Rychlý start: Transformace dat pomocí mapování toků dat
V tomto rychlém startu použijete Azure Synapse Analytics k vytvoření kanálu, který transformuje data ze zdroje Azure Data Lake Storage Gen2 (ADLS Gen2) na jímku ADLS Gen2 pomocí mapování toku dat. Vzor konfigurace v tomto rychlém startu je možné rozšířit při transformaci dat pomocí mapování toku dat.
V tomto rychlém startu provedete následující kroky:
- Vytvořte kanál s aktivitou Tok dat ve službě Azure Synapse Analytics.
- Sestavte tok dat mapování se čtyřmi transformacemi.
- Testovací spuštění kanálu
- Monitorování aktivity Tok dat
Požadavky
Předplatné Azure: Pokud nemáte předplatné Azure, vytvořte si před zahájením bezplatný účet Azure.
Pracovní prostor Azure Synapse: Vytvořte pracovní prostor Synapse pomocí webu Azure Portal podle pokynů v rychlém startu: Vytvoření pracovního prostoru Synapse.
Účet úložiště Azure: Úložiště ADLS používáte jako úložiště dat zdroje a jímky . Pokud účet úložiště nemáte, přečtěte si téma Vytvoření účtu služby Azure Storage, kde najdete postup jeho vytvoření.
Soubor, který transformujeme v tomto kurzu, je MoviesDB.csv, který najdete tady. Pokud chcete soubor načíst z GitHubu, zkopírujte obsah do textového editoru podle vašeho výběru a uložte ho místně jako soubor .csv. Pokud chcete nahrát soubor do účtu úložiště, přečtěte si téma Nahrání objektů blob pomocí webu Azure Portal. Příklady budou odkazovat na kontejner s názvem sample-data.
Přejděte do synapse Studia.
Po vytvoření pracovního prostoru Azure Synapse máte dva způsoby, jak otevřít Synapse Studio:
- Otevřete pracovní prostor Synapse na webu Azure Portal. Na kartě Otevřít Synapse Studio v části Začínáme vyberte Otevřít.
- Otevřete Azure Synapse Analytics a přihlaste se ke svému pracovnímu prostoru.
V tomto rychlém startu použijeme jako příklad pracovní prostor s názvem adftest2020. Automaticky vás převedou na domovskou stránku nástroje Synapse Studio.
Vytvoření kanálu s aktivitou Tok dat
Kanál obsahuje logický tok pro spuštění sady aktivit. V této části vytvoříte kanál, který obsahuje Tok dat aktivitu.
Přejděte na kartu Integrace . Vyberte ikonu plus vedle záhlaví kanálů a vyberte Kanál.
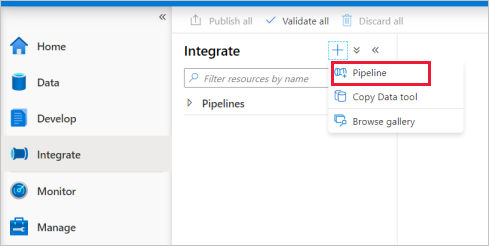
Na stránce Nastavení vlastností kanálu zadejte TransformMovies pro Název.
V části Přesunout a transformovat v podokně Aktivity přetáhněte tok dat na plátno kanálu.
V místní nabídce Přidání toku dat vyberte Vytvořit nový tok dat ->Tok dat. Až to budete mít, vyberte OK.
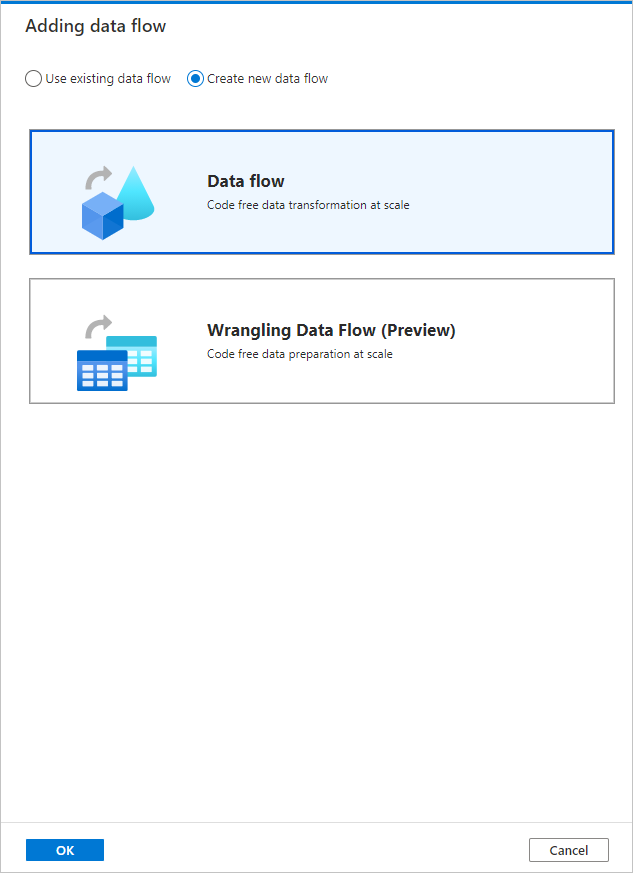
Na stránce Vlastnosti pojmenujte svůj tok dat TransformMovies.
