Kurz: Implementace vzoru zachycení data lake za účelem aktualizace tabulky Databricks Delta
V tomto kurzu se dozvíte, jak zpracovávat události v účtu úložiště, který má hierarchický obor názvů.
Vytvoříte malé řešení, které uživateli umožní naplnit tabulku Databricks Delta tak, že nahrajete soubor hodnot oddělených čárkami (CSV), který popisuje prodejní objednávku. Toto řešení vytvoříte propojením předplatného Event Gridu, funkce Azure a úlohy v Azure Databricks.
V tomto kurzu:
- Vytvořte odběr služby Event Grid, který volá funkci Azure Functions.
- Vytvořte funkci Azure, která obdrží oznámení z události a pak spustí úlohu v Azure Databricks.
- Vytvořte úlohu Databricks, která vloží objednávku zákazníka do tabulky Databricks Delta, která se nachází v účtu úložiště.
Toto řešení sestavíme v obráceném pořadí počínaje pracovním prostorem Azure Databricks.
Požadavky
Vytvořte účet úložiště, který má hierarchický obor názvů (Azure Data Lake Storage). Tento kurz používá účet úložiště s názvem
contosoorders.Viz Vytvoření účtu úložiště pro použití se službou Azure Data Lake Storage.
Ujistěte se, že má váš uživatelský účet přiřazenou roli Přispěvatel dat objektů blob služby Storage.
Vytvořte instanční objekt, vytvořte tajný klíč klienta a pak udělte instančnímu objektu přístup k účtu úložiště.
Viz kurz: Připojení ke službě Azure Data Lake Storage (kroky 1 až 3). Po dokončení těchto kroků nezapomeňte do textového souboru vložit ID tenanta, ID aplikace a tajné hodnoty klienta. Brzy je budete potřebovat.
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Vytvořit prodejní objednávku
Nejprve vytvořte soubor CSV, který popisuje prodejní objednávku, a pak tento soubor nahrajte do účtu úložiště. Později použijete data z tohoto souboru k naplnění prvního řádku v tabulce Databricks Delta.
Na webu Azure Portal přejděte k novému účtu úložiště.
Vyberte kontejner Storage browser-Blob-Add>> a vytvořte nový kontejner s názvem data.
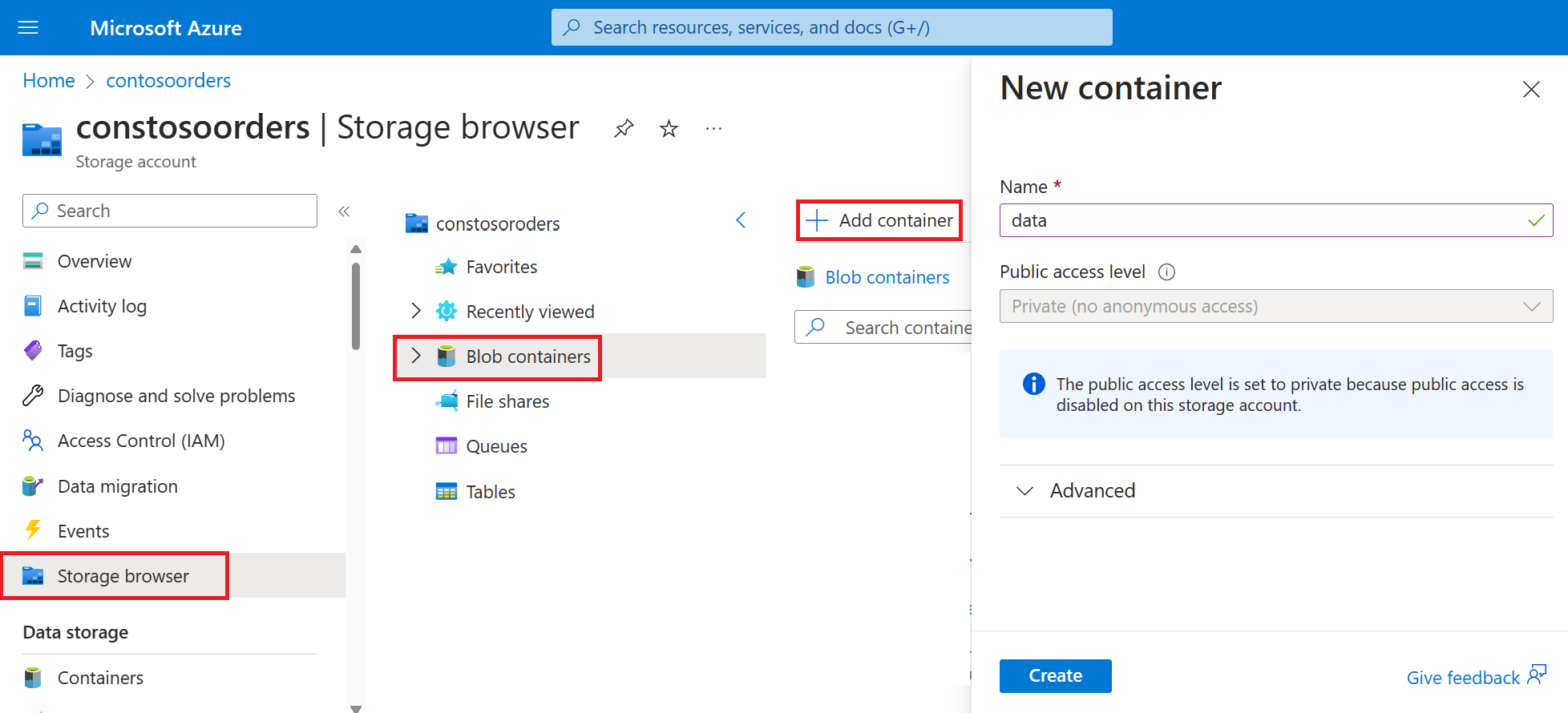
V kontejneru dat vytvořte adresář pojmenovaný vstup.
Do textového editoru vložte následující text.
InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536365,85123A,WHITE HANGING HEART T-LIGHT HOLDER,6,12/1/2010 8:26,2.55,17850,United KingdomUložte tento soubor do místního počítače a pojmenujte ho data.csv.
V prohlížeči úložiště nahrajte tento soubor do vstupní složky.
Vytvoření úlohy v Azure Databricks
V této části provedete tyto úlohy:
- Vytvořte pracovní prostor Azure Databricks.
- Vytvořte poznámkový blok.
- Vytvoření a naplnění tabulky Databricks Delta
- Přidejte kód, který vloží řádky do tabulky Databricks Delta.
- Vytvořte úlohu.
Vytvoření pracovního prostoru Azure Databricks
V této části vytvoříte pomocí portálu Azure pracovní prostor služby Azure Databricks.
Vytvořte pracovní prostor Azure Databricks. Pojmenujte tento pracovní prostor
contoso-orders. Viz Vytvoření pracovního prostoru Azure Databricks.Vytvořte cluster. Pojmenujte cluster
customer-order-cluster. Viz Vytvoření clusteru.Vytvořte poznámkový blok. Pojmenujte poznámkový blok
configure-customer-tablea jako výchozí jazyk poznámkového bloku zvolte Python. Viz Vytvoření poznámkového bloku.
Vytvoření a naplnění tabulky Databricks Delta
V poznámkovém bloku, který jste vytvořili, zkopírujte a vložte následující blok kódu do první buňky, ale tento kód ještě nespustit.
appIdNahraďte zástupné hodnoty vpasswordtenanttomto bloku kódu hodnotami, které jste shromáždili při dokončování požadavků tohoto kurzu.dbutils.widgets.text('source_file', "", "Source File") spark.conf.set("fs.azure.account.auth.type", "OAuth") spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider") spark.conf.set("fs.azure.account.oauth2.client.id", "<appId>") spark.conf.set("fs.azure.account.oauth2.client.secret", "<password>") spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com/<tenant>/oauth2/token") adlsPath = 'abfss://data@contosoorders.dfs.core.windows.net/' inputPath = adlsPath + dbutils.widgets.get('source_file') customerTablePath = adlsPath + 'delta-tables/customers'Tento kód vytvoří widget s názvem source_file. Později vytvoříte funkci Azure Functions, která tento kód zavolá a předá do tohoto widgetu cestu k souboru. Tento kód také ověřuje instanční objekt pomocí účtu úložiště a vytvoří některé proměnné, které použijete v jiných buňkách.
