Playbook Synapse POC: Analýza velkých objemů dat s fondem Apache Spark ve službě Azure Synapse Analytics
Tento článek představuje základní metodologii pro přípravu a spuštění efektivního projektu testování konceptu (POC) Služby Azure Synapse Analytics pro fond Apache Spark.
Poznámka:
Tento článek je součástí série článků o testování konceptu v Azure Synapse. Přehled série najdete v playbooku Testování konceptu v Azure Synapse.
Příprava na POC
Projekt POC vám pomůže učinit informované obchodní rozhodnutí o implementaci velkého objemu dat a pokročilého analytického prostředí na cloudové platformě, která využívá fond Apache Spark ve službě Azure Synapse.
Projekt POC identifikuje vaše klíčové cíle a obchodní faktory, které musí podporovat cloudová platforma pro velké objemy dat a pokročilou analytickou platformu. Bude testovat klíčové metriky a prokázat klíčové chování, které jsou důležité pro úspěch přípravy dat, vytváření modelů strojového učení a trénování požadavků. PoC není navržený tak, aby byl nasazen do produkčního prostředí. Jedná se spíše o krátkodobý projekt, který se zaměřuje na klíčové otázky a jeho výsledek je možné zahodit.
Než začnete plánovat projekt Spark POC:
- Identifikujte všechna omezení nebo pokyny, které má vaše organizace ohledně přesunu dat do cloudu.
- Identifikujte vedoucího pracovníka nebo obchodní sponzory pro projekt platformy pro velké objemy dat a pokročilou analytickou platformu. Zabezpečte podporu migrace do cloudu.
- Identifikujte dostupnost technických odborníků a podnikových uživatelů, kteří vás během provádění poc podporují.
Než začnete s přípravou projektu POC, doporučujeme nejprve přečíst dokumentaci k Apache Sparku.
Tip
Pokud s fondy Sparku začínáte, doporučujeme projít si studijní program Provádějte přípravu dat pomocí fondů Azure Synapse Apache Spark.
Nyní byste měli zjistit, že neexistují žádné okamžité překážky a pak můžete začít připravovat na své POC. Pokud s fondy Apache Spark ve službě Azure Synapse Analytics začínáte, můžete si projít tuto dokumentaci , kde získáte přehled o architektuře Sparku a dozvíte se, jak funguje v Azure Synapse.
Pracujte s těmito klíčovými koncepty:
- Apache Spark a jeho distribuovaná architektura
- Koncepty Sparku, jako jsou odolné distribuované datové sady (RDD) a oddíly (v paměti a fyzické).
- Pracovní prostor Azure Synapse, různé výpočetní moduly, kanál a monitorování.
- Oddělení výpočetních prostředků a úložiště ve fondu Sparku
- Ověřování a autorizace v Azure Synapse
- Nativní konektory, které se integrují s vyhrazeným fondem SQL Azure Synapse, službou Azure Cosmos DB a dalšími.
Azure Synapse odděluje výpočetní prostředky od úložiště, abyste mohli lépe spravovat potřeby zpracování dat a řídit náklady. Bezserverová architektura fondu Spark umožňuje rozrůstat a snižovat kapacitu clusteru Spark, a to nezávisle na úložišti. Cluster Sparku můžete pozastavit (nebo nastavit automatické pozastavení). Tímto způsobem platíte za výpočetní prostředky jenom v případě, že se používá. Pokud se nepoužívá, platíte jenom za úložiště. Můžete vertikálně navýšit kapacitu clusteru Spark pro náročné zpracování dat nebo velké zatížení a pak ho vertikálně snížit během méně intenzivní doby zpracování (nebo ho úplně vypnout). Cluster můžete efektivně škálovat a pozastavit, abyste snížili náklady. Testy Spark POC by měly zahrnovat příjem dat a zpracování dat v různých měřítkech (malé, střední a velké) a porovnat cenu a výkon v jiném měřítku. Další informace najdete v tématu Automatické škálování fondů Apache Spark ve službě Azure Synapse Analytics.
Je důležité pochopit rozdíl mezi různými sadami rozhraní API Sparku, abyste se mohli rozhodnout, co je pro váš scénář nejvhodnější. Můžete si vybrat ten, který poskytuje lepší výkon nebo snadné použití, a využívat stávající sady dovedností vašeho týmu. Další informace najdete v tématu A Tale of Three Apache Spark API: RDD, DataFrames a Datasets.
