Analýza výkonu ve službě Azure AI Search
Tento článek popisuje nástroje, chování a přístupy k analýze výkonu dotazů a indexování ve službě Azure AI Search.
Vývoj čísel směrných plánů
V jakékoli rozsáhlé implementaci je důležité provést test srovnávacích testů výkonu Search Azure AI před jeho uvedením do produkčního prostředí. Měli byste otestovat zatížení vyhledávacího dotazu, které očekáváte, ale také očekávané úlohy příjmu dat (pokud je to možné, spustit obě úlohy současně). Srovnávací testy pomáhají ověřit správnou úroveň vyhledávání, konfiguraci služby a očekávanou latenci dotazů.
Pokud chcete izolovat účinky architektury distribuované služby, zkuste otestovat konfigurace služeb jedné repliky a jednoho oddílu.
Poznámka:
U úrovní optimalizovaných pro úložiště (L1 a L2) byste měli očekávat nižší propustnost dotazů a vyšší latenci než úrovně Standard.
Použití protokolování prostředků
Nejdůležitějším diagnostickým nástrojem k dispozici správce je protokolování prostředků. Protokolování prostředků je shromažďování provozních dat a metrik o vaší vyhledávací službě. Protokolování prostředků je povolené prostřednictvím služby Azure Monitor. S používáním služby Azure Monitor a ukládáním dat jsou spojené náklady, ale pokud je povolíte pro svoji službu, může být prošetřování problémů s výkonem důležité.
Následující obrázek znázorňuje řetěz událostí v požadavku dotazu a odpovědi. Latence může nastat v libovolné z nich, ať už během přenosu sítě, zpracování obsahu ve vrstvě aplikačních služeb nebo ve vyhledávací službě. Klíčovou výhodou protokolování prostředků je to, že aktivity se protokolují z pohledu vyhledávací služby, což znamená, že vám protokol může pomoct určit, jestli je problém s výkonem způsobený problémy s dotazem nebo indexováním nebo jiným bodem selhání.
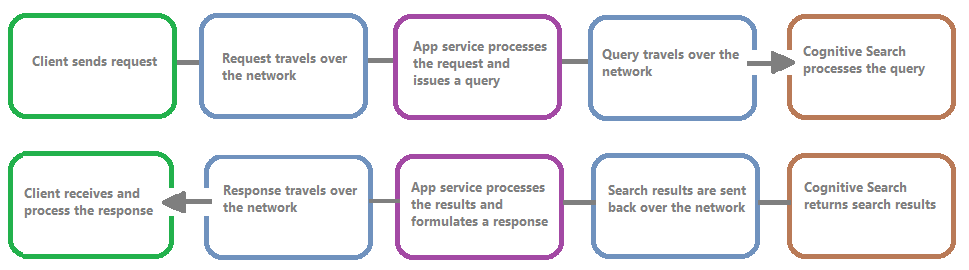
Protokolování prostředků poskytuje možnosti pro ukládání protokolovaných informací. Doporučujeme používat Log Analytics , abyste mohli spouštět pokročilé dotazy Kusto na data, abyste mohli zodpovědět mnoho otázek týkajících se využití a výkonu.
Na stránkách portálu vyhledávací služby můžete povolit protokolování prostřednictvím nastavení diagnostiky a pak vydat dotazy Kusto na Log Analytics tak, že zvolíte Protokoly. Informace o tom, jak odesílat protokoly prostředků do pracovního prostoru služby Log Analytics, kde je můžete analyzovat pomocí dotazů protokolu, najdete v tématu Shromažďování a analýza protokolů prostředků z prostředku Azure.
Chování omezování
K omezování dochází, když je vyhledávací služba v kapacitě. Omezování může nastat během dotazů nebo indexování. Na straně klienta má volání rozhraní API za následek odpověď HTTP 503, když došlo k omezení. Během indexování existuje také možnost přijetí odpovědi HTTP 207, která indikuje, že se jedné nebo více položek nepodařilo indexovat. Tato chyba je indikátorem, že vyhledávací služba se blíží kapacitě.
