Rychlý start: Vytvoření sady dovedností na webu Azure Portal
V tomto rychlém startu se dozvíte, jak sada dovedností ve službě Azure AI Search přidává optické rozpoznávání znaků (OCR), analýzu obrázků, rozpoznávání jazyka, překlad textu a rozpoznávání entit za účelem generování prohledávatelného obsahu v indexu vyhledávání.
Průvodce importem dat můžete spustit na webu Azure Portal a použít dovednosti, které během indexování vytvářejí a transformují textový obsah. Vstup je nezpracovaná data, obvykle objekty blob ve službě Azure Storage. Výstup je prohledávatelný index obsahující text, titulky a entity vygenerované AI. Vygenerovaný obsah je možné dotazovat na webu Azure Portal pomocí Průzkumníka služby Search.
Před spuštěním průvodce vytvoříte několik prostředků a nahrajete ukázkové soubory.
Požadavky
Účet Azure s aktivním předplatným. Vytvoření účtu zdarma
Vytvořte Search Azure AI nebo vyhledejte existující službu. Pro účely tohoto rychlého startu můžete použít bezplatnou službu.
Účet azure Storage se službou Azure Blob Storage
Poznámka:
V tomto rychlém startu se pro transformace AI používají služby Azure AI. Vzhledem k tomu, že úloha je tak malá, služby Azure AI se na pozadí klepnou na bezplatné zpracování až na 20 transakcí. Toto cvičení můžete dokončit bez nutnosti vytvořit prostředek Azure AI s více službami.
Nastavení dat
V následujících krocích nastavte kontejner objektů blob ve službě Azure Storage tak, aby ukládaly heterogenní soubory obsahu.
Stáhněte si ukázková data sestávající z malé sady souborů různých typů.
Přihlaste se k webu Azure Portal pomocí svého účtu Azure.
Vytvořte účet Azure Storage nebo vyhledejte existující účet.
Pokud se chcete vyhnout poplatkům za šířku pásma, zvolte stejnou oblast jako Azure AI Search.
Zvolte StorageV2 (pro obecné účely V2).
Na webu Azure Portal otevřete stránku azure Storage a vytvořte kontejner. Můžete použít výchozí úroveň přístupu.
V kontejneru vyberte Nahrát a nahrajte ukázkové soubory. Všimněte si, že máte širokou škálu typů obsahu, včetně obrázků a souborů aplikací, které nejsou fulltextově prohledávatelné ve svých nativních formátech.
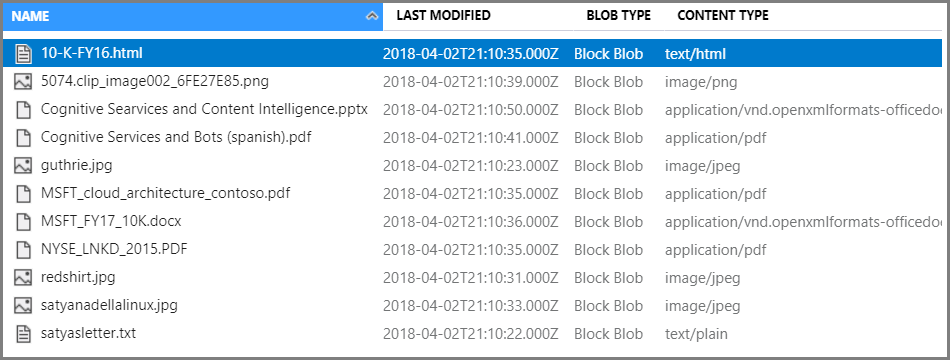
Teď jste připraveni přejít k průvodci importem dat.
Spuštění Průvodce importem dat
Přihlaste se k webu Azure Portal pomocí svého účtu Azure.
Vyhledejte vyhledávací službu. Na stránce Přehled vyberte Importovat data na panelu příkazů a vytvořte prohledávatelný obsah ve čtyřech krocích.
