastavení několika oblíbených nástrojů pro příjem dat.
| Nástroj | Nastavení |
|---|---|
| DistCp | -m (mapper) |
| Azure Data Factory | parallelCopies |
| Sqoop | fs.azure.block.size, -m (mapper) |
| AzCopy | AZCOPY_CONCURRENCY_VALUE |
Poznámka:
Celkový výkon operací ingestování závisí na dalších faktorech specifických pro nástroj, který používáte k ingestování dat. Nejlepší aktuální pokyny najdete v dokumentaci ke každému nástroji, který chcete použít.
Váš účet může škálovat tak, aby poskytoval potřebnou propustnost pro všechny analytické scénáře. Ve výchozím nastavení poskytuje účet s povolenou službou Data Lake Storage dostatečnou propustnost ve své výchozí konfiguraci, aby splňoval potřeby široké kategorie případů použití. Pokud narazíte na výchozí limit, můžete účet nakonfigurovat tak, aby poskytoval větší propustnost kontaktováním podpory Azure.
Strukturování datových sad
Zvažte předběžné plánování struktury vašich dat. Formát souboru, velikost souboru a adresářová struktura můžou mít vliv na výkon a náklady.
Formáty souborů
Data je možné ingestovat v různých formátech. Data se můžou zobrazovat v čitelných formátech člověka, jako jsou JSON, CSV nebo XML nebo jako komprimované binární formáty, například .tar.gz. Data můžou mít také různé velikosti. Data se dají skládat z velkých souborů (několik terabajtů), jako jsou data z exportu tabulky SQL z místních systémů. Data mohou také pocházet z velkého počtu malých souborů (několik kilobajtů), jako jsou data z událostí v reálném čase z řešení Internetu věcí (IoT). Efektivitu a náklady můžete optimalizovat výběrem vhodného formátu a velikosti souboru.
Hadoop podporuje sadu formátů souborů, které jsou optimalizované pro ukládání a zpracování strukturovaných dat. Mezi běžné formáty patří Avro, Parquet a Optimized Row Columnar (ORC). Všechny tyto formáty jsou strojově čitelné binární formáty souborů. Komprimují se, aby vám pomohly spravovat velikost souboru. Mají schéma vložené do každého souboru, takže je samopopisuje. Rozdíl mezi těmito formáty spočívá v ukládání dat. Avro ukládá data ve formátu založeném na řádcích a formát Parquet a ORC ukládají data ve sloupcovém formátu.
Zvažte použití formátu souboru Avro v případech, kdy jsou vaše vstupně-výstupní vzory náročné na zápis, nebo vzory dotazů dávají přednost načítání více řádků záznamů v celém rozsahu. Formát Avro například funguje dobře s sběrnici zpráv, jako je Event Hubs nebo Kafka, které postupně zapisují více událostí a zpráv.
Zvažte formáty souborů Parquet a ORC, pokud jsou vzory vstupně-výstupních operací náročné na čtení nebo když jsou vzorky dotazů zaměřeny na podmnožinu sloupců v záznamech. Transakce čtení je možné optimalizovat tak, aby načítaly konkrétní sloupce místo čtení celého záznamu.
Apache Parquet je opensourcový formát souboru, který je optimalizovaný pro kanály pro čtení náročných analýz. Struktura sloupcového úložiště Parquet umožňuje přeskočit nerelevantní data. Vaše dotazy jsou mnohem efektivnější, protože můžou zúžit rozsah dat, která se mají odesílat z úložiště do analytického modulu. Vzhledem k tomu, že se podobné datové typy (pro sloupec) ukládají společně, parquet podporuje efektivní schémata komprese a kódování dat, která můžou snížit náklady na úložiště dat. Služby, jako jsou Azure Synapse Analytics, Azure Databricks a Azure Data Factory, mají nativní funkce, které využívají formáty souborů Parquet.
Velikost souboru
Větší soubory vedou k lepšímu výkonu a snížení nákladů.
