Kurz: Optimalizace indexování pomocí rozhraní PUSH API
Azure AI Search podporuje dva základní přístupy k importu dat do indexu vyhledávání: nasdílení dat do indexu prostřednictvím kódu programu nebo načtení dat nasměrováním indexeru Azure AI Search na podporovaný zdroj dat.
V tomto kurzu se dozvíte, jak efektivně indexovat data pomocí modelu nabízení pomocí dávkových požadavků a použití exponenciální strategie opakování opakování. Ukázkovou aplikaci si můžete stáhnout a spustit. Tento článek vysvětluje klíčové aspekty aplikace a faktory, které je potřeba vzít v úvahu při indexování dat.
Tento kurz používá jazyk C# a knihovnu Azure.Search.Documents ze sady Azure SDK pro .NET k provádění následujících úloh:
- Vytvoření indexu
- Otestujte různé velikosti dávek, abyste zjistili nejúčinnější velikost.
- Asynchronně indexové dávky
- Použití více vláken ke zvýšení rychlosti indexování
- Použití exponenciální strategie opakování opakování k opakování neúspěšných dokumentů
Požadavky
Pro účely tohoto kurzu jsou vyžadovány následující služby a nástroje.
Předplatné Azure. Pokud žádné nemáte, můžete si vytvořit bezplatný účet.
Visual Studio, libovolná edice Vzorový kód a pokyny byly testovány na bezplatné edici Community.
Stažení souborů
Zdrojový kód pro tento kurz je ve složce optimize-data-indexing/v11 v úložišti GitHub Azure-Samples/azure-search-dotnet-scale .
Klíčové aspekty
Dále jsou uvedeny faktory, které ovlivňují rychlost indexování. Další informace najdete v tématu Indexování velkých datových sad.
- Úroveň služby a počet oddílů/replik: Přidání oddílů nebo upgrade úrovně zvyšuje rychlost indexování.
- Složitost schématu indexu: Přidávání polí a vlastností polí snižuje rychlost indexování. Menší indexy jsou rychlejší k indexování.
- Velikost dávky: Optimální velikost dávky se liší podle schématu indexu a datové sady.
- Počet vláken/pracovních procesů: Jedno vlákno nevyužívá plnou výhodu rychlosti indexování.
- Strategie opakování: Strategie opakování exponenciálního opakování je osvědčeným postupem pro optimální indexování.
- Rychlost přenosu dat v síti: Rychlost přenosu dat může být omezujícím faktorem. Indexujte data z prostředí Azure, abyste zvýšili rychlost přenosu dat.
Krok 1: Vytvoření Search Azure AI
K dokončení tohoto kurzu potřebujete Search Azure AI, kterou můžete vytvořit na webu Azure Portal nebo ve svém aktuálním předplatném najít existující službu. Doporučujeme použít stejnou úroveň, kterou plánujete použít v produkčním prostředí, abyste mohli přesně testovat a optimalizovat rychlost indexování.
Získání klíče správce a adresy URL služby Azure AI Search
V tomto kurzu se používá ověřování založené na klíčích. Zkopírujte klíč rozhraní API správce a vložte ho do souboru appsettings.json .
Přihlaste se k portálu Azure. Získejte adresu URL koncového bodu ze stránky Přehled vyhledávací služby. Příkladem koncového bodu může být
https://mydemo.search.windows.net.V části Klíče nastavení>získejte klíč správce pro úplná práva ke službě. Existují dva zaměnitelné klíče správce, které jsou k dispozici pro zajištění kontinuity podnikových procesů v případě, že potřebujete jeden převést. Primární nebo sekundární klíč můžete použít u požadavků pro přidávání, úpravy a odstraňování objektů.
Krok 2: Nastavení prostředí
Spusťte Visual Studio a otevřete OptimizeDataIndexing.sln.
V Průzkumník řešení otevřete appsettings.json a zadejte informace o připojení vaší služby.
{
"SearchServiceUri": "https://{service-name}.search.windows.net",
"SearchServiceAdminApiKey": "",
"SearchIndexName": "optimize-indexing"
}
Krok 3: Prozkoumání kódu
Po aktualizaci appsettings.json by měl být ukázkový program v OptimizeDataIndexing.sln připravený k sestavení a spuštění.
Tento kód je odvozený z části Rychlý start jazyka C#: Fulltextové vyhledávání pomocí sad Azure SDK. Podrobnější informace o základech práce se sadou .NET SDK najdete v tomto článku.