Dělení dat a souborů ve Sparku se mírně liší. Pochopení rozdílů vám pomůže optimalizovat výkon. Další informace najdete v dokumentaci k Apache Sparku: Možnosti zjišťování oddílů a konfigurace oddílů.
Nastavení cílů
Úspěšný projekt POC vyžaduje plánování. Začněte tím, že zjistíte, proč provádíte POC, abyste plně porozuměli skutečným motivacím. Motivací může být modernizace, úspora nákladů, zlepšení výkonu nebo integrované prostředí. Nezapomeňte zdokumentovat jasné cíle pro vaši POC a kritéria, která budou definovat jeho úspěch. Zeptejte se sami sebe:
- Co chcete jako výstupy poc?
- Co s těmito výstupy uděláte?
- Kdo bude používat výstupy?
- Co definuje úspěšné POC?
Mějte na paměti, že POC by mělo být krátké a zaměřené úsilí k rychlému prokázání omezené sady konceptů a schopností. Tyto koncepty a možnosti by měly být reprezentativní pro celkovou úlohu. Pokud máte dlouhý seznam položek, které se mají prokázat, můžete chtít naplánovat více než jeden POC. V takovém případě definujte brány mezi poc, abyste zjistili, jestli potřebujete pokračovat s dalším. Vzhledem k různým profesionálním rolím, které můžou používat fondy Sparku a poznámkové bloky ve službě Azure Synapse, můžete se rozhodnout spustit několik poc. Například jeden POC se může zaměřit na požadavky na roli přípravy dat, jako je příjem dat a zpracování. Další POC by se mohl zaměřit na vývoj modelů strojového učení (ML).
Při zvažování cílů POC si položte následující otázky, které vám pomůžou utvářet cíle:
- Migrujete z existující platformy pro velké objemy dat a pokročilou analytickou platformu (místní nebo cloud)?
- Migrujete, ale chcete provést co nejvíce změn u stávajícího příjmu dat a zpracování dat? Například migrace Sparku do Sparku nebo migrace Hadoop/Hive do Sparku.
- Migrujete, ale chcete provést nějaká rozsáhlá vylepšení? Můžete například znovu zapsat úlohy MapReduce jako úlohy Sparku nebo převést starší kód založený na RDD na kód založený na datovém rámci nebo datové sadě.
- Vytváříte zcela novou platformu pro velké objemy dat a pokročilou analytickou platformu (projekt zeleného pole)?
- Jaké jsou vaše aktuální body bolesti? Například škálovatelnost, výkon nebo flexibilita.
- Jaké nové obchodní požadavky potřebujete podporovat?
- Jaké smlouvy SLA se vyžadují ke splnění?
- Jaké budou úlohy? Například ETL, dávkové zpracování, zpracování datových proudů, trénování modelu strojového učení, analýzy, dotazy generování sestav nebo interaktivní dotazy?
- Jaké jsou dovednosti uživatelů, kteří budou projekt vlastnit (měli by být implementováno POC)? Například PySpark vs. Scala dovednosti, poznámkové bloky a prostředí IDE.
Tady je několik příkladů nastavení cíle POC:
- Proč děláme POC?
- Potřebujeme vědět, že výkon příjmu a zpracování dat pro naši úlohu s velkými objemy dat bude splňovat nové smlouvy SLA.
- Potřebujeme vědět, jestli je možné zpracování datových proudů téměř v reálném čase a jakou propustnost může podporovat. (Bude podporovat naše obchodní požadavky?)
- Potřebujeme vědět, jestli jsou naše stávající procesy příjmu a transformace dat vhodné a kde bude potřeba provést vylepšení.
- Potřebujeme vědět, jestli můžeme zkrátit dobu běhu integrace dat a o kolik času.
- Potřebujeme vědět, jestli naši datoví vědci můžou vytvářet a trénovat modely strojového učení a podle potřeby využívat knihovny AI/ML ve fondu Spark.
- Bude přechod na cloudovou službu Synapse Analytics vyhovovat našim cílům nákladů?
- Na závěr tohoto POC:
- Budeme mít data, abychom zjistili, jestli je možné splnit požadavky na výkon zpracování dat pro dávkové i streamování v reálném čase.
- Otestovali jsme příjem a zpracování všech našich různých datových typů (strukturovaných, polostrukturovaných a nestrukturovaných), které podporují naše případy použití.