Vytvoření logiky transformace na plátně toku dat
Po vytvoření Tok dat se automaticky odešle na plátno toku dat. V tomto kroku vytvoříte tok dat, který vezme MoviesDB.csv v úložišti ADLS a agreguje průměrné hodnocení comedies z roku 1910 do roku 2000. Potom tento soubor zapíšete zpět do úložiště ADLS.
Nad plátnem toku dat posuňte posuvník ladění toku dat. Režim ladění umožňuje interaktivní testování logiky transformace na živém clusteru Spark. Tok dat clusterů trvá 5 až 7 minut, než se zahřejí, a pokud plánují vývoj Tok dat, doporučuje se nejprve zapnout ladění. Další informace naleznete v tématu Režim ladění.
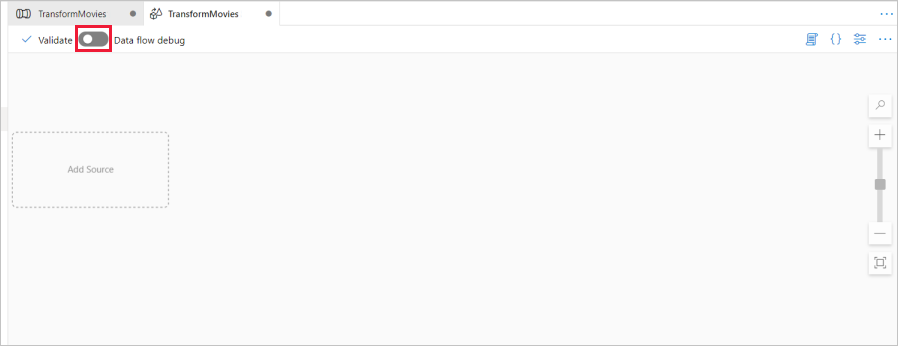
Na plátně toku dat přidejte zdroj kliknutím na pole Přidat zdroj .
Pojmenujte zdroj MoviesDB. Výběrem možnosti Nový vytvoříte novou zdrojovou datovou sadu.
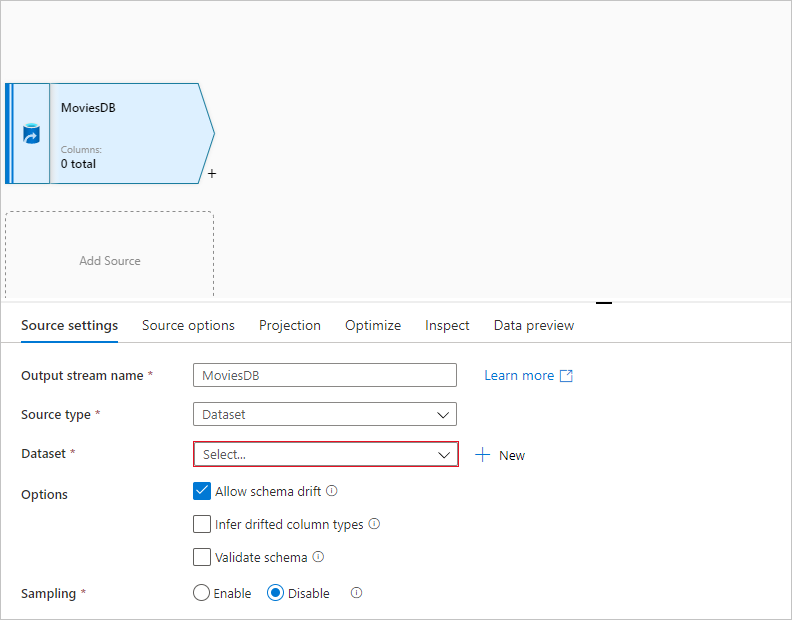
Zvolte Azure Data Lake Storage Gen2. Zvolte Pokračovat.

