Kurz: Trénování modelu strojového učení bez kódu (zastaralé)
Data v tabulkách Sparku můžete rozšířit o nové modely strojového učení, které natrénujete pomocí automatizovaného strojového učení. Ve službě Azure Synapse Analytics můžete v pracovním prostoru vybrat tabulku Sparku, která se použije jako trénovací datová sada pro vytváření modelů strojového učení, a to v prostředí bez kódu.
V tomto kurzu se naučíte trénovat modely strojového učení pomocí prostředí bez kódu v nástroji Synapse Studio. Synapse Studio je funkce Azure Synapse Analytics.
Automatizované strojové učení použijete ve službě Azure Machine Learning místo ručního kódování prostředí. Typ modelu, který natrénujete, závisí na problému, který se pokoušíte vyřešit. V tomto kurzu použijete regresní model k predikci jízdného taxíku z datové sady taxislužby v New Yorku.
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Upozorňující
- Od 29. září 2023 ukončí Azure Synapse oficiální podporu pro moduly Runtime Sparku 2.4. Po 29. září 2023 nebudeme řešit žádné lístky podpory související se Sparkem 2.4. Pro chyby nebo opravy zabezpečení pro Spark 2.4 nebude zaveden žádný kanál verze. Využití Sparku 2.4 po datu ukončení podpory se provádí na vlastním riziku. Důrazně nedoporučujeme jeho trvalé používání kvůli potenciálním obavám o zabezpečení a funkčnost.
- V rámci procesu vyřazení Apache Sparku 2.4 bychom vás chtěli upozornit, že AutoML ve službě Azure Synapse Analytics bude také zastaralé. To zahrnuje rozhraní s nízkým kódem i rozhraní API používaná k vytváření zkušebních verzí AutoML prostřednictvím kódu.
- Mějte na paměti, že funkce AutoML byla výhradně dostupná prostřednictvím modulu runtime Spark 2.4.
- Zákazníkům, kteří chtějí dál využívat funkce AutoML, doporučujeme ukládat data do účtu Azure Data Lake Storage Gen2 (ADLSg2). Odtud můžete bez problémů přistupovat k prostředí AutoML prostřednictvím služby Azure Machine Learning (AzureML). Další informace týkající se tohoto alternativního řešení najdete tady.
Požadavky
- Pracovní prostor Azure Synapse Analytics Ujistěte se, že má účet úložiště Azure Data Lake Storage Gen2 nakonfigurovaný jako výchozí úložiště. V systému souborů Data Lake Storage Gen2, se kterým pracujete, se ujistěte, že jste přispěvatelem dat objektů blob služby Storage.
- Fond Apache Sparku (verze 2.4) ve vašem pracovním prostoru Azure Synapse Analytics Podrobnosti najdete v tématu Rychlý start: Vytvoření bezserverového fondu Apache Spark pomocí nástroje Synapse Studio.
- Propojená služba Azure Machine Learning v pracovním prostoru Azure Synapse Analytics Podrobnosti najdete v tématu Rychlý start: Vytvoření nové propojené služby Azure Machine Learning ve službě Azure Synapse Analytics.
Přihlaste se k portálu Azure Portal.
Přihlaste se k portálu Azure.
Vytvoření tabulky Sparku pro trénovací datovou sadu
Pro účely tohoto kurzu potřebujete tabulku Sparku. Následující poznámkový blok vytvoří:
Stáhněte si poznámkový blok Create-Spark-Table-NYCTaxi- Data.ipynb.