- Otestovali jsme některé z našich stávajících složitých zpracování dat a můžeme identifikovat práci, která bude potřeba dokončit při migraci portfolia integrace dat do nového prostředí.
- Otestovali jsme příjem a zpracování dat a budeme mít datové body k odhadu úsilí potřebného pro počáteční migraci a zatížení historických dat a také odhadnout úsilí potřebné k migraci příjmu dat (Azure Data Factory (ADF), Distcp, Databox nebo jiných).
- Otestovali jsme příjem a zpracování dat a můžeme určit, jestli je možné splnit požadavky na zpracování ETL/ELT.
- Získali jsme přehled, abychom lépe odhadli úsilí potřebné k dokončení projektu implementace.
- Otestovali jsme možnosti škálování a škálování a budeme mít datové body, abychom lépe nakonfigurovali naši platformu pro lepší nastavení cenového výkonu.
- Budeme mít seznam položek, které můžou potřebovat další testování.
Plánování projektu
Pomocí cílů identifikujte konkrétní testy a poskytněte výstupy, které jste identifikovali. Je důležité mít jistotu, že máte alespoň jeden test pro podporu každého cíle a očekávaného výstupu. Identifikujte také konkrétní příjem dat, dávkové zpracování nebo zpracování datových proudů a všechny ostatní procesy, které se spustí, abyste mohli identifikovat velmi konkrétní datovou sadu a základ kódu. Tato konkrétní datová sada a základ kódu budou definovat rozsah POC.
Tady je příklad potřebné úrovně specificity při plánování:
- Cíl A: Potřebujeme vědět, jestli náš požadavek na příjem dat a zpracování dávkových dat lze splnit v rámci definované smlouvy SLA.
- Výstup A: Budeme mít data k určení, jestli náš dávkový příjem a zpracování dat může splňovat požadavek na zpracování dat a smlouvu SLA.
- Test A1: Zpracování dotazů A, B a C jsou identifikovány jako dobré testy výkonnosti, protože je běžně provádí tým přípravy dat. Představují také celkové potřeby zpracování dat.
- Test A2: Zpracování dotazů X, Y a Z jsou identifikovány jako dobré testy výkonnosti, protože obsahují požadavky na zpracování datových proudů téměř v reálném čase. Představují také celkové potřeby zpracování datových proudů založených na událostech.
- Test A3: Porovnejte výkon těchto dotazů v jiném měřítku clusteru Spark (různý počet pracovních uzlů, velikost pracovních uzlů – například malé, střední a velké – počet a velikost exekutorů) s srovnávacím testem získaným z existujícího systému. Mějte na paměti, že se zmenšuje zákon o výnosech . Přidání dalších prostředků (vertikálním navýšením kapacity nebo horizontálním navýšením kapacity) může pomoct dosáhnout paralelismu, ale existuje určité omezení, které je pro každý scénář jedinečné, aby bylo možné dosáhnout paralelismu. Objevte optimální konfiguraci pro každý identifikovaný případ použití ve vašem testování.
- Cíl B: Potřebujeme vědět, jestli naši datoví vědci můžou vytvářet a trénovat modely strojového učení na této platformě.
- Výstup B: Otestujeme některé z našich modelů strojového učení tím, že je trénujeme na data ve fondu Sparku nebo ve fondu SQL s využitím různých knihoven strojového učení. Tyto testy vám pomůžou určit, které modely strojového učení je možné migrovat do nového prostředí.
- Test B1: Budou testovány konkrétní modely strojového učení.
- Test B2: Otestujte základní knihovny strojového učení, které jsou součástí Sparku (Spark MLLib) spolu s další knihovnou, která se dá nainstalovat ve Sparku (například scikit-learn), aby splňovala požadavek.
- Cíl C: Otestovali jsme příjem dat a budeme mít datové body:
- Odhadněte úsilí o naši počáteční historickou migraci dat do data lake nebo fondu Sparku.
- Plánování přístupu k migraci historických dat
- Výstup C: Otestujeme a určíme míru příjmu dat v našem prostředí a můžeme určit, jestli je rychlost příjmu dat dostatečná pro migraci historických dat během dostupného časového intervalu.
- Test C1: Otestujte různé přístupy k migraci historických dat. Další informace najdete v tématu Přenos dat do a z Azure.
- Test C2: Identifikujte přidělenou šířku pásma ExpressRoute a pokud existuje nějaká omezení nastavená týmem infrastruktury. Další informace najdete v tématu Co je Azure ExpressRoute? (Možnosti šířky pásma).