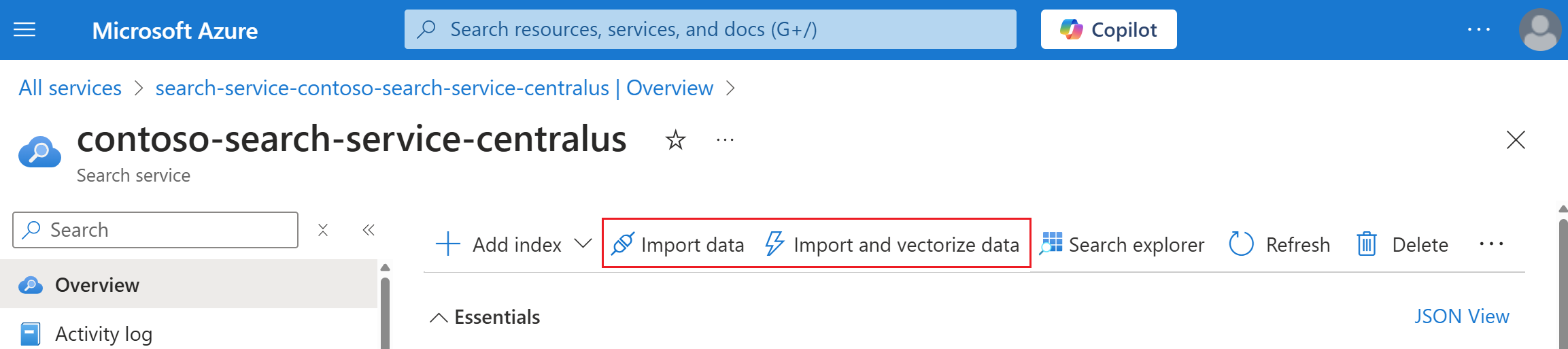
Krok 1: Vytvoření zdroje dat
V možnosti Připojit k datům zvolte Azure Blob Storage.
Zvolte existující připojení k účtu úložiště a vyberte kontejner, který jste vytvořili. Zadejte název pro zdroj dat a u ostatních položek nechejte výchozí hodnoty.
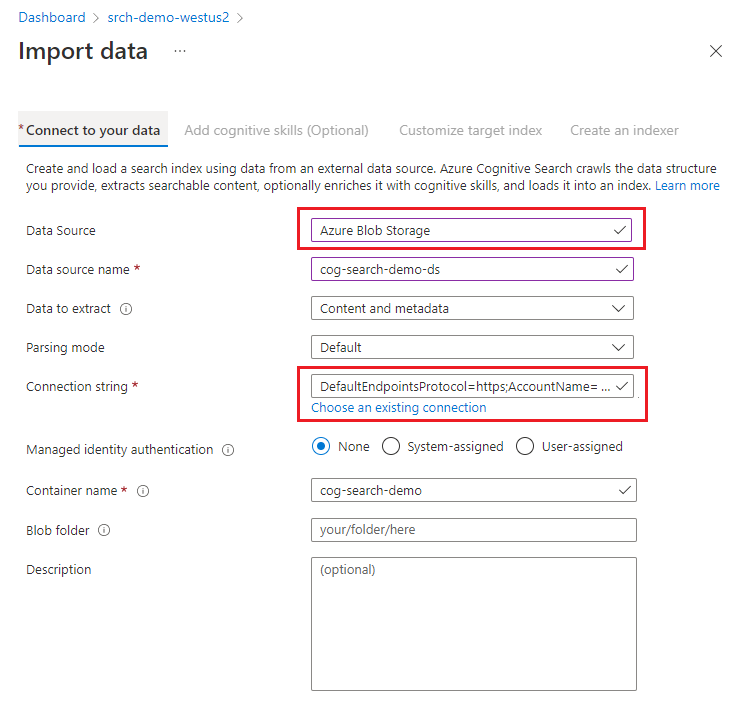
Pokračujte na další stránku.
