Odeslání dávkového spuštění pro vyhodnocení toku
Dávkové spuštění spustí tok výzvy s velkou datovou sadou a vygeneruje výstupy pro každý řádek dat. Pokud chcete vyhodnotit, jak dobře tok výzvy funguje s velkou datovou sadou, můžete odeslat dávkové spuštění a použít metody vyhodnocení ke generování výkonnostních skóre a metrik.
Po dokončení dávkového toku se metody vyhodnocení automaticky spustí, aby vypočítaly skóre a metriky. Metriky vyhodnocení můžete použít k vyhodnocení výstupu toku podle vašich kritérií výkonu a cílů.
Tento článek popisuje, jak odeslat dávkové spuštění a použít metodu vyhodnocení k měření kvality výstupu toku. Dozvíte se, jak zobrazit výsledek vyhodnocení a metriky a jak zahájit nové kolo vyhodnocení s jinou metodou nebo podmnožinou variant.
Požadavky
Ke spuštění dávkového toku s metodou vyhodnocení potřebujete následující komponenty:
Funkční tok výzvy služby Azure Machine Learning, pro který chcete otestovat výkon.
Testovací datová sada, která se má použít pro dávkové spuštění.
Testovací datová sada musí být ve formátu CSV, TSV nebo JSONL a měla by obsahovat hlavičky, které odpovídají vstupním názvům vašeho toku. Během procesu nastavení zkušebního spuštění ale můžete namapovat různé sloupce datové sady na vstupní sloupce.
Vytvoření a odeslání zkušebního dávkového spuštění
Pokud chcete odeslat dávkové spuštění, vyberte datovou sadu, pomocí které chcete tok otestovat. Můžete také vybrat metodu vyhodnocení pro výpočet metrik pro výstup toku. Pokud nechcete použít metodu vyhodnocení, můžete přeskočit kroky vyhodnocení a spustit dávkové spuštění bez výpočtu metrik. Zkušební kolo můžete spustit i později.
Pokud chcete spustit dávkové spuštění s vyhodnocením nebo bez vyhodnocení, vyberte Vyhodnotit v horní části stránky toku výzvy.
Na stránce Základní nastavení průvodce spuštěním a vyhodnocením služby Batch upravte zobrazovaný název spuštění, pokud je to žádoucí, a volitelně zadejte popis spuštění a značky. Vyberte Další.
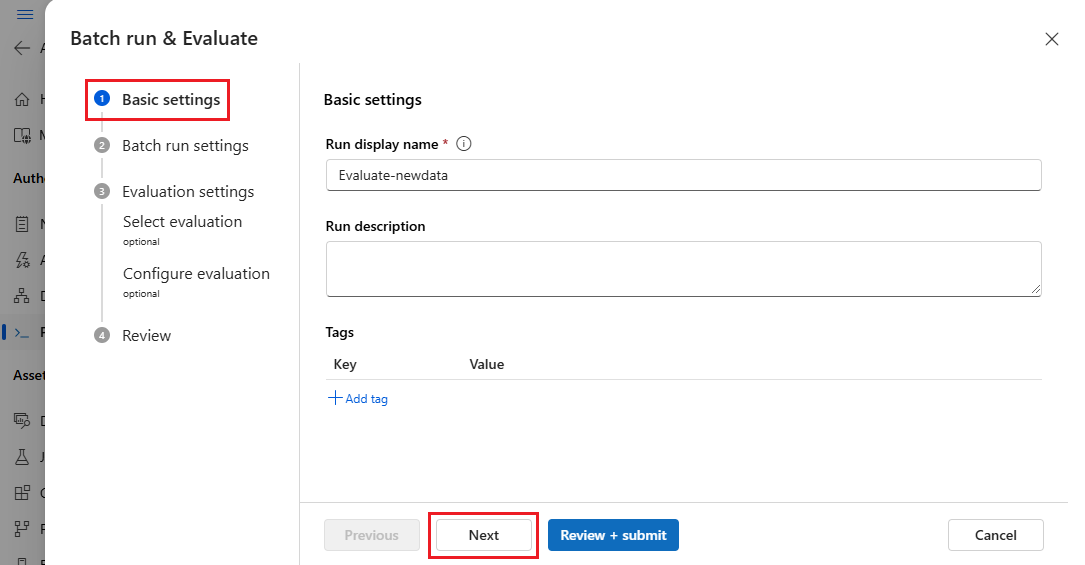
Na stránce nastavení spuštění služby Batch vyberte datovou sadu, která se má použít, a nakonfigurujte mapování vstupu.
Tok výzvy podporuje mapování vstupu toku na konkrétní datový sloupec v datové sadě. Sloupec datové sady můžete přiřadit určitému vstupu pomocí .
${data.<column>}Pokud chcete ke vstupu přiřadit konstantní hodnotu, můžete tuto hodnotu zadat přímo.
V tomto okamžiku můžete vybrat Zkontrolovat a odeslat , abyste přeskočí kroky vyhodnocení a spustili dávkové spuštění bez použití žádné metody vyhodnocení. Dávkové spuštění pak vygeneruje jednotlivé výstupy pro každou položku v datové sadě. Výstupy můžete zkontrolovat ručně nebo je exportovat pro další analýzu.