Poznámka:
V produkčním nastavení zvažte uložení ověřovacího klíče v Azure Databricks. Pak místo ověřovacího klíče přidejte do bloku kódu vyhledávací klíč.
Například místo použití tohoto řádku kódu:spark.conf.set("fs.azure.account.oauth2.client.secret", "<password>"), byste použili následující řádek kódu:spark.conf.set("fs.azure.account.oauth2.client.secret", dbutils.secrets.get(scope = "<scope-name>", key = "<key-name-for-service-credential>")).
Po dokončení tohoto kurzu se podívejte na článek Azure Data Lake Storage na webu Azure Databricks a podívejte se na příklady tohoto přístupu.Stisknutím kláves SHIFT + ENTER spusťte kód v tomto bloku.
Zkopírujte a vložte následující blok kódu do jiné buňky a stisknutím kláves SHIFT+ENTER kód spusťte v tomto bloku.
from pyspark.sql.types import StructType, StructField, DoubleType, IntegerType, StringType inputSchema = StructType([ StructField("InvoiceNo", IntegerType(), True), StructField("StockCode", StringType(), True), StructField("Description", StringType(), True), StructField("Quantity", IntegerType(), True), StructField("InvoiceDate", StringType(), True), StructField("UnitPrice", DoubleType(), True), StructField("CustomerID", IntegerType(), True), StructField("Country", StringType(), True) ]) rawDataDF = (spark.read .option("header", "true") .schema(inputSchema) .csv(adlsPath + 'input') ) (rawDataDF.write .mode("overwrite") .format("delta") .saveAsTable("customer_data", path=customerTablePath))Tento kód vytvoří tabulku Databricks Delta ve vašem účtu úložiště a pak načte některá počáteční data ze souboru CSV, který jste nahráli dříve.
Po úspěšném spuštění tohoto bloku kódu odeberte tento blok kódu z poznámkového bloku.
Přidání kódu, který vloží řádky do tabulky Databricks Delta
Zkopírujte a vložte následující blok kódu do jiné buňky, ale tuto buňku nespustíte.
upsertDataDF = (spark .read .option("header", "true") .csv(inputPath) ) upsertDataDF.createOrReplaceTempView("customer_data_to_upsert")Tento kód vloží data do dočasného zobrazení tabulky pomocí dat ze souboru CSV. Cesta k danému souboru CSV pochází ze vstupního widgetu, který jste vytvořili v předchozím kroku.
Zkopírujte a vložte následující blok kódu do jiné buňky. Tento kód sloučí obsah dočasného zobrazení tabulky s tabulkou Databricks Delta.
%sql MERGE INTO customer_data cd USING customer_data_to_upsert cu ON cd.CustomerID = cu.CustomerID WHEN MATCHED THEN UPDATE SET cd.StockCode = cu.StockCode, cd.Description = cu.Description, cd.InvoiceNo = cu.InvoiceNo, cd.Quantity = cu.Quantity, cd.InvoiceDate = cu.InvoiceDate, cd.UnitPrice = cu.UnitPrice, cd.Country = cu.Country WHEN NOT MATCHED THEN INSERT (InvoiceNo, StockCode, Description, Quantity, InvoiceDate, UnitPrice, CustomerID, Country) VALUES ( cu.InvoiceNo, cu.StockCode, cu.Description, cu.Quantity, cu.InvoiceDate, cu.UnitPrice, cu.CustomerID, cu.Country)
Vytvoření úlohy
Vytvořte úlohu, která spouští poznámkový blok, který jste vytvořili dříve. Později vytvoříte funkci Azure Functions, která spustí tuto úlohu při vyvolání události.
Vyberte Novou> úlohu.
Pojmenujte úlohu a zvolte poznámkový blok, který jste vytvořili a cluster. Pak vyberte Vytvořit a vytvořte úlohu.
Vytvoření funkce Azure
Vytvořte funkci Azure, která spouští úlohu.