Pokud se zobrazí chyba při zjišťování schématu indexu ze zdroje dat, indexer, který průvodce využívá, se nemůže připojit k vašemu zdroji dat. S největší pravděpodobností má zdroj dat ochranu zabezpečení. Zkuste následující řešení a spusťte průvodce znovu.
| Funkce zabezpečení | Řešení |
|---|---|
| Prostředek vyžaduje role Azure nebo jsou zakázané jeho přístupové klíče. | Připojení jako důvěryhodná služba nebo připojení pomocí spravované identity |
| Prostředek je za bránou firewall protokolu IP | Vytvoření příchozího pravidla pro vyhledávání a pro web Azure Portal |
| Prostředek vyžaduje připojení privátního koncového bodu. | Připojení přes privátní koncový bod |
Krok 2: Přidání kognitivních dovedností
Dále nakonfigurujte rozšiřování AI tak, aby vyvolávalo OCR, analýzu obrázků a zpracování přirozeného jazyka.
Analýza OCR a obrázků jsou k dispozici pro objekty blob ve službě Azure Blob Storage a Azure Data Lake Storage (ADLS) Gen2 a pro obsah obrázků ve OneLake. Obrázky můžou být samostatné soubory nebo vložené obrázky v PDF nebo jiných souborech.
Pro účely tohoto rychlého startu používáme prostředek bezplatných služeb Azure AI. Ukázková data se skládají ze 14 souborů, takže pro účely tohoto rychlého startu stačí bezplatné přidělení 20 transakcí ve službách Azure AI.
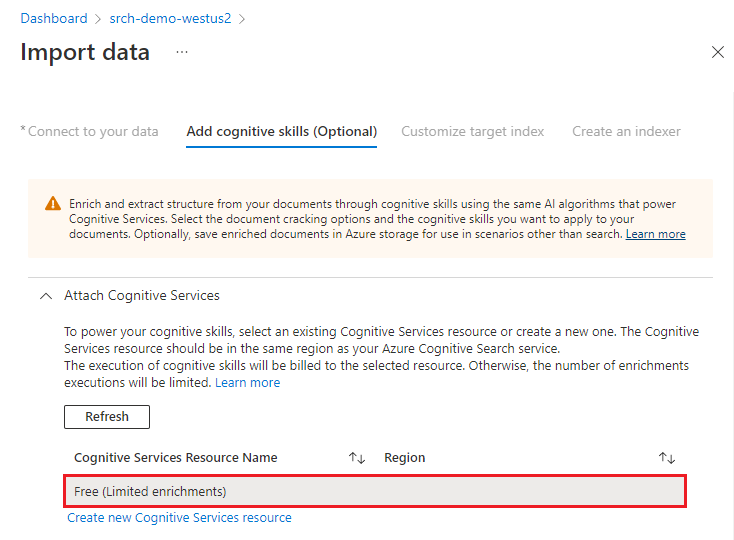
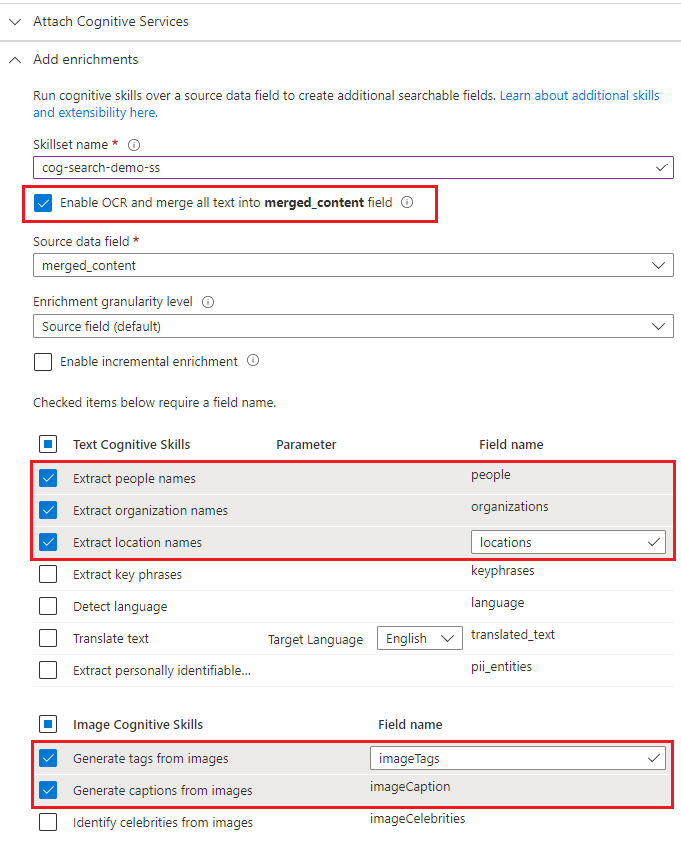
Rozbalte možnost Přidat rozšíření a proveďte šest výběrů.