Pokud chcete k ověření výkonu tohoto spuštění použít metodu vyhodnocení, vyberte Další. Do dokončeného dávkového spuštění můžete také přidat nové kolo vyhodnocení.
Na stránce Vybrat vyhodnocení vyberte jednu nebo více přizpůsobených nebo předdefinovaných vyhodnocení, která se mají spustit. Pokud chcete zobrazit další informace o metodě vyhodnocení, například metriky, které generuje, a připojení a vstupy, které vyžaduje, můžete vybrat tlačítko Zobrazit podrobnosti .
Dále na obrazovce Konfigurovat vyhodnocení zadejte zdroje požadovaných vstupů pro vyhodnocení. Například sloupec základní pravdy může pocházet z datové sady. Ve výchozím nastavení používá vyhodnocení stejnou datovou sadu jako celkové dávkové spuštění. Pokud jsou ale odpovídající popisky nebo cílové hodnoty pravdivých informací v jiné datové sadě, můžete ho použít.
Poznámka:
Pokud vaše metoda vyhodnocení nevyžaduje data z datové sady, je výběr datové sady volitelnou konfigurací, která nemá vliv na výsledky vyhodnocení. Nemusíte vybírat datovou sadu ani odkazovat na žádné sloupce datové sady v části mapování vstupu.
V části Mapování vstupu vyhodnocení uveďte zdroje požadovaných vstupů pro vyhodnocení.
- Pokud jsou data z testovací datové sady, nastavte zdroj jako
${data.[ColumnName]}. - Pokud jsou data z výstupu spuštění, nastavte zdroj jako
${run.outputs.[OutputName]}.
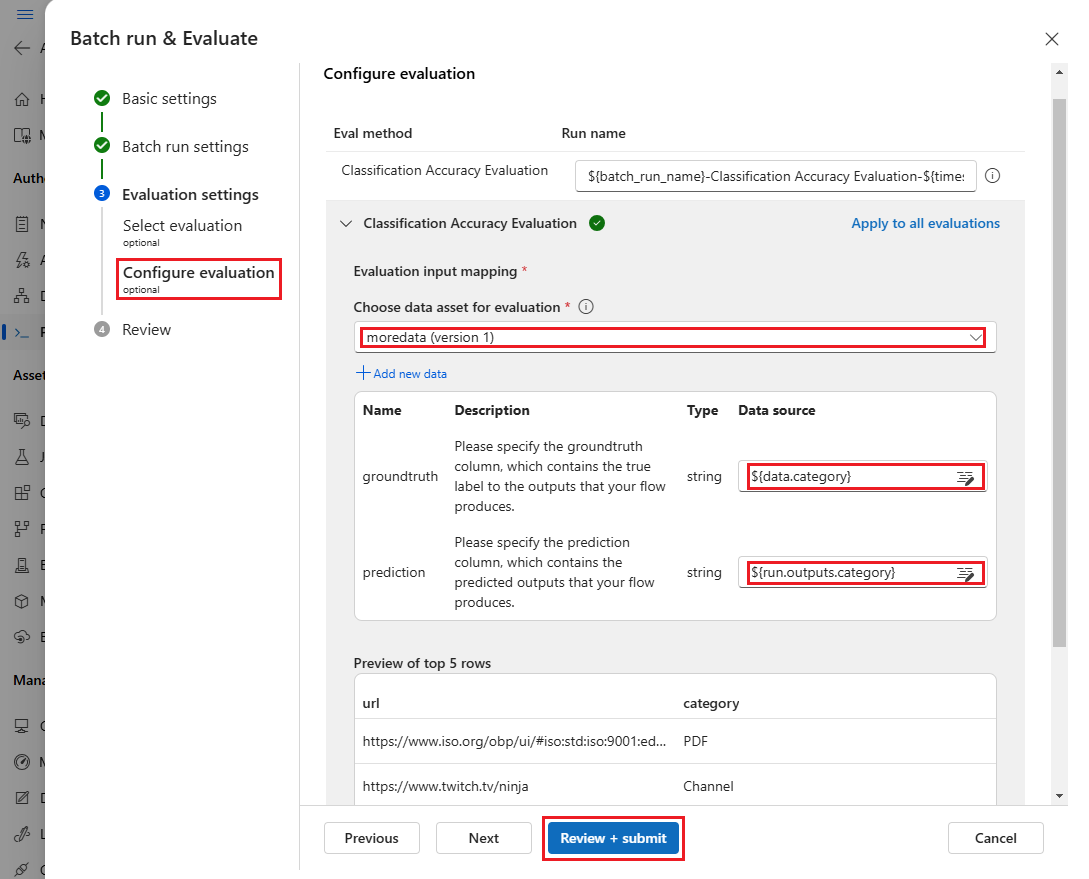
- Pokud jsou data z testovací datové sady, nastavte zdroj jako
Některé metody vyhodnocení vyžadují velké jazykové modely (LLM), jako je GPT-4 nebo GPT-3, nebo potřebují jiná připojení k využívání přihlašovacích údajů nebo klíčů. U těchto metod je nutné zadat data připojení do části Připojení v dolní části této obrazovky, aby bylo možné použít tok vyhodnocení. Další informace najdete v tématu Nastavení připojení.
