Kurz: Analýza sestav inventáře objektů blob
Když pochopíte, jak jsou objekty blob a kontejnery uložené, uspořádané a používané v produkčním prostředí, můžete lépe optimalizovat kompromisy mezi náklady a výkonem.
V tomto kurzu se dozvíte, jak generovat a vizualizovat statistiky, jako je růst dat v průběhu času, počet upravených souborů, velikosti snímků objektů blob, vzory přístupu v jednotlivých úrovních a způsob distribuce dat v současné době i v průběhu času (například data napříč vrstvami, typy souborů, kontejnery a typy objektů blob).
V tomto kurzu se naučíte:
- Generování sestavy inventáře objektů blob
- Nastavení pracovního prostoru Synapse
- Nastavení synapse Studia
- Generování analytických dat v nástroji Synapse Studio
- Vizualizovat výsledky v Power BI
Požadavky
Předplatné Azure – vytvoření účtu zdarma
Účet úložiště Azure – vytvoření účtu úložiště
Ujistěte se, že má vaše identita uživatele přiřazenou roli Přispěvatel dat objektů blob služby Storage.
Generování sestavy inventáře
Povolte pro svůj účet úložiště sestavy inventáře objektů blob. Viz Povolení sestav inventáře objektů blob služby Azure Storage.
Možná budete muset počkat až 24 hodin po povolení generování sestav inventáře pro první sestavu.
Nastavení pracovního prostoru Synapse
Vytvořte pracovní prostor Azure Synapse. Viz Vytvoření pracovního prostoru Azure Synapse.
Poznámka:
V rámci vytváření pracovního prostoru vytvoříte účet úložiště, který má hierarchický obor názvů. Azure Synapse ukládá do tohoto účtu tabulky Sparku a aplikační protokoly. Azure Synapse odkazuje na tento účet jako na primární účet úložiště. Aby se zabránilo nejasnostem, tento článek používá účet sestavy inventáře termínů k odkazování na účet, který obsahuje sestavy inventáře.
V pracovním prostoru Synapse přiřaďte roli Přispěvatel k vaší identitě uživatele. Viz Azure RBAC: Role vlastníka pracovního prostoru.
Udělte pracovnímu prostoru Synapse oprávnění pro přístup k sestavám inventáře ve vašem účtu úložiště tak, že přejdete k účtu sestavy inventáře a potom přiřadíte roli Přispěvatel dat objektů blob služby Storage k systémové spravované identitě pracovního prostoru. Viz téma Přiřazování rolí Azure s využitím webu Azure Portal.
Přejděte do primárního účtu úložiště a přiřaďte roli Přispěvatel služby Blob Storage vaší identitě uživatele.
Nastavení synapse Studia
Otevřete pracovní prostor Synapse v nástroji Synapse Studio. Viz Open Synapse Studio.
V nástroji Synapse Studio se ujistěte, že je vaší identitě přiřazená role správce Synapse. Viz Synapse RBAC: Role správce Synapse pro pracovní prostor.
Vytvořte fond Apache Sparku. Viz Vytvoření bezserverového fondu Apache Sparku.
Nastavení a spuštění ukázkového poznámkového bloku
V této části vygenerujete statistická data, která budete vizualizovat v sestavě. Pro zjednodušení tohoto kurzu se v této části používá ukázkový konfigurační soubor a ukázkový poznámkový blok PySpark. Poznámkový blok obsahuje kolekci dotazů, které se spouští v nástroji Azure Synapse Studio.
Úprava a nahrání ukázkového konfiguračního souboru
Stáhněte soubor BlobInventoryStorageAccountConfiguration.json.
Aktualizujte následující zástupné symboly tohoto souboru:
Nastavte
storageAccountNamenázev účtu sestavy inventáře.Nastavte
destinationContainerna název kontejneru, který obsahuje sestavy inventáře.Nastavte
blobInventoryRuleNamena název pravidla sestavy inventáře, které vygenerovalo výsledky, které chcete analyzovat.Nastavte
accessKeyklíč účtu účtu sestavy inventáře.
Nahrajte tento soubor do kontejneru v primárním účtu úložiště, který jste zadali při vytváření pracovního prostoru Synapse.
Import ukázkového poznámkového bloku PySpark
Stáhněte si ukázkový poznámkový blok ReportAnalysis.ipynb.