Analytické moduly, jako je HDInsight, mají obvykle režijní náklady na jednotlivé soubory, které zahrnují úlohy, jako je výpis, kontrola přístupu a provádění různých operací metadat. Pokud ukládáte data tolik malých souborů, může to negativně ovlivnit výkon. Obecně platí, že data uspořádejte do větších souborů s větší velikostí, abyste měli lepší výkon (velikost 256 MB až 100 GB). Některé moduly a aplikace můžou mít potíže s efektivním zpracováním souborů, které jsou větší než 100 GB.
Zvýšení velikosti souboru může také snížit náklady na transakce. Operace čtení a zápisu se účtují v přírůstcích po 4 megabajtech, takže se vám účtují poplatky za operaci bez ohledu na to, jestli soubor obsahuje 4 megabajty nebo jen několik kilobajtů. Informace o cenách najdete v tématu s cenami služby Azure Data Lake Storage.
Datové kanály někdy mají omezenou kontrolu nad nezpracovaná data, která obsahují velké množství malých souborů. Obecně doporučujeme, aby měl váš systém nějaký proces, který agreguje malé soubory do větších, aby je mohly používat podřízené aplikace. Pokud zpracováváte data v reálném čase, můžete použít modul streamování v reálném čase (například Azure Stream Analytics nebo Streamování Sparku) společně s zprostředkovatelem zpráv (například Event Hubs nebo Apache Kafka) k ukládání dat jako větších souborů. Při agregaci malých souborů do větších souborů zvažte jejich uložení ve formátu optimalizovaném pro čtení, jako je Apache Parquet pro zpracování podřízeného zpracování.
Adresářová struktura
Každá úloha má různé požadavky na způsob využívání dat, ale jedná se o některá běžná rozložení, která je potřeba vzít v úvahu při práci s internetem věcí (IoT), dávkových scénářích nebo při optimalizaci dat časových řad.
Struktura IoT
V úlohách IoT se může ingestovat velké množství dat, která pokrývají celou řadu produktů, zařízení, organizací a zákazníků. Je důležité předem naplánovat rozložení adresáře pro organizaci, zabezpečení a efektivní zpracování dat pro uživatele down-streamu. Obecná šablona, která se má zvážit, může být následující rozložení:
- {Region}/{SubjectMatter(s)}/{yyyy}/{mm}/{dd}/{hh}/
Například cílová telemetrie pro modul v letadle ve Velké Británii může vypadat jako následující struktura:
- UK/Letadla/BA1293/Motor1/2017/08/11/12/
V tomto příkladu tak, že umístíte datum na konec adresářové struktury, můžete seznamy ACL použít k snadnějšímu zabezpečení oblastí a předmětu konkrétních uživatelů a skupin. Pokud vložíte strukturu kalendářních dat na začátek, bude mnohem obtížnější zabezpečit tyto oblasti a záležitosti. Pokud byste například chtěli poskytnout přístup pouze k datům Uk nebo určitým rovinám, musíte použít samostatné oprávnění pro množství adresářů v rámci každou hodinu. Tato struktura by také exponenciálně zvýšila počet adresářů podle času.
Struktura dávkových úloh
Běžně používaným přístupem při dávkovém zpracování je umístit data do adresáře "in". Jakmile se data zpracují, vložte nová data do "out" adresáře, aby podřízené procesy spotřebovaly. Tato adresářová struktura se někdy používá pro úlohy, které vyžadují zpracování jednotlivých souborů, a nemusí vyžadovat masivní paralelní zpracování u velkých datových sad. Podobně jako výše doporučená struktura IoT má dobrá adresářová struktura adresáře nadřazené adresáře pro věci, jako jsou oblast a předměty (například organizace, produkt nebo producent). Zvažte datum a čas ve struktuře, abyste umožnili lepší organizaci, filtrované vyhledávání, zabezpečení a automatizaci při zpracování. Úroveň členitosti struktury kalendářních dat je určena intervalem, ve kterém se data nahrávají nebo zpracovávají, například hodinově, denně nebo dokonce měsíčně.
