Kurz: Indexování vnořených objektů blob Markdownu ze služby Azure Storage pomocí REST
Poznámka:
Tato funkce je v současné době ve verzi Public Preview. Tato verze Preview je poskytována bez smlouvy o úrovni služeb a nedoporučuje se pro produkční úlohy. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Azure AI Search může indexovat dokumenty a pole Markdownu ve službě Azure Blob Storage pomocí indexeru, který ví, jak číst data Markdownu.
V tomto kurzu se dozvíte, jak indexovat soubory Markdownu indexované pomocí oneToMany režimu analýzy Markdownu. K provádění následujících úloh používá klienta REST a rozhraní REST API služby Search:
- Nastavení ukázkových dat a konfigurace
azureblobzdroje dat - Vytvoření indexu Azure AI Search, který bude obsahovat prohledávatelný obsah
- Vytvoření a spuštění indexeru pro čtení kontejneru a extrakci prohledávatelného obsahu
- Prohledávání právě vytvořeného indexu
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Požadavky
Visual Studio Code s klientem REST
Azure AI Search. Vytvořte nebo najděte existující prostředek služby Azure AI Search v rámci vašeho aktuálního předplatného.
Poznámka:
Pro účely tohoto kurzu můžete použít bezplatnou službu. Bezplatná vyhledávací služba vás omezuje na tři indexy, tři indexery a tři zdroje dat. V tomto kurzu se vytváří od každého jeden. Než začnete, ujistěte se, že máte ve službě místo pro přijetí nových prostředků.
Vytvoření dokumentu Markdownu
Zkopírujte a vložte následující Markdown do souboru s názvem sample_markdown.md. Ukázková data jsou jeden soubor Markdownu obsahující různé prvky Markdownu. Zvolili jsme jeden soubor Markdownu, abychom zůstali pod limity úložiště úrovně Free.
# Project Documentation
## Introduction
This document provides a complete overview of the **Markdown Features** used within this project. The following sections demonstrate the richness of Markdown formatting, with examples of lists, tables, links, images, blockquotes, inline styles, and more.
---
## Table of Contents
1. [Headers](#headers)
2. [Introduction](#introduction)
3. [Basic Text Formatting](#basic-text-formatting)
4. [Lists](#lists)
5. [Blockquotes](#blockquotes)
6. [Images](#images)
7. [Links](#links)
8. [Tables](#tables)
9. [Code Blocks and Inline Code](#code-blocks-and-inline-code)
10. [Horizontal Rules](#horizontal-rules)
11. [Inline Elements](#inline-elements)
12. [Escaping Characters](#escaping-characters)
13. [HTML Elements](#html-elements)
14. [Emojis](#emojis)
15. [Footnotes](#footnotes)
16. [Task Lists](#task-lists)
17. [Conclusion](#conclusion)
---
## Headers
Markdown supports six levels of headers. Use `#` to create headers:
"# Project Documentation" at the top of the document is an example of an h1 header.
"## Headers" above is an example of an h2 header.
### h3 example
#### h4 example
##### h5 example
###### h6 example
This is an example of content underneath a header.
## Basic Text Formatting
You can apply various styles to your text:
- **Bold**: Use double asterisks or underscores: `**bold**` or `__bold__`.
- *Italic*: Use single asterisks or underscores: `*italic*` or `_italic_`.
- ~~Strikethrough~~: Use double tildes: `~~strikethrough~~`.
## Lists
### Ordered List
1. First item
2. Second item
3. Third item
### Unordered List
- Item A
- Item B
- Item C
### Nested List
1. Parent item
- Child item
- Child item
## Blockquotes
> This is a blockquote.
> Blockquotes are great for emphasizing important information.
>> Nested blockquotes are also possible!
## Images

## Links
[Visit Markdown Guide](https://www.markdownguide.org)
## Tables
| Syntax | Description | Example |
|-------------|-------------|---------------|
| Header | Title | Header Cell |
| Paragraph | Text block | Row Content |
## Code Blocks and Inline Code
### Inline Code
Use backticks to create `inline code`.