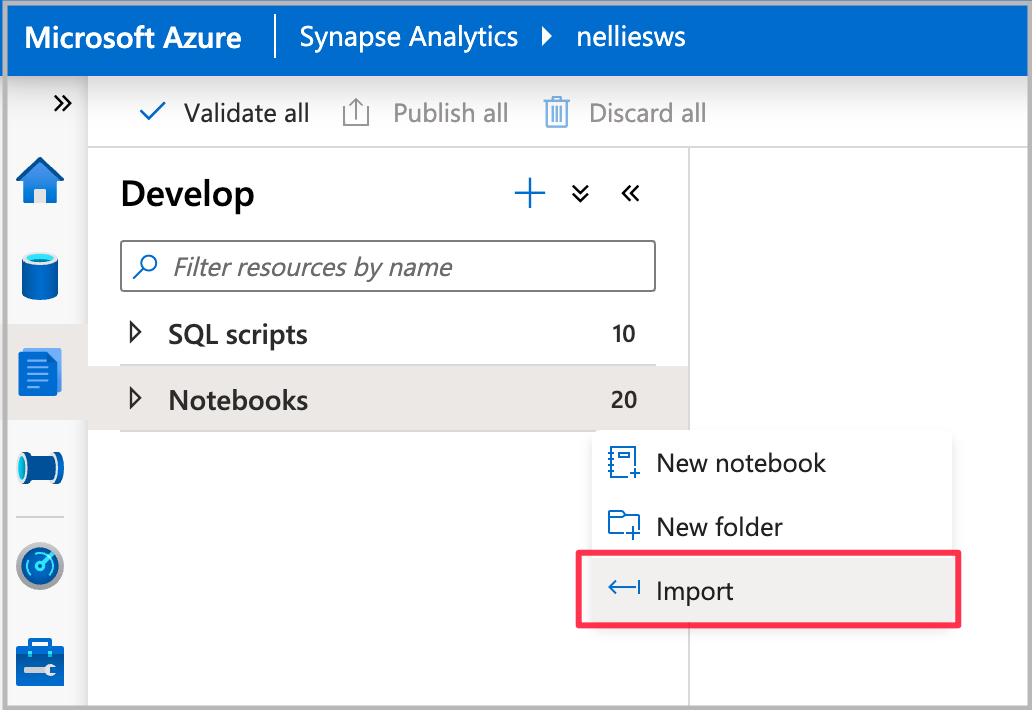
Importujte poznámkový blok do nástroje Synapse Studio.
Vyberte fond Sparku, který chcete použít, a pak vyberte Spustit vše. Tento krok získá data taxislužby New Yorku z otevřené datové sady a uloží data do výchozí databáze Spark.

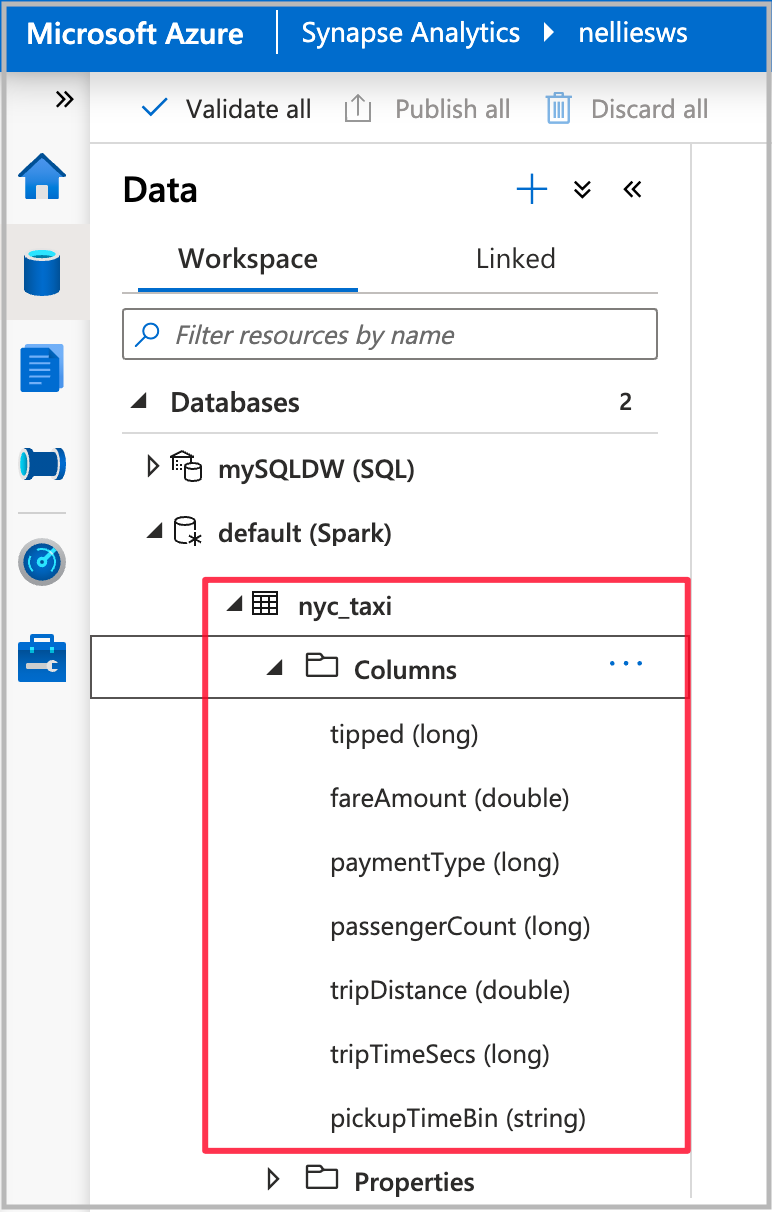
Po dokončení spuštění poznámkového bloku se pod výchozí databází Spark zobrazí nová tabulka Sparku. V části Data vyhledejte tabulku s názvem nyc_taxi.
