Kromě migrace Teradata implementujte moderní datový sklad v Microsoft Azure.
Tento článek je třetí částí sedmidílné série, která obsahuje pokyny k migraci z Teradata do Azure Synapse Analytics. Tento článek se zaměřuje na osvědčené postupy pro implementaci moderních datových skladů.
Migrace datového skladu do Azure
Klíčovým důvodem migrace stávajícího datového skladu do Azure Synapse Analytics je využití globálně zabezpečené, škálovatelné, nízkonákladové, cloudové nativní analytické databáze s průběžným platbou. S Azure Synapse můžete integrovat migrovaný datový sklad s kompletním analytickým ekosystémem Microsoft Azure, abyste mohli využívat další technologie Microsoftu a modernizovat migrovaný datový sklad. Mezi tyto technologie patří:
Azure Data Lake Storage pro nákladově efektivní příjem, přípravu, čištění a transformaci dat. Data Lake Storage může uvolnit kapacitu datového skladu obsazenou rychle rostoucími pracovními tabulkami.
Azure Data Factory pro spolupráci s IT a samoobslužnou integrací dat s konektory pro cloudové a místní zdroje dat a streamovaná data.
Common Data Model pro sdílení konzistentních důvěryhodných dat napříč několika technologiemi, včetně:
- Azure Synapse
- Azure Synapse Spark
- Azure HDInsight
- Power BI
- Adobe Customer Experience Platform
- Azure IoT
- Partneři Microsoft ISV
Technologie datových věd Microsoftu, mezi které patří:
- Studio Azure Machine Learning
- Azure Machine Learning
- Azure Synapse Spark (Spark jako služba)
- Poznámkové bloky Jupyter
- RStudio
- ML.NET
- .NET pro Apache Spark, který umožňuje datovým vědcům používat data Azure Synapse k trénování modelů strojového učení ve velkém měřítku.
Azure HDInsight pro zpracování velkých objemů dat a připojení velkých objemů dat k datům Azure Synapse vytvořením logického datového skladu pomocí PolyBase.
Azure Event Hubs, Azure Stream Analytics a Apache Kafka za účelem integrace živých streamovaných dat z Azure Synapse
Růst velkých objemů dat vedl k akutní poptávce po strojovém učení , aby bylo možné v Azure Synapse povolit vlastní vytvořené a natrénované modely strojového učení. Modely strojového učení umožňují, aby se analýzy v databázi spouštěly v dávkovém měřítku, a to na základě událostí a na vyžádání. Možnost využívat analýzy v databázi v Azure Synapse z několika nástrojů a aplikací BI také zaručuje konzistentní předpovědi a doporučení.
Kromě toho můžete azure Synapse integrovat s partnerskými nástroji Microsoftu v Azure, abyste zkrátili dobu na hodnotu.
Pojďme se podrobněji podívat, jak můžete využít výhod technologií v analytickém ekosystému Microsoftu k modernizaci datového skladu po migraci do Azure Synapse.
Přesměrování zpracování dat a zpracování ETL do Data Lake Storage a Data Factory
Digitální transformace vytvořila pro podniky klíčovou výzvu generováním nových dat pro zachytávání a analýzu. Dobrým příkladem jsou transakční data vytvořená otevřením systémů OLTP (Online TransactionAl Processing) pro přístup k službám z mobilních zařízení. Většina těchto dat najde cestu do datových skladů a systémy OLTP jsou hlavním zdrojem. U zákazníků, kteří teď spíše než zaměstnanci řídí rychlost transakcí, se objem dat v pracovních tabulkách datového skladu rychle rozrůstá.
Díky rychlému nárůstu dat do podniku spolu s novými zdroji dat, jako je Internet věcí (IoT), musí společnosti najít způsoby, jak vertikálně navýšit kapacitu zpracování ETL integrace dat. Jednou z metod je snižování zátěže příjmu dat, čištění dat, transformace a integrace do datového jezera a zpracování dat ve velkém měřítku v rámci programu modernizace datového skladu.
Po migraci datového skladu do Azure Synapse může Microsoft modernizovat zpracování ETL ingestováním a přípravou dat ve službě Data Lake Storage. Před paralelním načtením do Azure Synapse pomocí PolyBase pak můžete data ve velkém měřítku vyčistit, transformovat a integrovat.
U strategií ELT zvažte snížení zátěže zpracování ELT do Data Lake Storage, abyste mohli snadno škálovat s rostoucím objemem dat nebo frekvencí.
Microsoft Azure Data Factory
Azure Data Factory je služba pro integraci hybridních dat s průběžnou platbou za použití pro vysoce škálovatelné zpracování ETL a ELT. Data Factory poskytuje webové uživatelské rozhraní pro vytváření kanálů integrace dat bez kódu. Pomocí služby Data Factory můžete:
Vytvářejte škálovatelné kanály integrace dat bez kódu.
Snadno získávat data ve velkém měřítku.
Zaplatíte jenom to, co používáte.
Připojte se k místním, cloudovým a saaS datovým zdrojům.
Ingestování, přesouvání, čištění, transformace, integrace a analýza cloudových a místních dat ve velkém měřítku.
Bezproblémově vytvářejte, monitorujte a spravujte kanály, které zahrnují úložiště dat místně i v cloudu.
V souladu s růstem zákazníků povolte horizontální navýšení kapacity s průběžnými platbami.
Tyto funkce můžete použít bez psaní kódu nebo můžete do kanálů data Factory přidat vlastní kód. Následující snímek obrazovky ukazuje příklad kanálu služby Data Factory.