Obecně platí, že zkuste kvantifikovat množství omezování a jakékoli vzory. Pokud například dojde k omezení jednoho vyhledávacího dotazu z 500 000, nemusí být nutné prošetřit. Pokud je však v určitém období omezené velké procento dotazů, bude to větší problém. Když se podíváte na omezování v určitém období, pomůže vám také identifikovat časové rámce, ve kterých může dojít k omezování, a pomůže vám rozhodnout se, jak to nejlépe přizpůsobit.
Jednoduchou opravou většiny problémů s omezováním je vyvolání dalších prostředků ve vyhledávací službě (obvykle repliky pro omezování založené na dotazech nebo oddíly pro omezování na základě indexování). Zvýšení replik nebo oddílů ale zvyšuje náklady, a proto je důležité vědět, proč vůbec dochází k omezování. Prozkoumání podmínek, které způsobují omezování, se vysvětlí v následujících několika částech.
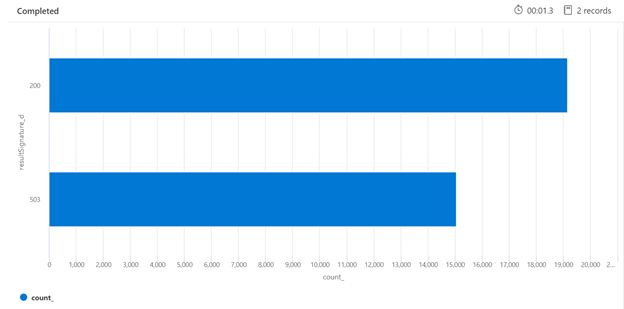
Níže je příklad dotazu Kusto, který dokáže identifikovat rozpis odpovědí HTTP z vyhledávací služby, která byla zatížena. Vykreslovaný pruhový graf během 7denního období ukazuje, že v porovnání s počtem úspěšných (200) odpovědí došlo k omezení relativně velkého procenta vyhledávacích dotazů.
AzureDiagnostics
| where TimeGenerated > ago(7d)
| summarize count() by resultSignature_d
| render barchart
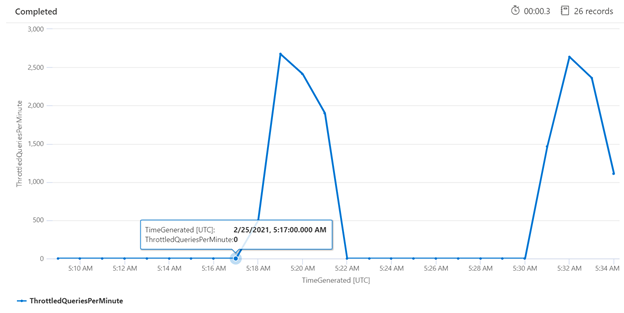
Zkoumání omezování v určitém časovém období vám může pomoct identifikovat časy, kdy k omezování může docházet častěji. V následujícím příkladu se graf časových řad používá k zobrazení počtu omezených dotazů, ke kterým došlo v zadaném časovém rámci. V tomto případě omezené dotazy korelují s časy při srovnávacím testu výkonu.
let ['_startTime']=datetime('2024-02-25T20:45:07Z');
let ['_endTime']=datetime('2024-03-03T20:45:07Z');
let intervalsize = 1m;
AzureDiagnostics
| where TimeGenerated > ago(7d)
| where resultSignature_d != 403 and resultSignature_d != 404 and OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete")
| summarize
ThrottledQueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete") and resultSignature_d == 503)/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
Měření jednotlivých dotazů
V některých případech může být užitečné otestovat jednotlivé dotazy a zjistit, jak fungují. K tomu je důležité zjistit, jak dlouho trvá dokončení práce vyhledávací služba a jak dlouho trvá provedení žádosti o odezvu od klienta a zpět do klienta. Diagnostické protokoly je možné použít k vyhledání jednotlivých operací, ale může být jednodušší to udělat z klienta REST.