Tato jednoduchá konzolová aplikace C#/.NET provádí následující úlohy:
- Vytvoří nový index založený na datové struktuře třídy C#
Hotel(která také odkazuje naAddresstřídu). - Testuje různé velikosti dávek, aby bylo možné určit nejúčinnější velikost.
- Indexuje data asynchronně.
- Zvýšení rychlosti indexování pomocí více vláken
- Použití exponenciální strategie opakování opakování k opakování neúspěšných položek
Než program spustíte, prostudujte si kód a definice indexu pro tuto ukázku. Příslušný kód je v několika souborech:
- Hotel.cs a Address.cs obsahují schéma definující index.
- DataGenerator.cs obsahuje jednoduchou třídu, která usnadňuje vytváření velkých objemů hotelových dat.
- ExponentialBackoff.cs obsahuje kód pro optimalizaci procesu indexování, jak je popsáno v tomto článku.
- Program.cs obsahuje funkce, které vytvářejí a odstraňuje index služby Azure AI Search, indexuje dávky dat a testuje různé velikosti dávek.
Vytvoření indexu
Tento ukázkový program používá sadu Azure SDK pro .NET k definování a vytvoření indexu Azure AI Search. Využívá třídu FieldBuilder k vygenerování struktury indexu z třídy datového modelu jazyka C#.
Datový model je definován Hotel třídou, která obsahuje také odkazy na Address třídu. FieldBuilder přejde k podrobnostem prostřednictvím více definic tříd a vygeneruje složitou datovou strukturu indexu. Značky metadat slouží k definování atributů jednotlivých polí, jako je například to, jestli je prohledávatelné nebo řaditelné.
Následující fragmenty kódu ze souboru Hotel.cs ukazují, jak lze zadat jedno pole a odkaz na jinou třídu datového modelu.
. . .
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
. . .
public Address Address { get; set; }
. . .
V souboru Program.cs je index definován s názvem a kolekcí polí vygenerovanou FieldBuilder.Build(typeof(Hotel)) metodou a pak vytvořen následujícím způsobem:
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address class is referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
Generovat data
Jednoduchá třída je implementována v souboru DataGenerator.cs pro generování dat pro testování. Jediným účelem této třídy je usnadnit generování velkého počtu dokumentů s jedinečným ID pro indexování.
Pokud chcete získat seznam 100 000 hotelů s jedinečnými ID, spusťte následující řádky kódu:
long numDocuments = 100000;
DataGenerator dg = new DataGenerator();
List<Hotel> hotels = dg.GetHotels(numDocuments, "large");
Pro testování v této ukázce jsou k dispozici dvě velikosti hotelů: malé a velké.
Schéma indexu má vliv na rychlosti indexování. Z tohoto důvodu dává smysl převést tuto třídu tak, aby generovala data, která nejlépe odpovídají zamýšlenému schématu indexu po spuštění tohoto kurzu.
Krok 4: Testování velikostí dávek
Azure AI Search podporuje následující rozhraní API pro načtení jednoho nebo více dokumentů do indexu:
Indexování dokumentů v dávkách výrazně zvyšuje výkon indexování. Tyto dávky můžou být až 1 000 dokumentů nebo přibližně 16 MB na dávku.
Určení optimální velikosti dávky pro vaše data je klíčovou součástí optimalizace rychlosti indexování. Optimální velikost dávky ovlivňují dva primární faktory:
- Schéma indexu
- Velikost dat
Vzhledem k tomu, že optimální velikost dávky závisí na indexu a vašich datech, nejlepším přístupem je otestovat různé velikosti dávek, abyste zjistili, jaké výsledky mají pro váš scénář nejrychlejší rychlost indexování.
Následující funkce ukazuje jednoduchý přístup k testování velikostí dávek.
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
Vzhledem k tomu, že ne všechny dokumenty mají stejnou velikost (i když jsou v této ukázce), odhadujeme velikost dat, která odesíláme do vyhledávací služby. Můžete to provést pomocí následující funkce, která nejprve převede objekt na json a pak určí jeho velikost v bajtech. Tato technika nám umožňuje určit, které velikosti dávek jsou nejúčinnější z hlediska rychlosti indexování MB/s.