Tip
Data Factory umožňuje vytvářet škálovatelné kanály integrace dat bez kódu.
Implementace vývoje kanálu služby Data Factory z libovolného z několika míst, včetně následujících:
Portál Microsoft Azure.
Microsoft Azure PowerShell.
Programově z .NET a Pythonu pomocí sady SDK s více jazyky.
Šablony Azure Resource Manageru (ARM).
ROZHRANÍ REST API.
Tip
Data Factory se může připojit k místním datům, cloudům a datům SaaS.
Vývojáři a datoví vědci, kteří dávají přednost psaní kódu, mohou snadno vytvářet kanály služby Data Factory v Javě, Pythonu a .NET pomocí sad SDK (Software Development Kit) dostupných pro tyto programovací jazyky. Kanály služby Data Factory můžou být hybridní datové kanály, protože se můžou připojit, ingestovat, ingestovat, vyčistit, transformovat a analyzovat data v místních datových centrech, Microsoft Azure, dalších cloudech a nabídkách SaaS.
Po vývoji kanálů služby Data Factory pro integraci a analýzu dat můžete tyto kanály nasadit globálně a naplánovat jejich spuštění v dávce, vyvolat je na vyžádání jako službu nebo je spustit v reálném čase na základě událostí. Kanál služby Data Factory může běžet také na jednom nebo více spouštěcích modulech a monitorovat spouštění, aby se zajistil výkon a sledoval chyby.
Tip
Kanály v Azure Data Factory řídí integraci a analýzu dat. Data Factory je software pro integraci dat na podnikové úrovni zaměřený na IT profesionály a má možnosti transformace dat pro podnikové uživatele.
Případy použití
Data Factory podporuje více případů použití, například:
Připravte, integrujte a obohatit data z cloudových a místních zdrojů dat a naplňte migrovaný datový sklad a datová tržiště v Microsoft Azure Synapse.
Příprava, integrace a rozšiřování dat z cloudových a místních zdrojů dat za účelem vytvoření trénovacích dat pro použití ve vývoji modelů strojového učení a při opětovném trénování analytických modelů.
Orchestrace přípravy a analýzy dat za účelem vytvoření prediktivních a preskriptivních analytických kanálů pro zpracování a analýzu dat v dávce, jako je analýza mínění. Buď zareagujte na výsledky analýzy, nebo naplňte datový sklad výsledky.
Příprava, integrace a rozšiřování dat pro obchodní aplikace řízené daty běžící v cloudu Azure nad provozními úložišti dat, jako je Azure Cosmos DB.
Tip
Vytváření trénovacích datových sad v oblasti datových věd pro vývoj modelů strojového učení
Zdroje dat
Data Factory umožňuje používat konektory z cloudových i místních zdrojů dat. Software agenta, označovaný jako místní prostředí Integration Runtime, bezpečně přistupuje k místním zdrojům dat a podporuje zabezpečený a škálovatelný přenos dat.
Transformace dat pomocí Azure Data Factory
V rámci kanálu Data Factory můžete ingestovat, ingestovat, vyčistit, transformovat, integrovat a analyzovat libovolný typ dat z těchto zdrojů. Data můžou být strukturovaná, částečně strukturovaná jako JSON nebo Avro nebo nestrukturovaná.
Bez psaní kódu můžou profesionální vývojáři ETL používat toky dat mapování služby Data Factory k filtrování, rozdělení, spojení několika typů, vyhledávání, pivot, unpivot, řazení, sjednocení a agregace dat. Kromě toho služba Data Factory podporuje náhradní klíče, několik možností zpracování zápisu, jako jsou vložení, upsert, aktualizace, úprava tabulky a zkrácení tabulky a několik typů cílových úložišť dat, označovaných také jako jímky. Vývojáři ETL můžou také vytvářet agregace, včetně agregací časových řad, které vyžadují umístění okna do datových sloupců.
Tip
Profesionální vývojáři ETL můžou pomocí mapování toků dat služby Data Factory vyčistit, transformovat a integrovat data bez nutnosti psát kód.
Můžete spustit mapování toků dat, které transformují data jako aktivity v kanálu služby Data Factory, a v případě potřeby můžete do jednoho kanálu zahrnout více toků dat mapování. Tímto způsobem můžete spravovat složitost rozdělením náročných úloh transformace dat a integrace do menších mapování toků dat, které je možné kombinovat. A v případě potřeby můžete přidat vlastní kód. Kromě této funkce zahrnují mapování toků dat služby Data Factory i tyto možnosti:
Definujte výrazy pro vyčištění a transformaci dat, agregací výpočtů a obohacení dat. Tyto výrazy můžou například provádět přípravu funkcí v poli kalendářního data, aby je rozdělily do více polí a vytvořily trénovací data během vývoje modelu strojového učení. Výrazy můžete vytvářet z bohaté sady funkcí, které zahrnují matematické, dočasné, rozdělené, slučovací, zřetězení řetězců, podmínky, shodu vzorů, nahrazení a mnoho dalších funkcí.
Automatické zpracování odchylek schématu, aby se kanály transformace dat mohly vyhnout změnám schématu ve zdrojích dat. Tato schopnost je obzvláště důležitá pro streamování dat IoT, kdy se změny schématu můžou vyskytnout bez předchozího upozornění, pokud se zařízení upgradují nebo když se při čtení zmeškají zařízeními brány, která shromažďují data IoT.
Rozdělte data tak, aby se transformace spouštěly paralelně ve velkém měřítku.
Zkontrolujte streamovaná data a prohlédněte si metadata datového proudu, který transformujete.