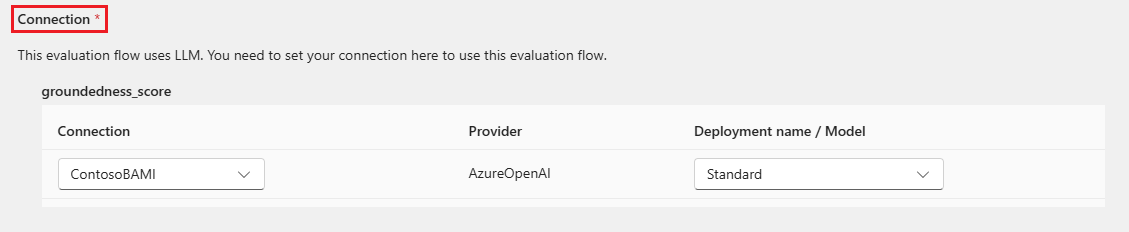
Výběrem možnosti Zkontrolovat a odeslat zkontrolujte nastavení a pak výběrem možnosti Odeslat spusťte dávkové spuštění s vyhodnocením.






Poznámka:
- Některé procesy vyhodnocení používají mnoho tokenů, proto doporučujeme použít model, který může podporovat >=16 tisíc tokenů.
- Spuštění služby Batch mají maximální dobu trvání 10 hodin. Pokud dávkové spuštění překročí tento limit, ukončí se a zobrazí se jako neúspěšné. Monitorujte kapacitu LLM, abyste se vyhnuli omezování. V případě potřeby zvažte zmenšení velikosti dat. Pokud problémy přetrvávají, vytvořte formulář pro zpětnou vazbu nebo žádost o podporu.
Zobrazení výsledků vyhodnocení a metrik
Seznam odeslaných dávkových spuštění najdete na kartě Spuštění na stránce toku studio Azure Machine Learning výzvy.
Pokud chcete zkontrolovat výsledky dávkového spuštění, vyberte spuštění a pak vyberte Vizualizovat výstupy.