Zvolte Text s oddělovači. Zvolte Pokračovat.
Pojmenujte datovou sadu MoviesDB. V rozevíracím seznamu propojené služby zvolte Nový.
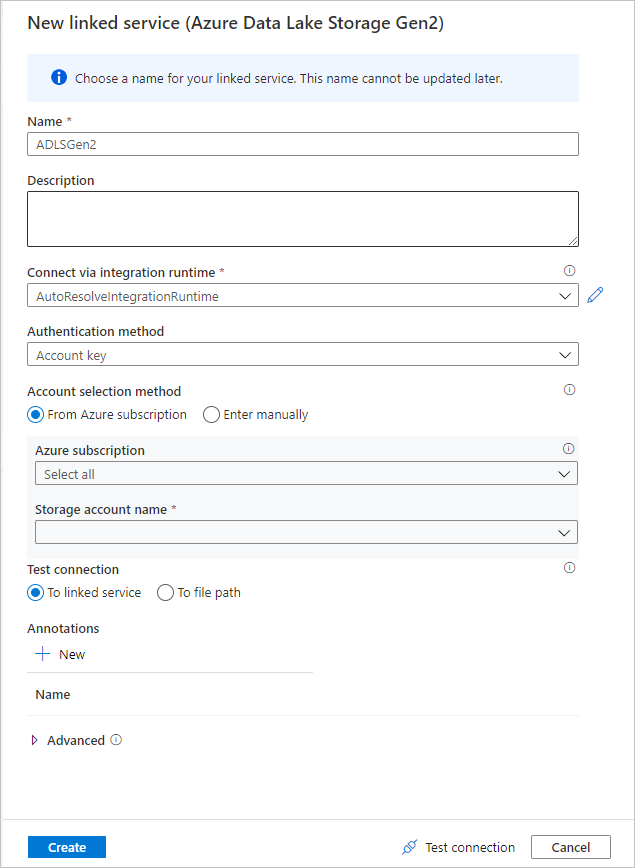
Na obrazovce pro vytvoření propojené služby pojmenujte propojenou službu ADLS Gen2 ADLSGen2 a zadejte metodu ověřování. Pak zadejte přihlašovací údaje pro připojení. V tomto rychlém startu používáme klíč účtu pro připojení k našemu účtu úložiště. Výběrem možnosti Test připojení můžete ověřit, jestli byly vaše přihlašovací údaje zadány správně. Po dokončení vyberte Vytvořit.
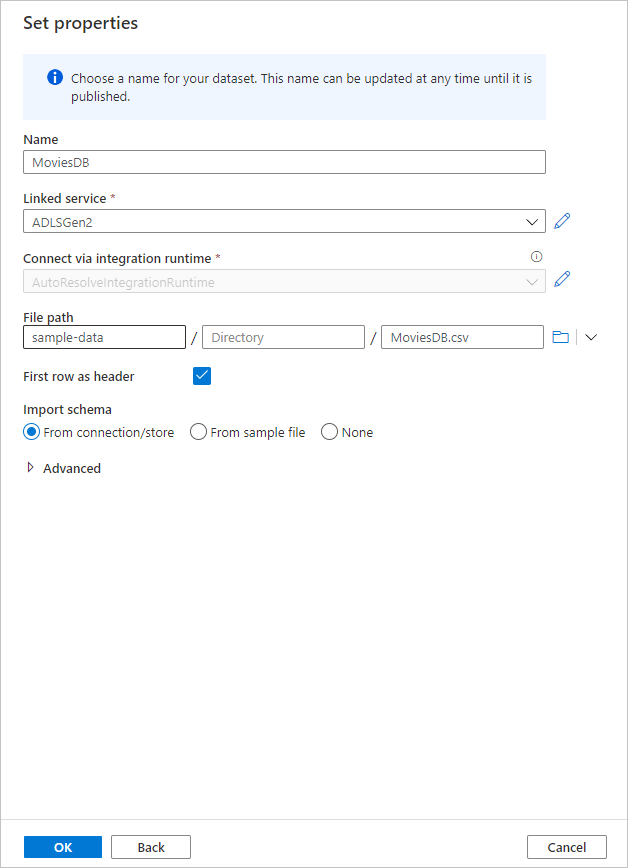
Jakmile se vrátíte na obrazovku pro vytvoření datové sady, zadejte do pole Cesta k souboru místo, kde se soubor nachází. V tomto rychlém startu se soubor "MoviesDB.csv" nachází v kontejneru sample-data. Vzhledem k tomu, že soubor obsahuje záhlaví, zaškrtněte první řádek jako záhlaví. Pokud chcete importovat schéma hlaviček přímo ze souboru v úložišti, vyberte z připojení nebo úložiště . Až to budete mít, vyberte OK.