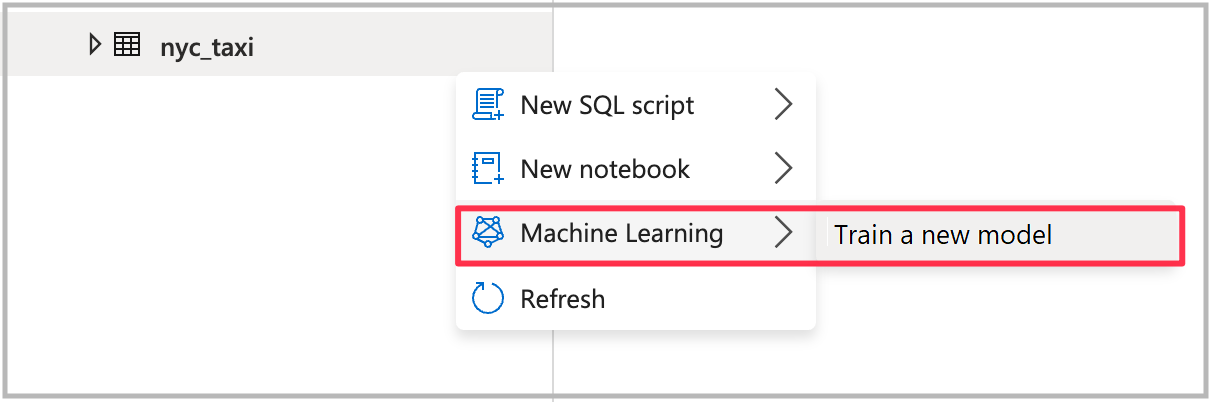
Otevření průvodce automatizovaným strojovém učením
Průvodce otevřete tak, že kliknete pravým tlačítkem na tabulku Sparku, kterou jste vytvořili v předchozím kroku. Pak vyberte Machine Learning>Trénovat nový model.