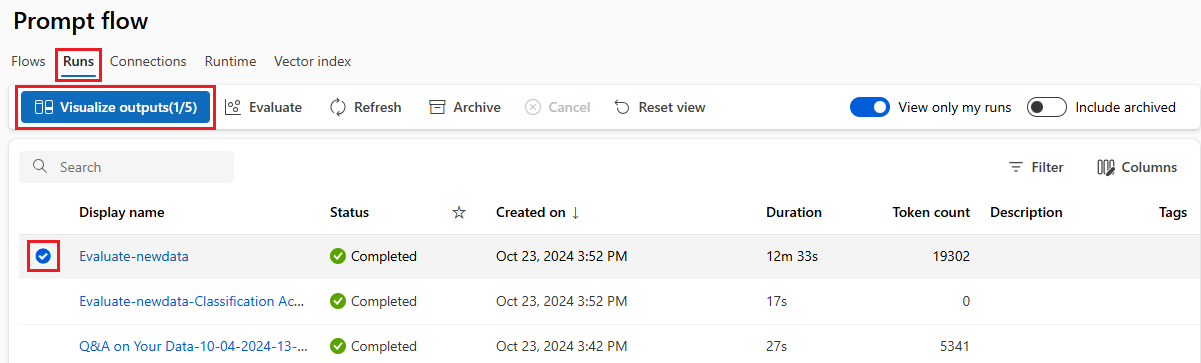
Na obrazovce Vizualizujte výstupy, v části Spuštění a metriky se zobrazují celkové výsledky dávkového spuštění a spuštění vyhodnocení. Oddíl Výstupy zobrazuje vstupy spuštění řádek po řádku v tabulce výsledků, která obsahuje také ID řádku, spuštění, stav a systémové metriky.
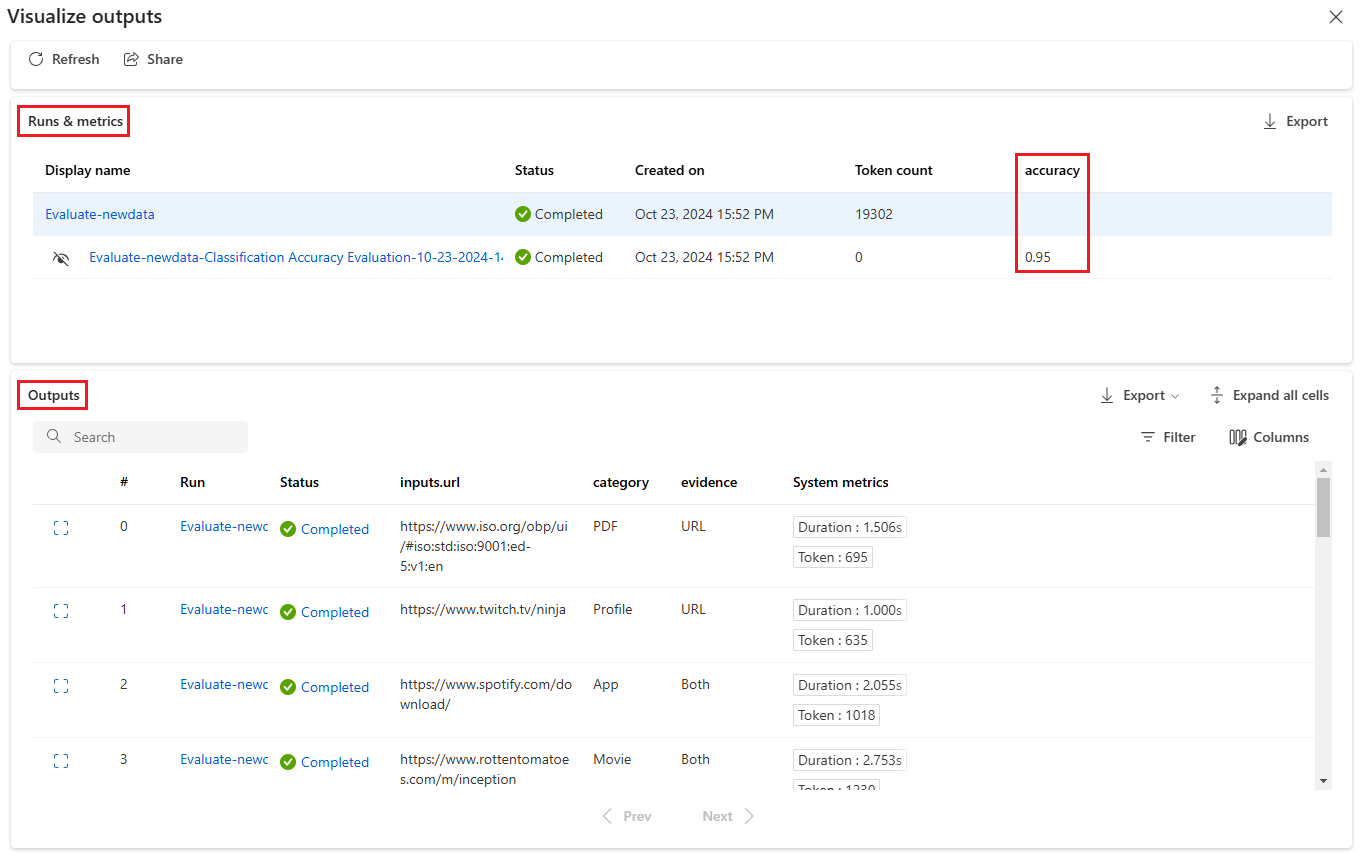
Pokud povolíte ikonu Zobrazení vedle spuštění vyhodnocení v části Spuštění a metriky, zobrazí se v tabulce Výstupy také hodnocení nebo hodnocení pro každý řádek.
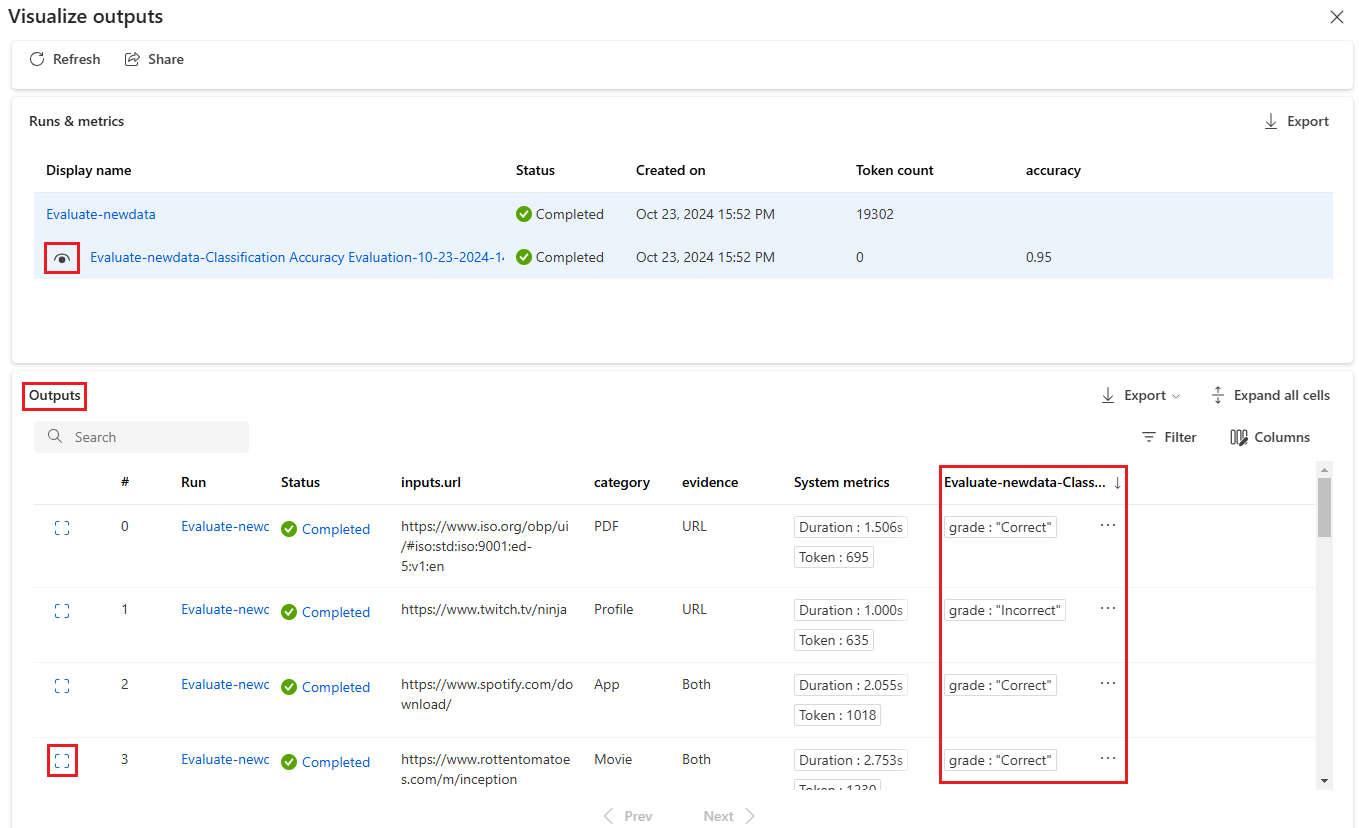
Výběrem ikony Zobrazit podrobnosti vedle každého řádku v tabulce Výstupy můžete sledovat a ladit zobrazení trasování a podrobnosti pro daný testovací případ. Zobrazení Trasování zobrazuje informace, jako je počet tokenů a doba trvání pro tento případ. Rozbalením a výběrem libovolného kroku zobrazíte přehled a vstupy pro tento krok.