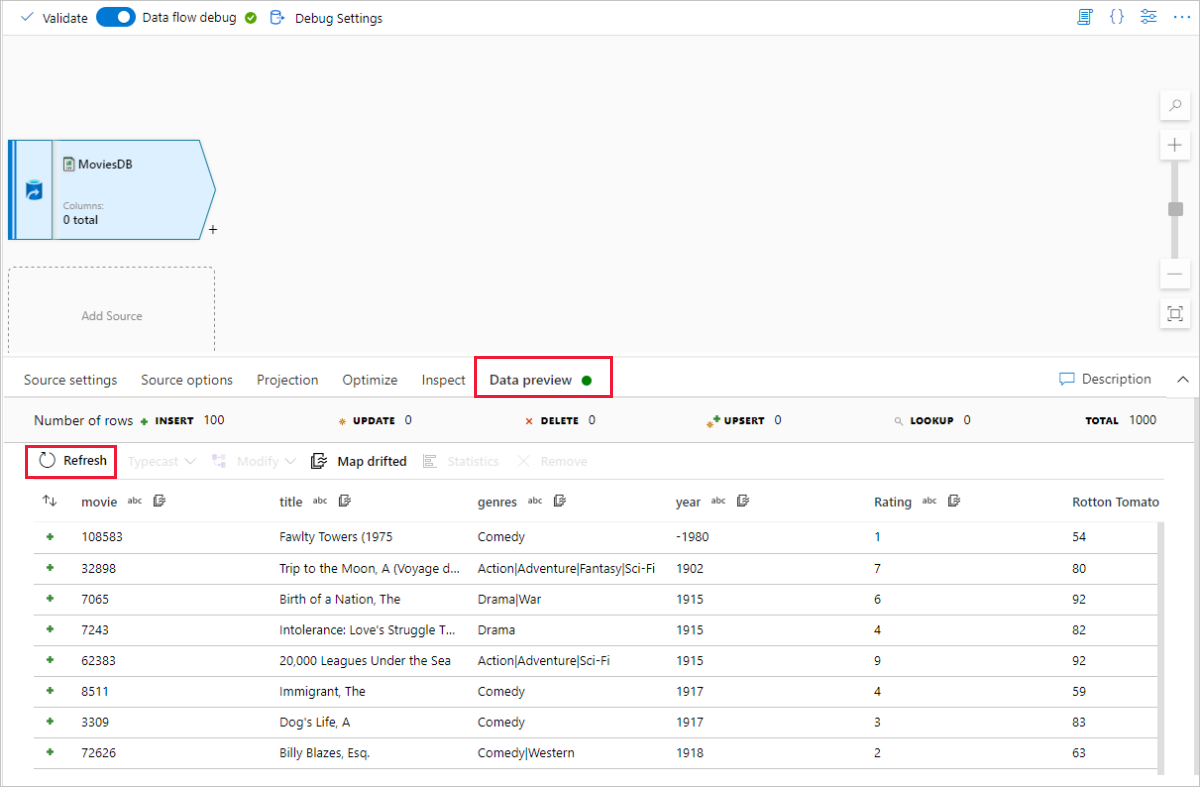
Pokud se váš ladicí cluster spustil, přejděte na kartu Náhled dat ve zdrojové transformaci a vyberte Aktualizovat , abyste získali snímek dat. Pomocí náhledu dat můžete ověřit, jestli je transformace správně nakonfigurovaná.
Vedle zdrojového uzlu na plátně toku dat vyberte ikonu plus a přidejte novou transformaci. První přidanou transformací je filtr.
Pojmenujte transformační filtr FilterYears. Výběrem pole výrazu vedle možnosti Filtrovat otevřete tvůrce výrazů. Tady zadáte podmínku filtrování.
Tvůrce výrazů toku dat umožňuje interaktivně vytvářet výrazy pro použití v různých transformacích. Výrazy můžou zahrnovat předdefinované funkce, sloupce ze vstupního schématu a uživatelem definované parametry. Další informace o vytváření výrazů najdete v tématu Tok dat tvůrce výrazů.