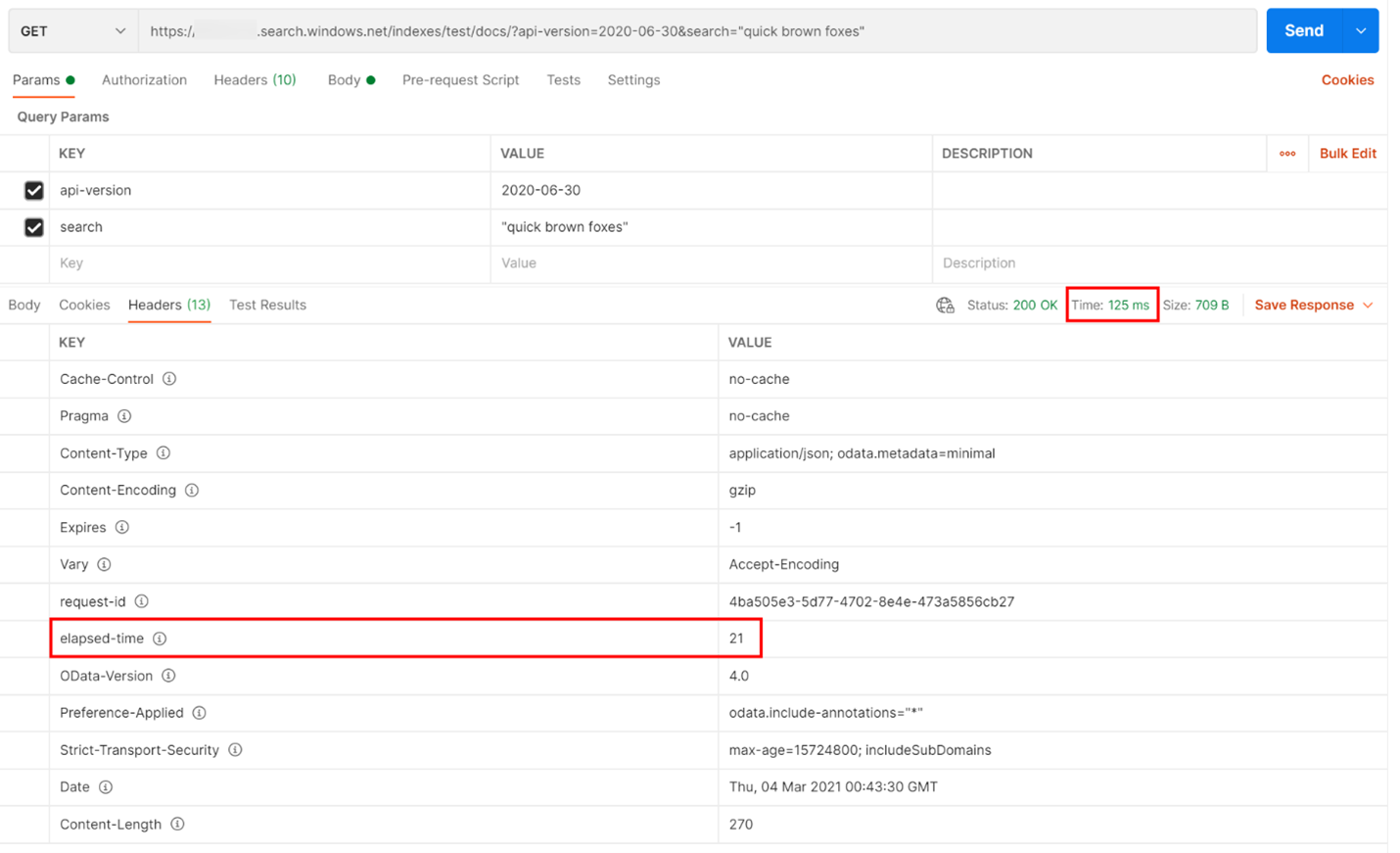
V následujícím příkladu se spustil vyhledávací dotaz založený na REST. Azure AI Search zahrnuje do každé odpovědi počet milisekund potřebných k dokončení dotazu, který je viditelný na kartě Záhlaví v "uplynulé době". Vedle položky Stav v horní části odpovědi najdete dobu odezvy, v tomto případě 418 milisekund (ms). V oddílu výsledků byla vybrána karta Záhlaví. Použití těchto dvou hodnot, zvýrazněné červeným polem na obrázku níže, vidíme, že vyhledávací služba vzala 21 ms k dokončení vyhledávacího dotazu a celá žádost o odezvu klienta trvala 125 ms. Odečtením těchto dvou čísel můžeme zjistit, že přenos vyhledávacího dotazu do vyhledávací služby a přenos výsledků hledání zpět klientovi trvalo 104 ms.