### Code Block
```javascript
// JavaScript example
function greet(name) {
console.log(`Hello, ${name}!`);
}
greet('World');
```
## Horizontal Rules
Use three or more dashes or underscores to create a horizontal rule.
---
___
## Inline Elements
Sometimes, it’s useful to include `inline code` to highlight code-like content.
You can also emphasize text like *this* or make it **bold**.
## Escaping Characters
To render special Markdown characters, use backslashes:
- \*Asterisks\*
- \#Hashes\#
- \[Brackets\]
## HTML Elements
You can mix HTML tags with Markdown:
<table>
<tr>
<th>HTML Table</th>
<th>With Markdown</th>
</tr>
<tr>
<td>Row 1</td>
<td>Data 1</td>
</tr>
</table>
## Emojis
Markdown supports some basic emojis:
- :smile: 😄
- :rocket: 🚀
- :checkered_flag: 🏁
## Footnotes
This is an example of a footnote[^1]. Footnotes allow you to add notes without cluttering the main text.
[^1]: This is the content of the footnote.
## Task Lists
- [x] Complete the introduction
- [ ] Add more examples
- [ ] Review the document
## Conclusion
Markdown is a lightweight yet powerful tool for writing documentation. It supports a variety of formatting options while maintaining simplicity and readability.
Thank you for reviewing this example!
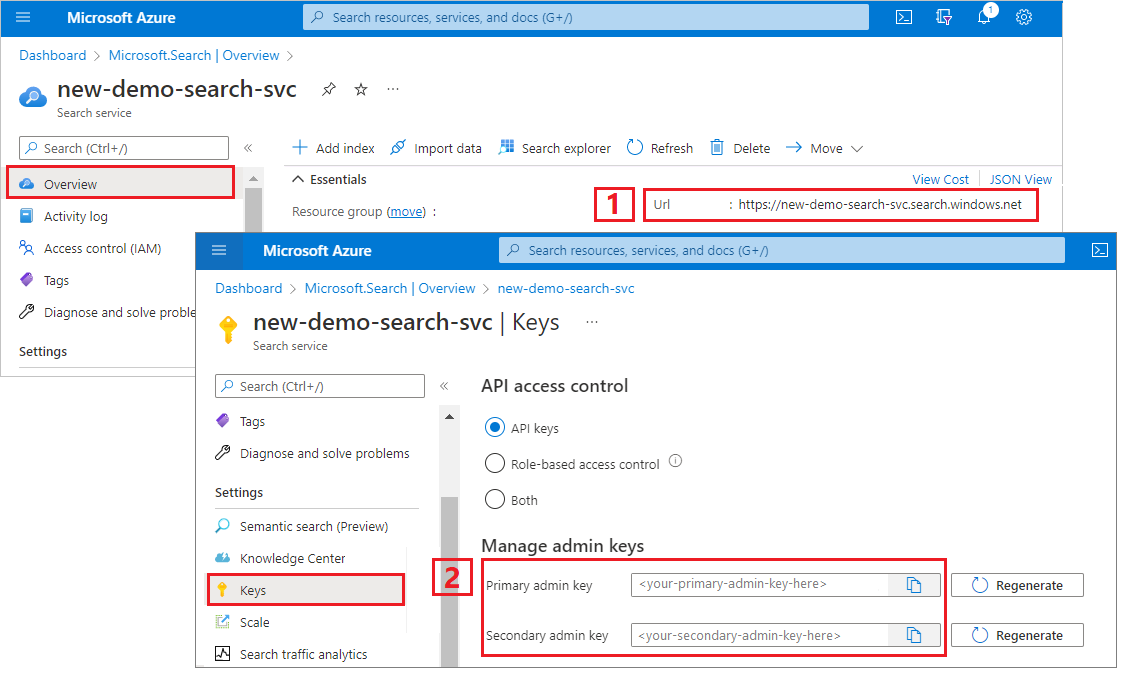
Zkopírování adresy URL vyhledávací služby a klíče rozhraní API
Pro účely tohoto kurzu vyžadují připojení ke službě Azure AI Search koncový bod a klíč rozhraní API. Tyto hodnoty můžete získat z webu Azure Portal. Alternativní metody připojení najdete v tématu spravované identity.