V tomto rychlém startu chcete filtrovat filmy žánrové komedie, které vyšly mezi roky 1910 a 2000. Vzhledem k tomu, že rok je aktuálně řetězec, musíte ho pomocí funkce převést na celé číslo
toInteger(). K porovnání s hodnotami literálového roku 1910 a 200-, použijte operátory> větší než nebo rovno (=) a menší než nebo rovno operátorům (<=). Sjednocujte tyto výrazy společně s operátorem&&(a). Výraz vychází takto:toInteger(year) >= 1910 && toInteger(year) <= 2000Pokud chcete zjistit, které filmy jsou komiky, můžete pomocí
rlike()funkce najít vzor "Comedy" ve sloupcových žánrech. Sjednocujterlikevýraz s porovnáním roku, abyste získali:toInteger(year) >= 1910 && toInteger(year) <= 2000 && rlike(genres, 'Comedy')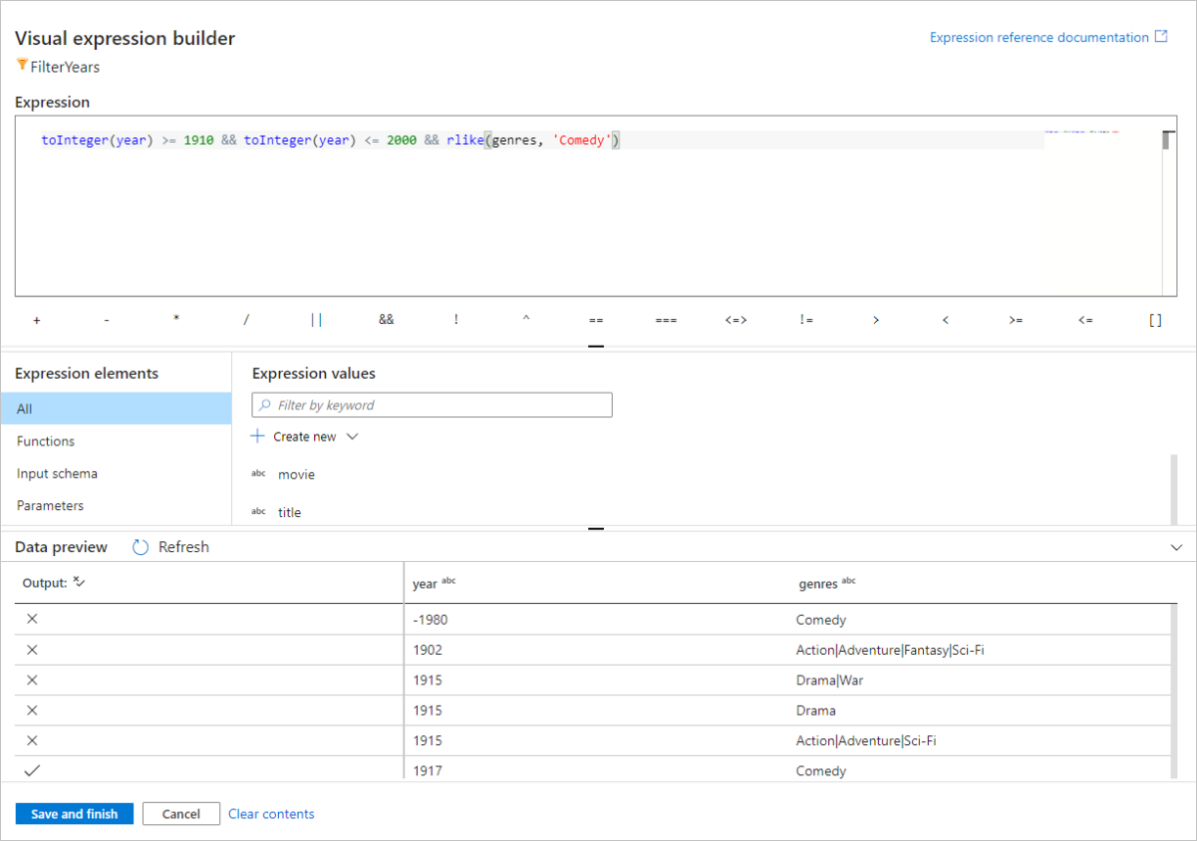
Pokud máte aktivní ladicí cluster, můžete ověřit logiku kliknutím na Aktualizovat a zobrazit výstup výrazu ve srovnání se vstupy použitými. Existuje více než jedna správná odpověď na to, jak tuto logiku dosáhnout pomocí jazyka výrazů toku dat.