Tato technika pomáhá izolovat latence sítě od jiných faktorů ovlivňujících výkon dotazů.
Sazby dotazů
Jedním z možných důvodů, proč vyhledávací služba omezuje požadavky, je celkový počet dotazů, které se provádějí, když se svazek zaznamenává jako dotazy za sekundu (QPS) nebo dotazy za minutu (QPM). Vzhledem k tomu, že vaše vyhledávací služba přijímá více QPS, bude obvykle trvat déle a déle reagovat na tyto dotazy, dokud už nebude moct udržet krok, protože bude odesílat zpět omezování 503 odpovědi HTTP.
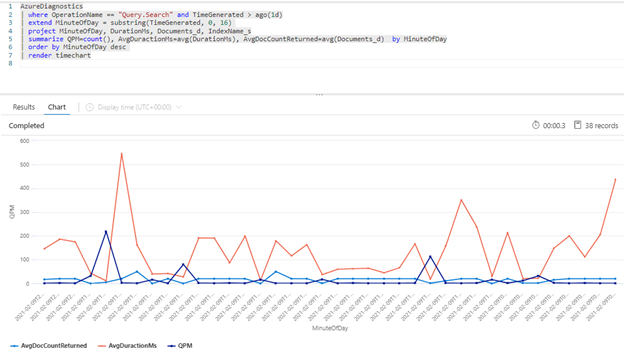
Následující dotaz Kusto zobrazuje objem dotazu měřený v QPM spolu s průměrnou dobou trvání dotazu v milisekundách (AvgDurationMS) a průměrným počtem dokumentů (AvgDocCountReturned) vrácených v každém z nich.
AzureDiagnostics
| where OperationName == "Query.Search" and TimeGenerated > ago(1d)
| extend MinuteOfDay = substring(TimeGenerated, 0, 16)
| project MinuteOfDay, DurationMs, Documents_d, IndexName_s
| summarize QPM=count(), AvgDuractionMs=avg(DurationMs), AvgDocCountReturned=avg(Documents_d) by MinuteOfDay
| order by MinuteOfDay desc
| render timechart
Tip
Pokud chcete zobrazit data za tímto grafem, odeberte čáru | render timechart a pak znovu spusťte dotaz.
Dopad indexování na dotazy
Důležitým faktorem, který je potřeba vzít v úvahu při pohledu na výkon, je, že indexování používá stejné prostředky jako vyhledávací dotazy. Pokud indexujete velké množství obsahu, můžete očekávat, že se zvýší latence, protože se služba snaží pojmout obě úlohy.
Pokud se dotazy zpomalují, podívejte se na načasování aktivity indexování a zjistěte, jestli se shoduje se snížením výkonu dotazů. Například indexer spouští denní nebo hodinovou úlohu, která koreluje s nižším výkonem vyhledávacích dotazů.
Tato část obsahuje sadu dotazů, které vám pomůžou vizualizovat sazby hledání a indexování. V těchto příkladech je časový rozsah nastavený v dotazu. Při spouštění dotazů na webu Azure Portal nezapomeňte nastavit v dotazu .