- Test C3: Otestujte rychlost přenosu dat pro online i offline migraci dat. Další informace najdete v aktivita Copy průvodci výkonem a škálovatelností.
- Test C4: Otestujte přenos dat z datového jezera do fondu SQL pomocí příkazu ADF, Polybase nebo COPY. Další informace najdete v tématu Strategie načítání dat pro vyhrazený fond SQL ve službě Azure Synapse Analytics.
- Cíl D: Otestujeme rychlost příjmu dat přírůstkového načítání dat a budeme mít datové body k odhadu časového intervalu příjmu a zpracování dat do datového jezera nebo vyhrazeného fondu SQL.
- Výstup D: Otestujeme rychlost příjmu dat a můžeme určit, jestli je možné splnit požadavky na příjem a zpracování dat s identifikovaným přístupem.
- Test D1: Otestujte příjem a zpracování dat denní aktualizace.
- Test D2: Otestujte zatížení zpracovaných dat do vyhrazené tabulky fondu SQL z fondu Sparku. Další informace najdete v tématu Konektor vyhrazeného fondu SQL Azure Synapse pro Apache Spark.
- Test D3: Souběžné spouštění denního procesu načítání aktualizací při spouštění dotazů koncových uživatelů
Nezapomeňte testy upřesnit přidáním několika testovacích scénářů. Azure Synapse umožňuje snadno testovat různé škálování (různý počet pracovních uzlů, velikost pracovních uzlů, jako jsou malé, střední a velké), a porovnat výkon a chování.
Tady je několik testovacích scénářů:
- Test fondu Spark A: Provedeme zpracování dat napříč několika typy uzlů (malé, střední a velké) a také různými počty pracovních uzlů.
- Test fondu SparkU B: Pomocí konektoru načteme nebo načteme zpracovávaná data z fondu Sparku do vyhrazeného fondu SQL.
- Test fondu Sparku C: Načteme a načteme zpracovaná data z fondu Sparku do azure Cosmos DB přes Azure Synapse Link.
Vyhodnocení datové sady POC
Pomocí konkrétních testů, které jste identifikovali, vyberte datovou sadu pro podporu testů. Než tuto datovou sadu zkontrolujete, udělejte si čas. Měli byste ověřit, že datová sada bude dostatečně reprezentovat budoucí zpracování z hlediska obsahu, složitosti a škálování. Nepoužívejte datovou sadu, která je příliš malá (menší než 1 TB), protože neposkytuje reprezentativní výkon. Naopak nepoužívejte datovou sadu, která je příliš velká, protože by se poC neměla stát úplnou migrací dat. Nezapomeňte získat odpovídající srovnávací testy ze stávajících systémů, abyste je mohli použít pro porovnání výkonu.
Důležité
Před přesunem jakýchkoli dat do cloudu se ujistěte, že u vlastníků firmy zkontrolujete případné překážky. Identifikujte všechny obavy ohledně zabezpečení nebo ochrany osobních údajů nebo jakékoli potřeby obfuskace dat, které by se měly provést před přesunem dat do cloudu.
Vytvoření architektury vysoké úrovně
Na základě architektury vysoké úrovně navrhované budoucí architektury stavu identifikujte komponenty, které budou tvořit součást vašeho POC. Architektura budoucího stavu vysoké úrovně pravděpodobně obsahuje mnoho zdrojů dat, mnoho příjemců dat, komponenty pro velké objemy dat a možná i uživatele dat umělé inteligence (AI). Architektura POC by měla konkrétně identifikovat komponenty, které budou součástí POC. Důležité je, že by měla identifikovat všechny komponenty, které nebudou součástí testování POC.
Pokud už používáte Azure, identifikujte všechny prostředky, které už máte (Microsoft Entra ID, ExpressRoute a další), které můžete použít během poC. Identifikujte také oblasti Azure, které vaše organizace používá. Teď je skvělá doba k identifikaci propustnosti připojení ExpressRoute a ke kontrole s ostatními firemními uživateli, že vaše POC může tuto propustnost využívat, aniž by to mělo nepříznivý dopad na produkční systémy.
Další informace najdete v tématu Architektury pro velké objemy dat.
Identifikace prostředků POC
Konkrétně identifikujte technické zdroje a časové závazky potřebné k podpoře vašeho POC. Váš POC bude potřebovat:
- Obchodní zástupce, který dohlíží na požadavky a výsledky.