Tip
Data Factory podporuje schopnost automaticky zjišťovat a spravovat změny schématu v příchozích datech, jako jsou streamovaná data.
Následující snímek obrazovky ukazuje příklad toku dat mapování služby Data Factory.

Datoví inženýři mohou profilovat kvalitu dat a zobrazit výsledky jednotlivých transformací dat povolením funkce ladění během vývoje.
Tip
Data Factory může také rozdělit data do oddílů, aby bylo možné zpracování ETL spouštět ve velkém měřítku.
V případě potřeby můžete rozšířit transformační a analytické funkce služby Data Factory přidáním propojené služby, která obsahuje váš kód do kanálu. Poznámkový blok fondu Azure Synapse Spark může například obsahovat kód Pythonu, který používá natrénovaný model k určení skóre dat integrovaných mapováním toku dat.
Integrovaná data a všechny výsledky z analýz v kanálu Data Factory můžete ukládat v jednom nebo několika úložištích dat, jako jsou Data Lake Storage, Azure Synapse nebo Tabulky Hive ve službě HDInsight. Můžete také vyvolat další aktivity, které budou fungovat s přehledy vytvořenými analytickým kanálem služby Data Factory.
Tip
Kanály služby Data Factory jsou rozšiřitelné, protože Služba Data Factory umožňuje napsat vlastní kód a spustit ho jako součást kanálu.
Použití Sparku ke škálování integrace dat
Služba Data Factory v době běhu interně používá fondy Azure Synapse Spark, což jsou nabídky Sparku od Microsoftu jako služby, k vyčištění a integraci dat v cloudu Azure. Ve velkém měřítku můžete vyčistit, integrovat a analyzovat data s vysokým objemem, vysokorychlostními daty, jako jsou data typu klikni a stream. Záměrem Microsoftu je také spouštět kanály Data Factory v jiných distribucích Sparku. Kromě spouštění úloh ETL ve Sparku může Data Factory vyvolat skripty Pig a dotazy Hive pro přístup k datům uloženým v HDInsight a jejich transformaci.
Propojení samoobslužné přípravy dat a zpracování ETL služby Data Factory pomocí transformace toků dat
Transformace dat umožňuje podnikovým uživatelům, označované také jako integrátoři dat občanů a datoví inženýři, používat platformu k vizuálnímu zjišťování, zkoumání a přípravě dat ve velkém měřítku bez psaní kódu. Tato funkce služby Data Factory se snadno používá a podobá se microsoft Excelu Power Query nebo tokům dat Microsoft Power BI, kde samoobslužní podnikoví uživatelé používají uživatelské rozhraní ve stylu tabulky s rozevíracími transformacemi k přípravě a integraci dat. Následující snímek obrazovky ukazuje příklad transformace toku dat služby Data Factory.

Na rozdíl od Excelu a Power BI používají toky transformace dat Data Factory Power Query k vygenerování kódu M a jejich následnému překladu do úlohy Sparku v paměti pro provádění v cloudovém měřítku. Kombinace mapování toků dat a transformace toků dat ve službě Data Factory umožňuje profesionálním vývojářům etL a podnikovým uživatelům spolupracovat na přípravě, integraci a analýze dat pro běžný obchodní účel. Předchozí diagram toků dat mapování služby Data Factory ukazuje, jak je možné poznámkové bloky fondu Data Factory i Azure Synapse Spark kombinovat ve stejném kanálu služby Data Factory. Kombinace mapování a transformace toků dat ve službě Data Factory pomáhá IT a firemním uživatelům udržet si přehled o tom, jaké toky dat se vytvořily, a podporuje opakované použití toku dat, aby se minimalizovala opětovná inventence a maximalizovala produktivita a konzistence.
Tip
Data Factory podporuje transformace toků dat i mapování toků dat, aby podnikoví uživatelé a it uživatelé mohli integrovat data společně na společné platformě.
Propojení dat a analýz v analytických kanálech
Kromě čištění a transformace dat může Služba Data Factory kombinovat integraci a analýzu dat ve stejném kanálu. Data Factory můžete použít k vytvoření kanálů integrace dat i analytického kanálu, přičemž druhá je rozšířením bývalé služby. Analytický model můžete vložit do kanálu a vytvořit analytický kanál, který generuje čistá, integrovaná data pro předpovědi nebo doporučení. Potom můžete okamžitě reagovat na predikce nebo doporučení nebo je uložit do datového skladu a poskytnout tak nové přehledy a doporučení, která se dají zobrazit v nástrojích BI.
K dávkovému hodnocení dat můžete vyvíjet analytický model, který vyvoláte jako službu v rámci kanálu Data Factory. Analytické modely můžete vyvíjet bez kódu pomocí studio Azure Machine Learning nebo pomocí sady Azure Machine Learning SDK pomocí poznámkových bloků fondu Azure Synapse Spark nebo R v RStudio. Když spustíte kanály strojového učení Sparku v poznámkových blocích fondu Azure Synapse Spark, provede se analýza ve velkém měřítku.
Integrovaná data a jakýkoli analytický kanál Data Factory můžete ukládat do jednoho nebo více úložišť dat, jako jsou Data Lake Storage, Azure Synapse nebo tabulky Hive ve službě HDInsight. Můžete také vyvolat další aktivity, které budou fungovat s přehledy vytvořenými analytickým kanálem služby Data Factory.
Použití databáze Lake ke sdílení konzistentních důvěryhodných dat
Klíčovým cílem jakéhokoli nastavení integrace dat je schopnost integrovat data jednou a opakovaně je používat všude, nejen v datovém skladu. Můžete například chtít použít integrovaná data v oblasti datových věd. Opakované použití zabraňuje opětovnému vynalézení a zajišťuje konzistentní, běžně pochopená data, kterým může každý důvěřovat.