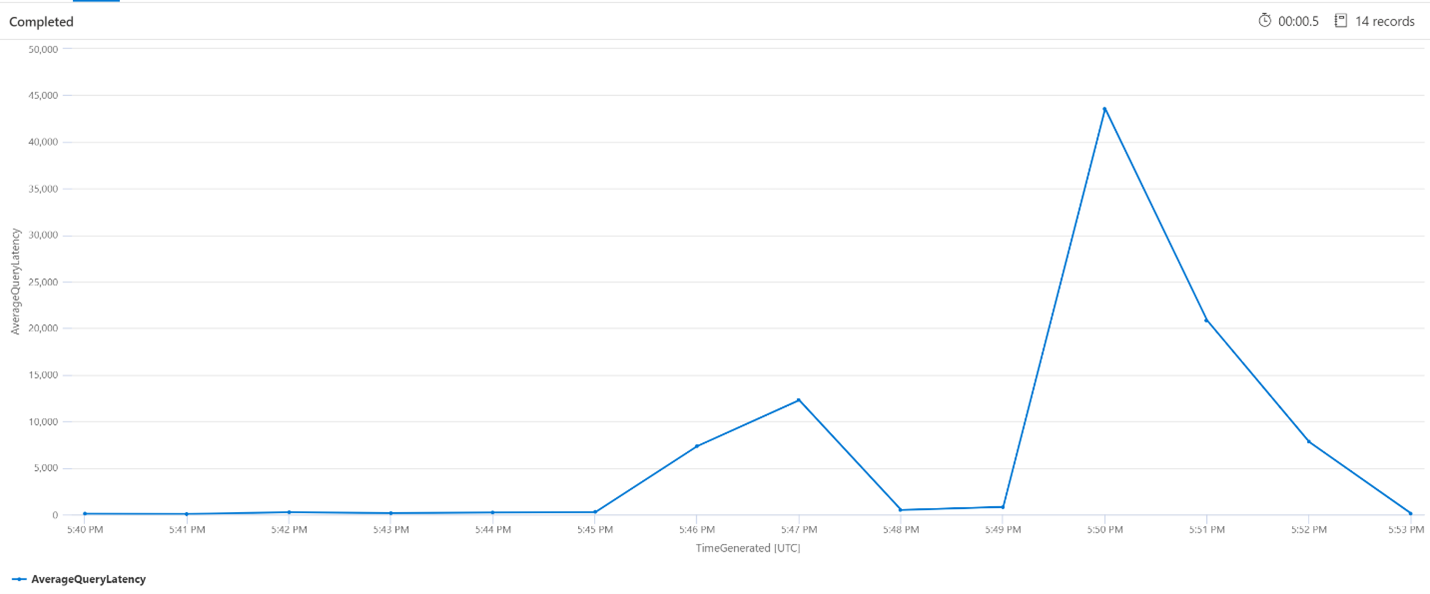
Průměrná latence dotazů
V následujícím dotazu se k zobrazení průměrné latence vyhledávacích dotazů používá velikost intervalu 1 minuta. Z grafu vidíme, že průměrná latence byla nízká do 5:45 a trvala do 5:53.00.
