Vytvoření indexu ve službě Azure AI Search
V tomto článku se dozvíte, jak definovat schéma indexu vyhledávání a nasdílit ho do vyhledávací služby. Vytvoření indexu vytvoří fyzické datové struktury ve vyhledávací službě. Jakmile index existuje, načtěte index jako samostatný úkol.
Požadavky
Oprávnění k zápisu jako přispěvatele vyhledávací služby nebo klíče rozhraní API pro správu pro ověřování na základě klíčů
Pochopení dat, která chcete indexovat. Index vyhledávání je založený na externím obsahu, který chcete prohledávat. Prohledávatelný obsah se ukládá jako pole v indexu. Měli byste mít jasnou představu o tom, která zdrojová pole chcete ve službě Azure AI Search prohledávat, zobrazovat, filtrovat, filtrovatelná, fasetová a řaditelná. Pokyny najdete v kontrolním seznamu schématu.
Musíte mít také jedinečné pole ve zdrojových datech, které lze použít jako klíč dokumentu (nebo ID) v indexu.
Stabilní umístění indexu. Přesunutí existujícího indexu do jiné vyhledávací služby se nepodporuje. Znovu si projděte požadavky na aplikace a ujistěte se, že vaše stávající vyhledávací služba (kapacita a oblast) dostatečná pro vaše potřeby. Pokud používáte závislost na službách Azure AI nebo Azure OpenAI, zvolte oblast, která poskytuje všechny potřebné prostředky.
Nakonec všechny úrovně služby mají omezení indexu počtu objektů, které můžete vytvořit. Pokud například experimentujete na úrovni Free, můžete mít v daném okamžiku pouze tři indexy. V samotném indexu existují omezení vektorů a limitů indexu pro počet jednoduchých a složitých polí.
Klíče dokumentu
Vytvoření indexu vyhledávání má dva požadavky: index musí mít jedinečný název vyhledávací služby a musí mít klíč dokumentu. Logický key atribut pole lze nastavit na hodnotu true, aby bylo možné určit, které pole poskytuje klíč dokumentu.
Klíč dokumentu je jedinečný identifikátor hledaného dokumentu a hledaný dokument je kolekce polí, která něco úplně popisují. Pokud například indexujete datovou sadu filmů, obsahuje hledaný dokument název, žánr a dobu trvání jednoho filmu. Názvy filmů jsou v této datové sadě jedinečné, takže název videa můžete použít jako klíč dokumentu.
Ve službě Azure AI Search je klíč dokumentu řetězec a musí pocházet z jedinečných hodnot ve zdroji dat, který poskytuje obsah, který se má indexovat. Obecně platí, že vyhledávací služba negeneruje klíčové hodnoty, ale v některých scénářích (jako je indexer tabulky Azure) syntetizuje existující hodnoty a vytvoří jedinečný klíč pro indexované dokumenty. Dalším scénářem je indexování 1:N pro blokovaná nebo dělená data, v takovém případě se klíče dokumentu generují pro každý blok dat.
Během přírůstkového indexování, kde se indexuje nový a aktualizovaný obsah, se přidají příchozí dokumenty s novými klíči, zatímco příchozí dokumenty s existujícími klíči se buď sloučí, nebo přepíšou v závislosti na tom, jestli jsou pole indexu null nebo naplněná.
Mezi důležité body týkající se klíčů dokumentu patří:
- Maximální délka hodnot v poli klíče je 1 024 znaků.
- Jako klíčové pole musí být vybráno přesně jedno pole nejvyšší úrovně v každém indexu a musí být typu
Edm.String. - Výchozí hodnota atributu
keyje false pro jednoduchá pole a hodnotu null pro složitá pole.
Klíčová pole se dají použít k přímému vyhledání dokumentů a aktualizaci nebo odstranění konkrétních dokumentů. Hodnoty polí klíčů se zpracovávají rozlišováním malých a velkých písmen při vyhledávání nebo indexování dokumentů. Podrobnosti najdete v tématu GET Document (REST) a Index documents (REST).
Kontrolní seznam schématu
Tento kontrolní seznam vám pomůže při rozhodování o návrhu indexu vyhledávání.
Zkontrolujte zásady vytváření názvů, aby názvy indexů a polí odpovídaly pravidlům pojmenování.