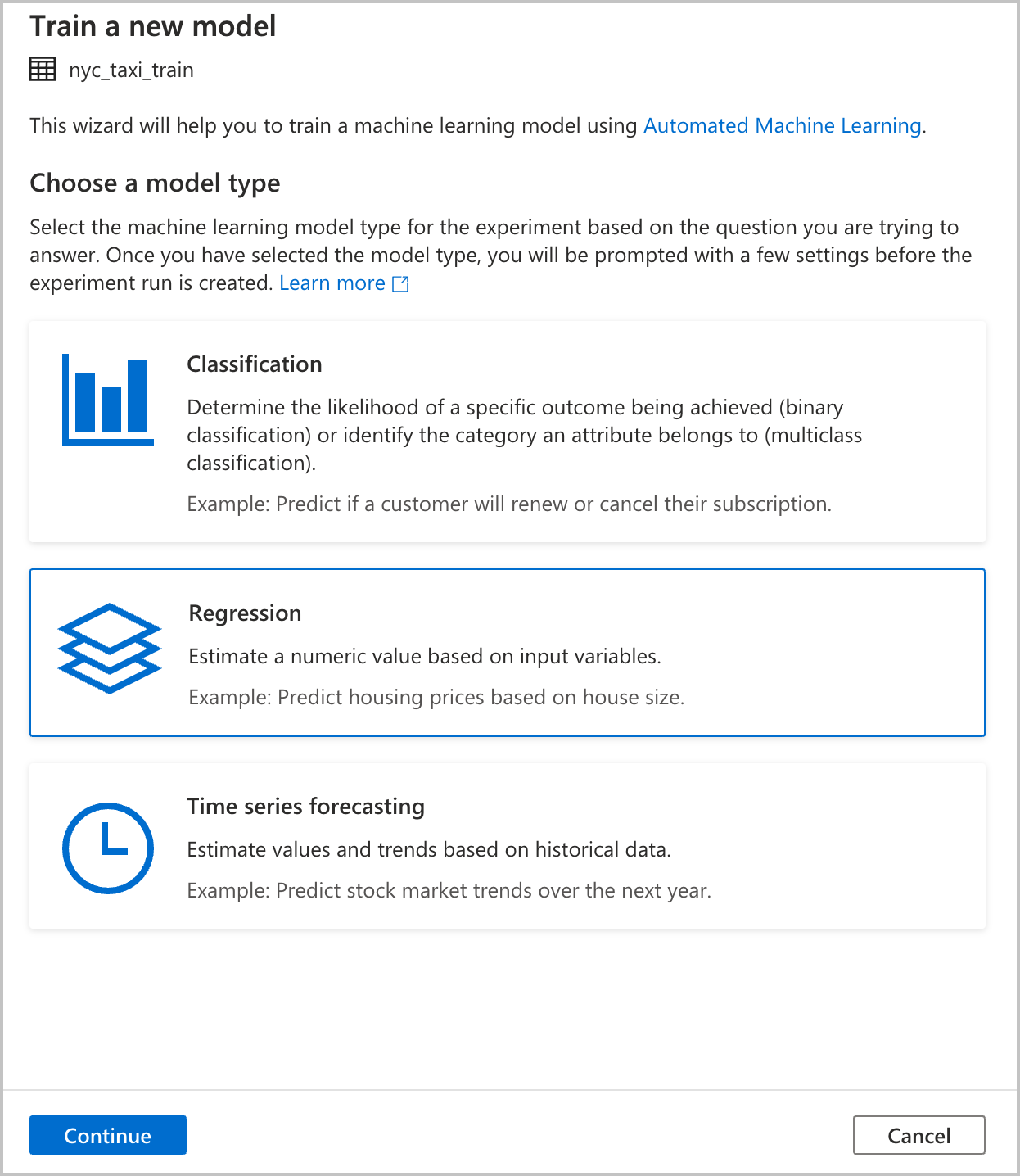
Zvolte typ modelu
Na základě otázky, na kterou se pokoušíte odpovědět, vyberte typ modelu strojového učení pro experiment. Vzhledem k tomu, že hodnota, kterou chcete predikovat, je číselná (jízdná taxíkem), vyberte zde regresi . Potom vyberte Pokračovat.
Konfigurace experimentu
Zadejte podrobnosti konfigurace pro vytvoření experimentu automatizovaného strojového učení ve službě Azure Machine Learning. Tento běh trénuje více modelů. Nejlepší model z úspěšného spuštění je zaregistrovaný v registru modelů služby Azure Machine Learning.