Common Data Model popisuje základní datové entity, které je možné sdílet a opakovaně používat v rámci podniku. Pro opakované použití vytvoří Common Data Model sadu běžných názvů dat a definic, které popisují logické datové entity. Mezi příklady běžných názvů dat patří Zákazník, Účet, Produkt, Dodavatel, Objednávky, Platby a Vrácení. IT a obchodní specialisté můžou pomocí softwaru pro integraci dat vytvářet a ukládat běžné datové prostředky, aby maximalizovali jejich opakované použití a řídili konzistenci všude.
Azure Synapse poskytuje oborové šablony databáze, které pomáhají standardizovat data v jezeře. Šablony databáze Lake poskytují schémata pro předdefinované obchodní oblasti, což umožňuje načtení dat do databáze lake strukturovaným způsobem. Výkon přichází při použití softwaru pro integraci dat k vytvoření běžných datových prostředků databáze Lake, což vede k vlastnímu popisu důvěryhodných dat, která můžou využívat aplikace a analytické systémy. Běžné datové prostředky můžete ve službě Data Lake Storage vytvořit pomocí služby Data Factory.
Tip
Data Lake Storage je sdílené úložiště, které podporuje Microsoft Azure Synapse, Azure Machine Learning, Azure Synapse Spark a HDInsight.
Power BI, Azure Synapse Spark, Azure Synapse a Azure Machine Learning můžou využívat běžné datové prostředky. Následující diagram znázorňuje použití databáze lake v Azure Synapse.
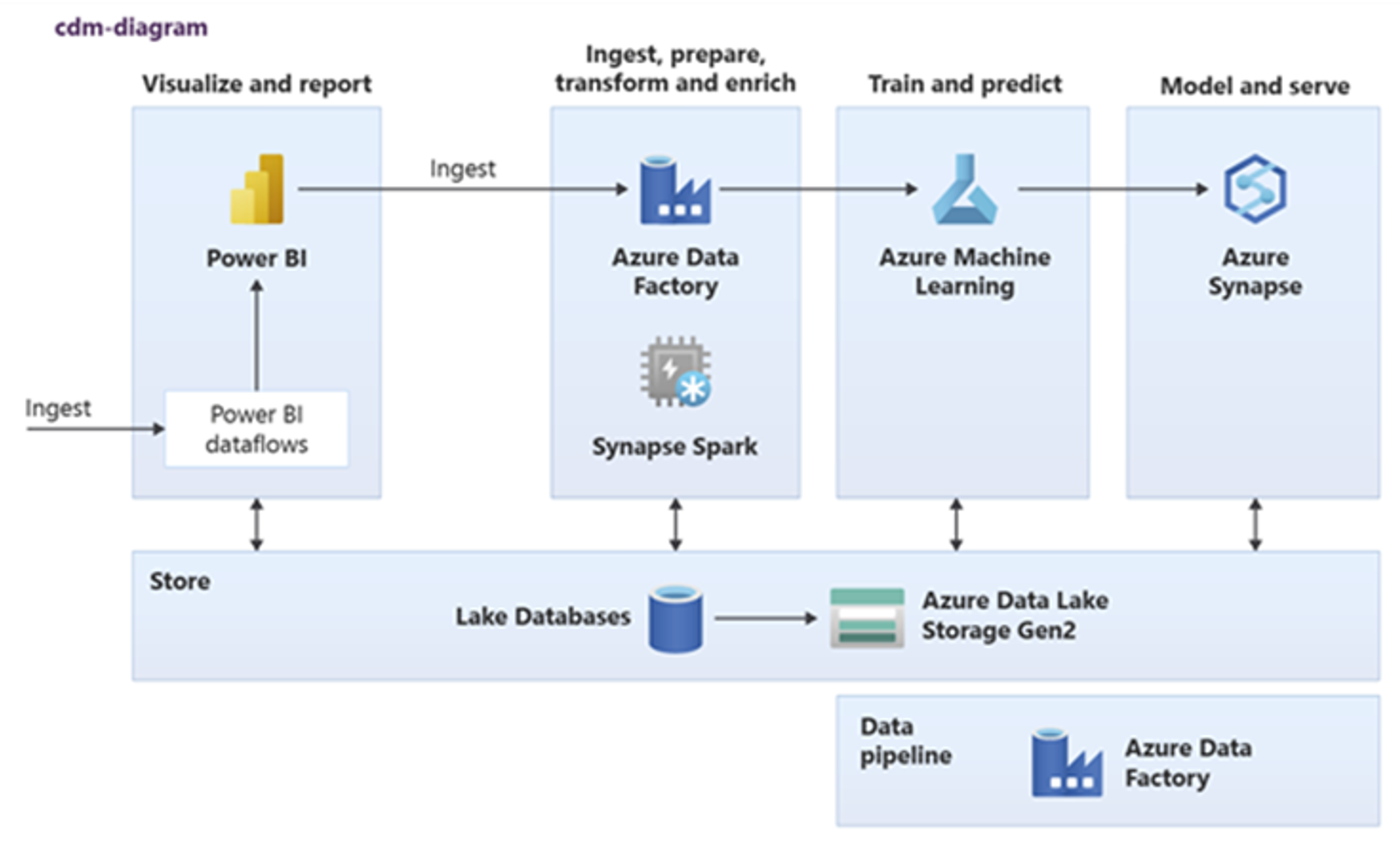
Tip
Integrujte data za účelem vytvoření logických entit databáze Lake ve sdíleném úložišti, abyste maximalizovali opakované použití běžných datových prostředků.