// Returns size of object in MB
public static double EstimateObjectSize(object data)
{
// converting object to byte[] to determine the size of the data
BinaryFormatter bf = new BinaryFormatter();
MemoryStream ms = new MemoryStream();
byte[] Array;
// converting data to json for more accurate sizing
var json = JsonSerializer.Serialize(data);
bf.Serialize(ms, json);
Array = ms.ToArray();
// converting from bytes to megabytes
double sizeInMb = (double)Array.Length / 1000000;
return sizeInMb;
}
Funkce vyžaduje SearchClient plus počet pokusů, které chcete otestovat pro každou velikost dávky. Vzhledem k tomu, že pro každou dávku může být proměnlivost časů indexování, vyzkoušejte ve výchozím nastavení každou dávku třikrát, aby výsledky byly statisticky významnější.
await TestBatchSizesAsync(searchClient, numTries: 3);
Při spuštění funkce by se měl v konzole zobrazit výstup podobný následujícímu příkladu:
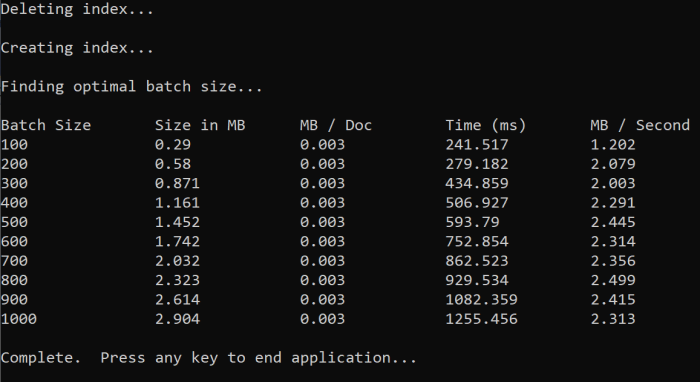
Určete, která velikost dávky je nejúčinnější, a pak tuto velikost dávky použijte v dalším kroku kurzu. V různých velikostech dávek se může zobrazit plateau v MB/s.
Krok 5: Indexování dat
Teď, když jste identifikovali velikost dávky, kterou chcete použít, je dalším krokem začít indexovat data. Pokud chcete efektivně indexovat data, tato ukázka:
- používá více vláken nebo pracovních procesů.
- implementuje exponenciální strategii opakování opakování.
Odkomentujte řádky 41 až 49 a spusťte program znovu. Při tomto spuštění ukázka vygeneruje a odesílá dávky dokumentů, až 100 000, pokud kód spustíte beze změny parametrů.
Použití více vláken nebo pracovních procesů
Pokud chcete využít plné výhody rychlosti indexování služby Azure AI Search, použijte více vláken k souběžnému odesílání žádostí o dávkové indexování do služby.
Několik klíčových aspektů, které jsme zmínili dříve, může ovlivnit optimální počet vláken. Tuto ukázku a testování můžete upravit s různými počty vláken, abyste zjistili optimální počet vláken pro váš scénář. Pokud ale máte spuštěných několik vláken současně, měli byste být schopni využít výhod většiny zvýšení efektivity.
Při zprovoznění požadavků do vyhledávací služby můžete narazit na stavové kódy HTTP, které značí, že požadavek nebyl plně úspěšný. Během indexování jsou dva běžné stavové kódy HTTP:
- 503 Služba není k dispozici: Tato chyba znamená, že systém je zatížený velkým zatížením a v tuto chvíli nelze vaši žádost zpracovat.
- 207 Multi-Status: Tato chyba znamená, že některé dokumenty byly úspěšné, ale alespoň jeden selhal.
Implementace strategie opakování exponenciálního zpožování
Pokud dojde k selhání, měly by se žádosti opakovat pomocí strategie exponenciálního opakování opakování.
Sada .NET SDK služby Azure AI Search automaticky opakuje pokusy o 503 a dalších neúspěšných požadavků, ale měli byste implementovat vlastní logiku pro opakování 207s. Opensourcové nástroje, jako je Polly , můžou být užitečné ve strategii opakování.
V této ukázce implementujeme vlastní strategii opakování exponenciálního opakování. Začneme definováním některých proměnných, včetně maxRetryAttempts a iniciály delay neúspěšného požadavku:
// Create batch of documents for indexing
var batch = IndexDocumentsBatch.Upload(hotels);
// Create an object to hold the result
IndexDocumentsResult result = null;
// Define parameters for exponential backoff
int attempts = 0;
TimeSpan delay = delay = TimeSpan.FromSeconds(2);
int maxRetryAttempts = 5;
Výsledky operace indexování jsou uloženy v proměnné IndexDocumentResult result. Tato proměnná je důležitá, protože umožňuje zkontrolovat, jestli některé dokumenty v dávce selhaly, jak je znázorněno v následujícím příkladu. Pokud dojde k částečnému selhání, vytvoří se nová dávka na základě ID neúspěšných dokumentů.