Viz Podporované datové typy. Datový typ ovlivňuje způsob použití pole. Například číselný obsah je filtrovatelný, ale není prohledávatelný jako fulltext. Nejběžnějším datovým typem pro prohledávatelný text je
Edm.String, který se tokenizuje a dotazuje pomocí fulltextového vyhledávacího modulu. Nejběžnějším datovým typem vektorového pole jeEdm.Single, ale můžete použít i jiné typy.Identifikace klíče dokumentu Klíč dokumentu je požadavek na index. Jedná se o jedno řetězcové pole naplněné zdrojovým datovým polem, které obsahuje jedinečné hodnoty. Pokud například indexujete ze služby Blob Storage, jako klíč dokumentu se často používá cesta k úložišti metadat, protože jednoznačně identifikuje každý objekt blob v kontejneru.
Identifikujte pole ve zdroji dat, která přispívají k prohledávatelnému obsahu v indexu.
Prohledávatelný obsah nevectoru obsahuje krátké nebo dlouhé řetězce, které jsou dotazovány pomocí fulltextového vyhledávacího webu. Pokud je obsah podrobný (Krátké fráze nebo větší bloky dat), experimentujte s různými analyzátory a zjistěte, jak se text tokenizuje.
Prohledávatelný vektorový obsah může být obrázky nebo text (v libovolném jazyce), které existují jako matematická reprezentace. Pomocí úzkých datových typů nebo komprese vektorů můžete zmenšit vektorová pole.
Atributy nastavené u polí, například
retrievablenebofilterable, určují chování hledání i fyzické vyjádření indexu ve vyhledávací službě. Určení způsobu, jakým mají být pole přiřazena, je iterativní proces pro mnoho vývojářů. Pokud chcete iterace urychlit, začněte ukázkovými daty, abyste je mohli snadno zahodit a znovu sestavit.Určete, která zdrojová pole je možné použít jako filtry. Vhodné je použít pole s číselným obsahem a pole s krátkým textem, zejména pole s opakujícími se hodnotami. Při práci s filtry nezapomeňte:
Filtry se dají použít v dotazech vektoru a nevectoru, ale samotný filtr se použije na pole čitelná pro člověka (nevector) ve vašem indexu.
Filtrovatelná pole se dají volitelně použít ve fasetové navigaci.
Filtrovatelná pole se vrací v libovolném pořadí a neprocházejí vyhodnocováním relevance, proto zvažte jejich seřazení.
U vektorových polí zadejte konfiguraci vektorového vyhledávání a algoritmy používané k vytváření navigačních cest a vyplňování vloženého prostoru. Další informace naleznete v tématu Přidání vektorových polí.
Vektorová pole mají další vlastnosti, které pole bezvectoru nemají, například které algoritmy použít a kompresi vektorů.
Vektorová pole vynechají atributy, které nejsou užitečné pro vektorová data, jako jsou řazení, filtrování a fasety.
U polí, která nejsou typuvector, určete, jestli se má použít výchozí analyzátor (
"analyzer": null) nebo jiný analyzátor. Analyzátory se používají k tokenizaci textových polí během indexování a k provádění dotazů.U vícejazyčných řetězců zvažte použití analyzátoru jazyka.
U řetězců se spojovníky nebo zvláštními znaky zvažte specializované analyzátory. Jedním z příkladů je klíčové slovo , které zachází s celým obsahem pole jako s jedním tokenem. Toto chování je užitečné pro data, jako jsou PSČ, ID a některé názvy produktů. Další informace najdete v tématu Hledání zkrácených termínů a vzorce se zvláštními znaky.
Poznámka:
Fulltextové vyhledávání se provádí pomocí termínů, které jsou tokenizovány během indexování. Pokud se vašim dotazům nepodaří vrátit očekávané výsledky, otestujte tokenizaci a ověřte, že řetězec, který hledáte, skutečně existuje. Můžete u řetězců vyzkoušet různé analyzátory a zjistit, jak se pro různé analyzátory vytvářejí tokeny.
Konfigurace definic polí
Kolekce polí definuje strukturu hledaného dokumentu. Všechna pole mají název, datový typ a atributy.
Nastavení pole jako prohledávatelného, filtrovatelného, řaditelného nebo facetable má vliv na velikost indexu a výkon dotazů. Nenastavujte tyto atributy u polí, na která se nemají odkazovat ve výrazech dotazu.
Pokud pole není nastavené tak, aby bylo prohledávatelné, filtrovatelné, řaditelné nebo facetable, pole se nedá odkazovat v žádném výrazu dotazu. To je žádoucí pro pole, která se nepoužívají v dotazech, ale jsou potřeba ve výsledcích hledání.