Integrace s technologiemi datových věd Microsoftu v Azure
Dalším klíčovým cílem při modernizaci datového skladu je vytvořit přehled o konkurenční výhodě. Můžete vytvářet přehledy integrací migrovaného datového skladu s technologiemi Microsoftu a datových věd třetích stran v Azure. Následující části popisují technologie strojového učení a datových věd nabízených Microsoftem, abyste zjistili, jak je lze používat s Azure Synapse v moderním prostředí datového skladu.
Technologie Microsoftu pro datové vědy v Azure
Microsoft nabízí řadu technologií, které podporují pokročilou analýzu. Pomocí těchto technologií můžete vytvářet prediktivní analytické modely pomocí strojového učení nebo analyzovat nestrukturovaná data pomocí hloubkového učení. Mezi tyto technologie patří:
Studio Azure Machine Learning
Azure Machine Learning
Poznámkové bloky fondu Azure Synapse Spark
ML.NET (ROZHRANÍ API, rozhraní příkazového řádku nebo tvůrce modelů ML.NET pro Visual Studio)
.NET pro Apache Spark
Datoví vědci můžou k vývoji analytických modelů použít RStudio (R) a Jupyter Notebook (Python), nebo můžou používat architektury, jako je Keras nebo TensorFlow.
Tip
Vyvíjejte modely strojového učení pomocí přístupu bez/nízkého kódu nebo pomocí programovacích jazyků, jako jsou Python, R a .NET.
Studio Azure Machine Learning
studio Azure Machine Learning je plně spravovaná cloudová služba, která umožňuje vytvářet, nasazovat a sdílet prediktivní analýzy pomocí webového uživatelského rozhraní založeného na přetahování myší. Následující snímek obrazovky ukazuje uživatelské rozhraní studio Azure Machine Learning.

Azure Machine Learning
Azure Machine Learning poskytuje sadu SDK a služby pro Python, které podporují, vám můžou pomoct rychle připravit data a také trénovat a nasazovat modely strojového učení. Azure Machine Learning můžete použít v poznámkových blocích Azure pomocí Jupyter Notebooku s opensourcovými architekturami, jako jsou PyTorch, TensorFlow, scikit-learn nebo Spark MLlib – knihovna strojového učení pro Spark.
Tip
Azure Machine Learning poskytuje sadu SDK pro vývoj modelů strojového učení pomocí několika opensourcových architektur.
Pomocí služby Azure Machine Learning můžete také vytvářet kanály strojového učení, které spravují kompletní pracovní postup, programově škálují v cloudu a nasazují modely do cloudu i do hraničních zařízení. Azure Machine Learning obsahuje pracovní prostory, což jsou logické prostory, které můžete programově nebo ručně vytvořit na webu Azure Portal. Tyto pracovní prostory uchovávají výpočetní cíle, experimenty, úložiště dat, vytrénované modely strojového učení, image Dockeru a nasazené služby na jednom místě, aby týmy mohly spolupracovat. Azure Machine Learning můžete použít v sadě Visual Studio s rozšířením Visual Studio pro AI.
Tip
Uspořádejte a spravujte související úložiště dat, experimenty, natrénované modely, image Dockeru a nasazené služby v pracovních prostorech.
Poznámkové bloky fondu Azure Synapse Spark
Poznámkový blok fondu Azure Synapse Spark je služba Apache Spark optimalizovaná pro Azure. Poznámkové bloky fondu Azure Synapse Spark:
Datoví inženýři můžou vytvářet a spouštět škálovatelné úlohy přípravy dat pomocí služby Data Factory.
Datoví vědci můžou vytvářet a spouštět modely strojového učení ve velkém měřítku pomocí poznámkových bloků napsaných v jazycích, jako jsou Scala, R, Python, Java a SQL, a vizualizovat výsledky.
Tip
Azure Synapse Spark je dynamicky škálovatelná nabídka Sparku jako služby od Microsoftu, Spark nabízí škálovatelné spouštění přípravy dat, vývoje modelů a nasazování modelů.
Úlohy spuštěné v poznámkových blocích fondu Azure Synapse Spark můžou načítat, zpracovávat a analyzovat data ve velkém měřítku ze služby Azure Blob Storage, Data Lake Storage, Azure Synapse, HDInsight a streamovaných datových služeb, jako je Apache Kafka.
Tip
Azure Synapse Spark má přístup k datům v celé řadě úložišť dat analytického ekosystému Microsoftu v Azure.
Poznámkové bloky fondu Azure Synapse Spark podporují automatické škálování a automatické ukončení, aby se snížily celkové náklady na vlastnictví(TCO). Datoví vědci můžou ke správě životního cyklu strojového učení použít opensourcovou architekturu MLflow.
ML.NET
ML.NET je opensourcová multiplatformní architektura strojového učení pro Windows, Linux a macOS. Společnost Microsoft vytvořila ML.NET, aby vývojáři .NET mohli používat existující nástroje, jako je ML.NET Model Builder pro Visual Studio, k vývoji vlastních modelů strojového učení a jejich integraci do svých aplikací .NET.
Tip
Microsoft rozšířil své možnosti strojového učení vývojářům .NET.
.NET pro Apache Spark
.NET pro Apache Spark rozšiřuje podporu Sparku nad rámec R, Scala, Pythonu a Javy na .NET a má za cíl zpřístupnit Spark vývojářům .NET napříč všemi rozhraními API Sparku. I když je .NET pro Apache Spark v současné době k dispozici pouze v Apache Sparku v HDInsight, Microsoft hodlá zpřístupnit .NET pro Apache Spark v poznámkových blocích fondu Azure Synapse Spark.