Přihlaste se k webu Azure Portal, přejděte na stránku Přehled vyhledávací služby a zkopírujte adresu URL. Příkladem koncového bodu může být
https://mydemo.search.windows.net.V části Klíče nastavení>zkopírujte klíč správce. Klíče správce slouží k přidávání, úpravám a odstraňování objektů. Existují dva zaměnitelné klíče správce. Zkopírujte jeden z nich.
Nastavení souboru REST
Spusťte Visual Studio Code a vytvořte nový soubor.
Zadejte hodnoty proměnných použitých v požadavku:
@baseUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnectionString = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @blobContainer = PUT-YOUR-CONTAINER-NAME-HEREUložte soubor pomocí přípony
.restnebo.httpsouboru.
Viz Rychlý start: Vyhledávání textu pomocí REST , pokud potřebujete pomoc s klientem REST.
Vytvoření zdroje dat
Vytvoření zdroje dat (REST) vytvoří připojení ke zdroji dat, které určuje, jaká data se mají indexovat.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "sample-markdown-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Odešlete požadavek. Odpověď by měla vypadat nějak takto:
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
ETag: "0x8DCF52E926A3C76"
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net:443/datasources('sample-markdown-ds')?api-version=2024-11-01-preview
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 0714c187-217e-4d35-928a-5069251e5cba
elapsed-time: 204
Date: Fri, 25 Oct 2024 19:52:35 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/$metadata#datasources/$entity",
"@odata.etag": "\"0x8DCF52E926A3C76\"",
"name": "sample-markdown-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": null
},
"container": {
"name": "markdown-container",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
Vytvoření indexu
Vytvoření indexu (REST) vytvoří vyhledávací index ve vyhledávací službě. Index určuje všechna pole a jejich atributy.
Při analýze 1:N definuje vyhledávací dokument stranu N relace. Pole zadaná v indexu určují strukturu hledaného dokumentu.
Potřebujete jenom pole pro prvky Markdownu, které analyzátor podporuje. Tato pole jsou:
content: Řetězec, který obsahuje nezpracovaný Markdown nalezený v určitém umístění, na základě metadat záhlaví v tomto okamžiku v dokumentu.sections: Objekt, který obsahuje podpole pro metadata záhlaví až do požadované úrovně záhlaví. Pokud je například nastavenamarkdownHeaderDepthhodnotah3, obsahuje řetězcová poleh1,h2ah3. Tato pole jsou indexována zrcadlením této struktury v indexu, nebo prostřednictvím mapování polí ve formátu/sections/h1,sections/h2atd. Příklady v kontextu najdete v následujících ukázkách v konfiguracích indexu a indexeru. Obsažená dílčí pole jsou:-
h1– Řetězec obsahující hodnotu hlavičky h1. Prázdný řetězec, pokud není v tomto okamžiku v dokumentu nastaven. - (Volitelné)
h2– Řetězec obsahující hodnotu záhlaví h2. Prázdný řetězec, pokud není v tomto okamžiku v dokumentu nastaven. - (Volitelné)
h3– Řetězec obsahující hodnotu hlavičky h3. Prázdný řetězec, pokud není v tomto okamžiku v dokumentu nastaven. - (Volitelné)
h4– Řetězec obsahující hodnotu hlavičky h4. Prázdný řetězec, pokud není v tomto okamžiku v dokumentu nastaven. - (Volitelné)
h5– Řetězec obsahující hodnotu hlavičky h5. Prázdný řetězec, pokud není v tomto okamžiku v dokumentu nastaven. - (Volitelné)
h6– Řetězec obsahující hodnotu záhlaví h6. Prázdný řetězec, pokud není v tomto okamžiku v dokumentu nastaven.