RequestFailedException Výjimky by také měly být zachyceny, protože indikují, že žádost selhala úplně a měla by se také opakovat.
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
Odsud zabalte exponenciální backoff kód do funkce, aby se dala snadno volat.
Pak se vytvoří další funkce pro správu aktivních vláken. Pro zjednodušení není tato funkce zahrnutá, ale najdete ji v ExponentialBackoff.cs. Funkci lze volat pomocí následujícího příkazu, kde jsou data, která hotels chcete nahrát, 1000 je velikost dávky a 8 je počet souběžných vláken:
await ExponentialBackoff.IndexData(indexClient, hotels, 1000, 8);
Při spuštění funkce by se měl zobrazit výstup:
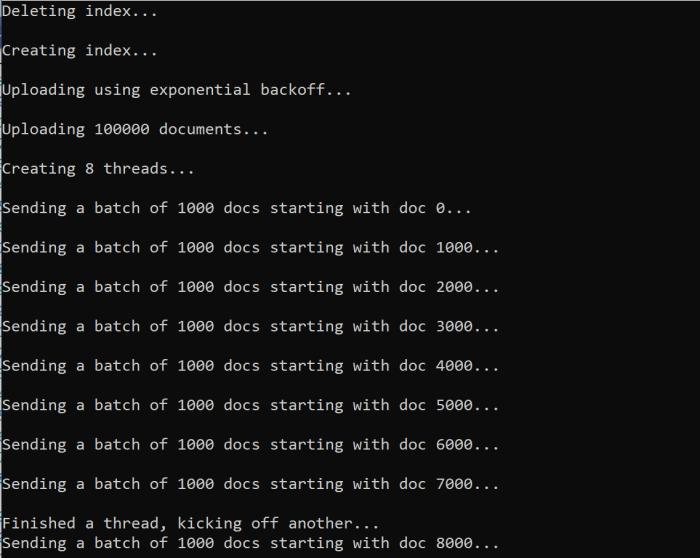
Pokud dávka dokumentů selže, vytiskne se chyba, která značí selhání a že se dávka opakuje:
[Batch starting at doc 6000 had partial failure]
[Retrying 560 failed documents]
Po dokončení funkce můžete ověřit, že všechny dokumenty byly přidány do indexu.
Krok 6: Prozkoumání indexu
Vyplněný index vyhledávání můžete prozkoumat po spuštění programu nebo pomocí Průzkumníka služby Search na webu Azure Portal.
Programově
Existují dvě hlavní možnosti pro kontrolu počtu dokumentů v indexu: rozhraní API Count Documents a rozhraní API pro získání statistik indexu. Obě cesty vyžadují čas na zpracování, takže pokud je vrácený počet vrácených dokumentů zpočátku nižší, než očekáváte.
Počet dokumentů
Operace Count Documents načte počet dokumentů v indexu vyhledávání:
long indexDocCount = await searchClient.GetDocumentCountAsync();
Získání statistik indexu
Operace Získat statistiku indexu vrátí počet dokumentů pro aktuální index a využití úložiště. Aktualizace statistik indexu trvá déle než počet dokumentů.
var indexStats = await indexClient.GetIndexStatisticsAsync(indexName);
portál Azure
Na webu Azure Portal v levém navigačním podokně vyhledejte indexování optimalizace v seznamu Indexy .

Počet dokumentů a velikost úložiště jsou založené na rozhraní API pro získání statistik indexu a aktualizace může trvat několik minut.
Resetování a opětovné spuštění
V počátečních experimentálních fázích vývoje je nejproktičtějším přístupem k iteraci návrhu odstranit objekty z Azure AI Search a umožnit kódu jejich opětovné sestavení. Názvy prostředků jsou jedinečné. Když se objekt odstraní, je možné ho znovu vytvořit se stejným názvem.
Vzorový kód pro tento kurz zkontroluje existující indexy a odstraní je, abyste mohli znovu spustit kód.
Indexy můžete odstranit také pomocí webu Azure Portal.
Vyčištění prostředků
Když pracujete ve vlastním předplatném, je na konci projektu vhodné odebrat prostředky, které už nepotřebujete. Prostředky, které necháte spuštěné, vás stojí peníze. Prostředky můžete odstraňovat jednotlivě nebo můžete odstranit skupinu prostředků, a odstranit tak celou sadu prostředků najednou.
Prostředky můžete najít a spravovat na webu Azure Portal pomocí odkazu Všechny prostředky nebo skupiny prostředků v levém navigačním podokně.
Další krok
Další informace o indexování velkých objemů dat najdete v následujícím kurzu.