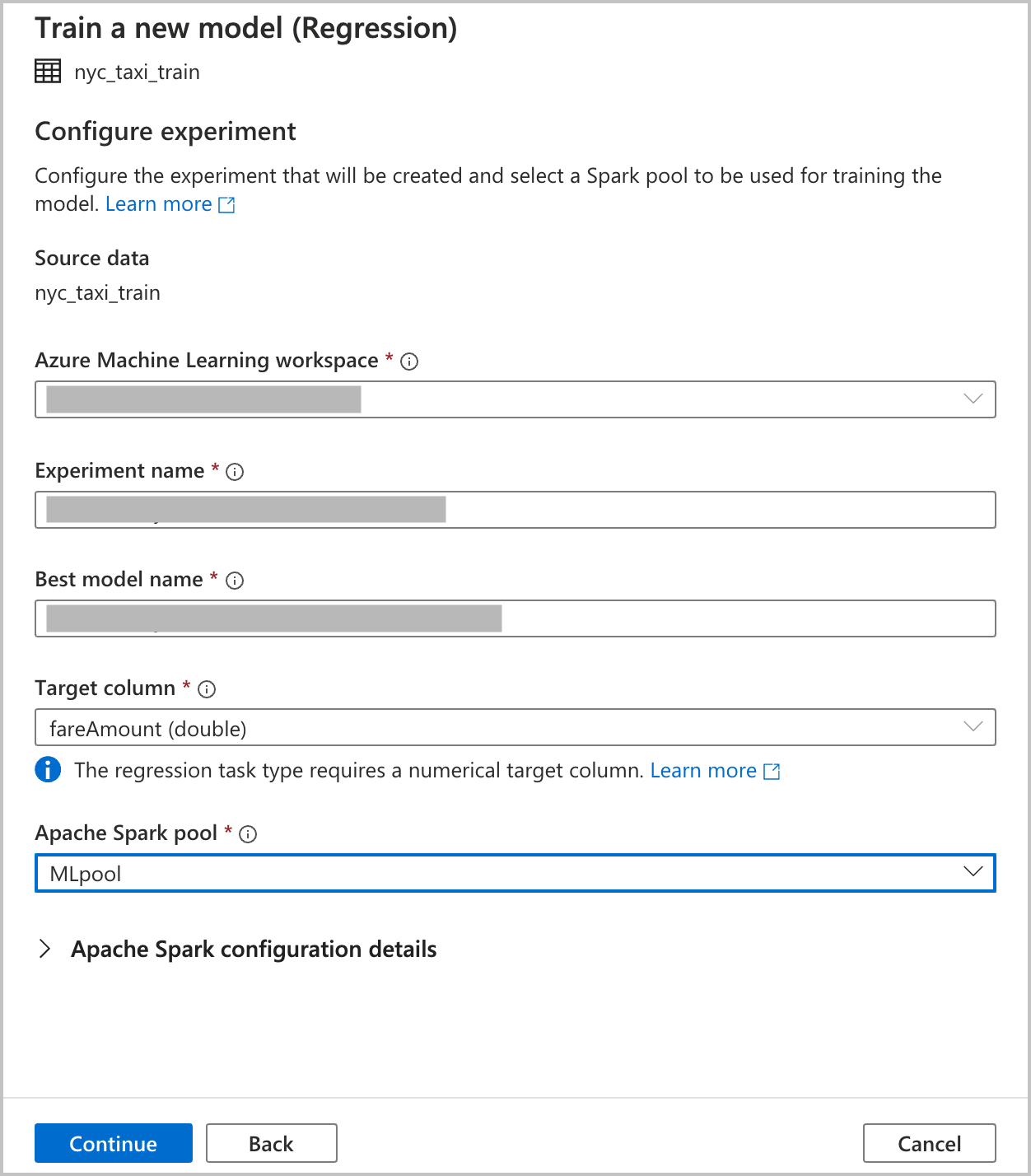
Pracovní prostor Azure Machine Learning: Pracovní prostor Služby Azure Machine Learning se vyžaduje k vytvoření experimentu automatizovaného strojového učení. Musíte také propojit pracovní prostor Azure Synapse Analytics s pracovním prostorem Služby Azure Machine Learning pomocí propojené služby. Po splnění všech požadavků můžete zadat pracovní prostor Služby Azure Machine Learning, který chcete použít pro toto automatizované spuštění.
Název experimentu: Zadejte název experimentu. Když odešlete spuštění automatizovaného strojového učení, zadáte název experimentu. Informace o spuštění se ukládají v rámci tohoto experimentu v pracovním prostoru Azure Machine Learning. Toto prostředí ve výchozím nastavení vytvoří nový experiment a vygeneruje navrhovaný název, ale můžete také zadat název existujícího experimentu.
Nejlepší název modelu: Zadejte název nejlepšího modelu z automatizovaného spuštění. Nejlepší model má tento název a uloží se do registru modelů Služby Azure Machine Learning automaticky po tomto spuštění. Spuštění automatizovaného strojového učení vytváří mnoho modelů strojového učení. Na základě primární metriky, kterou vyberete v pozdějším kroku, je možné tyto modely porovnat a vybrat nejlepší model.