V pracovním prostoru Azure Databricks klikněte na své uživatelské jméno Azure Databricks v horním panelu a pak v rozevíracím seznamu vyberte Uživatelská nastavení.
Na kartě Přístupové tokeny vyberte Vygenerovat nový token.
Zkopírujte token, který se zobrazí, a potom klepněte na tlačítko Hotovo.
V horním rohu pracovního prostoru Databricks zvolte ikonu lidé a pak zvolte Uživatelská nastavení.

Vyberte tlačítko Generovat nový token a pak vyberte tlačítko Generovat.
Nezapomeňte token zkopírovat na bezpečné místo. Vaše funkce Azure Functions potřebuje tento token k ověření pomocí Databricks, aby mohl spustit úlohu.
V nabídce webu Azure Portal nebo na domovské stránce vyberte Vytvořit prostředek.
Na stránce Nový vyberte Aplikaci výpočetních>funkcí.
Na kartě Základy na stránce Vytvořit aplikaci funkcí zvolte skupinu prostředků a pak změňte nebo ověřte následující nastavení:
Nastavení Hodnota Název aplikace funkcí contosoorder Zásobník modulu runtime .NET Publikovat Kód Operační systém Windows Typ plánu Využití (bez serverů) Vyberte položku Zkontrolovat + vytvořit a potom vyberte Vytvořit.
Po dokončení nasazení vyberte Přejít k prostředku a otevřete stránku přehledu aplikace funkcí.
Ve skupině Nastavení vyberte Možnost Konfigurace.
Na stránce Nastavení aplikace zvolte tlačítko Nové nastavení aplikace a přidejte každé nastavení.

Přidejte následující nastavení:
Název nastavení Hodnota DBX_INSTANCE Oblast pracovního prostoru Databricks Příklad: westus2.azuredatabricks.netDBX_PAT Token patu, který jste vygenerovali dříve. DBX_JOB_ID Identifikátor spuštěné úlohy. Výběrem možnosti Uložit potvrďte tato nastavení.
Ve skupině Functions vyberte Funkce a pak vyberte Vytvořit.
Zvolte trigger služby Azure Event Grid.
Pokud se zobrazí výzva, nainstalujte rozšíření Microsoft.Azure.WebJobs.Extensions.EventGrid. Pokud ho potřebujete nainstalovat, budete muset znovu zvolit trigger služby Azure Event Grid, abyste funkci vytvořili.
Zobrazí se podokno Nová funkce .
V podokně Nová funkce pojmenujte funkci UpsertOrder a pak vyberte tlačítko Vytvořit.
Nahraďte obsah souboru kódu tímto kódem a pak vyberte tlačítko Uložit :
#r "Azure.Messaging.EventGrid" #r "System.Memory.Data" #r "Newtonsoft.Json" #r "System.Text.Json" using Azure.Messaging.EventGrid; using Azure.Messaging.EventGrid.SystemEvents; using Newtonsoft.Json; using Newtonsoft.Json.Linq; private static HttpClient httpClient = new HttpClient(); public static async Task Run(EventGridEvent eventGridEvent, ILogger log) { log.LogInformation("Event Subject: " + eventGridEvent.Subject); log.LogInformation("Event Topic: " + eventGridEvent.Topic); log.LogInformation("Event Type: " + eventGridEvent.EventType); log.LogInformation(eventGridEvent.Data.ToString()); if (eventGridEvent.EventType == "Microsoft.Storage.BlobCreated" || eventGridEvent.EventType == "Microsoft.Storage.FileRenamed") { StorageBlobCreatedEventData fileData = eventGridEvent.Data.ToObjectFromJson<StorageBlobCreatedEventData>(); if (fileData.Api == "FlushWithClose") { log.LogInformation("Triggering Databricks Job for file: " + fileData.Url); var fileUrl = new Uri(fileData.Url); var httpRequestMessage = new HttpRequestMessage { Method = HttpMethod.Post, RequestUri = new Uri(String.Format("https://{0}/api/2.0/jobs/run-now", System.Environment.GetEnvironmentVariable("DBX_INSTANCE", EnvironmentVariableTarget.Process))), Headers = { { System.Net.HttpRequestHeader.Authorization.ToString(), "Bearer " + System.Environment.GetEnvironmentVariable("DBX_PAT", EnvironmentVariableTarget.Process)}, { System.Net.HttpRequestHeader.ContentType.ToString(), "application/json" } }, Content = new StringContent(JsonConvert.SerializeObject(new { job_id = System.Environment.GetEnvironmentVariable("DBX_JOB_ID", EnvironmentVariableTarget.Process), notebook_params = new { source_file = String.Join("", fileUrl.Segments.Skip(2)) } })) }; var response = await httpClient.SendAsync(httpRequestMessage); response.EnsureSuccessStatusCode(); } } }
Tento kód analyzuje informace o události úložiště, která byla vyvolána, a pak vytvoří zprávu požadavku s adresou URL souboru, který událost aktivoval. V rámci zprávy funkce předá hodnotu do widgetu source_file , který jste vytvořili dříve. Kód funkce odešle zprávu do úlohy Databricks a použije token, který jste získali dříve jako ověřování.