Použití Služby Azure Synapse Analytics s datovým skladem
Pokud chcete kombinovat modely strojového učení s Azure Synapse, můžete:
Pomocí modelů strojového učení v dávkovém nebo reálném čase streamovaných dat můžete vytvářet nové přehledy a přidávat tyto přehledy k tomu, co už znáte ve službě Azure Synapse.
Data v Azure Synapse můžete použít k vývoji a trénování nových prediktivních modelů pro nasazení jinde, například v jiných aplikacích.
Nasaďte modely strojového učení, včetně modelů natrénovaných jinde, ve službě Azure Synapse za účelem analýzy dat ve vašem datovém skladu a zajištění nové obchodní hodnoty.
Tip
Trénování, testování, vyhodnocování a spouštění modelů strojového učení ve velkém měřítku v poznámkových blocích fondu Azure Synapse Spark pomocí dat v Azure Synapse
Datoví vědci můžou používat poznámkové bloky fondu RStudio, Jupyter Notebook a fond Azure Synapse Spark společně se službou Azure Machine Learning k vývoji modelů strojového učení, které běží ve velkém měřítku v poznámkových blocích fondu Azure Synapse Spark s využitím dat v Azure Synapse. Datoví vědci můžou například vytvořit model bez dohledu, který segmentuje zákazníky, aby mohli řídit různé marketingové kampaně. Pomocí strojového učení pod dohledem můžete vytrénovat model tak, aby předpověděl konkrétní výsledek, například k predikci náchylnosti zákazníka k četnosti změn, nebo k doporučení další nejlepší nabídky pro zákazníka, aby se pokusil zvýšit jeho hodnotu. Následující diagram ukazuje, jak se dá Azure Synapse použít pro Azure Machine Learning.
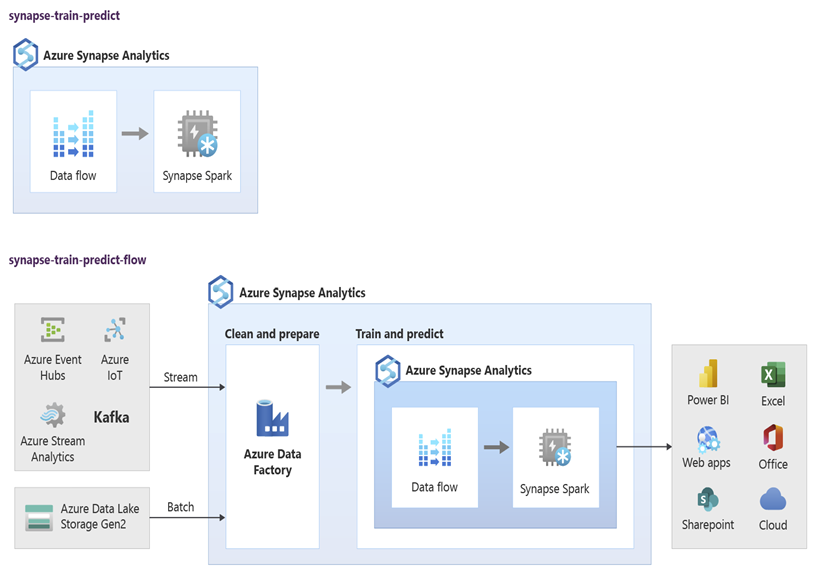
V jiném scénáři můžete ingestovat sociální síť nebo zkontrolovat data webu do Data Lake Storage a pak připravit a analyzovat data ve velkém měřítku v poznámkovém bloku fondu Azure Synapse Spark pomocí zpracování přirozeného jazyka za účelem určení mínění zákazníků o vašich produktech nebo značce. Tyto skóre pak můžete přidat do datového skladu. Když použijete analýzu velkých objemů dat k pochopení vlivu negativního mínění na prodej produktů, přidáte do toho, co už znáte ve svém datovém skladu.
Tip
Vytvářejte nové přehledy pomocí strojového učení v Azure v dávce nebo v reálném čase a přidejte do toho, co znáte ve svém datovém skladu.
Integrace živých streamovaných dat do Azure Synapse Analytics
Při analýze dat v moderním datovém skladu musíte být schopni analyzovat streamovaná data v reálném čase a spojit je s historickými daty v datovém skladu. Příkladem je kombinování dat IoT s daty o produktech nebo prostředcích.
Tip
Integrujte datový sklad se streamovanými daty ze zařízení IoT nebo clickstreamy.
Jakmile úspěšně migrujete datový sklad do Azure Synapse, můžete v rámci modernizace datového skladu zavést integraci dat živého streamování, a to díky využití dalších funkcí v Azure Synapse. Pokud to chcete udělat, ingestujte streamovaná data prostřednictvím služby Event Hubs, dalších technologií, jako je Apache Kafka, nebo případně existující nástroj ETL, pokud podporuje streamované zdroje dat. Uložte data ve službě Data Lake Storage. Pak vytvořte v Azure Synapse externí tabulku pomocí PolyBase a nasměrujte ji na data streamovaná do Data Lake Storage, aby váš datový sklad teď obsahovaly nové tabulky, které poskytují přístup k streamovaným datům v reálném čase. Dotazujte externí tabulku, jako kdyby byla data v datovém skladu pomocí standardního T-SQL z libovolného nástroje BI, který má přístup k Azure Synapse. Streamovaná data můžete také připojit k dalším tabulkám s historickými daty a vytvořit zobrazení, která spojují živá streamovaná data s historickými daty, aby firemní uživatelé měli k datům přístup snadněji.