Povolte funkci OCR, abyste mohli přidat dovednosti analýzy obrázků na stránku průvodce.
Zvolte rozpoznávání entit (lidé, organizace, umístění) a dovednosti analýzy obrázků (značky, titulky).
Pokračujte na další stránku.
Krok 3: Konfigurace indexu
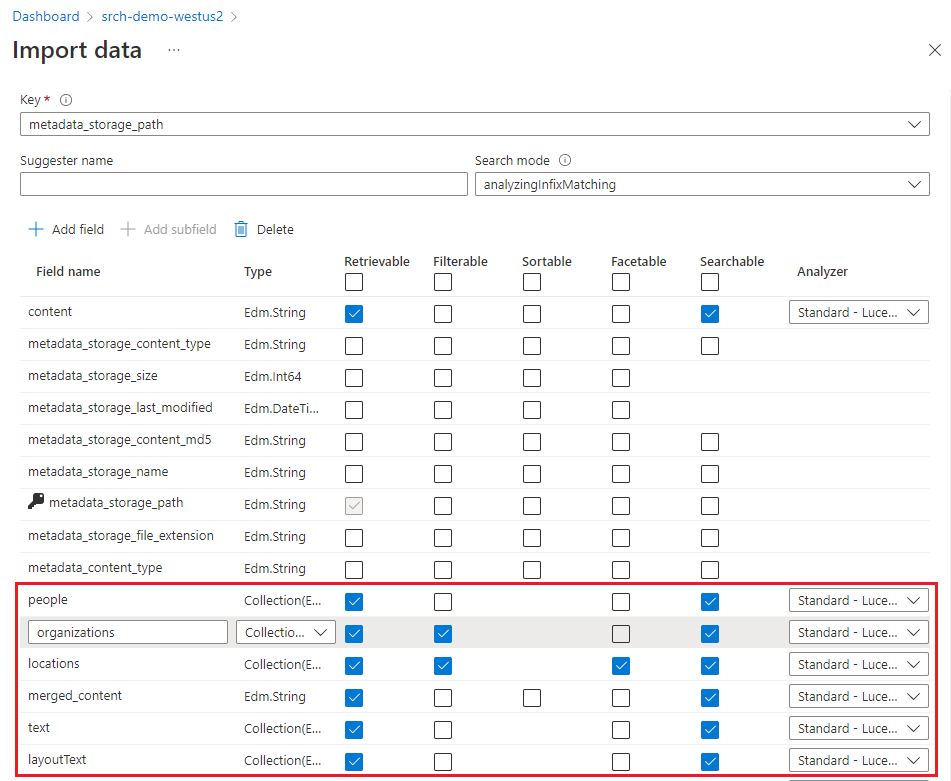
Index obsahuje prohledávatelný obsah a Průvodce importem dat obvykle může vytvořit schéma vzorkováním zdroje dat. V tomto kroku zkontrolujte vygenerované schéma a případně upravte všechna nastavení.
Pro tento rychlý start průvodce odvedl dobrou práci při nastavování rozumných výchozích hodnot:
Výchozí pole jsou založená na vlastnostech metadat existujících objektů blob a nová pole pro výstup rozšiřování (například
people, ,organizationslocations). Datové typy se odvozují z metadat a vzorkováním dat.Výchozí klíč dokumentu je metadata_storage_path (vybráno, protože pole obsahuje jedinečné hodnoty).
Výchozí atributy jsou načístelné a prohledávatelné. Prohledávatelné umožňuje fulltextové vyhledávání v poli. Načítání znamená, že hodnoty polí se dají vrátit ve výsledcích. Průvodce předpokládá, že chcete, aby tato pole byla načítaná a prohledávatelná, protože jste je vytvořili prostřednictvím sady dovedností. Pokud chcete použít pole ve výrazu filtru, vyberte Možnost Filtrovatelná .
Označení pole jako zobrazitelné neznamená, že pole musí být ve výsledcích hledání. Složení výsledků hledání můžete řídit pomocí parametru výběrového dotazu a určit, která pole se mají zahrnout.
Pokračujte na další stránku.
Krok 4: Konfigurace indexeru
Indexer řídí proces indexování. Určuje název zdroje dat, cílový index a frekvenci provádění. Průvodce importem dat vytvoří několik objektů, včetně indexeru, který můžete obnovit a spustit opakovaně.
Na stránce Indexer přijměte výchozí název a vyberte Jednou.
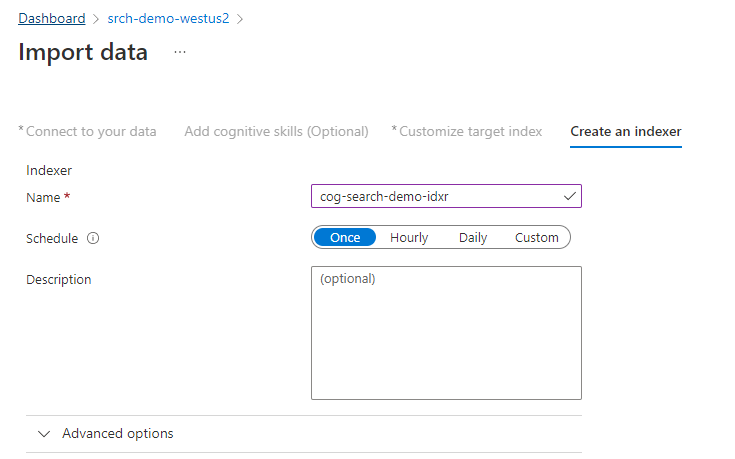
Výběrem možnosti Odeslat vytvořte indexer a spusťte ho současně.
Monitorovat stav
V levém navigačním podokně vyberte Indexery , abyste mohli monitorovat stav, a pak vyberte indexer. Indexování založené na dovednostech trvá déle než indexování založené na textu, zejména analýzy OCR a obrázků.
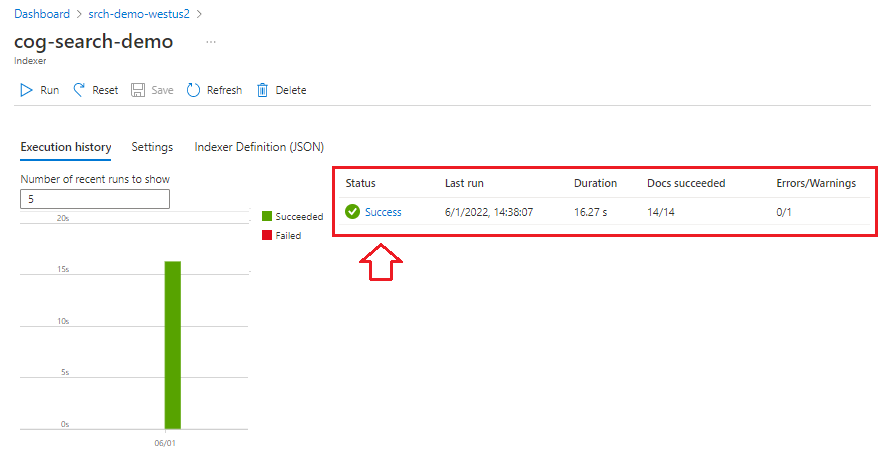
Pokud chcete zobrazit podrobnosti o stavu spuštění, vyberte Úspěch (nebo Neúspěšné) a zobrazte podrobnosti o spuštění.
V této ukázce existuje několik upozornění: "Nepodařilo se spustit dovednost, protože jeden nebo více vstupů dovedností bylo neplatné." Říká vám, že soubor PNG ve zdroji dat neposkytuje textový vstup do rozpoznávání entit. K tomuto upozornění dochází, protože upstreamová dovednost OCR nerozpoznala žádný text na obrázku, a proto nemohla poskytnout textový vstup dovednosti rozpoznávání entit podřízené entitě.