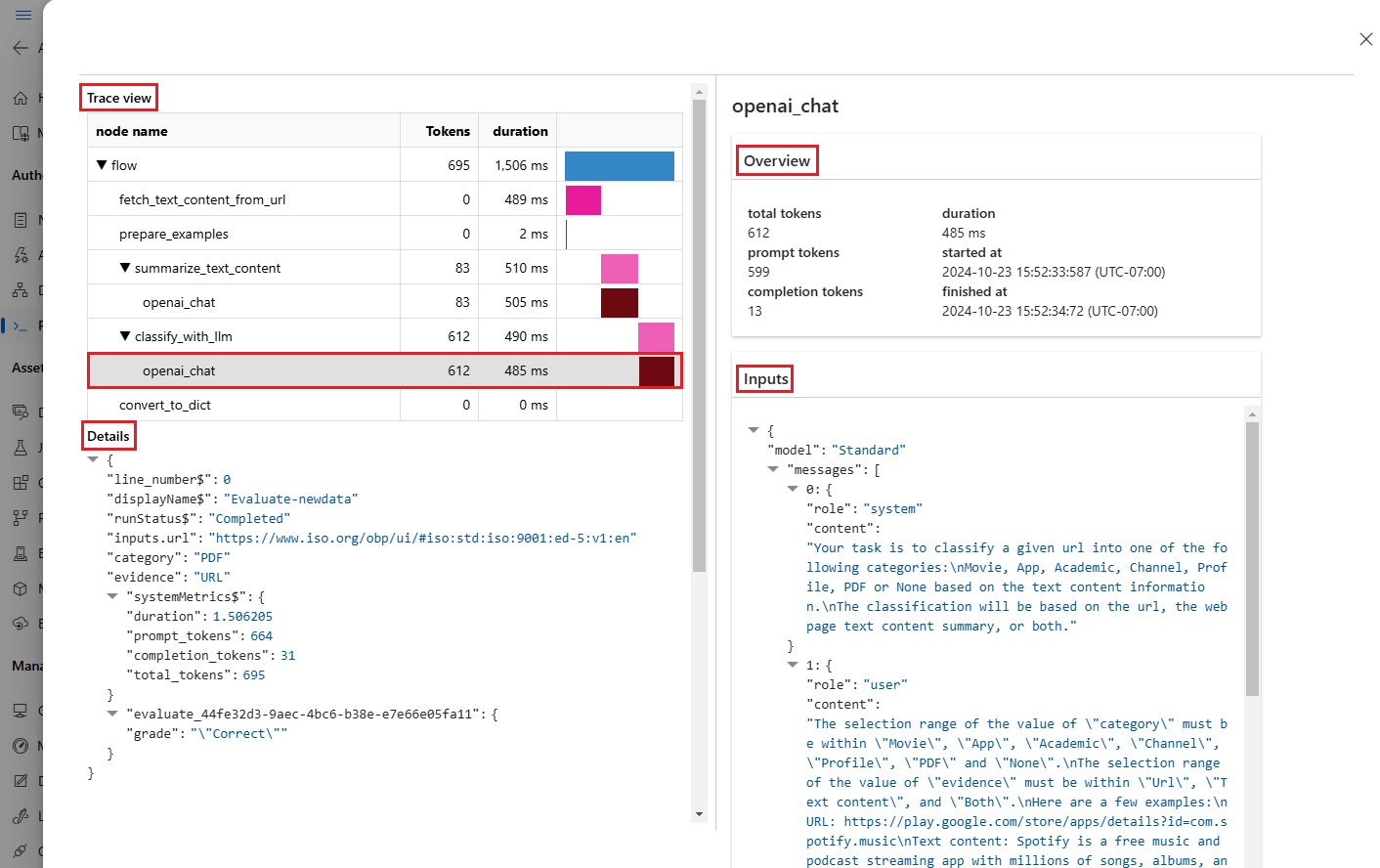




Výsledky spuštění vyhodnocení můžete zobrazit také z toku výzvy, který jste otestovali. V části Zobrazení dávkových spuštění vyberte Zobrazit dávkové spuštění , abyste zobrazili seznam dávkových spuštění toku, nebo vyberte Zobrazit nejnovější výstupy dávkového spuštění, abyste viděli výstupy pro nejnovější spuštění.