Tip
Ingestování streamovaných dat do Data Lake Storage ze služby Event Hubs nebo Apache Kafka a přístup k datům z Azure Synapse pomocí externích tabulek PolyBase.
V následujícím diagramu je datový sklad v reálném čase v Azure Synapse integrovaný se streamovanými daty ve službě Data Lake Storage.
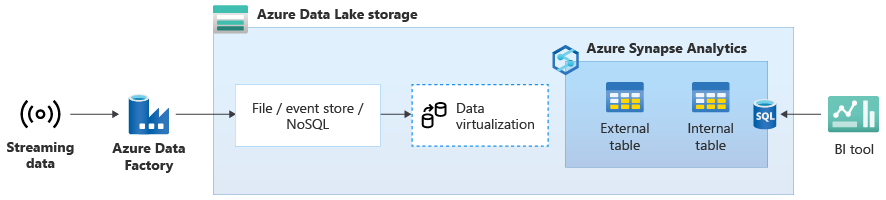
Vytvoření logického datového skladu pomocí PolyBase
Pomocí PolyBase můžete vytvořit logický datový sklad, který zjednodušuje přístup uživatelů k více analytickým úložištům dat. Řada společností přijala kromě datových skladů i úložiště analytických dat optimalizovaných pro úlohy za posledních několik let. Analytické platformy v Azure zahrnují:
Data Lake Storage s poznámkovým blokem fondu Azure Synapse Spark (Spark jako služba) pro analýzy velkých objemů dat
HDInsight (Hadoop jako služba) také pro analýzy velkých objemů dat.
Grafové databáze NoSQL pro analýzu grafů, které je možné provést ve službě Azure Cosmos DB.
Event Hubs a Stream Analytics pro analýzu dat v reálném čase.
Můžete mít ekvivalenty jiných platforem než Microsoft nebo hlavní systém správy dat (MDM), ke kterému je potřeba přistupovat kvůli konzistentním důvěryhodným datům na zákaznících, dodavatelích, produktech, prostředcích a dalších.
Tip
PolyBase zjednodušuje přístup k několika podkladovým úložištím analytických dat v Azure pro usnadnění přístupu podnikových uživatelů.
Tyto analytické platformy vznikly kvůli explozi nových zdrojů dat uvnitř podniku i mimo firmu a poptávce podnikových uživatelů zachytávat a analyzovat nová data. Mezi nové zdroje dat patří:
Strojově generovaná data, jako jsou data snímačů IoT a data clickstream.
Data generovaná lidmi, jako jsou data sociálních sítí, kontrola dat webu, příchozí e-mail zákazníka, obrázky a video.
Další externí data, jako jsou otevřená data státní správy a data o počasí.
Tato nová data překračují strukturovaná data transakcí a hlavní zdroje dat, které obvykle živí datové sklady a často zahrnují:
- Částečně strukturovaná data, jako jsou JSON, XML nebo Avro.
- Nestrukturovaná data, jako je text, hlas, obrázek nebo video, je složitější zpracovat a analyzovat.
- Vysoká objemová data, vysokorychlostní data nebo obojí.
V důsledku toho vznikly nové složitější typy analýz, jako je zpracování přirozeného jazyka, analýza grafů, hluboké učení, analýza streamování nebo složitá analýza velkých objemů strukturovaných dat. Tyto druhy analýz se obvykle nedějí v datovém skladu, takže není divu, že uvidíte různé analytické platformy pro různé typy analytických úloh, jak je znázorněno v následujícím diagramu.
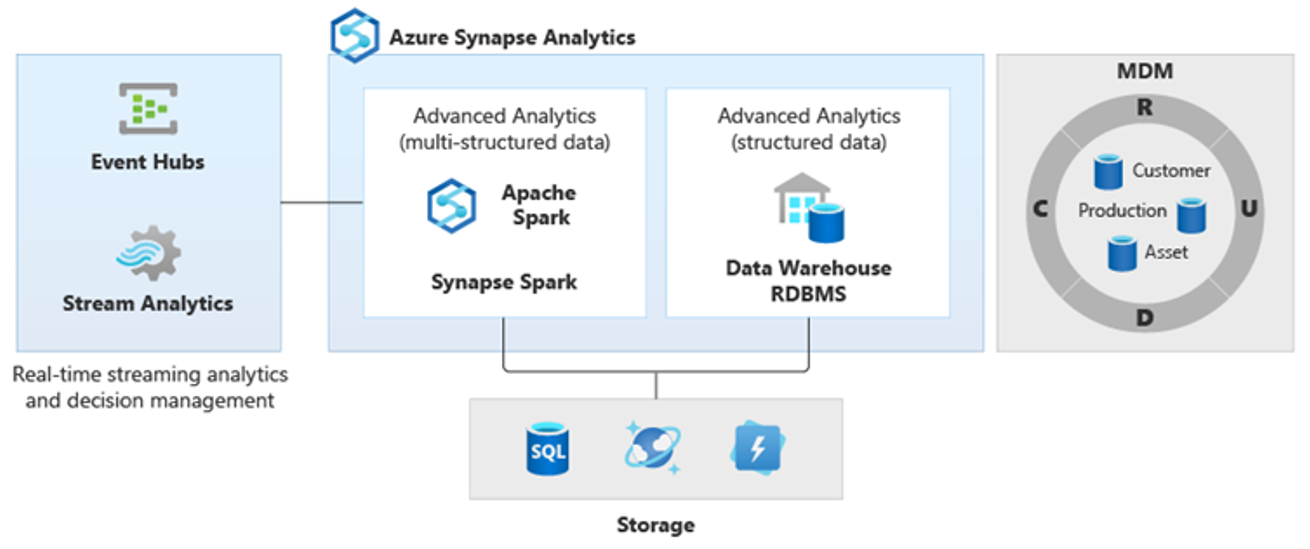
Tip
Schopnost vytvářet data v několika analytických úložištích dat vypadá, jako by byla všechna v jednom systému a připojila se k Azure Synapse, se označuje jako architektura logického datového skladu.