Upozornění jsou při provádění sady dovedností běžná. Až se seznámíte s iterací dovedností nad daty, můžete si začít všimnout vzorů a zjistit, která upozornění se dají bezpečně ignorovat.
Dotaz v Průzkumníku služby Hledání
Po vytvoření indexu použijte Průzkumníka služby Search k vrácení výsledků.
Na levé straně vyberte Indexy a pak vyberte index. Průzkumník služby Search je na první kartě.
Zadejte hledaný řetězec pro dotazování indexu, například
satya nadella. Vyhledávací panel přijímá klíčová slova, uvozovky uzavřené fráze a operátory:"Satya Nadella" +"Bill Gates" +"Steve Ballmer"
Výsledky se vrací jako podrobný formát JSON, který může být obtížně čitelný, zejména ve velkých dokumentech. Mezi tipy pro vyhledávání v tomto nástroji patří následující techniky:
Přepněte do zobrazení JSON a zadejte parametry, které tvarují výsledky.
Přidáním
selectomezíte pole ve výsledcích.Přidejte
count, aby se zobrazil počet shod.Pomocí kombinace kláves CTRL-F vyhledejte ve formátu JSON konkrétní vlastnosti nebo termíny.
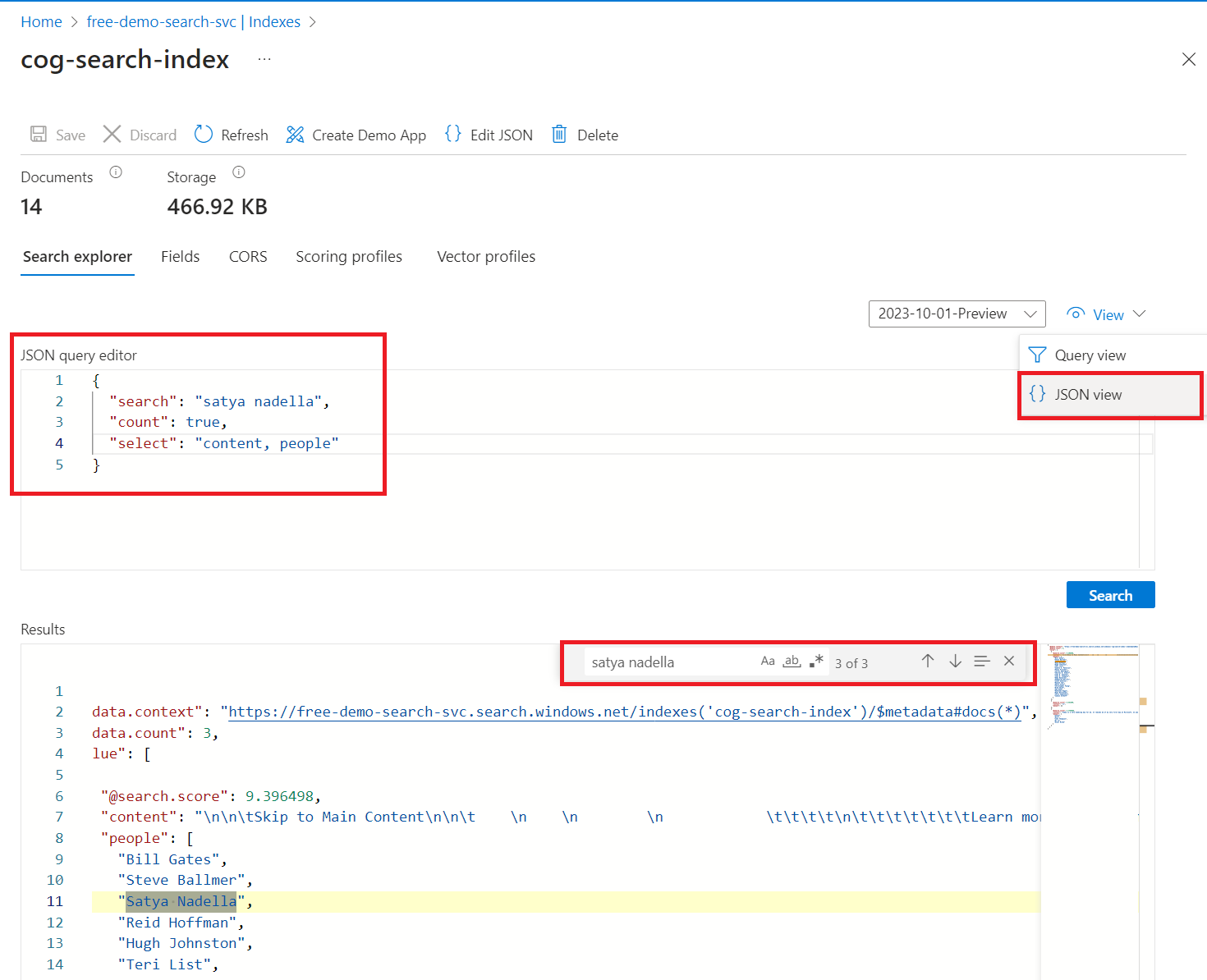
Tady je několik JSON, které můžete vložit do zobrazení:
{
"search": "\"Satya Nadella\" +\"Bill Gates\" +\"Steve Ballmer\"",
"count": true,
"select": "content, people"
}
Tip
Řetězce dotazů rozlišují malá a velká písmena, takže pokud se zobrazí zpráva "neznámé pole", zkontrolujte pole nebo definici indexu (JSON) a ověřte název a malá písmena.
Shrnutí
Teď jste vytvořili svou první sadu dovedností a naučili jste se základní kroky indexování založené na dovednostech.
Mezi klíčové koncepty, které doufáme, že jste získali, patří závislosti. Sada dovedností je svázaná s indexerem a indexery jsou specifické pro Azure a zdroj. I když tento rychlý start používá Službu Azure Blob Storage, jsou možné i jiné zdroje dat Azure. Další informace najdete v tématu Indexery ve službě Azure AI Search.