-
ordinal_position: Celočíselná hodnota označující pozici oddílu v hierarchii dokumentů. Toto pole slouží k seřazení oddílů v původní sekvenci, jak se zobrazují v dokumentu, počínaje pořadovou pozicí 1 a postupně se pro každý blok obsahu zvýší.
Tato implementace využívá mapování polí v indexeru k mapování z rozšířeného obsahu na index. Další informace o parsované struktuře dokumentu 1:N najdete v objektech blob markdownu indexu.
Tento příklad obsahuje ukázky, jak indexovat data pomocí mapování polí i bez mapování polí. V tomto případě víme, že h1 obsahuje název dokumentu, abychom ho mohli namapovat na pole s názvem title. Budeme také mapovat h2 pole a h3 pole na h2_subheader a h3_subheader v uvedeném pořadí. Pole contentordinal_position nevyžadují žádné mapování, protože se extrahují z Markdownu přímo do polí používajících tyto názvy. Příklad úplného schématu indexu, které nevyžaduje mapování polí, najdete na konci této části.
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "sample-markdown-index",
"fields": [
{"name": "id", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "content", "type": "Edm.String", "key": false, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "title", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h2_subheader", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h3_subheader", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "ordinal_position", "type": "Edm.Int32", "searchable": false, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
}
Schéma indexu v konfiguraci bez mapování polí
Mapování polí umožňují manipulovat s rozšířeným obsahem a filtrovat ho tak, aby se vešly do požadovaného obrazce indexu, ale můžete chtít obsah rozšířit přímo. V takovém případě by schéma vypadalo takto:
{
"name": "sample-markdown-index",
"fields": [
{"name": "id", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "content", "type": "Edm.String", "key": false, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "sections",
"type": "Edm.ComplexType",
"fields": [
{"name": "h1", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h2", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h3", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
},
{"name": "ordinal_position", "type": "Edm.Int32", "searchable": false, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
}
Abychom znovu opakovali, máme v objektu oddílů dílčí pole h3 , protože markdownHeaderDepth je nastavena na h3.
Pokud se rozhodnete toto schéma použít, nezapomeňte odpovídajícím způsobem upravit pozdější požadavky. To bude vyžadovat odebrání mapování polí z konfigurace indexeru a aktualizaci vyhledávacích dotazů tak, aby používaly odpovídající názvy polí.
Vytvoření a spuštění indexeru
Vytvoření indexeru vytvoří indexer ve vyhledávací službě. Indexer se připojí ke zdroji dat, načte a indexuje data a volitelně poskytuje plán pro automatizaci aktualizace dat.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "sample-markdown-indexer",
"dataSourceName": "sample-markdown-ds",
"targetIndexName": "sample-markdown-index",
"parameters" : {
"configuration": {
"parsingMode": "markdown",
"markdownParsingSubmode": "oneToMany",
"markdownHeaderDepth": "h3"
}
},
"fieldMappings" : [
{
"sourceFieldName": "/sections/h1",
"targetFieldName": "title",
"mappingFunction": null
}
]
}
Klíčové body:
Indexer bude parsovat pouze hlavičky až do
h3. Jakákoli záhlaví nižší úrovně (h4,h5)h6se bude považovat za prostý text a zobrazí se vcontentpoli. To je důvod, proč mapování indexu a polí existují pouze až do hloubkyh3.ordinal_positionPolecontentnevyžadují žádné mapování polí, protože existují s těmito názvy v rozšířeném obsahu.