Zpracování souborů je někdy neúspěšné kvůli poškození dat nebo neočekávaným formátům. V takových případech může adresářová struktura těžit ze složky /bad a přesunout soubory do další kontroly. Dávková úloha může také zpracovávat hlášení nebo oznámení těchto chybných souborů pro ruční zásah. Představte si následující strukturu šablony:
- {Region}/{SubjectMatter(s)}/In/{yyyy}/{mm}/{dd}/{hh}/
- {Region}/{SubjectMatter(s)}/Out/{yyyy}/{mm}/{dd}/{hh}/
- {Region}/{SubjectMatter(s)}/Bad/{yyyy}/{mm}/{dd}/{hh}/
Například marketingová firma přijímá denní data extrahování aktualizací zákazníků ze svých klientů v Severní Amerika. Může to vypadat jako následující fragment kódu před zpracováním a po jeho zpracování:
- NA/Extracts/ACMEPaperCo/In/2017/08/14/updates_08142017.csv
- NA/Extracts/ACMEPaperCo/Out/2017/08/14/processed_updates_08142017.csv
V běžném případě dávkových dat zpracovávaných přímo do databází, jako je Hive nebo tradiční databáze SQL, není potřeba adresář /in nebo /out , protože výstup už přejde do samostatné složky pro tabulku Hive nebo externí databázi. Například denní extrakce od zákazníků by se dostala do příslušných adresářů. Pak by služba, jako je Azure Data Factory, Apache Oozie nebo Apache Airflow , aktivovala každodenní úlohu Hive nebo Sparku pro zpracování a zápis dat do tabulky Hive.
Datová struktura časových řad
U úloh Hive může dělení dat časových řad pomoct některým dotazům číst jen podmnožinu dat, což zlepšuje výkon.
Tyto kanály, které ingestují data časových řad, často umisťují soubory se strukturovaným pojmenováním souborů a složek. Níže je běžný příklad dat, která jsou strukturovaná podle data:
/DataSet/YYYY/MM/DD/datafile_YYYY_MM_DD.tsv
Všimněte si, že informace o datetime se zobrazují jako složky i v názvu souboru.
Pro datum a čas je běžným vzorem následující:
/DataSet/YYYY/MM/DD/HH/mm/datafile_YYYY_MM_DD_HH_mm.tsv
Opět platí, že volba, kterou zvolíte s organizací složek a souborů, by měla optimalizovat pro větší velikosti souborů a přiměřený počet souborů v každé složce.
Nastavit zabezpečení
Začněte tím, že si projděte doporučení v doporučeních zabezpečení pro úložiště objektů blob. Osvědčené postupy pro ochranu dat před náhodným nebo škodlivým odstraněním, zabezpečením dat za bránou firewall a používáním MICROSOFT Entra ID jako základ správy identit najdete v osvědčených postupech.
Pak si projděte model řízení přístupu v článku Azure Data Lake Storage , kde najdete pokyny, které jsou specifické pro účty s povolenými službami Data Lake Storage. Tento článek vám pomůže pochopit, jak používat role řízení přístupu na základě role v Azure (Azure RBAC) společně se seznamy řízení přístupu (ACL) k vynucení oprávnění zabezpečení u adresářů a souborů ve vašem hierarchickém systému souborů.
Ingestování, zpracování a analýza
Existuje mnoho různých zdrojů dat a různých způsobů, jak je možné tato data ingestovat do účtu s povolenou službou Data Lake Storage.
Můžete například ingestovat velké sady dat z clusterů HDInsight a Hadoop nebo menších sad ad hoc dat pro vytváření prototypů aplikací. Můžete ingestovat streamovaná data generovaná různými zdroji, jako jsou aplikace, zařízení a senzory. Pro tento typ dat můžete pomocí nástrojů zaznamenávat a zpracovávat data v jednotlivých událostech v reálném čase a pak zapisovat události do dávek do svého účtu. Můžete také ingestovat protokoly webového serveru, které obsahují informace, jako je historie požadavků na stránky. U dat protokolu zvažte zápis vlastních skriptů nebo aplikací, které je mají nahrát, abyste měli flexibilitu zahrnout komponentu pro nahrávání dat jako součást větší aplikace pro velké objemy dat.