Poznámka:
Nezapomeňte tento soubor uložit s příponou
.ipynb.Otevřete pracovní prostor Synapse v nástroji Synapse Studio. Viz Open Synapse Studio.
V nástroji Synapse Studio vyberte kartu Vývoj .
Vyberte znaménko plus (+) a přidejte položku.
Vyberte Importovat, přejděte k ukázkovém souboru, který jste stáhli, vyberte ho a vyberte Otevřít.
Zobrazí se dialogové okno Vlastnosti .
V dialogovém okně Vlastnosti vyberte odkaz Konfigurovat relaci .
Otevře se dialogové okno Konfigurovat relaci .
V rozevíracím seznamu Připojit k dialogovém okně Konfigurovat relaci vyberte fond Spark, který jste vytvořili dříve v tomto článku. Pak vyberte tlačítko Použít .
Úprava poznámkového bloku Pythonu
V první buňce poznámkového bloku Pythonu nastavte hodnotu
storage_accountproměnné na název primárního účtu úložiště.Aktualizujte hodnotu
container_nameproměnné na název kontejneru v tomto účtu, který jste zadali při vytváření pracovního prostoru Synapse.Vyberte tlačítko Publikovat.
Spuštění poznámkového bloku PySpark
V poznámkovém bloku PySpark vyberte Spustit vše.
Spuštění relace Sparku a zpracování sestav inventáře bude několik minut trvat několik minut. První spuštění může chvíli trvat, pokud je potřeba zpracovat řadu sestav inventáře. Následná spuštění budou zpracovávat pouze nové sestavy inventáře vytvořené od posledního spuštění.
Poznámka:
Pokud v poznámkovém bloku provedete nějaké změny, bude poznámkový blok spuštěný, nezapomeňte tyto změny publikovat pomocí tlačítka Publikovat .
Výběrem karty Data ověřte, že se poznámkový blok úspěšně spustil.
Databáze s názvem reportdata by se měla zobrazit na kartě Pracovní prostor v podokně Data . Pokud se tato databáze nezobrazí, možná budete muset webovou stránku aktualizovat.
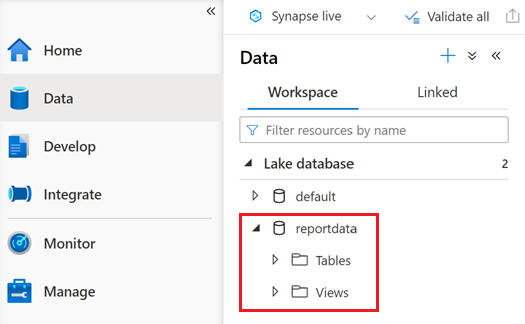
Databáze obsahuje sadu tabulek. Každá tabulka obsahuje informace získané spuštěním dotazů z poznámkového bloku PySpark.
Pokud chcete prozkoumat obsah tabulky, rozbalte složku Tabulky databáze sestav. Potom klikněte pravým tlačítkem myši na tabulku, vyberte Vybrat skript SQL a pak vyberte Vybrat PRVNÍCH 100 řádků.
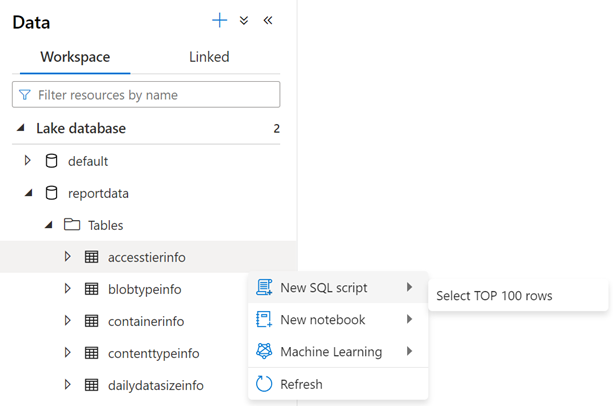
Podle potřeby můžete dotaz upravit a pak výběrem možnosti Spustit zobrazit výsledky.
