Azure Data Lake Storage zrychlení dotazů
Akcelerace dotazů umožňuje aplikacím a analytickým architekturám výrazně optimalizovat zpracování dat tím, že načtou jenom data, která potřebují k provedení dané operace. Tím se zkrátí čas a výpočetní výkon, který je potřeba k získání důležitého přehledu o uložených datech.
Přehled
Akcelerace dotazů přijímá predikáty filtrování a projekce sloupců, které aplikacím umožňují filtrovat řádky a sloupce v době, kdy se data čtou z disku. Přes síť se do aplikace přenášejí pouze data, která splňují podmínky predikátu. Tím se sníží latence sítě a náklady na výpočetní prostředky.
Sql můžete použít k určení predikátů filtru řádků a projekcí sloupců v požadavku na zrychlení dotazu. Požadavek zpracovává pouze jeden soubor. Proto se nepodporují pokročilé relační funkce SQL, jako jsou spojení a seskupení podle agregací. Akcelerace dotazů podporuje data ve formátu CSV a JSON jako vstup pro každý požadavek.
Funkce akcelerace dotazů není omezená na Data Lake Storage (účty úložiště, u kterých je povolený hierarchický obor názvů). Akcelerace dotazů je kompatibilní s objekty blob v účtech úložiště, u kterých není povolený hierarchický obor názvů. To znamená, že při zpracování dat, která už máte uložená jako objekty blob v účtech úložiště, můžete dosáhnout stejného snížení latence sítě a nákladů na výpočetní prostředky.
Příklad použití akcelerace dotazů v klientské aplikaci najdete v tématu Filtrování dat pomocí Azure Data Lake Storage zrychlení dotazů.
Tok dat
Následující diagram znázorňuje, jak typická aplikace používá akceleraci dotazů ke zpracování dat.
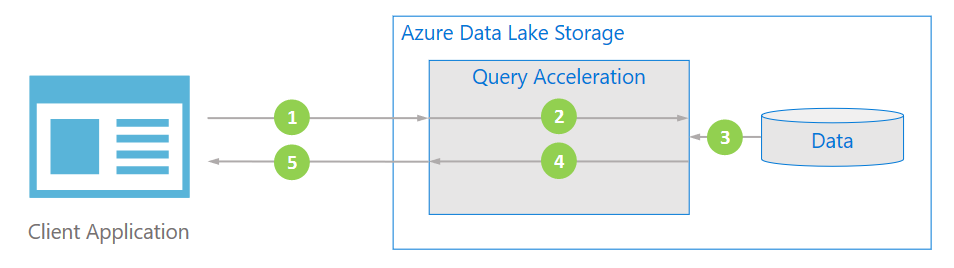
Klientská aplikace požaduje data souboru zadáním predikátů a projekcí sloupců.
Akcelerace dotazů parsuje zadaný dotaz SQL a distribuuje práci na parsování a filtrování dat.
Procesory načtou data z disku, parsují data pomocí příslušného formátu a pak filtrují data použitím zadaných predikátů a projekcí sloupců.
Akcelerace dotazů kombinuje horizontální oddíly odpovědí a streamuje zpět do klientské aplikace.
Klientská aplikace přijímá a parsuje streamovanou odpověď. Aplikace nemusí filtrovat žádná další data a může použít požadovaný výpočet nebo transformaci přímo.
Lepší výkon při nižších nákladech
Akcelerace dotazů optimalizuje výkon tím, že snižuje množství dat přenášených a zpracovávaných vaší aplikací.
Při výpočtu agregované hodnoty aplikace obvykle načítají všechna data ze souboru a pak je místně zpracovávají a filtrují. Z analýzy vstupních a výstupních vzorů analytických úloh vyplývá, že aplikace obvykle k provedení výpočtu vyžadují pouze 20 % dat, která načtou. Tato statistika platí i po použití technik, jako je vyřezávání oddílů. To znamená, že 80 % těchto dat je zbytečně přenášeno přes síť, analyzováno a filtrováno aplikacemi. Tento model, navržený tak, aby odebral nepotřebná data, nese značné náklady na výpočetní prostředky.
I když Azure nabízí špičkovou síť, z hlediska propustnosti i latence je zbytečný přenos dat v této síti stále nákladný z hlediska výkonu aplikací. Díky vyfiltrování nežádoucích dat během požadavku na úložiště se tyto náklady eliminují akcelerací dotazů.
Kromě toho zatížení procesoru, které je nutné k analýze a filtrování nepotřebných dat, vyžaduje, aby vaše aplikace zřídila větší počet a větší virtuální počítače, aby mohla pracovat. Přenosem tohoto výpočetního zatížení do akcelerace dotazů můžou aplikace dosáhnout výrazných úspor nákladů.
Aplikace, které můžou těžit z akcelerace dotazů
Akcelerace dotazů je určená pro distribuované analytické architektury a aplikace pro zpracování dat.
Distribuované analytické architektury, jako jsou Apache Spark a Apache Hive, obsahují v rámci architektury vrstvu abstrakce úložiště. Tyto moduly také zahrnují optimalizátory dotazů, které mohou při určování optimálního plánu dotazů pro uživatelské dotazy začlenit znalosti o možnostech základní vstupně-výstupní služby. Tato rozhraní začínají integrovat akceleraci dotazů. V důsledku toho uživatelé těchto architektur uvidí vyšší latenci dotazů a nižší celkové náklady na vlastnictví, aniž by museli provádět jakékoli změny dotazů.
Akcelerace dotazů je také určená pro aplikace zpracování dat. Tyto typy aplikací obvykle provádějí rozsáhlé transformace dat, které nemusí přímo vést k analytickým přehledům, takže nemusí vždy používat zavedené architektury distribuovaných analýz. Tyto aplikace mají často přímější vztah se základní službou úložiště, takže můžou přímo využívat funkce, jako je akcelerace dotazů.
Příklad toho, jak může aplikace integrovat akceleraci dotazů, najdete v tématu Filtrování dat pomocí Azure Data Lake Storage zrychlení dotazů.
Ceny
Vzhledem ke zvýšenému výpočetnímu zatížení v rámci služby Azure Data Lake Storage se cenový model pro použití akcelerace dotazů liší od normálního Azure Data Lake Storage transakčního modelu. Akcelerace dotazů účtuje náklady na množství kontrolovaných dat a také náklady na množství dat vrácených volajícímu. Další informace najdete v tématu o cenách Azure Data Lake Storage Gen2.
Bez ohledu na změnu fakturačního modelu je cenový model zrychlení dotazů navržený tak, aby snížil celkové náklady na vlastnictví úlohy, a to s ohledem na snížení mnohem dražších nákladů na virtuální počítače.