Jakmile jsou data dostupná ve vašem účtu, můžete spouštět analýzy těchto dat, vytvářet vizualizace a dokonce stahovat data do místního počítače nebo do jiných úložišť, jako je databáze Azure SQL nebo instance SQL Serveru.
Následující tabulka doporučuje nástroje, které můžete použít k ingestování, analýze, vizualizaci a stahování dat. Pomocí odkazů v této tabulce najdete pokyny ke konfiguraci a používání jednotlivých nástrojů.
| Účel | Nástroje a pokyny k nástrojům |
|---|---|
| Ingestování ad hoc dat | Azure Portal, Azure PowerShell, Azure CLI, REST, Průzkumník služby Azure Storage, Apache DistCp, AzCopy |
| Ingestování relačních dat | Azure Data Factory |
| Ingestování protokolů webového serveru | Azure PowerShell, Azure CLI, REST, sady Azure SDK (.NET, Java, Python a Node.js), Azure Data Factory |
| Ingestování z clusterů HDInsight | Azure Data Factory, Apache DistCp, AzCopy |
| Příjem z clusterů Hadoop | Azure Data Factory, Apache DistCp, WANdisco LiveData Migrator pro Azure, Azure Data Box |
| Ingestování velkých datových sad (několik terabajtů) | Azure ExpressRoute |
| Zpracování a analýza dat | Azure Synapse Analytics, Azure HDInsight, Databricks |
| Vizualizace dat | Zrychlení dotazů Azure Data Lake Storage v Power BI |
| Stahování souborů | Azure Portal, PowerShell, Azure CLI, REST, sady Azure SDK (.NET, Java, Python a Node.js), Průzkumník služby Azure Storage, AzCopy, Azure Data Factory, Apache DistCp |
Poznámka:
Tato tabulka neodráží úplný seznam služeb Azure, které podporují Data Lake Storage. Pokud chcete zobrazit seznam podporovaných služeb Azure, jejich úroveň podpory, podívejte se na služby Azure, které podporují Azure Data Lake Storage.
Monitorování telemetrie
Monitorování využití a výkonu je důležitou součástí zprovoznění vaší služby. Mezi příklady patří časté operace, operace s vysokou latencí nebo operace, které způsobují omezování na straně služby.
Veškerá telemetrie pro váš účet úložiště je dostupná prostřednictvím protokolů azure Storage ve službě Azure Monitor. Tato funkce integruje váš účet úložiště se službou Log Analytics a event Hubs a zároveň umožňuje archivovat protokoly do jiného účtu úložiště. Úplný seznam metrik a protokolů prostředků a jejich přidruženého schématu najdete v referenčních informacích k monitorování služby Azure Storage.
Umístění, kam se rozhodnete ukládat protokoly, závisí na tom, jak k nim plánujete přistupovat. Pokud například chcete získat přístup k protokolům téměř v reálném čase a mít možnost korelovat události v protokolech s dalšími metrikami ze služby Azure Monitor, můžete protokoly uložit do pracovního prostoru služby Log Analytics. Pak se na protokoly dotazujte pomocí KQL a dotazů autora, které vyčíslí StorageBlobLogs tabulku v pracovním prostoru.
Pokud chcete ukládat protokoly pro dotazy téměř v reálném čase i dlouhodobé uchovávání, můžete nakonfigurovat nastavení diagnostiky tak, aby odesílala protokoly do pracovního prostoru služby Log Analytics i do účtu úložiště.
Pokud chcete získat přístup k protokolům prostřednictvím jiného dotazovacího modulu, jako je Například Splunk, můžete nakonfigurovat nastavení diagnostiky tak, aby odesílala protokoly do centra událostí a ingestuje protokoly z centra událostí do zvoleného cíle.
Protokoly azure Storage ve službě Azure Monitor je možné povolit prostřednictvím webu Azure Portal, PowerShellu, Azure CLI a šablon Azure Resource Manageru. Pro nasazení ve velkém měřítku je možné službu Azure Policy použít s plnou podporou pro úlohy nápravy. Další informace najdete v tématu ciphertxt/AzureStoragePolicy.