Spouštění dotazů
Hledání můžete začít hned, jak se načte první dokument.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true
}
Odešlete požadavek. Jedná se o nezadáný fulltextový vyhledávací dotaz, který vrátí všechna pole označená jako zobrazitelná v indexu spolu s počtem dokumentů. Odpověď by měla vypadat nějak takto:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 6b94e605-55e8-47a5-ae15-834f926ddd14
elapsed-time: 77
Date: Fri, 25 Oct 2024 20:22:58 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 22,
"value": [
<22 search documents here>
]
}
search Přidejte parametr pro hledání řetězce.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "h4",
"count": true,
}
Odešlete požadavek. Odpověď by měla vypadat nějak takto:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: ec5d03f1-e3e7-472f-9396-7ff8e3782105
elapsed-time: 52
Date: Fri, 25 Oct 2024 20:26:29 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 1,
"value": [
{
"@search.score": 0.8744742,
"section_id": "aHR0cHM6Ly9hcmphZ2Fubmpma2ZpbGVzLmJsb2IuY29yZS53aW5kb3dzLm5ldC9tYXJrZG93bi10dXRvcmlhbC9zYW1wbGVfbWFya2Rvd24ubWQ7NA2",
"content": "#### h4 example\r\n##### h5 example\r\n###### h6 example\r\nThis is an example of content underneath a header.\r\n",
"title": "Project Documentation",
"h2_subheader": "Headers",
"h3_subheader": "h3 example",
"ordinal_position": 4
}
]
}
Klíčové body:
Vzhledem k tomu, že je nastavena
markdownHeaderDepthnah3,h4h5, ah6záhlaví jsou považovány za prostý text, takže se zobrazí vcontentpoli.Ordinální pozice zde je
4. Tento obsah je čtvrtý z 22 celkového počtu oddílů obsahu.
select Přidejte parametr, který omezí výsledky na méně polí.
filter Přidejte k dalšímu zúžení hledání.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "Markdown",
"count": true,
"select": "title, content, h2_subheader",
"filter": "h2_subheader eq 'Conclusion'"
}
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: a6f9bd46-a064-4e28-818f-ea077618014b
elapsed-time: 35
Date: Fri, 25 Oct 2024 20:36:10 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 1,
"value": [
{
"@search.score": 1.1029507,
"content": "Markdown is a lightweight yet powerful tool for writing documentation. It supports a variety of formatting options while maintaining simplicity and readability.\r\n\r\nThank you for reviewing this example!",
"title": "Project Documentation",
"h2_subheader": "Conclusion"
}
]
}
U filtrů můžete také použít logické operátory (a nebo ne) a relační operátory (eq, ne, gt, lt, ge, le). Při porovnávání řetězců se rozlišují malá a velká písmena. Další informace a příklady najdete v tématu Vytvoření dotazu.
Poznámka:
Parametr $filter funguje jenom u polí, která byla označena jako filtrovatelná při vytváření indexu.
Resetování a opětovné spuštění
Indexery je možné resetovat, vymazat historii provádění, což umožňuje úplné opětovné spuštění. Následující požadavky GET jsou určené k resetování a následné opětovné spuštění.
### Reset the indexer
POST {{baseUrl}}/indexers/sample-markdown-indexer/reset?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
### Run the indexer
POST {{baseUrl}}/indexers/sample-markdown-indexer/run?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
### Check indexer status
GET {{baseUrl}}/indexers/sample-markdown-indexer/status?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
Vyčištění prostředků
Když pracujete ve vlastním předplatném, je na konci projektu vhodné odebrat prostředky, které už nepotřebujete. Prostředky, které necháte spuštěné, vás stojí peníze. Prostředky můžete odstraňovat jednotlivě nebo můžete odstranit skupinu prostředků, a odstranit tak celou sadu prostředků najednou.
Pomocí webu Azure Portal můžete odstranit indexy, indexery a zdroje dat.
Další kroky
Teď, když znáte základy indexování objektů blob v Azure, se podrobněji podíváme na konfiguraci indexeru pro objekty blob Markdown ve službě Azure Storage.