Až budete hotovi s výrazem, vyberte Uložit a Dokončit .
Načtením náhledu dat ověřte, že filtr funguje správně.
Další přidanou transformací je agregační transformace v modifikátoru schématu.
Pojmenujte agregační transformaci AggregateComedyRatings. Na kartě Seskupit podle vyberte v rozevíracím seznamu rok a seskupte agregace podle roku, ve které film přišel.
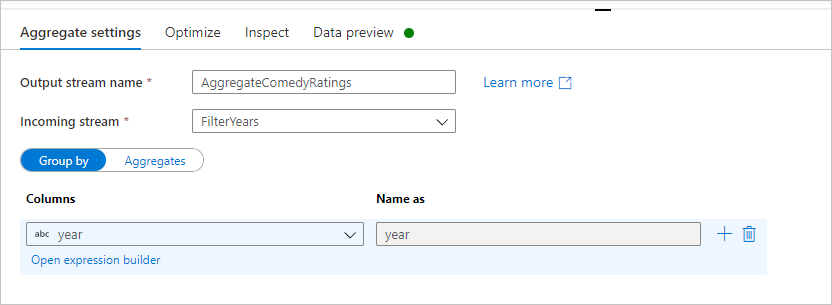
Přejděte na kartu Agregace . V levém textovém poli pojmenujte agregovaný sloupec AverageComedyRating. Výběrem pravého pole výrazu zadejte agregační výraz prostřednictvím tvůrce výrazů.
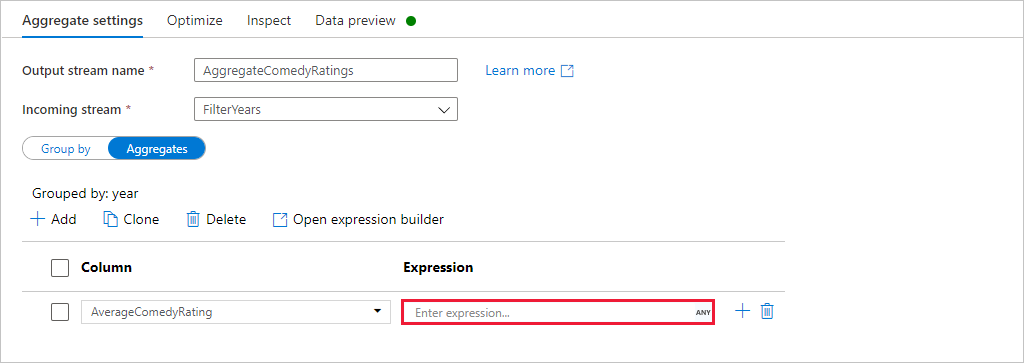
Pokud chcete získat průměr sloupce Hodnocení, použijte
avg()agregační funkci. Protože rating je řetězec aavg()přebírá číselný vstup, musíme hodnotu převést na číslo prostřednictvímtoInteger()funkce. Tento výraz vypadá takto:avg(toInteger(Rating))Po dokončení vyberte Uložit a dokončit .
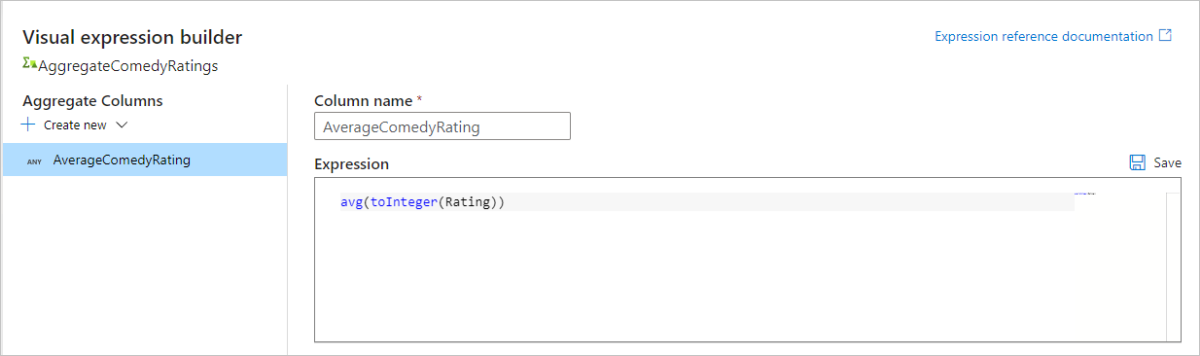
Přejděte na kartu Náhled dat a zobrazte výstup transformace. Všimněte si, že existují jenom dva sloupce, rok a AverageComedyRating.