V seznamu dávkových spuštění vyberte název dávkového spuštění, aby se otevřela stránka toku pro dané spuštění.
Na stránce toku pro spuštění vyhodnocení vyberte Zobrazit výstupy nebo Podrobnosti a zobrazte podrobnosti o toku. Můžete ho také naklonovat a vytvořit nový tok nebo ho nasadit jako online koncový bod.

Na obrazovce Podrobnosti:
Karta Přehled zobrazuje komplexní informace o spuštění, včetně vlastností spuštění, vstupní datové sady, výstupní datové sady, značek a popisu.
Karta Výstupy zobrazuje souhrn výsledků v horní části stránky a tabulku výsledků dávkového spuštění. Pokud vyberete spuštění vyhodnocení vedle možnosti Připojit související výsledky, zobrazí se v tabulce také výsledky spuštění vyhodnocení.
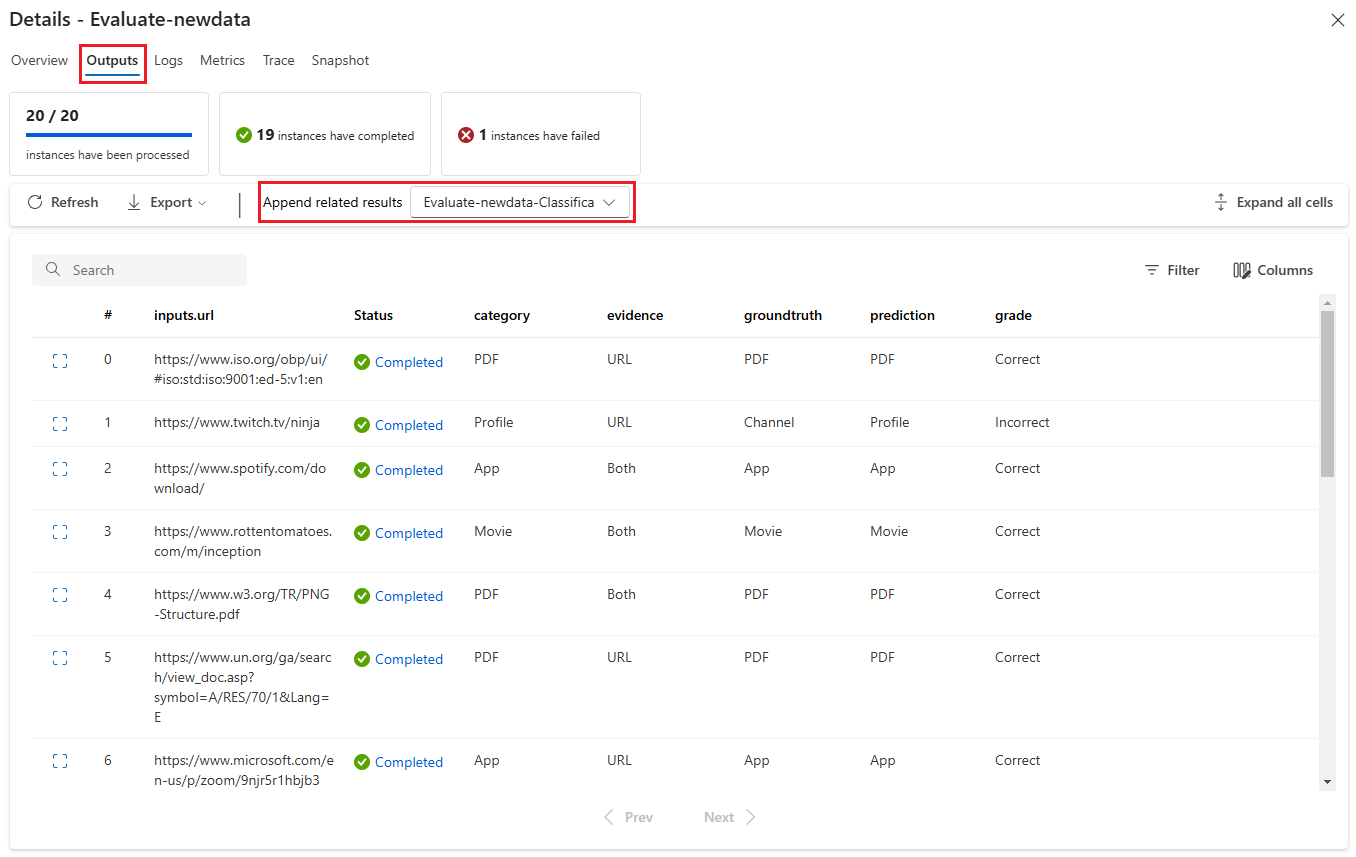
Na kartě Protokoly se zobrazují protokoly spuštění, které můžou být užitečné pro podrobné ladění chyb spuštění. Soubory protokolu si můžete stáhnout.
Na kartě Metriky najdete odkaz na metriky spuštění.
Karta Trasování zobrazuje podrobné informace, jako je počet tokenů a doba trvání každého testovacího případu. Rozbalením a výběrem libovolného kroku zobrazíte přehled a vstupy pro tento krok.