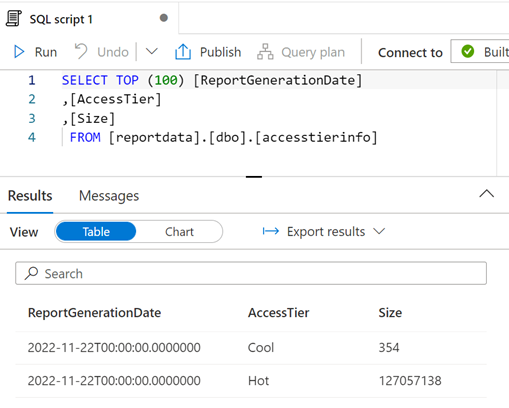
Vizualizace dat
Otevřete Power BI Desktop. Pokyny k instalaci najdete v tématu Získání Power BI Desktopu.
V Power BI vyberte Soubor, Otevřít sestavu a pak Procházet sestavy.
V dialogovém okně Otevřít změňte typ souboru na soubory šablon Power BI (*.pbit).

Přejděte do umístění souboru ReportAnalysis.pbit , který jste stáhli, a pak vyberte Otevřít.
Zobrazí se dialogové okno s dotazem, abyste zadali název pracovního prostoru Synapse a název základu dat.
V dialogovém okně nastavte pole synapse_workspace_name na název pracovního prostoru a nastavte pole database_name na
