Spouštění dávkových koncových bodů ze služby Azure Data Factory
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Velké objemy dat vyžadují službu, která dokáže orchestrovat a zprovoznit procesy pro upřesnění těchto obrovských úložišť nezpracovaných dat do použitelných obchodních přehledů. Spravovaná cloudová služba Azure Data Factory zpracovává tyto komplexní hybridní úlohy extrakce a transformace (ETL), extrakce a transformace načítání (ELT) a projekty integrace dat.
Azure Data Factory umožňuje vytvářet kanály, které můžou orchestrovat více transformací dat a spravovat je jako jednu jednotku. Dávkové koncové body jsou skvělým kandidátem na to, aby se stal krokem v tomto pracovním postupu zpracování.
V tomto článku se dozvíte, jak používat dávkové koncové body v aktivitách služby Azure Data Factory tím, že se spoléháte na aktivitu vyvolání webu a rozhraní REST API.
Tip
Při použití datových kanálů v prostředcích infrastruktury můžete vyvolat dávkové koncové body přímo pomocí aktivity Azure Machine Learning. K orchestraci dat doporučujeme používat prostředky infrastruktury, kdykoli je to možné, abyste využili nejnovějších funkcí. Aktivita Azure Machine Learning ve službě Azure Data Factory může pracovat pouze s prostředky z Azure Machine Learning verze 1. Další informace najdete v tématu Spouštění modelů Azure Machine Learning z Prostředků infrastruktury pomocí dávkových koncových bodů (Preview).
Požadavky
Model nasazený jako dávkový koncový bod Použijte klasifikátor srdečního stavu vytvořený v modelech MLflow v dávkových nasazeních.
Prostředek služby Azure Data Factory. Pokud chcete vytvořit datovou továrnu, postupujte podle kroků v rychlém startu: Vytvoření datové továrny pomocí webu Azure Portal.
Po vytvoření datové továrny přejděte na web Azure Portal a vyberte Spustit studio:


Ověřování pomocí dávkových koncových bodů
Azure Data Factory může vyvolat rozhraní REST API dávkových koncových bodů pomocí aktivity Vyvolání webu. Koncové body služby Batch podporují ID Microsoft Entra pro autorizaci a požadavek na rozhraní API vyžaduje správné zpracování ověřování. Další informace najdete v tématu Webová aktivita ve službě Azure Data Factory a Azure Synapse Analytics.
Instanční objekt nebo spravovanou identitu můžete použít k ověření na dávkových koncových bodech. Doporučujeme používat spravovanou identitu, protože zjednodušuje používání tajných kódů.
Spravovanou identitu služby Azure Data Factory můžete použít ke komunikaci s dávkovými koncovými body. V takovém případě se musíte ujistit, že se váš prostředek služby Azure Data Factory nasadil se spravovanou identitou.
Pokud nemáte prostředek Služby Azure Data Factory nebo už byl nasazen bez spravované identity, vytvořte ho pomocí tohoto postupu: Spravovaná identita přiřazená systémem.
Upozornění
Po nasazení není možné změnit identitu prostředku ve službě Azure Data Factory. Pokud potřebujete po jeho vytvoření změnit identitu prostředku, musíte prostředek vytvořit znovu.
Po nasazení udělte přístup ke spravované identitě prostředku, který jste vytvořili v pracovním prostoru Azure Machine Learning. Viz Udělení přístupu. V tomto příkladu instanční objekt vyžaduje:
- Oprávnění v pracovním prostoru ke čtení dávkových nasazení a provádění akcí nad nimi
- Oprávnění ke čtení a zápisu v úložištích dat
- Oprávnění ke čtení v libovolném cloudovém umístění (účtu úložiště) označená jako vstup dat
Informace o kanálu
V tomto příkladu vytvoříte kanál ve službě Azure Data Factory, který může vyvolat daný dávkový koncový bod přes určitá data. Kanál komunikuje s koncovými body batch služby Azure Machine Learning pomocí REST. Další informace o tom, jak používat rozhraní REST API dávkových koncových bodů, najdete v tématu Vytváření úloh a vstupních dat pro dávkové koncové body.