Vytvoření odběru Event Gridu
V této části vytvoříte odběr služby Event Grid, který zavolá funkci Azure Functions při nahrání souborů do účtu úložiště.
Vyberte Možnost Integrace a pak na stránce Integrace vyberte Trigger event Gridu.
V podokně Upravit aktivační událost pojmenujte událost
eventGridEventa pak vyberte Vytvořit odběr události.Poznámka:
Název
eventGridEventodpovídá parametru, který se předává do funkce Azure Functions.Na kartě Základy na stránce Vytvořit odběr události změňte nebo ověřte následující nastavení:
Nastavení Hodnota Name contoso-order-event-subscription Typ tématu Účet úložiště Zdrojový prostředek contosoorders Název systémového tématu <create any name>Filtrovat na typy událostí Vytvoření objektu blob a odstranění objektu blob Vyberte tlačítko Vytvořit.
Testování odběru Event Gridu
Vytvořte soubor s názvem
customer-order.csv, vložte do něj následující informace a uložte ho do místního počítače.InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536371,99999,EverGlow Single,228,1/1/2018 9:01,33.85,20993,Sierra LeoneV Průzkumník služby Storage nahrajte tento soubor do vstupní složky vašeho účtu úložiště.
Nahrání souboru vyvolá událost Microsoft.Storage.BlobCreated . Event Grid upozorní všechny odběratele na tuto událost. V našem případě je funkce Azure Functions jediným předplatitelem. Funkce Azure analyzuje parametry události a určí, ke které události došlo. Pak předá adresu URL souboru do úlohy Databricks. Úloha Databricks načte soubor a přidá řádek do tabulky Databricks Delta, která se nachází ve vašem účtu úložiště.
Pokud chcete zkontrolovat, jestli úloha proběhla úspěšně, prohlédněte si spuštění vaší úlohy. Zobrazí se stav dokončení. Další informace o zobrazení spuštění pro úlohu najdete v tématu Zobrazení spuštění úlohy.
V nové buňce sešitu spusťte tento dotaz v buňce, aby se zobrazila aktualizovaná rozdílová tabulka.
%sql select * from customer_dataVrácená tabulka zobrazuje nejnovější záznam.

Pokud chcete tento záznam aktualizovat, vytvořte soubor s názvem
customer-order-update.csv, vložte do něj následující informace a uložte ho do místního počítače.InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536371,99999,EverGlow Single,22,1/1/2018 9:01,33.85,20993,Sierra LeoneTento soubor CSV je téměř shodný s předchozím souborem, s výjimkou množství objednávky se změní z
228na22.V Průzkumník služby Storage nahrajte tento soubor do vstupní složky vašeho účtu úložiště.
selectSpusťte dotaz znovu, aby se zobrazila aktualizovaná rozdílová tabulka.%sql select * from customer_dataVrácená tabulka zobrazuje aktualizovaný záznam.

Vyčištění prostředků
Pokud už nejsou potřeba, odstraňte skupinu prostředků a všechny související prostředky. Uděláte to tak, že vyberete skupinu prostředků pro účet úložiště a vyberete Odstranit.