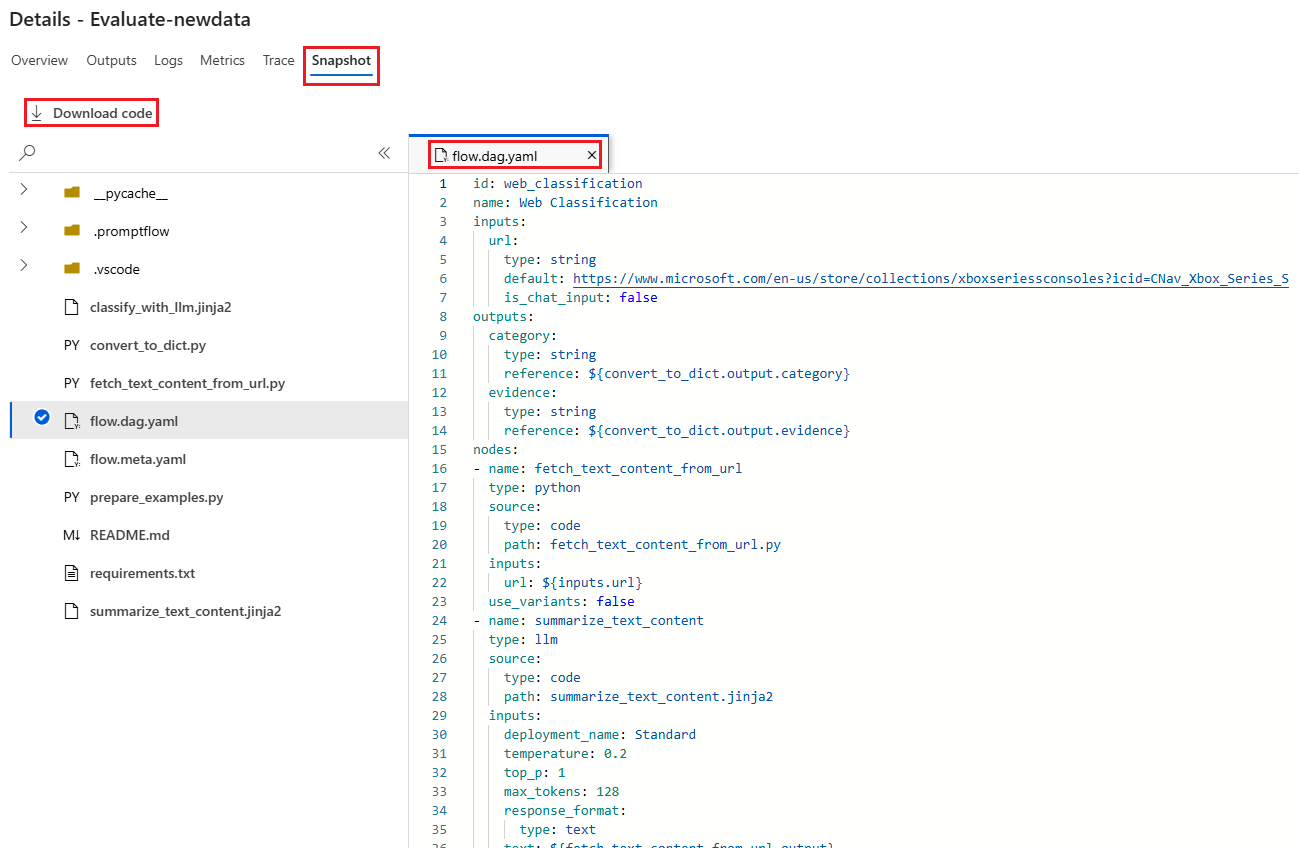
Na kartě Snímek se zobrazí soubory a kód ze spuštění. Zobrazí se definice toku flow.dag.yaml a stáhnete všechny soubory.


Zahájení nového zkušebního kola pro stejné spuštění
Můžete spustit nové zkušební kolo pro výpočet metrik pro dokončené dávkové spuštění bez opětovného spuštění toku. Tento proces šetří náklady na opětovné spouštění toku a je užitečný v následujících scénářích:
- Při odeslání dávkového spuštění jste nevybrali metodu vyhodnocení a teď chcete vyhodnotit výkon spuštění.
- Použili jste metodu vyhodnocení k výpočtu určité metriky a teď chcete vypočítat jinou metriku.
- Předchozí spuštění vyhodnocení se nezdařilo, ale dávkové spuštění úspěšně vygenerovalo výstupy a chcete vyhodnocení zkusit znovu.
Pokud chcete zahájit další kolo vyhodnocení, vyberte Možnost Vyhodnotit v horní části stránky toku dávkového spuštění. Průvodce novým vyhodnocením se otevře na obrazovce Vybrat vyhodnocení . Dokončete nastavení a odešlete nové zkušební spuštění.
Nové spuštění se zobrazí v seznamu spuštění toku výzvy a v seznamu můžete vybrat více než jeden řádek a pak vybrat Vizualizovat výstupy a porovnat výstupy a metriky.
Porovnání historie spuštění vyhodnocení a metrik
Pokud upravíte tok tak, aby se zlepšil jeho výkon, můžete odeslat několik dávkových spuštění a porovnat výkon různých verzí toku. Můžete také porovnat metriky počítané různými metodami vyhodnocení a zjistit, která metoda je pro váš tok vhodnější.