Kanál vypadá takto:

Kanál obsahuje následující aktivity:
Spuštění dávkového koncového bodu: Webová aktivita, která k vyvolání používá identifikátor URI dávkového koncového bodu. Předá identifikátor URI vstupních dat, kde se data nacházejí, a očekávaný výstupní soubor.
Čekání na úlohu: Jedná se o aktivitu smyčky, která kontroluje stav vytvořené úlohy a čeká na dokončení, a to buď jako Dokončeno , nebo Neúspěšné. Tato aktivita pak používá následující aktivity:
- Stav kontroly: Webová aktivita, která se dotazuje na stav prostředku úlohy, který se vrátil jako odpověď aktivity spuštění dávkového koncového bodu .
- Čekání: Aktivita čekání, která řídí frekvenci dotazování stavu úlohy. Nastavíme výchozí hodnotu 120 (2 minuty).
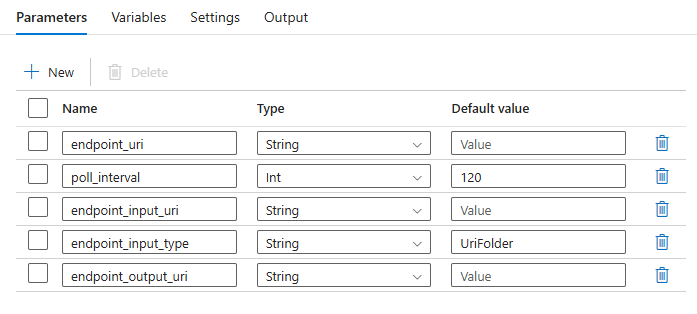
Kanál vyžaduje, abyste nakonfigurovali následující parametry:
| Parametr | Popis | Ukázková hodnota |
|---|---|---|
endpoint_uri |
Identifikátor URI bodování koncového bodu | https://<endpoint_name>.<region>.inference.ml.azure.com/jobs |
poll_interval |
Počet sekund, které se mají počkat, než zkontrolujete stav úlohy dokončení. Výchozí hodnota 120je . |
120 |
endpoint_input_uri |
Vstupní data koncového bodu. Podporuje se více typů zadávání dat. Ujistěte se, že spravovaná identita, kterou používáte ke spuštění úlohy, má přístup k podkladovému umístění. Případně pokud používáte úložiště dat, ujistěte se, že jsou tam uvedené přihlašovací údaje. | azureml://datastores/.../paths/.../data/ |
endpoint_input_type |
Typ vstupních dat, která poskytujete. Aktuálně dávkové koncové body podporují složky (UriFolder) a File (UriFile). Výchozí hodnota UriFolderje . |
UriFolder |
endpoint_output_uri |
Výstupní datový soubor koncového bodu. Musí to být cesta k výstupnímu souboru v úložišti dat připojeném k pracovnímu prostoru Machine Learning. Nepodporuje se žádný jiný typ identifikátorů URI. Můžete použít výchozí úložiště dat služby Azure Machine Learning s názvem workspaceblobstore. |
azureml://datastores/workspaceblobstore/paths/batch/predictions.csv |

Upozorňující
Mějte na paměti, že endpoint_output_uri by měla být cesta k souboru, který ještě neexistuje. V opačném případě úloha selže s chybou , ke které cesta již existuje.
Vytvoření kanálu
Pokud chcete vytvořit tento kanál ve stávající službě Azure Data Factory a vyvolat dávkové koncové body, postupujte takto:
Ujistěte se, že výpočetní prostředí, ve kterém je spuštěný dávkový koncový bod, má oprávnění k připojení dat, která služba Azure Data Factory poskytuje jako vstup. Entita, která vyvolá koncový bod, stále uděluje přístup.
V tomto případě je to Azure Data Factory. Výpočetní prostředky, ve kterých se spouští koncový bod batch, ale musí mít oprávnění k připojení účtu úložiště, který poskytuje vaše služba Azure Data Factory. Podrobnosti najdete v tématu Přístup ke službám úložiště.
Otevřete Azure Data Factory Studio. Výběrem ikony tužky otevřete podokno Autor a v části Prostředky továrny vyberte znaménko plus.
Vyberte Import kanálu>ze šablony kanálu.
Vyberte soubor .zip.