Dále chcete v části Cíl přidat transformaci jímky.
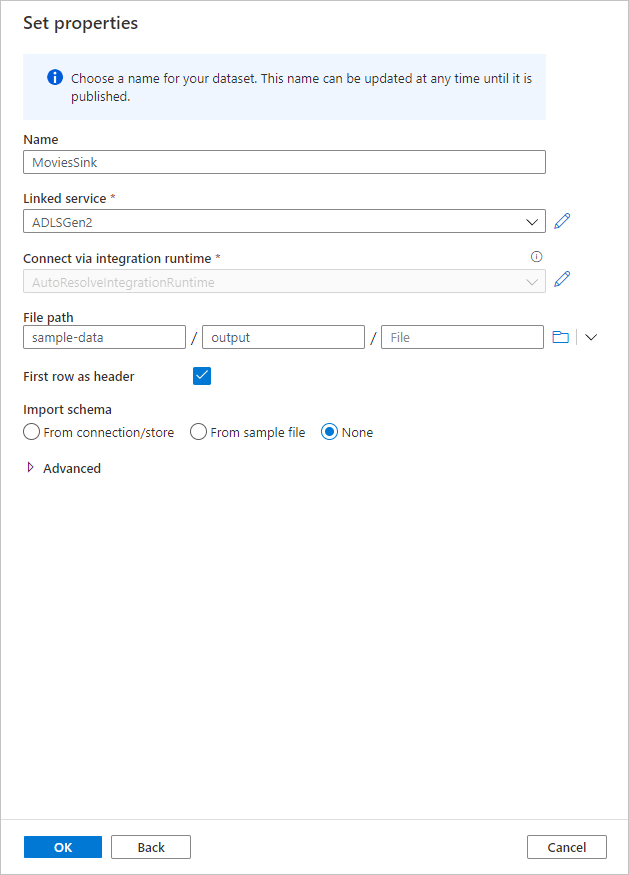
Pojmenujte jímku. Vyberte Nový a vytvořte datovou sadu jímky.
Zvolte Azure Data Lake Storage Gen2. Zvolte Pokračovat.
Zvolte Text s oddělovači. Zvolte Pokračovat.
Pojmenujte datovou sadu jímky MoviesSink. Pro propojenou službu zvolte propojenou službu ADLS Gen2, kterou jste vytvořili v kroku 7. Zadejte výstupní složku pro zápis dat do. V tomto rychlém startu zapisujeme do složky output v kontejneru sample-data. Složka nemusí předem existovat a je možné ji dynamicky vytvořit. Nastavte první řádek jako záhlaví jako true a jako schéma importu vyberte Žádné. Až to budete mít, vyberte OK.
Teď jste dokončili vytváření toku dat. Jste připraveni ho spustit ve svém kanálu.
Spuštění a monitorování Tok dat
Kanál můžete ladit, než ho publikujete. V tomto kroku aktivujete spuštění ladění kanálu toku dat. Náhled dat sice nezapisuje data, ale spuštění ladění zapisuje data do cíle jímky.
Přejděte na plátno kanálu. Vyberte Ladit , aby se aktivovalo spuštění ladění.
Ladění kanálu aktivit Tok dat používá aktivní ladicí cluster, ale inicializace trvá aspoň minutu. Průběh můžete sledovat pomocí karty Výstup . Po úspěšném spuštění otevřete podokno monitorování výběrem ikony brýle.