Rozhraní REST API mají výchozí přiřazení na základě datových typů, které používají také průvodci importem na webu Azure Portal. Sady Azure SDK nemají výchozí hodnoty, ale mají podtřídy polí, které zahrnují vlastnosti a chování, například SearchableField pro řetězce a SimpleField pro primitiva.
Výchozí přiřazení polí pro rozhraní REST API jsou shrnuté v následující tabulce.
| Datový typ | Lze prohledávat | Lze získat | Filterable | Facetable | Lze seřadit | Uložený |
|---|---|---|---|---|---|---|
Edm.String |
✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
Collection(Edm.String) |
✅ | ✅ | ✅ | ✅ | ❌ | ✅ |
Edm.Boolean |
❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
Edm.Int32, , Edm.Int64Edm.Double |
❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
Edm.DateTimeOffset |
❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
Edm.GeographyPoint |
✅ | ✅ | ✅ | ❌ | ✅ | ✅ |
Edm.ComplexType |
✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
Collection(Edm.Single) a všechny ostatní typy vektorových polí |
✅ | ✅ nebo ❌ | ❌ | ❌ | ❌ | ✅ |
Pole řetězců můžou být také volitelně přidružená k analyzátorům a mapám synonym. Pole typu Edm.String , která jsou filtrovatelná, řaditelná nebo facetable, můžou mít maximálně 32 kilobajtů. Důvodem je, že hodnoty těchto polí se považují za jeden hledaný termín a maximální délka termínu ve službě Azure AI Search je 32 kilobajtů. Pokud potřebujete do jednoho textového pole uložit více textu, měli byste explicitně nastavit filtrovatelné, řaditelné a omezující vlastnosti false v definici indexu.
Vektorová pole musí být přidružená k dimenzím a vektorovým profilům. Výchozí možnost načtení je true, pokud přidáte vektorové pole pomocí průvodce importem a vektorizací na webu Azure Portal, jinak je false, pokud používáte rozhraní REST API.
Atributy pole jsou popsány v následující tabulce.
| Atribut | Popis |
|---|---|
| name | Požadováno. Nastaví název pole, které musí být jedinečné v rámci kolekce polí indexu nebo nadřazeného pole. |
| type | Povinný: Nastaví datový typ pole. Pole můžou být jednoduchá nebo složitá. Jednoduchá pole jsou primitivních typů, například Edm.String pro text nebo Edm.Int32 celá čísla.
Složitá pole můžou mít dílčí pole, která jsou sama o sobě jednoduchá nebo složitá. To vám umožní modelovat objekty a pole objektů, které pak umožňují nahrát většinu objektů JSON do indexu. Úplný seznam podporovaných typů najdete v části Podporované datové typy . |
| key | Povinný: Nastavte tento atribut na true a určete, že hodnoty pole jednoznačně identifikují dokumenty v indexu. Podrobnosti najdete v části Klíče dokumentu v tomto článku. |
| retrievable | Určuje, jestli se pole může vrátit ve výsledku hledání. Tento atribut nastavte, false pokud chcete použít pole jako filtr, řazení nebo bodovací mechanismus, ale nechcete, aby bylo pole viditelné pro koncového uživatele. Tento atribut musí být true pro klíčová pole a musí se jednat null o složitá pole. Tento atribut lze změnit u existujících polí. Nastavení pro načtení true nezpůsobí žádné zvýšení požadavků na úložiště indexů. Výchozí hodnota je true pro jednoduchá pole a null pro složitá pole. |
| searchable | Určuje, jestli je pole prohledávatelné fulltextové a lze na toto pole odkazovat ve vyhledávacích dotazech. To znamená, že prochází lexikální analýzou , jako je například dělení slov během indexování. Pokud nastavíte prohledávatelné pole na hodnotu jako "Sunny day", interně se normalizuje do jednotlivých tokenů "sunny" a "day". To umožňuje fulltextové vyhledávání těchto termínů. Pole typu Edm.String nebo Collection(Edm.String) jsou ve výchozím nastavení prohledávatelná. Tento atribut musí být false určený pro jednoduchá pole jiných datových typů, která nejsou součástí řetězce, a musí se jednat null o složitá pole.