let intervalsize = 1m;
let _startTime = datetime('2024-02-23 17:40');
let _endTime = datetime('2024-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime']..['_endTime']) // Time range filtering
| summarize AverageQueryLatency = avgif(DurationMs, OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))
by bin(TimeGenerated, intervalsize)
| render timechart
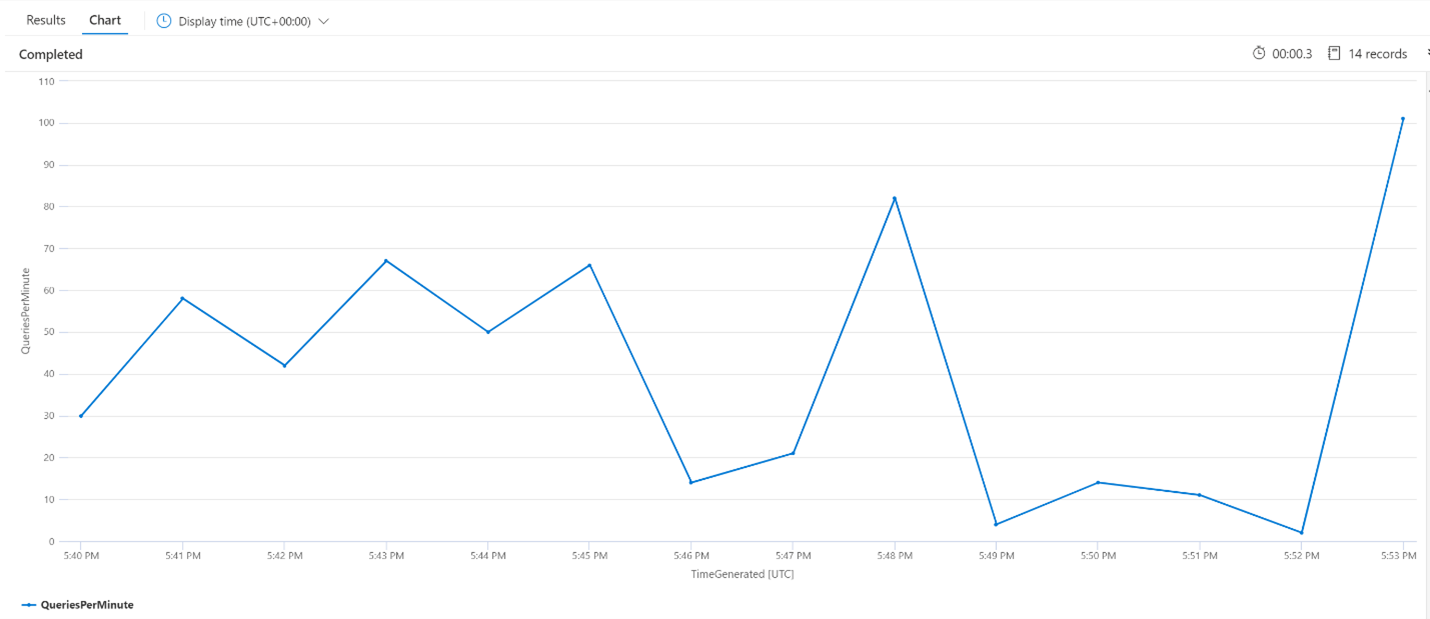
Průměrné dotazy za minutu (QPM)
Následující dotaz se podívá na průměrný počet dotazů za minutu, aby se zajistilo, že v požadavcích hledání nedošlo ke špičkám, které by mohly ovlivnit latenci. Z grafu vidíme, že je nějaká odchylka, ale nic neznamená špičku v počtu požadavků.