Cílový sloupec: Model se natrénuje tak, aby předpověděl. Vyberte sloupec v datové sadě obsahující data, která chcete předpovědět. Pro účely tohoto kurzu vyberte číselný sloupec
fareAmountjako cílový sloupec.Fond Spark: Zadejte fond Sparku, který chcete použít pro spuštění automatizovaného experimentu. Výpočty se spouští ve vámi zadaném fondu.
Podrobnosti konfigurace Sparku: Kromě fondu Sparku máte možnost zadat podrobnosti o konfiguraci relace.
Zvolte Pokračovat.
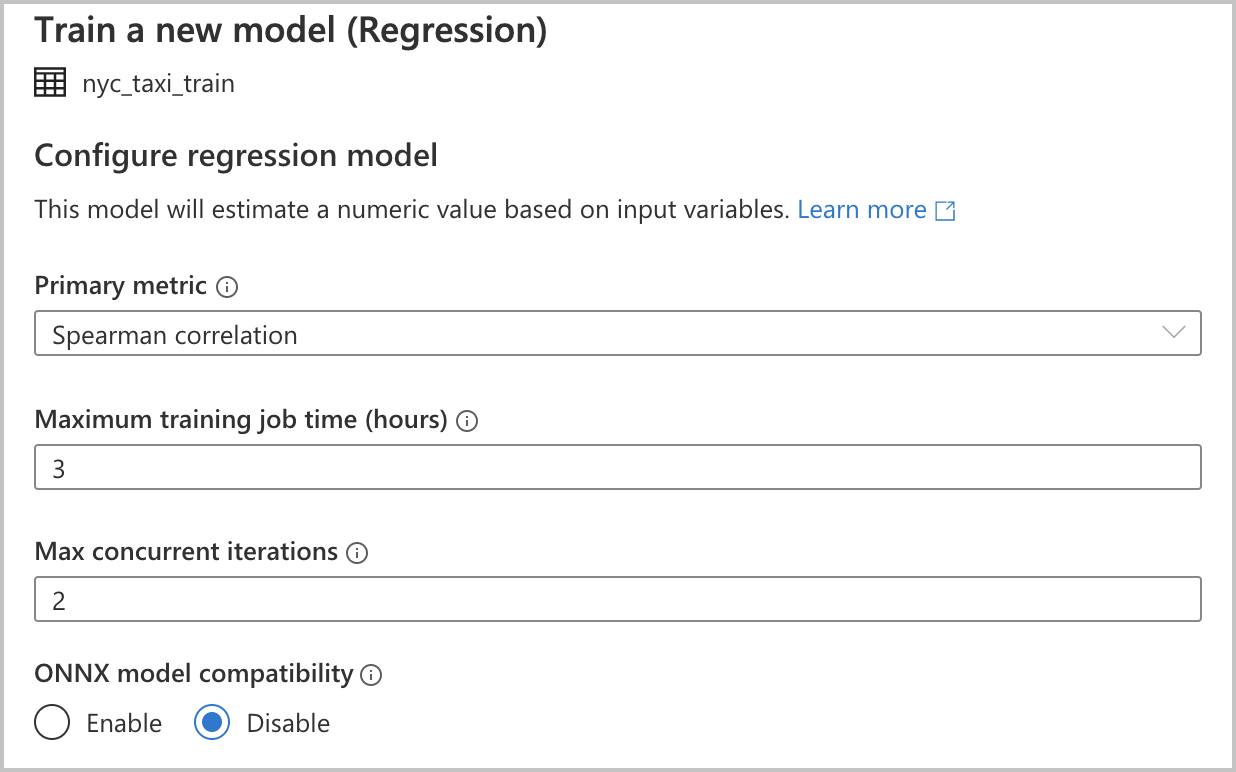
Konfigurace modelu
Vzhledem k tomu, že jste jako typ modelu v předchozí části vybrali Regresi, jsou k dispozici následující konfigurace (jsou k dispozici také pro typ klasifikačního modelu):
Primární metrika: Zadejte metriku, která měří, jak dobře model dělá. Pomocí této metriky můžete porovnat různé modely vytvořené v automatizovaném spuštění a určit, který model fungoval nejlépe.