Prohledávatelné pole spotřebovává v indexu nadbytečné místo, protože Azure AI Search zpracovává obsah těchto polí a uspořádá je v pomocných datových strukturách pro výkonné vyhledávání. Pokud chcete ušetřit místo v indexu a nepotřebujete pole, které by se mělo zahrnout do hledání, nastavte možnost hledání na falsehodnotu . Podrobnosti najdete v tématu Jak funguje fulltextové vyhledávání ve službě Azure AI Search . |
| filterable | Určuje, jestli se má na pole odkazovat v $filter dotazech. Filtrovatelné se liší od prohledávatelného způsobu zpracování řetězců. Pole typu Edm.String nebo Collection(Edm.String) filtrovatelné neprocházejí lexikální analýzou, takže porovnání jsou určená jenom pro přesné shody. Pokud například nastavíte takové pole f na "Slunečný den", $filter=f eq 'sunny' nenajde žádné shody, ale $filter=f eq 'Sunny day' bude. Tento atribut musí být null pro složitá pole. Výchozí hodnota je true pro jednoduchá pole a null pro složitá pole. Pokud chcete zmenšit velikost indexu, nastavte tento atribut na false pole, na která nebudete filtrovat. |
| sortable | Určuje, zda má být pole odkazováno ve $orderby výrazech. Ve výchozím nastavení Azure AI Search seřadí výsledky podle skóre, ale v mnoha prostředích uživatelé chtějí řadit podle polí v dokumentech. Jednoduché pole lze řadit pouze v případě, že je jednohodnotové (má jednu hodnotu v oboru nadřazeného dokumentu).
Jednoduchá pole kolekce nelze řadit, protože jsou vícehodnotová. Jednoduché podpole komplexních kolekcí jsou také vícehodnotové, a proto není možné řadit. To platí bez ohledu na to, jestli se jedná o okamžité nadřazené pole nebo nadřazené pole, což je složitá kolekce. Složitá pole nelze seřadit a atribut řazení musí být null pro taková pole. Výchozí možnost řazení je true pro jednoduchá pole s jednou hodnotou, false pro jednoduchá pole s více hodnotami a null pro složitá pole. |
| facetable | Určuje, jestli se má na pole odkazovat v dotazech omezující vlastnosti. Obvykle se používá v prezentaci výsledků hledání, která zahrnuje počet přístupů podle kategorií (například hledání digitálních fotoaparátů a zobrazení hitů podle značky, podle megapixelů, podle ceny atd.). Tento atribut musí být null pro složitá pole. Pole typu Edm.GeographyPoint nebo Collection(Edm.GeographyPoint) nemůžou být tabulkovatelná. Výchozí hodnota je true pro všechna ostatní jednoduchá pole. Pokud chcete zmenšit velikost indexu, nastavte tento atribut na false pole, na která nebudete omezující vlastnosti. |
| analyzátor | Nastaví lexikální analyzátor pro tokenizaci řetězců během indexování a operací dotazů. Platné hodnoty pro tuto vlastnost zahrnují analyzátory jazyka, integrované analyzátory a vlastní analyzátory. Výchozí hodnota je standard.lucene. Tento atribut lze použít pouze s prohledávatelnými poli řetězců a nelze jej nastavit společně s funkcí searchAnalyzer nebo indexAnalyzer. Jakmile je analyzátor vybrán a pole se vytvoří v indexu, nelze ho pro dané pole změnit. Musí se jednat null o složitá pole. |
| searchAnalyzer | Nastavte tuto vlastnost společně s indexAnalyzer pro určení různých lexikálních analyzátorů pro indexování a dotazy. Pokud použijete tuto vlastnost, nastavte analyzátor a null ujistěte se, že indexAnalyzer je nastaven na povolenou hodnotu. Platné hodnoty pro tuto vlastnost zahrnují integrované analyzátory a vlastní analyzátory. Tento atribut lze použít pouze s prohledávatelnými poli. Analyzátor vyhledávání je možné aktualizovat u existujícího pole, protože se používá jenom v době dotazu. Musí se jednat null o složitá pole]. |
| indexAnalyzer | Tuto vlastnost nastavte společně s funkcí searchAnalyzer a určete různé lexikální analyzátory pro indexování a dotazy. Pokud použijete tuto vlastnost, nastavte analyzátor na null a ujistěte se, že searchAnalyzer je nastavena na povolenou hodnotu. Platné hodnoty pro tuto vlastnost zahrnují integrované analyzátory a vlastní analyzátory. Tento atribut lze použít pouze s prohledávatelnými poli. Jakmile vyberete analyzátor indexu, nedá se pro dané pole změnit. Musí se jednat null o složitá pole. |
| synonymMaps | Seznam názvů map synonym, které se mají přidružit k tomuto poli. Tento atribut lze použít pouze s prohledávatelnými poli. V současné době je podporováno pouze jedno mapování synonym pro každé pole. Přiřazení mapování synonym k poli zajišťuje, aby se termíny dotazu, které cílí na toto pole, rozšířily v době dotazu pomocí pravidel v mapě synonym. Tento atribut lze změnit u existujících polí. Pro složitá pole musí být null nebo prázdná kolekce. |
| pole | Seznam dílčích polí, pokud se jedná o pole typu Edm.ComplexType nebo Collection(Edm.ComplexType). Pro jednoduchá pole musí být nebo musí být null prázdná. Další informace o tom, jak a kdy používat dílčí pole, najdete v tématu Modelování složitých datových typů ve službě Azure AI Search . |
Vytvoření indexu
Až budete připraveni vytvořit index, použijte vyhledávacího klienta, který může požadavek odeslat. K počátečnímu vývoji a testování konceptu můžete použít azure Portal nebo rozhraní REST API, jinak je běžné používat sady Azure SDK.