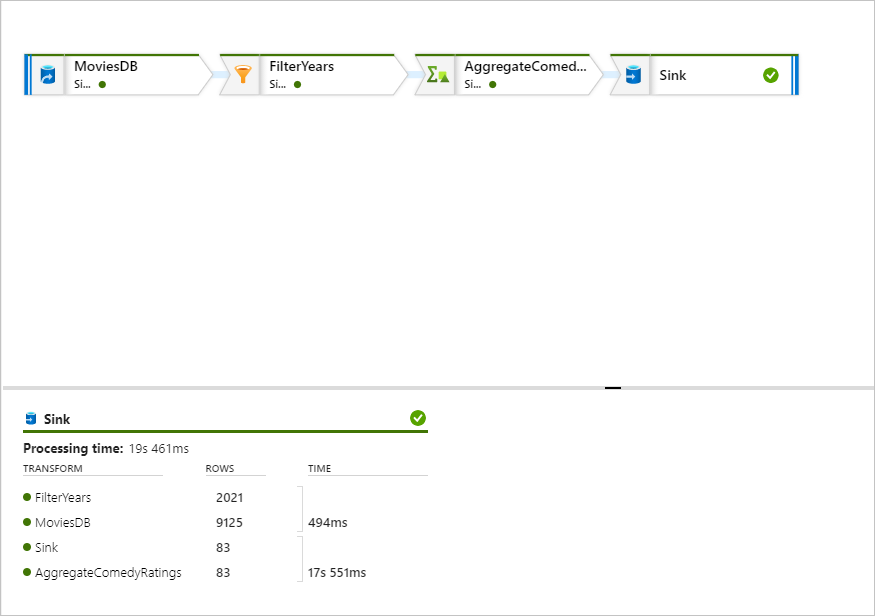
V podokně monitorování můžete zobrazit počet řádků a času strávených v jednotlivých krocích transformace.
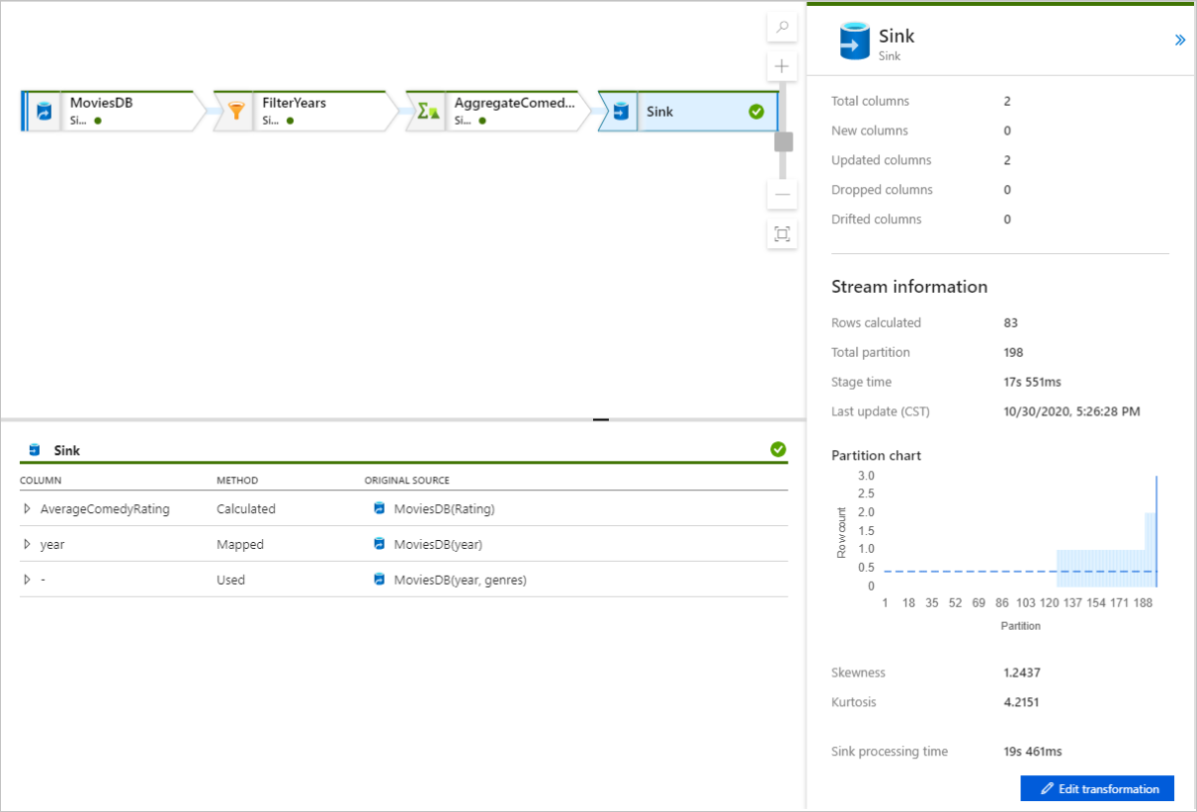
Výběrem transformace získáte podrobné informace o sloupcích a dělení dat.
Pokud jste postupovali podle tohoto rychlého startu správně, měli byste do složky jímky napsat 83 řádků a 2 sloupce. Data můžete ověřit kontrolou úložiště objektů blob.
Další kroky
V následujících článcích se dozvíte o podpoře azure Synapse Analytics: