Vysoká dostupnost pro SAP HANA na virtuálních počítačích Azure na serveru SUSE Linux Enterprise Server
Pokud chcete vytvořit vysokou dostupnost v místním nasazení SAP HANA, můžete použít replikaci systému SAP HANA nebo sdílené úložiště.
V současné době je replikace systému SAP HANA v Azure na virtuálních počítačích Azure jedinou podporovanou funkcí s vysokou dostupností.
Replikace systému SAP HANA se skládá z jednoho primárního uzlu a alespoň jednoho sekundárního uzlu. Změny dat v primárním uzlu se replikují do sekundárního uzlu synchronně nebo asynchronně.
Tento článek popisuje, jak nasadit a nakonfigurovat virtuální počítače, nainstalovat architekturu clusteru a nainstalovat a nakonfigurovat replikaci systému SAP HANA.
Než začnete, přečtěte si následující poznámky a dokumenty SAP:
- SAP Note 1928533. Poznámka obsahuje:
- Seznam velikostí virtuálních počítačů Azure, které jsou podporované pro nasazení softwaru SAP.
- Důležité informace o kapacitě pro velikosti virtuálních počítačů Azure
- Podporované kombinace softwaru SAP, operačního systému a databáze.
- Požadované verze jádra SAP pro Windows a Linux v Microsoft Azure.
- SAP Note 2015553 uvádí požadavky pro nasazení softwaru SAP s podporou SAP v Azure.
- SAP Note 2205917 doporučuje nastavení operačního systému pro SUSE Linux Enterprise Server 12 (SLES 12) pro aplikace SAP.
- SAP Note 2684254 doporučuje nastavení operačního systému pro SUSE Linux Enterprise Server 15 (SLES 15) pro aplikace SAP.
- SAP Note 2235581 má podporované operační systémy SAP HANA
- SAP Note 2178632 obsahuje podrobné informace o všech metrikách monitorování, které jsou hlášeny pro SAP v Azure.
- SAP Note 2191498 má požadovanou verzi agenta hostitele SAP pro Linux v Azure.
- SAP Note 2243692 obsahuje informace o licencování SAP pro Linux v Azure.
- SAP Note 1984787 obsahuje obecné informace o SUSE Linux Enterprise Serveru 12.
- SAP Note 1999351 obsahuje další informace o řešení potíží pro rozšíření rozšířeného monitorování Azure pro SAP.
- SAP Note 401162 obsahuje informace o tom, jak se při nastavování replikace systému HANA vyhnout chybám adresy, které se už používají.
- Wikiweb podpory komunity SAP obsahuje všechny požadované poznámky SAP pro Linux.
- Platformy SAP HANA Certified IaaS
- Průvodce plánováním a implementací azure Virtual Machines pro SAP v Linuxu
- Průvodce nasazením služby Azure Virtual Machines pro SAP v Linuxu
- Průvodce nasazením DBMS ve službě Azure Virtual Machines pro SAP v Linuxu
- Osvědčené postupy pro SUSE Linux Enterprise Server for SAP Applications 15 a příručky s osvědčenými postupy pro SUSE Linux Enterprise Server for SAP Applications 12:
- Nastavení infrastruktury optimalizované pro výkon sr SAP HANA (SLES pro aplikace SAP) Tato příručka obsahuje všechny požadované informace pro nastavení systémové replikace SAP HANA pro místní vývoj. Tuto příručku použijte jako směrný plán.
- Nastavení infrastruktury optimalizované pro službu SAP HANA SR (SLES pro aplikace SAP)
Plánování vysoké dostupnosti SAP HANA
Pokud chcete dosáhnout vysoké dostupnosti, nainstalujte SAP HANA na dva virtuální počítače. Data se replikují pomocí systémové replikace HANA.
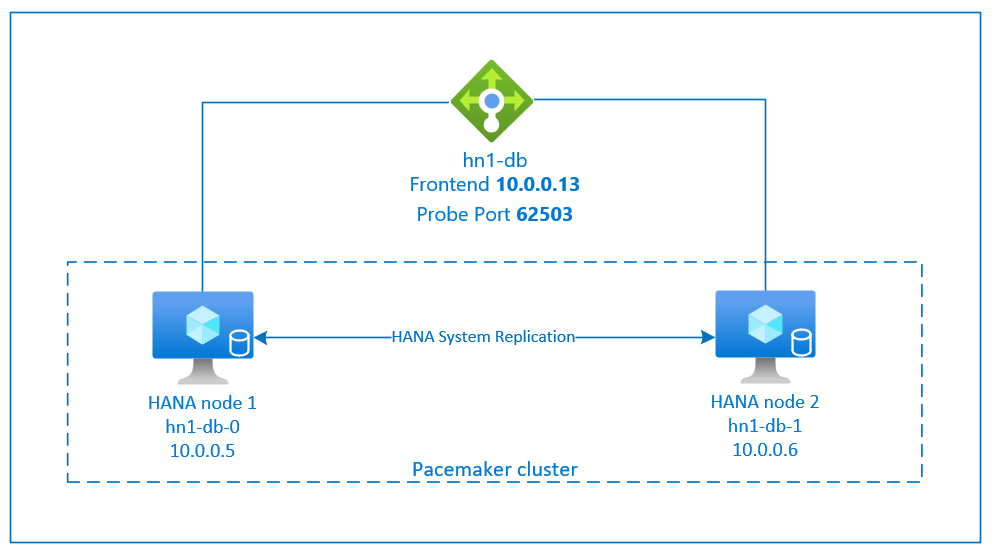
Nastavení replikace systému SAP HANA používá vyhrazený název virtuálního hostitele a virtuální IP adresy. V Azure potřebujete nástroj pro vyrovnávání zatížení pro nasazení virtuální IP adresy.
Předchozí obrázek ukazuje příklad nástroje pro vyrovnávání zatížení, který má tyto konfigurace:
- Front-endová IP adresa: 10.0.0.13 pro HN1-db
- Port sondy: 62503
Příprava infrastruktury
Agent prostředků pro SAP HANA je součástí SUSE Linux Enterprise Serveru pro aplikace SAP. Image pro SUSE Linux Enterprise Server pro SAP Applications 12 nebo 15 je k dispozici na Azure Marketplace. Image můžete použít k nasazení nových virtuálních počítačů.
Ruční nasazení virtuálních počítačů s Linuxem prostřednictvím webu Azure Portal
Tento dokument předpokládá, že jste už nasadili skupinu prostředků, virtuální síť Azure a podsíť.
Nasazení virtuálních počítačů pro SAP HANA Zvolte vhodný obrázek SLES, který je podporovaný pro systém HANA. Virtuální počítač můžete nasadit v libovolné z možností dostupnosti – škálovací sada virtuálních počítačů, zóna dostupnosti nebo skupina dostupnosti.
Důležité
Ujistěte se, že vybraný operační systém má certifikaci SAP pro SAP HANA na konkrétních typech virtuálních počítačů, které plánujete použít ve svém nasazení. V platformách SAP HANA Certified IaaS můžete vyhledat typy virtuálních počítačů certifikovaných pro SAP HANA a jejich vydání operačního systému. Ujistěte se, že se podíváte na podrobnosti o typu virtuálního počítače, abyste získali úplný seznam vydaných verzí operačního systému podporovaných SAP HANA pro konkrétní typ virtuálního počítače.
Konfigurace nástroje pro vyrovnávání zatížení Azure
Během konfigurace virtuálního počítače máte možnost vytvořit nebo vybrat ukončení nástroje pro vyrovnávání zatížení v části Sítě. Pokud chcete nastavit standardní nástroj pro vyrovnávání zatížení pro nastavení databáze HANA s vysokou dostupností, postupujte podle následujících kroků.
Postupujte podle kroků v tématu Vytvoření nástroje pro vyrovnávání zatížení a nastavte standardní nástroj pro vyrovnávání zatížení pro systém SAP s vysokou dostupností pomocí webu Azure Portal. Při nastavování nástroje pro vyrovnávání zatížení zvažte následující body:
- Konfigurace front-endové IP adresy: Vytvořte front-endovou IP adresu. Vyberte stejnou virtuální síť a název podsítě jako vaše databázové virtuální počítače.
- Back-endový fond: Vytvořte back-endový fond a přidejte databázové virtuální počítače.
- Příchozí pravidla: Vytvořte pravidlo vyrovnávání zatížení. U obou pravidel vyrovnávání zatížení postupujte stejně.
- IP adresa front-endu: Vyberte front-endovou IP adresu.
- Back-endový fond: Vyberte back-endový fond.
- Porty s vysokou dostupností: Tuto možnost vyberte.
- Protokol: Vyberte TCP.
- Sonda stavu: Vytvořte sondu stavu s následujícími podrobnostmi:
- Protokol: Vyberte TCP.
- Port: Například 625<instance-no.>.
- Interval: Zadejte 5.
- Prahová hodnota sondy: Zadejte 2.
- Časový limit nečinnosti (minuty):Zadejte 30.
- Povolit plovoucí IP adresu: Vyberte tuto možnost.
Poznámka:
Vlastnost numberOfProbeskonfigurace sondy stavu , jinak označovaná jako prahová hodnota není v pořádku na portálu, se nerespektuje. Chcete-li řídit počet úspěšných nebo neúspěšných po sobě jdoucích sond, nastavte vlastnost probeThreshold na 2hodnotu . V současné době není možné tuto vlastnost nastavit pomocí webu Azure Portal, takže použijte buď Azure CLI, nebo příkaz PowerShellu.
Další informace o požadovaných portech pro SAP HANA najdete v kapitole Připojení k databázím tenantů v průvodci databázemi tenantů SAP HANA nebo v 2388694 SAP Note.
Poznámka:
Pokud se virtuální počítače, které nemají veřejné IP adresy, umístí do back-endového fondu interní (bez veřejné IP adresy) standardní instance Azure Load Balanceru, výchozí konfigurace není odchozí připojení k internetu. Můžete provést další kroky, které umožní směrování do veřejných koncových bodů. Podrobnosti o tom, jak dosáhnout odchozího připojení, najdete v tématu Připojení k veřejnému koncovému bodu pro virtuální počítače pomocí Azure Standard Load Balanceru ve scénářích s vysokou dostupností SAP.
Důležité
- Nepovolujte časové razítka TCP na virtuálních počítačích Azure, které jsou umístěné za Azure Load Balancerem. Povolení časových razítek PROTOKOLU TCP způsobí selhání sond stavu. Nastavte parametr
net.ipv4.tcp_timestampsna0. Podrobnosti najdete v sondách stavu Load Balanceru nebo 2382421 SAP. - Chcete-li zabránit saptune změnit ručně nastavenou
net.ipv4.tcp_timestampshodnotu zpět0na1, aktualizujte saptune verze na 3.1.1 nebo vyšší. Další podrobnosti najdete v tématu saptune 3.1.1 – Musím aktualizovat?.
Vytvoření clusteru Pacemaker
Postupujte podle kroků v tématu Nastavení Pacemakeru na serveru SUSE Linux Enterprise Server v Azure a vytvořte základní cluster Pacemaker pro tento server HANA. Stejný cluster Pacemaker můžete použít pro SAP HANA a SAP NetWeaver (A)SCS.
Instalace SAP HANA
Kroky v této části používají následující předpony:
- [A]: Tento krok platí pro všechny uzly.
- [1]: Krok se vztahuje pouze na uzel 1.
- [2]: Krok se vztahuje pouze na uzel 2 clusteru Pacemaker.
Nahraďte <placeholders> hodnotami pro instalaci SAP HANA.
[A] Nastavení rozložení disku pomocí Správce logických svazků (LVM).
Doporučujeme použít LVM pro svazky, které ukládají data a soubory protokolů. Následující příklad předpokládá, že virtuální počítače mají čtyři připojené datové disky, které se používají k vytvoření dvou svazků.
Spuštěním tohoto příkazu zobrazte seznam všech dostupných disků:
ls /dev/disk/azure/scsi1/lun*Příklad výstupu:
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2 /dev/disk/azure/scsi1/lun3Vytvořte fyzické svazky pro všechny disky, které chcete použít:
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2 sudo pvcreate /dev/disk/azure/scsi1/lun3Vytvořte skupinu svazků pro datové soubory. Pro soubory protokolů a jednu skupinu svazků pro sdílený adresář SAP HANA použijte jednu skupinu svazků:
sudo vgcreate vg_hana_data_<HANA SID> /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_<HANA SID> /dev/disk/azure/scsi1/lun2 sudo vgcreate vg_hana_shared_<HANA SID> /dev/disk/azure/scsi1/lun3Vytvořte logické svazky.
Lineární svazek se vytvoří, když použijete
lvcreatebez-ipřepínače. Doporučujeme vytvořit pruhovaný svazek pro lepší výkon vstupně-výstupních operací. Zarovnejte velikosti pruhů s hodnotami popsanými v konfiguracích úložiště virtuálních počítačů SAP HANA. Argumentem-iby měl být počet základních fyzických svazků a-Iargumentem je velikost pruhu.Pokud se například pro datový svazek používají dva fyzické svazky,
-ije argument přepínače nastaven na hodnotu 2 a velikost pruhu datového svazku je 256KiB. Jeden fyzický svazek se používá pro svazek protokolu, takže pro příkazy svazku protokolu se explicitně nepoužívají žádné-inebo-Ipřepínače.Důležité
Pokud pro každý datový svazek, svazek protokolu nebo sdílený svazek používáte více než jeden fyzický svazek, použijte
-ipřepínač a nastavte ho na počet podkladových fyzických svazků. Při vytváření pruhovaného svazku-Ipoužijte přepínač k určení velikosti pruhu.Doporučené konfigurace úložiště, včetně velikostí prokládání a počtu disků, najdete v tématu Konfigurace úložiště virtuálních počítačů SAP HANA.
sudo lvcreate <-i number of physical volumes> <-I stripe size for the data volume> -l 100%FREE -n hana_data vg_hana_data_<HANA SID> sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_<HANA SID> sudo lvcreate -l 100%FREE -n hana_shared vg_hana_shared_<HANA SID> sudo mkfs.xfs /dev/vg_hana_data_<HANA SID>/hana_data sudo mkfs.xfs /dev/vg_hana_log_<HANA SID>/hana_log sudo mkfs.xfs /dev/vg_hana_shared_<HANA SID>/hana_sharedVytvořte adresáře připojení a zkopírujte univerzální jedinečný identifikátor (UUID) všech logických svazků:
sudo mkdir -p /hana/data/<HANA SID> sudo mkdir -p /hana/log/<HANA SID> sudo mkdir -p /hana/shared/<HANA SID> # Write down the ID of /dev/vg_hana_data_<HANA SID>/hana_data, /dev/vg_hana_log_<HANA SID>/hana_log, and /dev/vg_hana_shared_<HANA SID>/hana_shared sudo blkidUpravte soubor /etc/fstab a vytvořte
fstabpoložky pro tři logické svazky:sudo vi /etc/fstabDo souboru /etc/fstab vložte následující řádky:
/dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_data_<HANA SID>-hana_data> /hana/data/<HANA SID> xfs defaults,nofail 0 2 /dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_log_<HANA SID>-hana_log> /hana/log/<HANA SID> xfs defaults,nofail 0 2 /dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_shared_<HANA SID>-hana_shared> /hana/shared/<HANA SID> xfs defaults,nofail 0 2Připojte nové svazky:
sudo mount -a
[A] Nastavte rozložení disku pomocí prostých disků.
V případě ukázkových systémů můžete data HANA a soubory protokolů umístit na jeden disk.
Vytvořte oddíl na /dev/disk/azure/scsi1/lun0 a naformátujte ho pomocí XFS:
sudo sh -c 'echo -e "n\n\n\n\n\nw\n" | fdisk /dev/disk/azure/scsi1/lun0' sudo mkfs.xfs /dev/disk/azure/scsi1/lun0-part1 # Write down the ID of /dev/disk/azure/scsi1/lun0-part1 sudo /sbin/blkid sudo vi /etc/fstabVložte tento řádek do souboru /etc/fstab :
/dev/disk/by-uuid/<UUID> /hana xfs defaults,nofail 0 2Vytvořte cílový adresář a připojte disk:
sudo mkdir /hana sudo mount -a
[A] Nastavte překlad názvů hostitelů pro všechny hostitele.
Můžete použít server DNS nebo upravit soubor /etc/hosts na všech uzlech. Tento příklad ukazuje, jak používat soubor /etc/hosts . V následujících příkazech nahraďte IP adresy a názvy hostitelů.
Upravte soubor /etc/hosts:
sudo vi /etc/hostsDo souboru /etc/hosts vložte následující řádky. Změňte IP adresy a názvy hostitelů tak, aby odpovídaly vašemu prostředí.
10.0.0.5 hn1-db-0 10.0.0.6 hn1-db-1
[A] Nainstalujte SAP HANA podle dokumentace k SAP.
Konfigurace systémové replikace SAP HANA 2.0
Kroky v této části používají následující předpony:
- [A]: Tento krok platí pro všechny uzly.
- [1]: Krok se vztahuje pouze na uzel 1.
- [2]: Krok se vztahuje pouze na uzel 2 clusteru Pacemaker.
Nahraďte <placeholders> hodnotami pro instalaci SAP HANA.
[1] Vytvořte databázi tenanta.
Pokud používáte SAP HANA 2.0 nebo SAP HANA MDC, vytvořte pro svůj systém SAP NetWeaver databázi tenanta.
Spusťte následující příkaz jako <adm HANA SID>:
hdbsql -u SYSTEM -p "<password>" -i <instance number> -d SYSTEMDB 'CREATE DATABASE <SAP SID> SYSTEM USER PASSWORD "<password>"'[1] Nakonfigurujte replikaci systému na prvním uzlu:
Nejprve zálohujte databáze jako <adm HANA SID>:
hdbsql -d SYSTEMDB -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for SYS>')" hdbsql -d <HANA SID> -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for HANA SID>')" hdbsql -d <SAP SID> -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for SAP SID>')"Potom zkopírujte soubory infrastruktury veřejných klíčů systému (PKI) do sekundární lokality:
scp /usr/sap/<HANA SID>/SYS/global/security/rsecssfs/data/SSFS_<HANA SID>.DAT hn1-db-1:/usr/sap/<HANA SID>/SYS/global/security/rsecssfs/data/ scp /usr/sap/<HANA SID>/SYS/global/security/rsecssfs/key/SSFS_<HANA SID>.KEY hn1-db-1:/usr/sap/<HANA SID>/SYS/global/security/rsecssfs/key/Vytvořte primární lokalitu:
hdbnsutil -sr_enable --name=<site 1>[2] Nakonfigurujte replikaci systému na druhém uzlu:
Zaregistrujte druhý uzel a spusťte replikaci systému.
Spusťte následující příkaz jako <adm HANA SID>:
sapcontrol -nr <instance number> -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2>
Implementace agentů prostředků HANA
SUSE poskytuje dva různé softwarové balíčky pro agenta prostředků Pacemaker pro správu SAP HANA. Softwarové balíčky SAPHanaSR a SAPHanaSR-angi používají mírně odlišnou syntaxi a parametry a nejsou kompatibilní. Podrobnosti a rozdíly mezi SAPHanaSR a SAPHanaSR-angi najdete v poznámkách k verzi SUSE a dokumentaci . Tento dokument popisuje oba balíčky na samostatných kartách v příslušných oddílech.
Upozorňující
Nenahrazovat balíček SAPHanaSR sapHanaSR-angi v již nakonfigurovaném clusteru. Upgrade ze SAPHanaSR na SAPHanaSR-angi vyžaduje konkrétní postup.
- [A] Nainstalujte balíčky s vysokou dostupností SAP HANA:
Spuštěním následujícího příkazu nainstalujte balíčky s vysokou dostupností:
sudo zypper install SAPHanaSR
Nastavení poskytovatelů vysoké dostupnosti /zotavení po havárii SAP HANA
Poskytovatelé vysoké dostupnosti a zotavení po havárii SAP HANA optimalizují integraci s clusterem a vylepšují detekci v případě potřeby převzetí služeb při selhání clusteru. Hlavním skriptem hooku je SAPHanaSR (pro balíček SAPHanaSR) / susHanaSR (pro SAPHanaSR-angi). Důrazně doporučujeme nakonfigurovat háček Pythonu SAPHanaSR/susHanaSR. Pro HANA 2.0 SPS 05 a novější doporučujeme implementovat sapHanaSR/susHanaSR i susChkSrv háky.
Háček susChkSrv rozšiřuje funkčnost hlavního poskytovatele SAPHanaSR/susHanaSR HA. Funguje, když se proces HANA hdbindexserver chybově ukončí. Pokud dojde k chybovému ukončení jednoho procesu, hana se obvykle pokusí restartovat. Restartování procesu indexserveru může trvat dlouhou dobu, během které databáze HANA nereaguje.
Při implementaci susChkSrv se provede okamžitá a konfigurovatelná akce. Akce aktivuje převzetí služeb při selhání v nakonfigurované době časového limitu místo čekání na restartování procesu serveru hdbindex na stejném uzlu.
- [A] Zastavte HANA na obou uzlech.
Spusťte následující kód jako <adm sap-sid>:
sapcontrol -nr <instance number> -function StopSystem
[A] Nainstalujte háky replikace systému HANA. Háky musí být nainstalované na obou databázových uzlech HANA.
Tip
Hook SAPHanaSR Python je možné implementovat pouze pro HANA 2.0. Balíček SAPHanaSR musí být minimálně verze 0.153.
Háček SAPHanaSR-angi Python lze implementovat pouze pro HANA 2.0 SPS 05 a novější.
Háček susChkSrv Python vyžaduje SAP HANA 2.0 SPS 05 a musí být nainstalovaná verze SAPHanaSR 0.161.1_BF nebo novější.[A] Upravte global.ini na každém uzlu clusteru.
Pokud nejsou splněny požadavky na háček susChkSrv, odeberte celý
[ha_dr_provider_suschksrv]blok z následujících parametrů. ChovánísusChkSrvmůžete upravit pomocí parametruaction_on_lost. Platné hodnoty jsou [ignorefence| |stop|kill].[ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /usr/share/SAPHanaSR execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR execution_order = 3 action_on_lost = fence [trace] ha_dr_saphanasr = infoPokud odkazujete na cestu parametru na výchozí
/usr/share/SAPHanaSRumístění, kód háku Pythonu se automaticky aktualizuje prostřednictvím aktualizací operačního systému nebo aktualizací balíčků. HANA při příštím restartování používá aktualizace kódu hooku. S volitelnou vlastní cestou, jako/hana/shared/myHooksje , můžete oddělit aktualizace operačního systému od verze háku, kterou používáte.[A] Cluster vyžaduje konfiguraci sudoers na každém uzlu clusteru pro <adm sap-sid>. V tomto příkladu toho dosáhnete vytvořením nového souboru.
Spusťte následující příkaz jako kořen. Nahraďte <sid> malými písmeny ID systému SAP, <SID> velkými písmeny SAP system ID a <siteA/B> zvolenými názvy webů HANA.
cat << EOF > /etc/sudoers.d/20-saphana # Needed for SAPHanaSR and susChkSrv Python hooks Cmnd_Alias SOK_SITEA = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteA> -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEA = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteA> -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SOK_SITEB = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteB> -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEB = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteB> -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias HELPER_TAKEOVER = /usr/sbin/SAPHanaSR-hookHelper --sid=<SID> --case=checkTakeover Cmnd_Alias HELPER_FENCE = /usr/sbin/SAPHanaSR-hookHelper --sid=<SID> --case=fenceMe <sid>adm ALL=(ALL) NOPASSWD: SOK_SITEA, SFAIL_SITEA, SOK_SITEB, SFAIL_SITEB, HELPER_TAKEOVER, HELPER_FENCE EOF
Podrobnosti o implementaci háku replikace systému SAP HANA najdete v tématu Nastavení poskytovatelů HA/DR pro HANA.
[A] Spusťte SAP HANA na obou uzlech. Spusťte následující příkaz jako <sap-sid>adm:
sapcontrol -nr <instance number> -function StartSystem[1] Ověřte instalaci háku. V aktivní lokalitě replikace systému HANA spusťte následující příkaz jako <adm sap-sid>:
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_* # Example output # 2021-04-08 22:18:15.877583 ha_dr_SAPHanaSR SFAIL # 2021-04-08 22:18:46.531564 ha_dr_SAPHanaSR SFAIL # 2021-04-08 22:21:26.816573 ha_dr_SAPHanaSR SOK
- [1] Ověřte instalaci háku susChkSrv.
Na virtuálních počítačích HANA spusťte následující příkaz jako <adm sap-sid>:
cdtrace egrep '(LOST:|STOP:|START:|DOWN:|init|load|fail)' nameserver_suschksrv.trc # Example output # 2022-11-03 18:06:21.116728 susChkSrv.init() version 0.7.7, parameter info: action_on_lost=fence stop_timeout=20 kill_signal=9 # 2022-11-03 18:06:27.613588 START: indexserver event looks like graceful tenant start # 2022-11-03 18:07:56.143766 START: indexserver event looks like graceful tenant start (indexserver started)
Vytvoření prostředků clusteru SAP HANA
- [1] Nejprve vytvořte prostředek topologie HANA.
Na jednom z uzlů clusteru Pacemaker spusťte následující příkazy:
sudo crm configure property maintenance-mode=true
# Replace <placeholders> with your instance number and HANA system ID
sudo crm configure primitive rsc_SAPHanaTopology_<HANA SID>_HDB<instance number> ocf:suse:SAPHanaTopology \
operations \$id="rsc_sap2_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10" timeout="600" \
op start interval="0" timeout="600" \
op stop interval="0" timeout="300" \
params SID="<HANA SID>" InstanceNumber="<instance number>"
sudo crm configure clone cln_SAPHanaTopology_<HANA SID>_HDB<instance number> rsc_SAPHanaTopology_<HANA SID>_HDB<instance number> \
meta clone-node-max="1" target-role="Started" interleave="true"
- [1] Dále vytvořte prostředky HANA:
Poznámka:
Tento článek obsahuje odkazy na termíny, které už Microsoft nepoužívá. Když se tyto podmínky odeberou ze softwaru, odebereme je z tohoto článku.
# Replace <placeholders> with your instance number and HANA system ID.
sudo crm configure primitive rsc_SAPHana_<HANA SID>_HDB<instance number> ocf:suse:SAPHana \
operations \$id="rsc_sap_<HANA SID>_HDB<instance number>-operations" \
op start interval="0" timeout="3600" \
op stop interval="0" timeout="3600" \
op promote interval="0" timeout="3600" \
op monitor interval="60" role="Master" timeout="700" \
op monitor interval="61" role="Slave" timeout="700" \
params SID="<HANA SID>" InstanceNumber="<instance number>" PREFER_SITE_TAKEOVER="true" \
DUPLICATE_PRIMARY_TIMEOUT="7200" AUTOMATED_REGISTER="false"
# Run the following command if the cluster nodes are running on SLES 12 SP05.
sudo crm configure ms msl_SAPHana_<HANA SID>_HDB<instance number> rsc_SAPHana_<HANA SID>_HDB<instance number> \
meta notify="true" clone-max="2" clone-node-max="1" \
target-role="Started" interleave="true"
# Run the following command if the cluster nodes are running on SLES 15 SP03 or later.
sudo crm configure clone msl_SAPHana_<HANA SID>_HDB<instance number> rsc_SAPHana_<HANA SID>_HDB<instance number> \
meta notify="true" clone-max="2" clone-node-max="1" \
target-role="Started" interleave="true" promotable="true"
sudo crm resource meta msl_SAPHana_<HANA SID>_HDB<instance number> set priority 100
- [1] Pokračujte s prostředky clusteru pro virtuální IP adresy, výchozí hodnoty a omezení.
# Replace <placeholders> with your instance number, HANA system ID, and the front-end IP address of the Azure load balancer.
sudo crm configure primitive rsc_ip_<HANA SID>_HDB<instance number> ocf:heartbeat:IPaddr2 \
meta target-role="Started" \
operations \$id="rsc_ip_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10s" timeout="20s" \
params ip="<front-end IP address>"
sudo crm configure primitive rsc_nc_<HANA SID>_HDB<instance number> azure-lb port=625<instance number> \
op monitor timeout=20s interval=10 \
meta resource-stickiness=0
sudo crm configure group g_ip_<HANA SID>_HDB<instance number> rsc_ip_<HANA SID>_HDB<instance number> rsc_nc_<HANA SID>_HDB<instance number>
sudo crm configure colocation col_saphana_ip_<HANA SID>_HDB<instance number> 4000: g_ip_<HANA SID>_HDB<instance number>:Started \
msl_SAPHana_<HANA SID>_HDB<instance number>:Master
sudo crm configure order ord_SAPHana_<HANA SID>_HDB<instance number> Optional: cln_SAPHanaTopology_<HANA SID>_HDB<instance number> \
msl_SAPHana_<HANA SID>_HDB<instance number>
# Clean up the HANA resources. The HANA resources might have failed because of a known issue.
sudo crm resource cleanup rsc_SAPHana_<HANA SID>_HDB<instance number>
sudo crm configure property priority-fencing-delay=30
sudo crm configure property maintenance-mode=false
sudo crm configure rsc_defaults resource-stickiness=1000
sudo crm configure rsc_defaults migration-threshold=5000
Důležité
Doporučujeme nastavit, abyste false nastavili AUTOMATED_REGISTER jenom v době, kdy provádíte důkladné testy převzetí služeb při selhání, aby se primární instance, která selhala, automaticky zaregistrovala jako sekundární. Po úspěšném dokončení testů převzetí služeb při selhání se nastaví AUTOMATED_REGISTER na truehodnotu , aby se po převzetí replikace systému automaticky obnovila.
Ujistěte se, že stav clusteru je OK a že se spustily všechny prostředky. Nezáleží na tom, na kterém uzlu jsou prostředky spuštěné.
sudo crm_mon -r
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
Konfigurace replikace systému s podporou aktivní/čtení HANA v clusteru Pacemaker
V SAP HANA 2.0 SPS 01 a novějších verzích umožňuje SAP nastavení s podporou aktivního a čtení pro replikaci systému SAP HANA. V tomto scénáři je možné sekundární systémy replikace systému SAP HANA aktivně používat pro úlohy náročné na čtení.
Pro podporu tohoto nastavení v clusteru se vyžaduje druhá virtuální IP adresa, aby klienti mohli přistupovat k sekundární databázi SAP HANA s podporou čtení. Aby se zajistilo, že sekundární lokalita replikace bude i po převzetí přístupná, musí cluster přesunout virtuální IP adresu kolem sekundárního prostředku SAPHana.
Tato část popisuje další kroky potřebné ke správě replikace systému s podporou aktivní/čtení HANA v clusteru s vysokou dostupností SUSE, který používá druhou virtuální IP adresu.
Než budete pokračovat, ujistěte se, že jste plně nakonfigurovali cluster SUSE s vysokou dostupností, který spravuje databázi SAP HANA, jak je popsáno v předchozích částech.
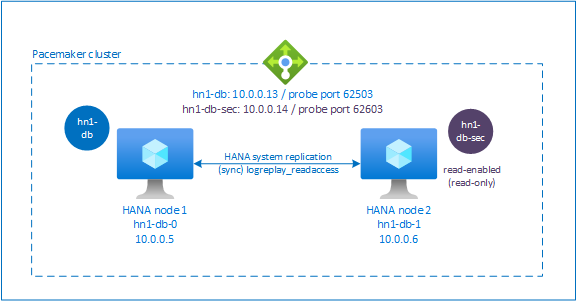
Nastavení nástroje pro vyrovnávání zatížení pro replikaci systému s podporou aktivního nebo čtení
Pokud chcete pokračovat dalšími kroky pro zřízení druhé virtuální IP adresy, ujistěte se, že jste nakonfigurovali Azure Load Balancer, jak je popsáno v tématu Ruční nasazení virtuálních počítačů s Linuxem prostřednictvím webu Azure Portal.
Pro nástroj pro vyrovnávání zatížení úrovně Standard proveďte tyto další kroky na stejném nástroji pro vyrovnávání zatížení, který jste vytvořili dříve.
- Vytvořte druhý front-endový fond IP adres:
- Otevřete nástroj pro vyrovnávání zatížení, vyberte front-endový fond IP adres a vyberte Přidat.
- Zadejte název druhého front-endového fondu IP adres (například hana-secondaryIP).
- Nastavte přiřazení na Static a zadejte IP adresu (například 10.0.0.14).
- Vyberte OK.
- Po vytvoření nového front-endového fondu IP adres si poznamenejte front-endovou IP adresu.
- Vytvoření sondy stavu:
- V nástroji pro vyrovnávání zatížení vyberte sondy stavu a vyberte Přidat.
- Zadejte název nové sondy stavu (například hana-secondaryhp).
- Jako protokol a číslo> instance portu 626<vyberte tcp. Ponechte hodnotu Interval nastavenou na 5 a prahová hodnota není v pořádku nastavená na hodnotu 2.
- Vyberte OK.
- Vytvořte pravidla vyrovnávání zatížení:
- V nástroji pro vyrovnávání zatížení vyberte pravidla vyrovnávání zatížení a vyberte Přidat.
- Zadejte název nového pravidla nástroje pro vyrovnávání zatížení (například hana-secondarylb).
- Vyberte front-endovou IP adresu, back-endový fond a sondu stavu, kterou jste vytvořili dříve (například hana-secondaryIP, hana-backend a hana-secondaryhp).
- Vyberte porty vysoké dostupnosti.
- Zvyšte časový limit nečinnosti na 30 minut.
- Ujistěte se, že povolíte plovoucí IP adresu.
- Vyberte OK.
Nastavení replikace systému s podporou aktivního/čtení HANA
Postup konfigurace systémové replikace HANA je popsaný v tématu Konfigurace systémové replikace SAP HANA 2.0. Pokud nasazujete sekundární scénář s podporou čtení, spusťte při nastavování replikace systému na druhém uzlu následující příkaz jako <adm HANA SID>:
sapcontrol -nr <instance number> -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> --operationMode=logreplay_readaccess
Přidání prostředku sekundární virtuální IP adresy
Druhou virtuální IP adresu a příslušné omezení kolokace můžete nastavit pomocí následujících příkazů:
crm configure property maintenance-mode=true
crm configure primitive rsc_secip_<HANA SID>_HDB<instance number> ocf:heartbeat:IPaddr2 \
meta target-role="Started" \
operations \$id="rsc_secip_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10s" timeout="20s" \
params ip="<secondary IP address>"
crm configure primitive rsc_secnc_<HANA SID>_HDB<instance number> azure-lb port=626<instance number> \
op monitor timeout=20s interval=10 \
meta resource-stickiness=0
crm configure group g_secip_<HANA SID>_HDB<instance number> rsc_secip_<HANA SID>_HDB<instance number> rsc_secnc_<HANA SID>_HDB<instance number>
crm configure colocation col_saphana_secip_<HANA SID>_HDB<instance number> 4000: g_secip_<HANA SID>_HDB<instance number>:Started \
msl_SAPHana_<HANA SID>_HDB<instance number>:Slave
crm configure property maintenance-mode=false
Ujistěte se, že stav clusteru je OK a že se spustily všechny prostředky. Druhá virtuální IP adresa běží v sekundární lokalitě spolu s sekundárním prostředkem SAPHana.
sudo crm_mon -r
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# Resource Group: g_secip_HN1_HDB03:
# rsc_secip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
# rsc_secnc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Další část popisuje typickou sadu testů převzetí služeb při selhání, které se mají provést.
Důležité informace při testování clusteru HANA, který je nakonfigurovaný se sekundárním serverem s povoleným čtením:
Při migraci prostředku clusteru
SAPHana_<HANA SID>_HDB<instance number>dohn1-db-1, druhá virtuální IP adresa se přesune dohn1-db-0. Pokud jste nakonfigurovaliAUTOMATED_REGISTER="false"a replikace systému HANA není zaregistrovaná automaticky, druhá virtuální IP adresa se spustíhn1-db-0, protože server je dostupný a služby clusteru jsou online.Při testování chybového ukončení serveru se na primárním serveru společně s primárními prostředky virtuální IP adresy spustí druhý prostředek virtuální IP adresy (
rsc_secip_<HANA SID>_HDB<instance number>) a prostředekrsc_secnc_<HANA SID>_HDB<instance number>portu nástroje pro vyrovnávání zatížení Azure. Zatímco sekundární server je mimo provoz, aplikace, které jsou připojené k databázi HANA s podporou čtení, se připojují k primární databázi HANA. Toto chování se očekává, protože nechcete, aby aplikace, které jsou připojené k databázi HANA s podporou čtení, byly nepřístupné, když sekundární server není dostupný.Pokud je sekundární server dostupný a služby clusteru jsou online, druhá virtuální IP adresa a prostředky portů se automaticky přesunou na sekundární server, i když replikace systému HANA nemusí být zaregistrovaná jako sekundární. Před spuštěním služeb clusteru na daném serveru se ujistěte, že sekundární databázi HANA zaregistrujete jako povolenou pro čtení. Prostředek clusteru instance HANA můžete nakonfigurovat tak, aby se sekundární registr automaticky zaregistroval nastavením parametru
AUTOMATED_REGISTER="true".Během převzetí služeb při selhání a záložního převzetí služeb při selhání může dojít k přerušení stávajících připojení k aplikacím, které pak pro připojení k databázi HANA používají druhou virtuální IP adresu.
Otestování nastavení clusteru
Tato část popisuje, jak můžete otestovat nastavení. Každý test předpokládá, že jste přihlášení jako kořen a že hlavní server SAP HANA běží na virtuálním hn1-db-0 počítači.
Otestování migrace
Než spustíte test, ujistěte se, že Pacemaker nemá žádnou neúspěšnou akci (spuštění crm_mon -r), že neexistují žádná neočekávaná omezení umístění (například levý přechod testu migrace) a že hana je například ve stavu synchronizace, například spuštěním SAPHanaSR-showAttr.
hn1-db-0:~ # SAPHanaSR-showAttr
Sites srHook
----------------
SITE2 SOK
Global cib-time
--------------------------------
global Mon Aug 13 11:26:04 2018
Hosts clone_state lpa_hn1_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
hn1-db-0 PROMOTED 1534159564 online logreplay nws-hana-vm-1 4:P:master1:master:worker:master 150 SITE1 sync PRIM 2.00.030.00.1522209842 nws-hana-vm-0
hn1-db-1 DEMOTED 30 online logreplay nws-hana-vm-0 4:S:master1:master:worker:master 100 SITE2 sync SOK 2.00.030.00.1522209842 nws-hana-vm-1
Hlavní uzel SAP HANA můžete migrovat spuštěním následujícího příkazu:
crm resource move msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1 force
Cluster by migroval hlavní uzel SAP HANA a skupinu obsahující virtuální IP adresu do hn1-db-1.
Po dokončení migrace bude výstup vypadat jako v tomto příkladu crm_mon -r :
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Stopped: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Failed Actions:
* rsc_SAPHana_HN1_HDB03_start_0 on hn1-db-0 'not running' (7): call=84, status=complete, exitreason='none',
last-rc-change='Mon Aug 13 11:31:37 2018', queued=0ms, exec=2095ms
V AUTOMATED_REGISTER="false"případě, že cluster nerestartoval neúspěšnou databázi HANA nebo ho zaregistroval proti nové primární databázi hn1-db-0. V tomto případě nakonfigurujte instanci HANA jako sekundární spuštěním tohoto příkazu:
su - <hana sid>adm
# Stop the HANA instance, just in case it is running
hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> sapcontrol -nr <instance number> -function StopWait 600 10
hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1>
Migrace vytvoří omezení umístění, která je potřeba odstranit znovu:
# Switch back to root and clean up the failed state
exit
hn1-db-0:~ # crm resource clear msl_SAPHana_<HANA SID>_HDB<instance number>
Musíte také vyčistit stav prostředku sekundárního uzlu:
hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0
Monitorování stavu prostředku HANA pomocí crm_mon -r. Při spuštění hn1-db-0HANA vypadá výstup jako v tomto příkladu:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Blokování síťové komunikace
Stav prostředku před zahájením testu:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Spuštěním pravidla brány firewall zablokujte komunikaci na jednom z uzlů.
# Execute iptable rule on hn1-db-1 (10.0.0.6) to block the incoming and outgoing traffic to hn1-db-0 (10.0.0.5)
iptables -A INPUT -s 10.0.0.5 -j DROP; iptables -A OUTPUT -d 10.0.0.5 -j DROP
Pokud uzly clusteru nemůžou vzájemně komunikovat, hrozí riziko rozděleného mozku. Vtakovýchch uzlech se v takových situacích pokusí o vzájemné ohraničení, což vede k rase plotu.
Při konfiguraci zařízení pro ohraničení se doporučuje nakonfigurovat pcmk_delay_max vlastnost. V případě rozděleného mozku tedy cluster zavádí náhodné zpoždění až do pcmk_delay_max hodnoty, akci šermování na každém uzlu. Uzel s nejkratší prodlevou bude vybrán pro ohraničení.
Kromě toho se doporučuje priority-fencing-delay nastavit vlastnost v konfiguraci clusteru, aby uzel, na kterém běží hlavní server HANA, prioritu a vyhraje závod plotu ve scénáři rozděleného mozku. Když povolíte vlastnost priority-zpoždění, cluster může zavést další zpoždění v akci šermování konkrétně na uzlu hostujícího hlavní prostředek HANA, což umožňuje uzlu vyhrát plotové závody.
Spuštěním následujícího příkazu odstraňte pravidlo brány firewall.
# If the iptables rule set on the server gets reset after a reboot, the rules will be cleared out. In case they have not been reset, please proceed to remove the iptables rule using the following command.
iptables -D INPUT -s 10.0.0.5 -j DROP; iptables -D OUTPUT -d 10.0.0.5 -j DROP
Testování šermování SBD
Nastavení SBD můžete otestovat tak, že proces inquisitoru zabijete:
hn1-db-0:~ # ps aux | grep sbd
root 1912 0.0 0.0 85420 11740 ? SL 12:25 0:00 sbd: inquisitor
root 1929 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014056f268462316e4681b704a9f73 - slot: 0 - uuid: 7b862dba-e7f7-4800-92ed-f76a4e3978c8
root 1930 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014059bc9ea4e4bac4b18808299aaf - slot: 0 - uuid: 5813ee04-b75c-482e-805e-3b1e22ba16cd
root 1931 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-36001405b8dddd44eb3647908def6621c - slot: 0 - uuid: 986ed8f8-947d-4396-8aec-b933b75e904c
root 1932 0.0 0.0 90524 16656 ? SL 12:25 0:00 sbd: watcher: Pacemaker
root 1933 0.0 0.0 102708 28260 ? SL 12:25 0:00 sbd: watcher: Cluster
root 13877 0.0 0.0 9292 1572 pts/0 S+ 12:27 0:00 grep sbd
hn1-db-0:~ # kill -9 1912
Uzel <HANA SID>-db-<database 1> clusteru se restartuje. Služba Pacemaker se nemusí restartovat. Ujistěte se, že ho znovu spustíte.
Testování ručního převzetí služeb při selhání
Ruční převzetí služeb při selhání můžete otestovat zastavením služby Pacemaker na hn1-db-0 uzlu:
service pacemaker stop
Po převzetí služeb při selhání můžete službu spustit znovu. Pokud nastavíte AUTOMATED_REGISTER="false", prostředek SAP HANA na hn1-db-0 uzlu se nespustí jako sekundární.
V tomto případě nakonfigurujte instanci HANA jako sekundární spuštěním tohoto příkazu:
service pacemaker start
su - <hana sid>adm
# Stop the HANA instance, just in case it is running
sapcontrol -nr <instance number> -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1>
# Switch back to root and clean up the failed state
exit
crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0
Testy SUSE
Důležité
Ujistěte se, že vybraný operační systém má certifikaci SAP pro SAP HANA na konkrétních typech virtuálních počítačů, které plánujete použít. V platformách SAP HANA Certified IaaS můžete vyhledat typy virtuálních počítačů certifikovaných pro SAP HANA a jejich vydání operačního systému. Ujistěte se, že se podíváte na podrobnosti o typu virtuálního počítače, který plánujete použít k získání kompletního seznamu verzí operačního systému podporovaného sap HANA pro daný typ virtuálního počítače.
V závislosti na vašem scénáři spusťte všechny testovací případy, které jsou uvedené v průvodci scénářem optimalizovaným pro výkon sap HANA SR nebo v průvodci scénářem optimalizovaným pro službu SAP HANA SR. Příručky uvedené v SLES najdete v osvědčených postupech PRO SAP.
Následující testy představují kopii popisu testu průvodce SUSE Linux Enterprise Serverem SUSE Linux Enterprise Server pro aplikace SAP 12 SP1. Aktuální verzi si můžete přečíst také v samotném průvodci. Před spuštěním testu se vždy ujistěte, že je HANA synchronizovaná, a ujistěte se, že je konfigurace Pacemakeru správná.
V následujícíchpopisch PREFER_SITE_TAKEOVER="true" AUTOMATED_REGISTER="false"
Poznámka:
Následující testy jsou navržené tak, aby se spouštěly v sekvenci. Každý test závisí na stavu ukončení předchozího testu.
Test 1: Zastavte primární databázi na uzlu 1.
Stav prostředku před zahájením testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Na uzlu spusťte následující příkazy jako <adm
hn1-db-0hana sid>:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> HDB stopPacemaker zjistí zastavenou instanci HANA a převezme služby při selhání do druhého uzlu. Po dokončení převzetí služeb při selhání se instance HANA na
hn1-db-0uzlu zastaví, protože Pacemaker neregistruje uzel automaticky jako sekundární HANA.Spuštěním následujících příkazů zaregistrujte
hn1-db-0uzel jako sekundární a vyčistíte prostředek, který selhal:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Stav prostředku po testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Test 2: Zastavte primární databázi na uzlu 2.