reportdatahodnotu . Pak vyberte tlačítko Načíst .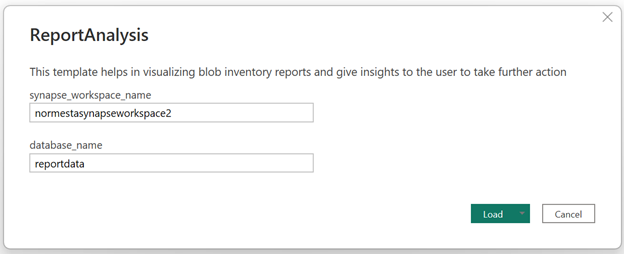
Zobrazí se sestava, která poskytuje vizualizace dat načtených poznámkovým blokem. Následující obrázky znázorňují typy grafů a grafů, které se zobrazují v této sestavě.
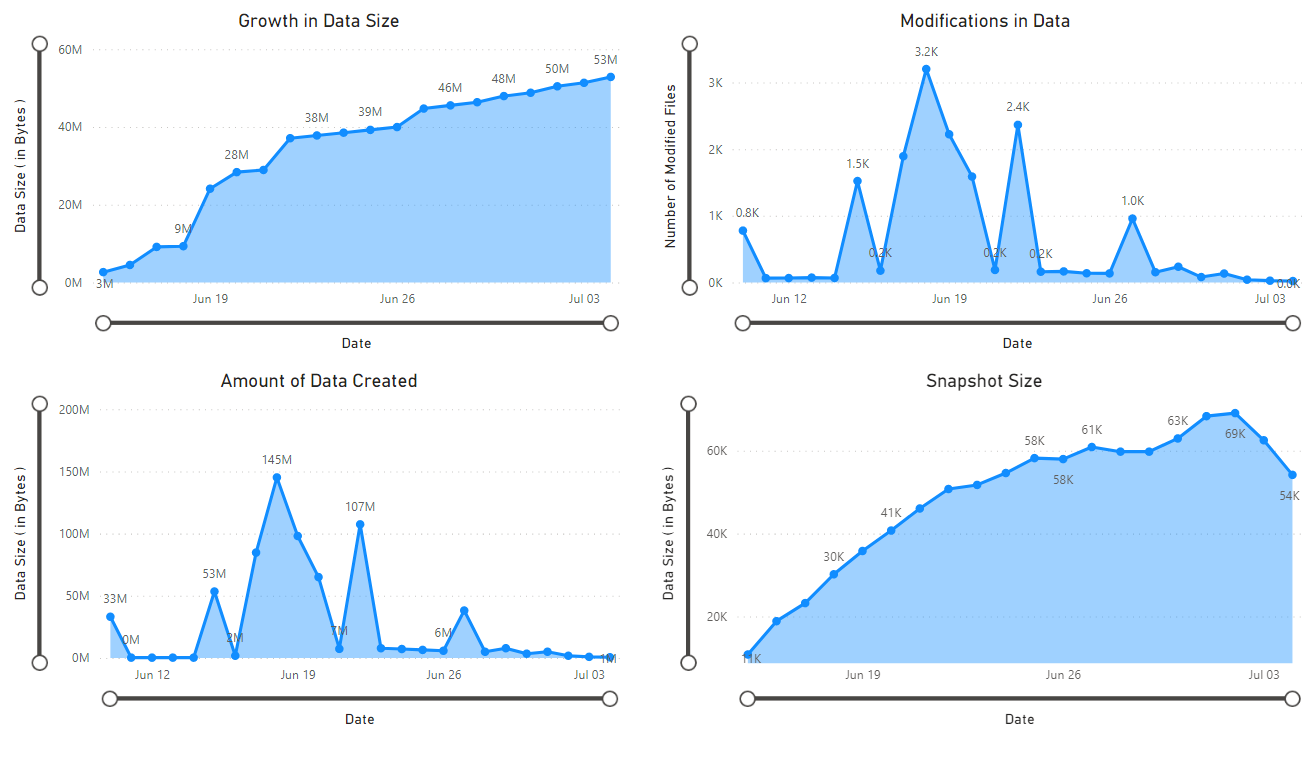
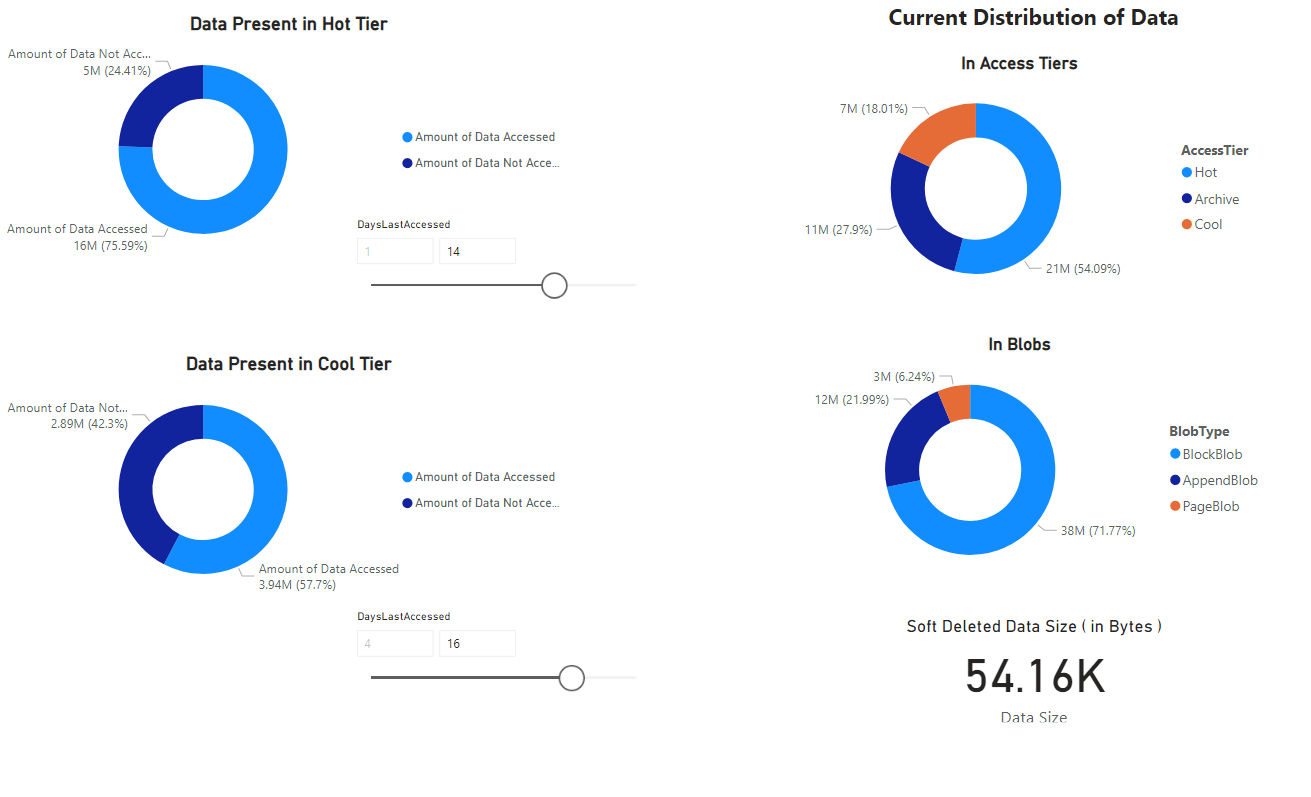
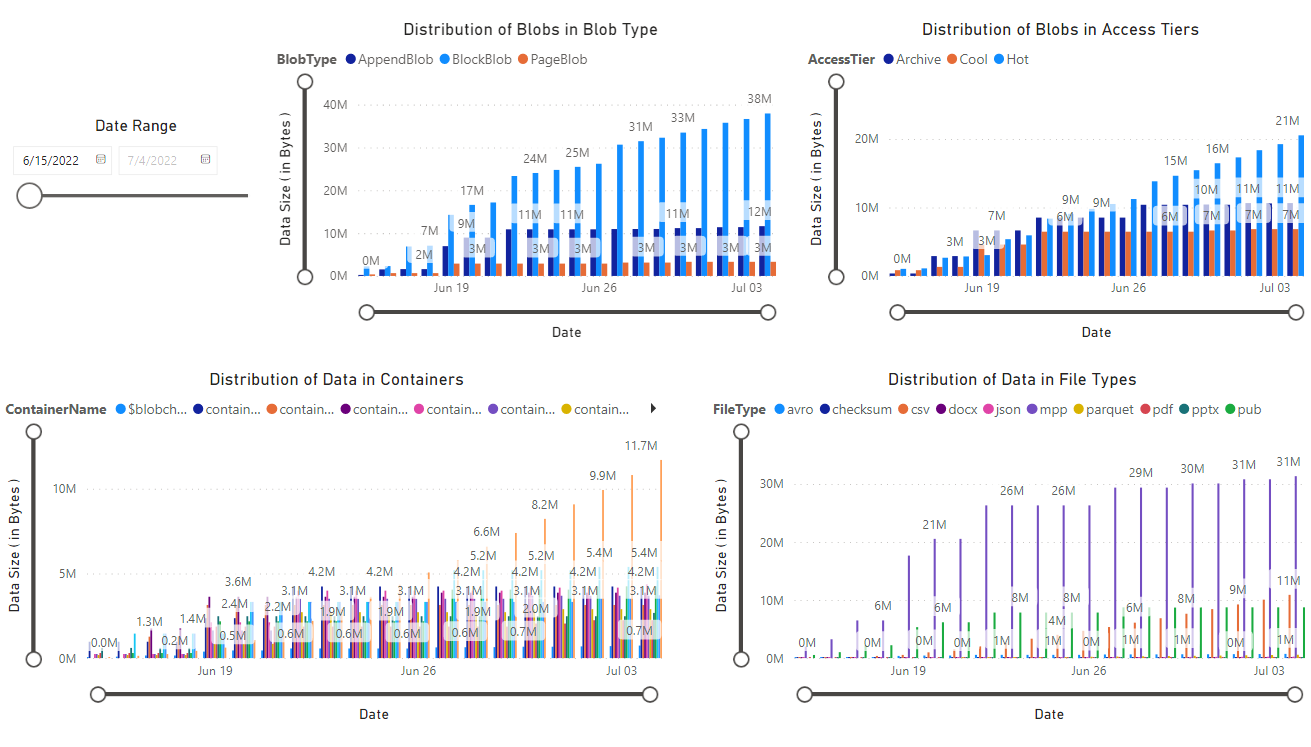
Další kroky
Nastavte kanál Azure Synapse tak, aby poznámkový blok běžel v pravidelných intervalech. Tímto způsobem můžete zpracovávat nové sestavy inventáře při jejich vytváření. Po počátečním spuštění budou všechna další spuštění analyzovat přírůstková data a pak aktualizovat tabulky výsledky této analýzy. Pokyny najdete v tématu Integrace s kanály.
Zjistěte, jak analyzovat jednotlivé kontejnery v účtu úložiště. Podívejte se na tyto články:
Zjistěte, jak optimalizovat náklady na základě analýzy objektů blob a kontejnerů. Podívejte se na tyto články:
Plánování a správa nákladů na službu Azure Blob Storage
Odhad nákladů na archivaci dat
Optimalizace nákladů automatickou správou životního cyklu dat