let intervalsize = 1m;
let _startTime = datetime('2024-02-23 17:40');
let _endTime = datetime('2024-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize QueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
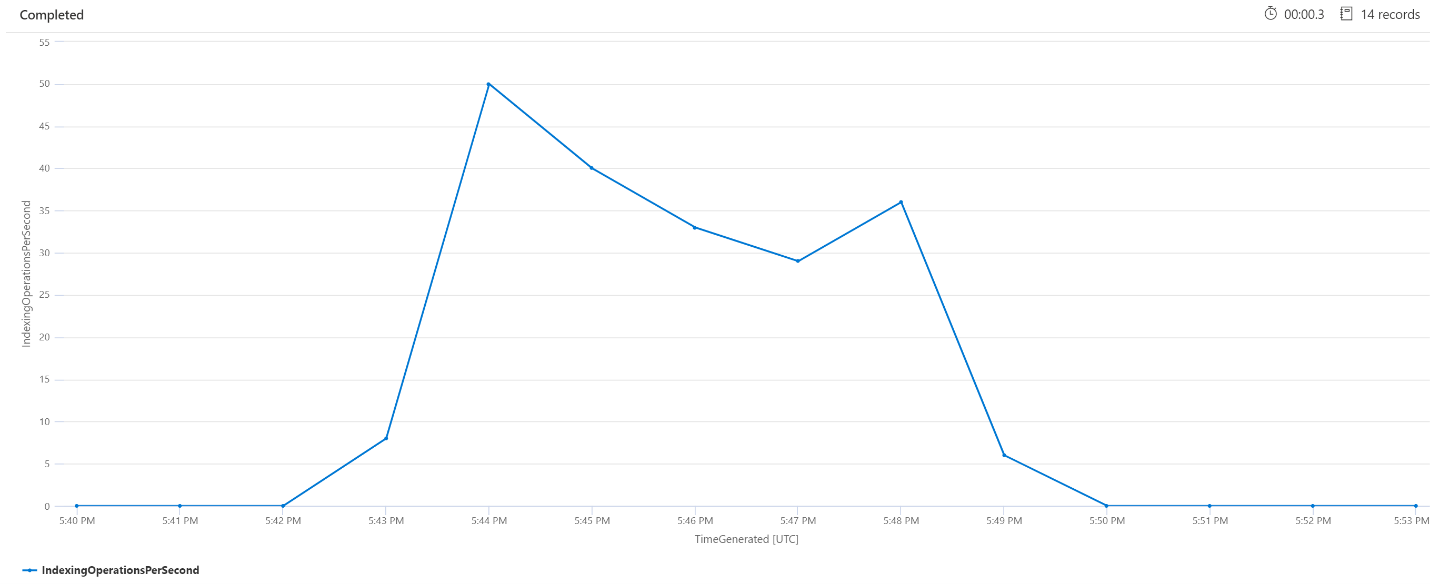
Operace indexování za minutu (OPM)
Tady se podíváme na počet operací indexování za minutu. Z grafu vidíme, že velké množství dat bylo indexováno v 17:42 a skončilo v 17:50. Toto indexování začalo 3 minuty, než se vyhledávací dotazy začaly schovávat a skončily 3 minuty, než vyhledávací dotazy přestaly být latentní.
Z tohoto přehledu vidíme, že přibližně 3 minuty trvalo, než vyhledávací služba přestane být zaneprázdněná, aby indexování ovlivnilo latenci dotazů. Vidíme také, že po dokončení indexování trvalo další 3 minuty, než vyhledávací služba dokončila veškerou práci z nově indexovaného obsahu a aby se vyřešila latence dotazů.
let intervalsize = 1m;
let _startTime = datetime('2024-02-23 17:40');
let _endTime = datetime('2024-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize IndexingOperationsPerSecond=bin(countif(OperationName == "Indexing.Index")/ (intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
Zpracování služby na pozadí
Občasné špičky v latenci dotazů nebo indexování se běžně zobrazují. Špičky můžou nastat v reakci na indexování nebo vysoké míry dotazů, ale můžou nastat i během operací sloučení. Indexy vyhledávání se ukládají do bloků dat nebo horizontálních oddílů. Systém pravidelně slučuje menší horizontální oddíly do velkých horizontálních oddílů, což může pomoct optimalizovat výkon služby. Tento proces sloučení také vyčistí dokumenty, které byly dříve označené k odstranění z indexu, což vede k obnovení prostoru úložiště.
Slučování horizontálních oddílů je rychlé, ale také náročné na prostředky a má tak potenciál snížit výkon služby. Pokud zaznamenáte krátké nárůsty latence dotazů a tyto shluky se shodují s nedávnými změnami indexovaného obsahu, můžete předpokládat, že latence je způsobená operacemi sloučení horizontálních oddílů.
Další kroky
Projděte si tyto články týkající se analýzy výkonu služby.