Stav prostředku před zahájením testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Na uzlu spusťte následující příkazy jako <adm
hn1-db-1hana sid>:hn1adm@hn1-db-1:/usr/sap/HN1/HDB01> HDB stopPacemaker zjistí zastavenou instanci HANA a převezme služby při selhání do druhého uzlu. Po dokončení převzetí služeb při selhání se instance HANA na
hn1-db-1uzlu zastaví, protože Pacemaker neregistruje uzel automaticky jako sekundární HANA.Spuštěním následujících příkazů zaregistrujte
hn1-db-1uzel jako sekundární a vyčistíte prostředek, který selhal:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Stav prostředku po testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 3: Chyba primární databáze na uzlu 1
Stav prostředku před zahájením testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Na uzlu spusťte následující příkazy jako <adm
hn1-db-0hana sid>:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker zjistí zabitou instanci HANA a převezme služby při selhání na druhý uzel. Po dokončení převzetí služeb při selhání se instance HANA na
hn1-db-0uzlu zastaví, protože Pacemaker neregistruje uzel automaticky jako sekundární HANA.Spuštěním následujících příkazů zaregistrujte
hn1-db-0uzel jako sekundární a vyčistíte prostředek, který selhal:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Stav prostředku po testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Test 4: Chyba primární databáze na uzlu 2
Stav prostředku před zahájením testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Na uzlu spusťte následující příkazy jako <adm
hn1-db-1hana sid>:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker zjistí zabitou instanci HANA a převezme služby při selhání na druhý uzel. Po dokončení převzetí služeb při selhání se instance HANA na
hn1-db-1uzlu zastaví, protože Pacemaker neregistruje uzel automaticky jako sekundární HANA.Spuštěním následujících příkazů zaregistrujte
hn1-db-1uzel jako sekundární a vyčistíte prostředek, který selhal.hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Stav prostředku po testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 5: Chyba uzlu primární lokality (uzel 1).
Stav prostředku před zahájením testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Na uzlu spusťte následující příkazy jako kořen
hn1-db-0:hn1-db-0:~ # echo 'b' > /proc/sysrq-triggerPacemaker zjistí uzel zabitého clusteru a ohradí uzel. Když je uzel ohraničený, Pacemaker aktivuje převzetí instance HANA. Po restartování ohraničeného uzlu se Pacemaker nespustí automaticky.
Spuštěním následujících příkazů spusťte Pacemaker, vyčistíte zprávy SBD pro
hn1-db-0uzel, zaregistrujtehn1-db-0uzel jako sekundární a vyčistíte prostředek, který selhal:# run as root # list the SBD device(s) hn1-db-0:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-0:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-0 clear hn1-db-0:~ # systemctl start pacemaker # run as <hana sid>adm hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Stav prostředku po testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Test 6: Chyba uzlu sekundární lokality (uzel 2).
Stav prostředku před zahájením testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Na uzlu spusťte následující příkazy jako kořen
hn1-db-1:hn1-db-1:~ # echo 'b' > /proc/sysrq-triggerPacemaker zjistí uzel zabitého clusteru a ohradí uzel. Když je uzel ohraničený, Pacemaker aktivuje převzetí instance HANA. Po restartování ohraničeného uzlu se Pacemaker nespustí automaticky.
Spuštěním následujících příkazů spusťte Pacemaker, vyčistíte zprávy SBD pro
hn1-db-1uzel, zaregistrujtehn1-db-1uzel jako sekundární a vyčistíte prostředek, který selhal:# run as root # list the SBD device(s) hn1-db-1:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-1:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-1 clear hn1-db-1:~ # systemctl start pacemaker # run as <hana sid>adm hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Stav prostředku po testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0 </code></pre>Test 7: Zastavte sekundární databázi na uzlu 2.
Stav prostředku před zahájením testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Na uzlu spusťte následující příkazy jako <adm
hn1-db-1hana sid>:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB stopPacemaker zjistí zastavenou instanci HANA a označí prostředek jako neúspěšný na
hn1-db-1uzlu. Pacemaker automaticky restartuje instanci HANA.Spuštěním následujícího příkazu vyčistíte stav selhání:
# run as root hn1-db-1>:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Stav prostředku po testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 8: Selhání sekundární databáze na uzlu 2
Stav prostředku před zahájením testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Na uzlu spusťte následující příkazy jako <adm
hn1-db-1hana sid>:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker zjistí zabitou instanci HANA a označí prostředek jako neúspěšný na
hn1-db-1uzlu. Spuštěním následujícího příkazu vyčistíte stav selhání. Pacemaker pak automaticky restartuje instanci HANA.# run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> HN1-db-1Stav prostředku po testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 9: Chyba uzlu sekundární lokality (uzel 2), na kterém běží sekundární databáze HANA.
Stav prostředku před zahájením testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Na uzlu spusťte následující příkazy jako kořen
hn1-db-1:hn1-db-1:~ # echo b > /proc/sysrq-triggerPacemaker zjistí uzel clusteru, který zabil, a ohradil uzel. Po restartování ohraničeného uzlu se Pacemaker nespustí automaticky.
Spuštěním následujících příkazů spusťte Pacemaker, vyčistíte zprávy SBD pro
hn1-db-1uzel a vyčistíte prostředek, který selhal:# run as root # list the SBD device(s) hn1-db-1:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-1:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-1 clear hn1-db-1:~ # systemctl start pacemaker hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Stav prostředku po testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 10: Selhání primárního indexovacího serveru databáze
Tento test je relevantní pouze v případě, že jste nastavili hook susChkSrv, jak je uvedeno v implementaci agentů prostředků HANA.
Stav prostředku před zahájením testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Na uzlu spusťte následující příkazy jako kořen
hn1-db-0:hn1-db-0:~ # killall -9 hdbindexserverKdyž se indexserver ukončí, háček susChkSrv zjistí událost a aktivuje akci, která ohradí uzel hn1-db-0 a zahájí proces převzetí.
Spuštěním následujících příkazů zaregistrujte
hn1-db-0uzel jako sekundární a vyčistíte prostředek, který selhal:# run as <hana sid>adm hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Stav prostředku po testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Můžete spustit srovnatelný testovací případ tím, že způsobí chybové ukončení indexovacího serveru na sekundárním uzlu. V případě chybového ukončení indexserveru rozpozná háček susChkSrv výskyt a zahájí akci pro ohraničení sekundárního uzlu.