Dalším důležitým konceptem je, že dovednosti pracují s typy obsahu a při práci s heterogenním obsahem se některé vstupy přeskočí. Velké soubory nebo pole také můžou překročit limity indexeru vaší úrovně služby. Při výskytu těchto událostí je normální zobrazit upozornění.
Výstup se směruje do indexu vyhledávání a mezi páry název-hodnota vytvořenými během indexování a jednotlivých polí v indexu je mapování. Průvodce interně nastaví strom rozšiřování a definuje sadu dovedností a určí pořadí operací a obecného toku. Tyto kroky jsou v průvodci skryté, ale když začnete psát kód, stanou se tyto koncepty důležité.
Nakonec jste se dozvěděli, že můžete ověřit obsah dotazováním indexu. Na konci je to, co Azure AI Search poskytuje, prohledávatelný index, který můžete dotazovat pomocí jednoduché nebo plně rozšířené syntaxe dotazu. Index, který obsahuje rozšířená pole, se v ničem neliší od ostatních indexů. Můžete začlenit standardní nebo vlastní analyzátory, bodovací profily, synonyma, fasetovou navigaci, geografické vyhledávání nebo jakoukoli jinou funkci Azure AI Search.
Vyčištění prostředků
Pokud pracujete s vlastním předplatným, je vhodné vždy na konci projektu zkontrolovat, jestli budete vytvořené prostředky ještě potřebovat. Prostředky, které necháte spuštěné, vás stojí peníze. Prostředky můžete odstraňovat jednotlivě nebo můžete odstranit skupinu prostředků, a odstranit tak celou sadu prostředků najednou.
Prostředky můžete najít a spravovat na webu Azure Portal pomocí odkazu Všechny prostředky nebo skupiny prostředků v levém navigačním podokně.
Pokud jste použili bezplatnou službu, mějte na paměti, že jste omezeni na tři indexy, indexery a zdroje dat. Jednotlivé položky na webu Azure Portal můžete odstranit, abyste zůstali pod limitem.
Další krok
Sady dovedností můžete vytvářet pomocí webu Azure Portal, sady .NET SDK nebo rozhraní REST API. Pro další znalosti vyzkoušejte rozhraní REST API pomocí klienta REST a dalších ukázkových dat.