Vzhledem k tomu, že tyto platformy vytvářejí nové přehledy, je běžné vidět požadavek na kombinování nových přehledů s tím, co už víte v Azure Synapse, což je to, co PolyBase umožňuje.
Pomocí virtualizace dat PolyBase ve službě Azure Synapse můžete implementovat logický datový sklad, ve kterém jsou data ve službě Azure Synapse připojená k datům v jiných úložištích analytických dat v Azure a místních analytických úložištích, jako je HDInsight, Azure Cosmos DB nebo streamovaná data streamovaná do služby Data Lake Storage z Stream Analytics nebo Event Hubs. Tento přístup snižuje složitost uživatelů, kteří přistupují k externím tabulkám v Azure Synapse a nepotřebují vědět, že data, ke kterým přistupují, jsou uložená v několika základních analytických systémech. Následující diagram znázorňuje složitou strukturu datového skladu, ke které se přistupuje prostřednictvím poměrně jednodušších, ale stále výkonných metod uživatelského rozhraní.
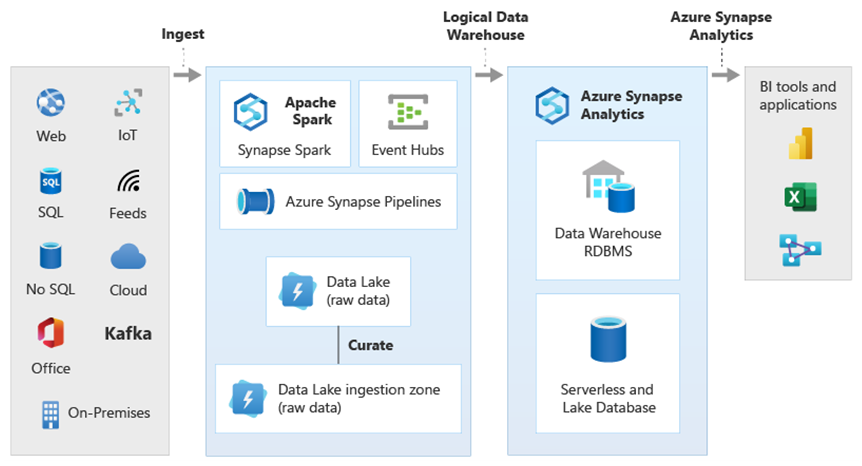
Diagram znázorňuje, jak lze v analytickém ekosystému Microsoftu kombinovat další technologie s schopností architektury logického datového skladu v Azure Synapse. Můžete například ingestovat data do Data Lake Storage a spravovat data pomocí Služby pro vytváření důvěryhodných datových produktů, které představují entity logických dat databáze Microsoft Lake. Tato důvěryhodná, běžně srozumitelná data se pak dají využívat a opakovaně používat v různých analytických prostředích, jako jsou azure Synapse, poznámkové bloky fondu Azure Synapse Spark nebo Azure Cosmos DB. Všechny přehledy vytvořené v těchto prostředích jsou přístupné prostřednictvím vrstvy virtualizace dat logického datového skladu, kterou umožňuje PolyBase.
Tip
Architektura logického datového skladu zjednodušuje přístup podnikových uživatelů k datům a přidává novou hodnotu k tomu, co už znáte ve svém datovém skladu.
Závěry
Po migraci datového skladu do Azure Synapse můžete využít další technologie v analytickém ekosystému Microsoftu. Tímto způsobem nejen modernizujete datový sklad, ale přinášíte přehledy vytvořené v jiných analytických úložištích dat Azure do integrované analytické architektury.
Můžete rozšířit zpracování ETL na příjem dat libovolného typu do Data Lake Storage a pak připravit a integrovat data ve velkém měřítku pomocí služby Data Factory k vytvoření důvěryhodných, běžně srozumitelných datových prostředků. Tyto prostředky můžou využívat váš datový sklad a přistupovat k němu datoví vědci a další aplikace. Můžete vytvářet analytické kanály v reálném čase a dávkové analytické kanály a vytvářet modely strojového učení, které se budou spouštět v dávce, v reálném čase na streamovaných datech a na vyžádání jako služba.
PolyBase můžete použít nebo COPY INTO můžete přejít mimo datový sklad a zjednodušit tak přístup k přehledům z několika podkladových analytických platforem v Azure. Pokud to chcete udělat, vytvořte ucelená integrovaná zobrazení v logickém datovém skladu, která podporují přístup ke streamování, velkým objemům dat a tradičním přehledům datového skladu z nástrojů a aplikací BI.
Migrací datového skladu do Azure Synapse můžete využít bohatý analytický ekosystém Microsoftu běžícího v Azure k zajištění nové hodnoty ve vaší firmě.
Další kroky
Další informace o migraci do vyhrazeného fondu SQL najdete v tématu Migrace datového skladu do vyhrazeného fondu SQL ve službě Azure Synapse Analytics.