Doba trénování úlohy (hodiny):: Zadejte maximální dobu v hodinách, po kterou má experiment spouštět a trénovat modely. Všimněte si, že můžete také zadat hodnoty menší než 1 (například 0,5).
Maximální počet souběžných iterací: Zvolte maximální počet iterací, které běží paralelně.
Kompatibilita modelů ONNX: Pokud tuto možnost povolíte, modely natrénované automatizovaným strojovém učení se převedou do formátu ONNX. To je zvlášť důležité, pokud chcete použít model pro bodování ve fondech SQL služby Azure Synapse Analytics.
Všechna tato nastavení mají výchozí hodnotu, kterou můžete přizpůsobit.
Spuštění
Po dokončení všech požadovaných konfigurací můžete spustit automatizované spuštění. Spuštění můžete vytvořit přímo výběrem možnosti Vytvořit spuštění – tím se spustí bez kódu. Pokud dáváte přednost kódu, můžete vybrat Otevřít v poznámkovém bloku – tím se otevře poznámkový blok obsahující kód, který vytvoří spuštění, abyste mohli kód zobrazit a spustit sami.

Poznámka:
Pokud jste jako typ modelu v předchozí části vybrali prognózování časových řad, musíte provést další konfigurace. Prognózování také nepodporuje kompatibilitu modelu ONNX.
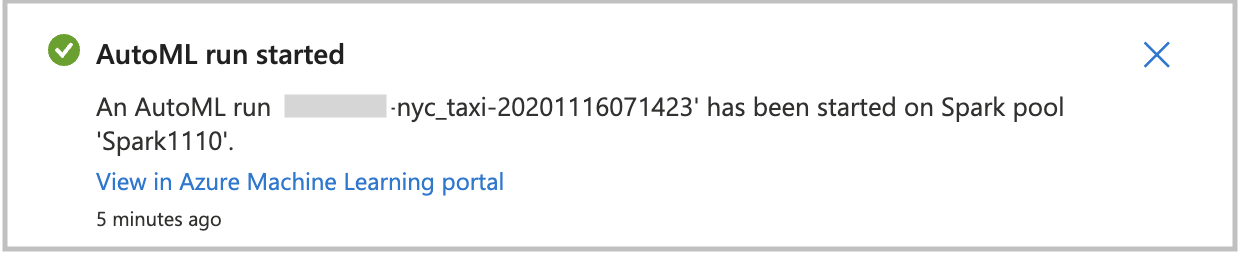
Vytvoření spuštění přímo
Pokud chcete spustit automatizované strojové učení přímo, vyberte Vytvořit spuštění. Zobrazí se oznámení, které indikuje, že spuštění začíná. Pak se zobrazí další oznámení, které indikuje úspěch. Stav ve službě Azure Machine Learning můžete také zkontrolovat tak, že v oznámení vyberete odkaz.
Vytvoření spuštění s poznámkovým blokem
Pokud chcete vygenerovat poznámkový blok, vyberte Otevřít v poznámkovém bloku. Díky tomu můžete přidat nastavení nebo jinak upravit kód pro spuštění automatizovaného strojového učení. Až budete připraveni spustit kód, vyberte Spustit vše.

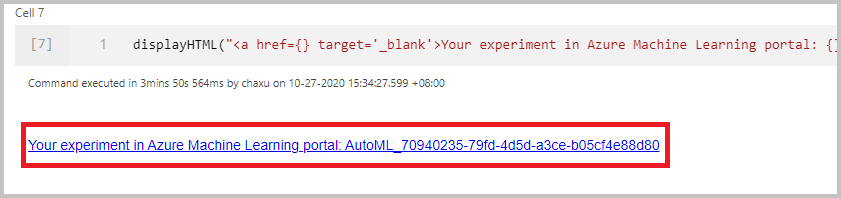
Monitorování spuštění
Po úspěšném odeslání spuštění se ve výstupu poznámkového bloku zobrazí odkaz na spuštění experimentu v pracovním prostoru Azure Machine Learning. Vyberte odkaz pro monitorování automatizovaného spuštění ve službě Azure Machine Learning.