- Odborník na data aplikací ke zdroji dat pro POC a poskytnutí znalostí existujících procesů a logiky.
- Odborník na apache Spark a fond Spark.
- Odborný poradce pro optimalizaci testů POC.
- Zdroje, které budou vyžadovány pro konkrétní součásti projektu POC, ale nemusí se nutně vyžadovat po dobu trvání POC. Mezi tyto prostředky patří správci sítě, správci Azure, správci Active Directory, správci webu Azure Portal a další.
- Ujistěte se, že jsou zřízené všechny požadované prostředky služeb Azure a je udělena požadovaná úroveň přístupu, včetně přístupu k účtům úložiště.
- Ujistěte se, že máte účet, který má požadovaná oprávnění pro přístup k datům pro načtení dat ze všech zdrojů dat v oboru POC.
Tip
Doporučujeme zapojit odborníka, který vám pomůže s poc. Partnerská komunita Microsoftu má globální dostupnost expertních konzultantů, kteří vám můžou pomoct vyhodnotit, vyhodnotit nebo implementovat Azure Synapse.
Nastavení časové osy
Projděte si podrobnosti o plánování POC a potřeby firmy, abyste identifikovali časový rámec pro váš POC. Proveďte realistické odhady času, který bude potřeba k dokončení cílů POC. Doba dokončení poc bude ovlivněna velikostí datové sady POC, počtem a složitostí testů a počtem rozhraní, která se mají testovat. Pokud odhadnete, že poc poběží déle než čtyři týdny, zvažte snížení rozsahu POC, aby se zaměřil na cíle s nejvyšší prioritou. Než budete pokračovat, nezapomeňte získat schválení a závazek od všech potenciálních zdrojů a sponzorů.
Vyzkoušejte si POC.
Doporučujeme spustit projekt POC s disciplínou a kategorií jakéhokoli produkčního projektu. Spusťte projekt podle plánu a spravujte proces žádosti o změnu, aby se zabránilo nekontrolovatelnému růstu rozsahu POC.
Tady je několik příkladů úloh vysoké úrovně:
Vytvořte pracovní prostor Synapse, fondy Sparku a vyhrazené fondy SQL, účty úložiště a všechny prostředky Azure identifikované v plánu POC.
Načtení datové sady POC:
- Zpřístupnění dat v Azure extrahováním ze zdroje nebo vytvořením ukázkových dat v Azure Další informace najdete tady: .
- Otestujte vyhrazený konektor pro fond Sparku a vyhrazený fond SQL.
Migrace existujícího kódu do fondu Sparku:
- Pokud migrujete ze Sparku, bude vaše migrace pravděpodobně jednoduchá vzhledem k tomu, že fond Spark využívá opensourcovou distribuci Sparku. Pokud ale používáte funkce specifické pro dodavatele nad základními funkcemi Sparku, budete je muset správně namapovat na funkce fondu Sparku.
- Pokud migrujete z jiného systému než Spark, vaše úsilí o migraci se bude lišit v závislosti na složitosti.
Proveďte testy:
- Mnoho testů se dá spustit paralelně napříč několika clustery fondu Sparku.
- Zaznamenejte si výsledky v použitelném a snadno pochopitelném formátu.
Monitorování pro řešení potíží a výkon Další informace naleznete v tématu:
Monitorování nerovnoměrné distribuce dat, míry nerovnoměrné distribuce času a procentuálního využití exekutoru otevřením karty Diagnostika na serveru historie Sparku
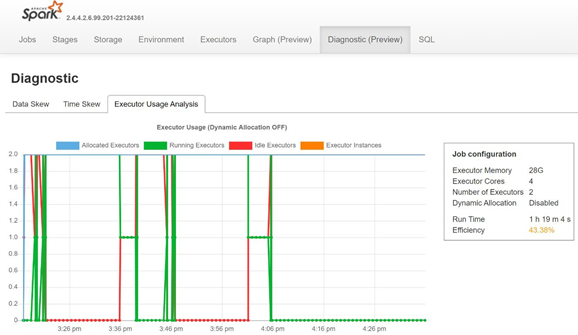
Interpretace výsledků POC
Po dokončení všech testů POC vyhodnotíte výsledky. Začněte vyhodnocením, jestli byly splněny cíle poc a byly shromážděny požadované výstupy. Určete, jestli je potřeba provést další testování, nebo jestli je potřeba řešit jakékoli otázky.