Pokud chcete zkontrolovat historii dávkového spuštění toku, vyberte Zobrazit dávkové spuštění v horní části stránky toku. Můžete vybrat každé spuštění a zkontrolovat podrobnosti. Můžete také vybrat více spuštění a vybrat Vizualizovat výstupy a porovnat metriky a výstupy těchto spuštění.

Vysvětlení předdefinovaných metrik vyhodnocení
Tok výzvy azure Machine Learning nabízí několik předdefinovaných metod vyhodnocení, které vám pomůžou měřit výkon výstupu toku. Každá metoda vyhodnocení vypočítá různé metriky. Následující tabulka popisuje dostupné předdefinované metody vyhodnocení.
| Metoda vyhodnocení | Metrický | Popis | Vyžaduje se připojení? | Požadovaný vstup | Hodnoty skóre |
|---|---|---|---|---|---|
| Vyhodnocení přesnosti klasifikace | Přesnost | Měří výkon klasifikačního systému porovnáním výstupů se základní pravdou. | No | predikce, základní pravda | V rozsahu [0, 1] |
| Vyhodnocení základnosti QnA | Uzemnění | Měří způsob, jakým jsou předpokládané odpovědi modelu ve vstupním zdroji. I když jsou odpovědi LLM přesné, jsou neuzemněné, pokud nejsou ověřitelné vůči zdroji. | Ano | otázka, odpověď, kontext (bez základní pravdy) | 1 až 5, s 1 = nejhorší a 5 = nejlepší |
| Vyhodnocení podobnosti gpt QnA | Podobnost GPT | Měří podobnost mezi odpověďmi základní pravdy poskytovanou uživatelem a modelem předpovězenou odpovědí pomocí modelu GPT. | Ano | otázka, odpověď, základní pravda (kontext není potřeba) | 1 až 5, s 1 = nejhorší a 5 = nejlepší |
| Vyhodnocení relevance QnA | Relevance | Měří, jak relevantní jsou predikované odpovědi modelu na otázky. | Ano | otázka, odpověď, kontext (bez základní pravdy) | 1 až 5, s 1 = nejhorší a 5 = nejlepší |
| Hodnocení soudržnosti QnA | Koherence | Měří kvalitu všech vět v předpovězené odpovědi modelu a způsob, jakým se přirozeně vejdou dohromady. | Ano | otázka, odpověď (bez základní pravdy nebo kontextu) | 1 až 5, s 1 = nejhorší a 5 = nejlepší |
| Vyhodnocení fluency QnA | Plynulost | Měří gramatickou a jazykovou správnost předpovězené odpovědi modelu. | Ano | otázka, odpověď (bez základní pravdy nebo kontextu) | 1 až 5, s 1 = nejhorší a 5 = nejlepší |
| Vyhodnocení skóre QnA F1 | F1 – skóre | Měří poměr počtu sdílených slov mezi predikcí modelu a základní pravdou. | No | otázka, odpověď, základní pravda (kontext není potřeba) | V rozsahu [0, 1] |
| Vyhodnocení podobnosti QnA Ada | Podobnost Ada | Vypočítá vkládání na úrovni věty (dokumentu) pomocí rozhraní API pro vkládání Ada pro základní pravdu i predikci a pak vypočítá kosinusovou podobnost mezi nimi (jedno číslo s plovoucí desetinou čárkou). | Ano | otázka, odpověď, základní pravda (kontext není potřeba) | V rozsahu [0, 1] |
Zlepšení výkonu toku
Pokud vaše spuštění selže, zkontrolujte výstup a data protokolu a vylaďte případné selhání toku. Pokud chcete tok opravit nebo zvýšit výkon, zkuste upravit výzvu toku, systémovou zprávu, parametry toku nebo logiku toku.
Vytváření efektivních dotazů
Konstrukce výzvy může být obtížná. Další informace o konceptech vytváření výzev najdete v tématu Přehled výzev. Informace o vytvoření výzvy, která vám pomůže dosáhnout vašich cílů, najdete v tématu Techniky přípravy výzvy.
Systémová zpráva
Systémovou zprávu, která se někdy označuje jako metaprompt nebo výzva systému, můžete použít k vedení chování systému AI a ke zlepšení výkonu systému. Další informace o tom, jak zlepšit výkon toku pomocí systémových zpráv, najdete v tématu Podrobné vytváření systémových zpráv.
Zlaté datové sady
Vytvoření kopírovacího objektu, který používá LLM, obvykle zahrnuje vytvoření modelu ve skutečnosti pomocí zdrojových datových sad. Zlatá datová sada pomáhá zajistit, aby LLM poskytovaly nejpřesnější a nejužitečnější odpovědi na dotazy zákazníků.
Zlatá datová sada je kolekce realistických zákaznických otázek a expertně vytvořených odpovědí, které slouží jako nástroj pro kontrolu kvality pro LLMs, které používá váš copilot. Zlaté datové sady se nepoužívají k trénování LLM ani vkládání kontextu do výzvy LLM, ale k vyhodnocení kvality odpovědí, které LLM vygeneruje.
Pokud váš scénář zahrnuje copilot nebo vytváříte vlastní kopírovací objekt, přečtěte si téma Vytváření zlatých datových sad s podrobnými pokyny a osvědčenými postupy.