- Pokud chcete použít spravované identity, vyberte tento soubor.
- Pokud chcete použít instanci, vyberte tento soubor.
Na portálu se zobrazí náhled kanálu. Vyberte Použít tuto šablonu.
Kanál se vytvoří za vás s názvem Run-BatchEndpoint.
Nakonfigurujte parametry dávkového nasazení:
Upozorňující
Před odesláním úlohy se ujistěte, že váš koncový bod batch má nakonfigurované výchozí nasazení. Vytvořený kanál vyvolá koncový bod. Je potřeba vytvořit a nakonfigurovat výchozí nasazení.
Tip
Pokud chcete co nejlépe opakovaně používat, použijte vytvořený kanál jako šablonu a volejte ho z jiných kanálů Azure Data Factory pomocí aktivity Spustit kanál. V takovém případě nekonfigurujte parametry ve vnitřním kanálu, ale předejte je jako parametry z vnějšího kanálu, jak je znázorněno na následujícím obrázku:
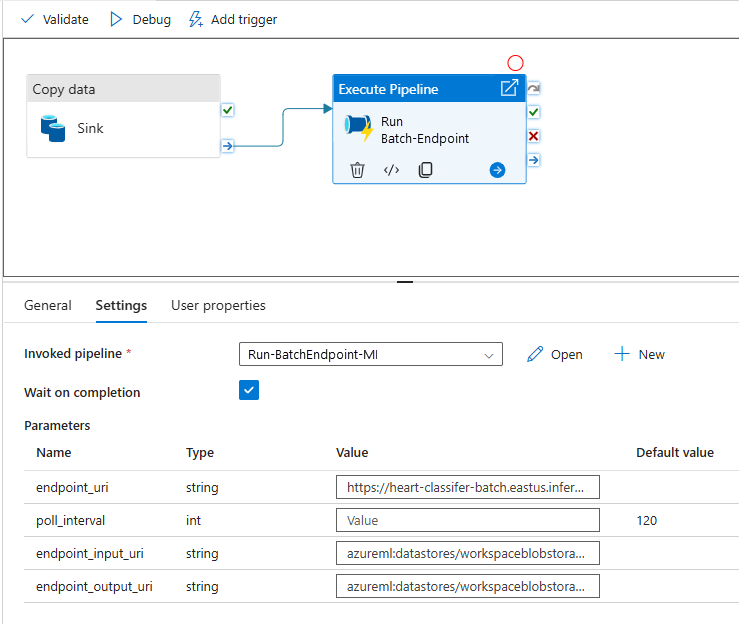
Váš kanál je připravený k použití.
Omezení
Při použití dávkových nasazení služby Azure Machine Learning zvažte následující omezení:
Vstupy dat
- Jako vstupy se podporují jenom úložiště dat Azure Machine Learning nebo účty Azure Storage (Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2). Pokud jsou vstupní data v jiném zdroji, použijte službu Azure Data Factory aktivita Copy před spuštěním dávkové úlohy pro jímku dat do kompatibilního úložiště.
- Úlohy koncových bodů služby Batch nevyzkoušují vnořené složky. Nemůžou pracovat s vnořenými strukturami složek. Pokud jsou vaše data distribuovaná ve více složkách, musíte strukturu zploštět.
- Ujistěte se, že bodovací skript zadaný v nasazení dokáže zpracovávat data podle očekávání, že se do úlohy zadají. Pokud je model MLflow, podívejte se na omezení podporovaných typů souborů v tématu Nasazení modelů MLflow v dávkových nasazeních.
Výstupy dat
- Podporují se jenom registrovaná úložiště dat Azure Machine Learning. Doporučujeme zaregistrovat účet úložiště, který služba Azure Data Factory používá jako úložiště dat ve službě Azure Machine Learning. Tímto způsobem můžete zapisovat zpět do stejného účtu úložiště, ve kterém čtete.
- Výstupy podporují jenom účty Azure Blob Storage. Azure Data Lake Storage Gen2 se například nepodporuje jako výstup v úlohách dávkového nasazení. Pokud potřebujete exportovat data do jiného umístění nebo jímky, po spuštění dávkové úlohy použijte službu Azure Data Factory aktivita Copy.