Během vývoje naplánujte časté opětovné sestavení. Vzhledem k tomu, že se ve službě vytvářejí fyzické struktury, je pro mnoho úprav nezbytné vyřazení a opětovné vytvoření indexů . Můžete zvážit, že budete pracovat s podmnožinou dat, aby opětovné sestavení bylo rychlejší.
Návrh indexu prostřednictvím webu Azure Portal vynucuje požadavky a pravidla schématu pro konkrétní datové typy, například zakázání funkcí fulltextového vyhledávání u číselných polí.
Přihlaste se k portálu Azure.
Zkontrolujte místo. Search podléhají maximálnímu počtu indexů, které se liší podle úrovně služby. Ujistěte se, že máte prostor pro druhý index.
Na stránce Přehled vyhledávací služby zvolte jednu z možností pro vytvoření indexu vyhledávání:
- Přidání indexu, vloženého editoru pro určení schématu indexu
- Průvodce importem
Průvodce je komplexní pracovní postup, který vytvoří indexer, zdroj dat a dokončený index. Načte také data. Pokud je to víc, než chcete, použijte místo toho přidat index .
Následující snímek obrazovky ukazuje, kde se na panelu příkazů zobrazí přidání indexu, importu dat a vektorizace dat .
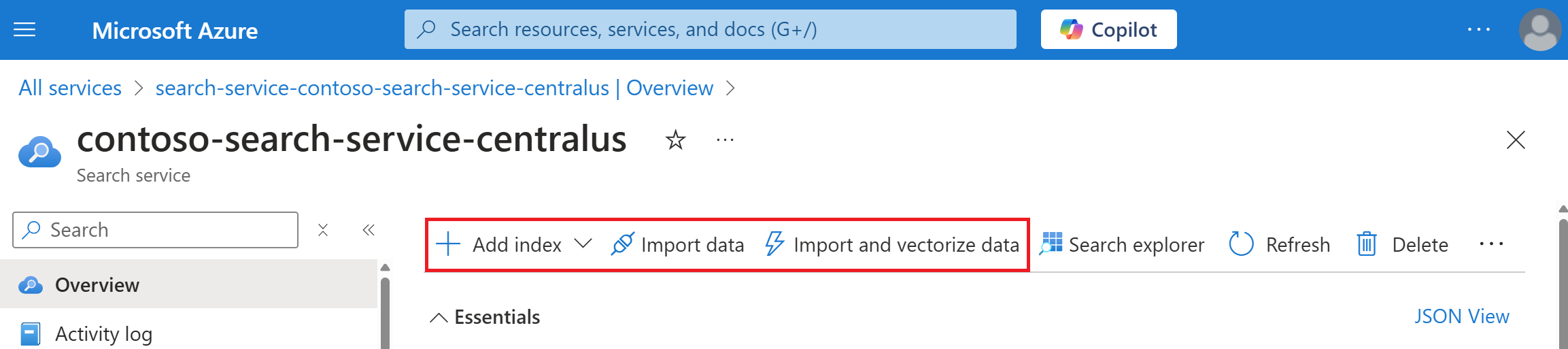
Po vytvoření indexu ho můžete znovu najít na stránce Indexy v levém navigačním podokně.
Tip
Po vytvoření indexu na webu Azure Portal můžete zkopírovat reprezentaci JSON a přidat ho do kódu aplikace.
Nastavení corsOptions pro dotazy mezi zdroji
Schémata indexu obsahují oddíl pro nastavení corsOptions. JavaScript na straně klienta ve výchozím nastavení nemůže volat žádná rozhraní API, protože prohlížeče brání všem požadavkům mezi zdroji. Pokud chcete povolit dotazy mezi zdroji prostřednictvím indexu, povolte CORS (sdílení prostředků mezi zdroji) nastavením atributu corsOptions . Z bezpečnostních důvodů podporují CORS jenom rozhraní API dotazů.
"corsOptions": {
"allowedOrigins": [
"*"
],
"maxAgeInSeconds": 300
Pro CORS je možné nastavit následující vlastnosti:
allowedOrigins (povinné): Toto je seznam původů, které mají povolený přístup k vašemu indexu. Kód JavaScriptu obsluhované z těchto zdrojů může dotazovat index (za předpokladu, že volající poskytuje platný klíč nebo má oprávnění). Každý původ je obvykle ve formuláři
protocol://<fully-qualified-domain-name>:<port>, i když<port>je často vynechán. Další informace najdete v tématu Sdílení prostředků mezi zdroji (Wikipedie).</a0> Pokud chcete povolit přístup ke všem zdrojům, zahrňte
*jako jednu položku do pole allowedOrigins . To není doporučený postup pro produkční vyhledávací služby , ale často je užitečný pro vývoj a ladění.maxAgeInSeconds (volitelné): Prohlížeče používají tuto hodnotu k určení doby trvání (v sekundách) pro ukládání předběžných odpovědí CORS do mezipaměti. Musí to být nezáporné celé číslo. Delší období mezipaměti poskytuje lepší výkon, ale prodlužuje dobu, po kterou se zásady CORS musí projevit. Pokud tato hodnota není nastavená, použije se výchozí doba trvání 5 minut.
Povolené aktualizace existujících indexů
Vytvořit index vytvoří ve vyhledávací službě fyzické datové struktury (soubory a invertované indexy). Po vytvoření indexu může vaše schopnost projevit změny pomocí funkce Vytvořit nebo Aktualizovat index na základě toho, jestli vaše úpravy zneplatní tyto fyzické struktury. Většinu atributů pole nelze po vytvoření pole v indexu změnit.
Pokud chcete minimalizovat četnost změn v kódu aplikace, můžete vytvořit alias indexu, který slouží jako stabilní odkaz na index vyhledávání. Místo aktualizace kódu názvy indexů můžete aktualizovat alias indexu tak, aby odkazovat na novější verze indexu.
Pokud chcete minimalizovat četnost změn v procesu návrhu, následující tabulka popisuje, které prvky jsou ve schématu pevné a flexibilní. Změna pevného prvku vyžaduje opětovné sestavení indexu, zatímco flexibilní prvky lze kdykoli změnit, aniž by to mělo vliv na fyzickou implementaci. Další informace naleznete v tématu Aktualizace nebo opětovné sestavení indexu.
| Element (Prvek) | Dá se aktualizovat? |
|---|---|
| Název | No |
| Klíč | No |
| Názvy a typy polí | No |
| Atributy pole (prohledávatelné, filtrovatelné, facetable, řazení) | No |
| Atribut pole (retrievable) | Ano |
| Uložené (platí pro vektory) | No |
| Analyzátor | Do indexu můžete přidat a upravit vlastní analyzátory. Pokud jde o přiřazení analyzátoru u řetězcových polí, můžete upravit searchAnalyzerpouze . Všechna ostatní přiřazení a úpravy vyžadují opětovné sestavení. |
| Profily skórování | Ano |
| Moduly pro návrhy | No |
| sdílení prostředků mezi zdroji (CORS) | Ano |
| Šifrování | Ano |
| Mapy synonym | Ano |
| Sémantická konfigurace | Ano |
Další kroky
Pomocí následujících odkazů se dozvíte o specializovaných funkcích, které je možné přidat do indexu:
- Přidání vektorových polí a vektorových profilů
- Přidání profilů bodování
- Přidání sémantického řazení
- Přidání navrhovačů
- Přidání map synonym
- Přidání analyzátorů
- Přidání šifrování
K načtení nebo aktualizaci indexu použijte tyto odkazy: