Spouštění modelů Azure Machine Learning z Prostředků infrastruktury pomocí dávkových koncových bodů (Preview)
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
V tomto článku se dozvíte, jak využívat dávkové nasazení služby Azure Machine Learning z Microsoft Fabric. I když pracovní postup používá modely, které jsou nasazené do dávkových koncových bodů, podporuje také použití nasazení dávkových kanálů z Prostředků infrastruktury.
Důležité
Tato funkce je v současné době ve verzi Public Preview. Tato verze Preview je poskytována bez smlouvy o úrovni služeb a nedoporučujeme ji pro produkční úlohy. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti.
Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Požadavky
- Získejte předplatné Microsoft Fabric. Nebo si zaregistrujte bezplatnou zkušební verzi Microsoft Fabric.
- Přihlaste se k Microsoft Fabric.
- Předplatné Azure. Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet. Vyzkoušejte bezplatnou nebo placenou verzi služby Azure Machine Learning.
- Pracovní prostor služby Azure Machine Learning. Pokud ho nemáte, postupujte podle pokynů v tématu Správa pracovních prostorů a vytvořte ho.
- Ujistěte se, že máte v pracovním prostoru následující oprávnění:
- Vytváření a správa dávkových koncových bodů a nasazení: Umožňuje používat role Vlastník, Přispěvatel nebo Vlastní role.
Microsoft.MachineLearningServices/workspaces/batchEndpoints/* - Vytvořte nasazení ARM ve skupině prostředků pracovního prostoru: Použijte role Vlastník, Přispěvatel nebo Vlastní role, které umožňují
Microsoft.Resources/deployments/writeve skupině prostředků, ve které je pracovní prostor nasazený.
- Vytváření a správa dávkových koncových bodů a nasazení: Umožňuje používat role Vlastník, Přispěvatel nebo Vlastní role.
- Ujistěte se, že máte v pracovním prostoru následující oprávnění:
- Model nasazený do dávkového koncového bodu Pokud ho nemáte, vytvořte ho pomocí kroků v části Nasazení modelů pro bodování v dávkových koncových bodech .
- Stáhněte si ukázkovou datovou sadu heart-unlabeled.csv, která se má použít k bodování.
Architektura
Azure Machine Learning nemá přímý přístup k datům uloženým v OneLake fabric. Pomocí funkce OneLake ale můžete v rámci Lakehouse vytvářet zástupce ke čtení a zápisu dat uložených v Azure Data Lake Gen2. Vzhledem k tomu, že Azure Machine Learning podporuje azure Data Lake Storage Gen2, umožňuje toto nastavení společně používat prostředky infrastruktury a Azure Machine Learning. Architektura dat je následující:

Konfigurace přístupu k datům
Pokud chcete službě Fabric a Azure Machine Learning umožnit čtení a zápis stejných dat bez nutnosti jejich kopírování, můžete využít klávesové zkratky OneLake a úložiště dat Služby Azure Machine Learning. Když nasměrujete zástupce OneLake a úložiště dat na stejný účet úložiště, můžete zajistit, aby prostředky Infrastruktury i Azure Machine Learning četly ze stejných podkladových dat a zapisovat do nich.
V této části vytvoříte nebo identifikujete účet úložiště, který se použije k ukládání informací, které bude koncový bod dávky využívat, a že uživatelé prostředků infrastruktury uvidí ve OneLake. Prostředky infrastruktury podporují pouze účty úložiště s povolenými hierarchickými názvy, jako je Azure Data Lake Gen2.
Vytvoření zástupce OneLake pro účet úložiště
Otevřete prostředí pro Datoví technici Synapse v prostředcích infrastruktury.
Na levém panelu vyberte pracovní prostor Fabric a otevřete ho.
Otevřete lakehouse, který použijete ke konfiguraci připojení. Pokud ještě nemáte jezerní dům, přejděte do Datoví technici prostředí pro vytvoření jezera. V tomto příkladu použijete lakehouse s názvem důvěryhodné.
Na navigačním panelu na levé straně otevřete další možnosti pro soubory a pak vyberte Nový zástupce , aby se průvodce otevřel.
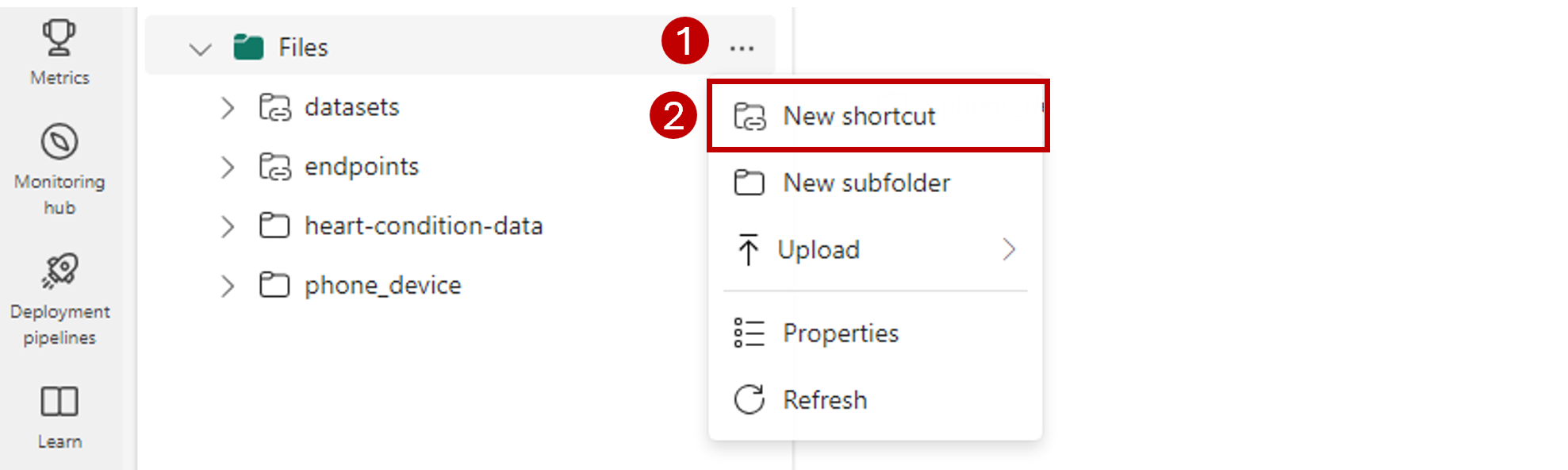
Vyberte možnost Azure Data Lake Storage Gen2.

V části Nastavení připojení vložte adresu URL přidruženou k účtu úložiště Azure Data Lake Gen2.
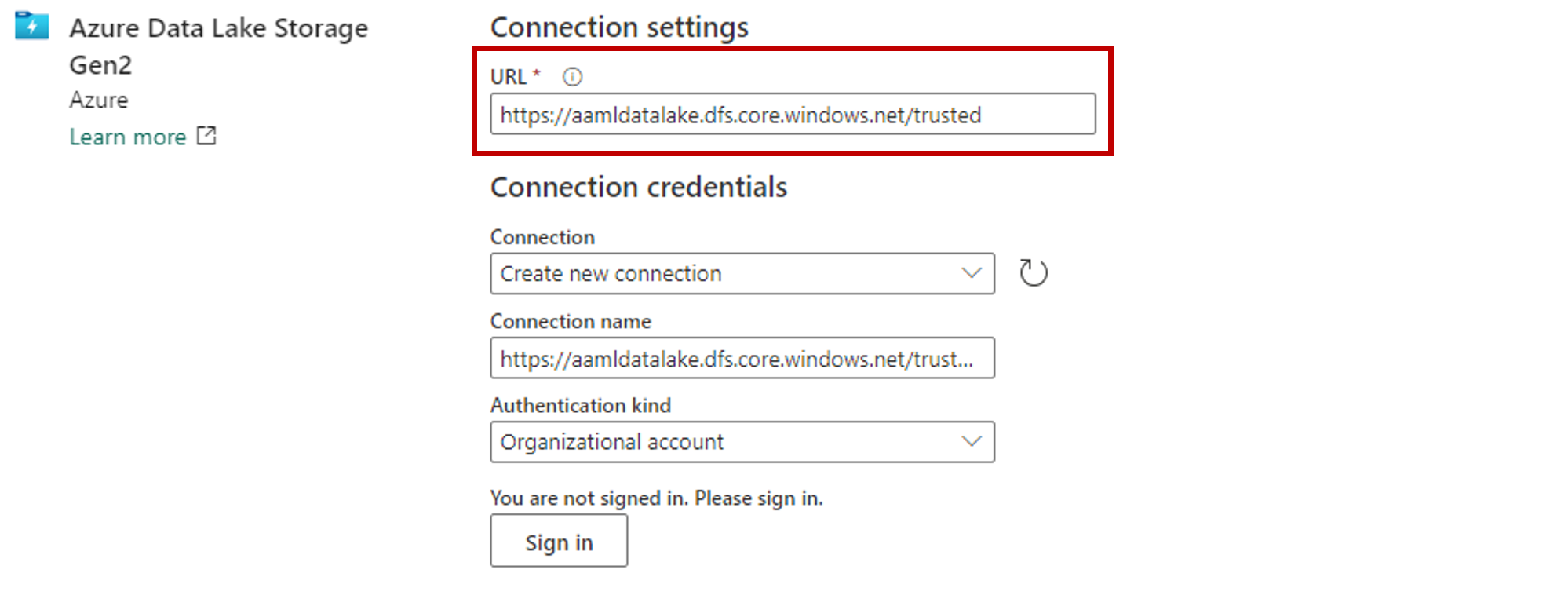
V části Přihlašovací údaje připojení:
- V části Připojení vyberte Vytvořit nové připojení.
- Jako název připojení ponechte výchozí vyplněnou hodnotu.
- Jako druh ověřování vyberte účet organizace a použijte přihlašovací údaje připojeného uživatele prostřednictvím OAuth 2.0.
- Pokud se chcete přihlásit, vyberte Přihlásit se.
Vyberte Další.
V případě potřeby nakonfigurujte cestu ke zkratce vzhledem k účtu úložiště. Toto nastavení použijte ke konfiguraci složky, na kterou bude zástupce odkazovat.
Nakonfigurujte název zástupce. Tento název bude cesta uvnitř jezera. V tomto příkladu pojmenujte datové sady zástupců.
Uložte změny.



Vytvoření úložiště dat, které odkazuje na účet úložiště
Přejděte do pracovního prostoru Azure Machine Learning.
Přejděte do části Data .
Vyberte kartu Úložiště dat.
Vyberte Vytvořit.
Úložiště dat nakonfigurujte následujícím způsobem:
Jako název úložiště dat zadejte trusted_blob.
Jako typ úložiště dat vyberte Azure Blob Storage.
Tip
Proč byste měli místo Azure Data Lake Gen2 nakonfigurovat Azure Blob Storage? Koncové body služby Batch můžou zapisovat pouze předpovědi do účtů Blob Storage. Každý účet úložiště Azure Data Lake Gen2 je však také účtem úložiště objektů blob; lze je proto použít zaměnitelně.
V průvodci vyberte účet úložiště pomocí ID předplatného, účtu úložiště a kontejneru objektů blob (systém souborů).
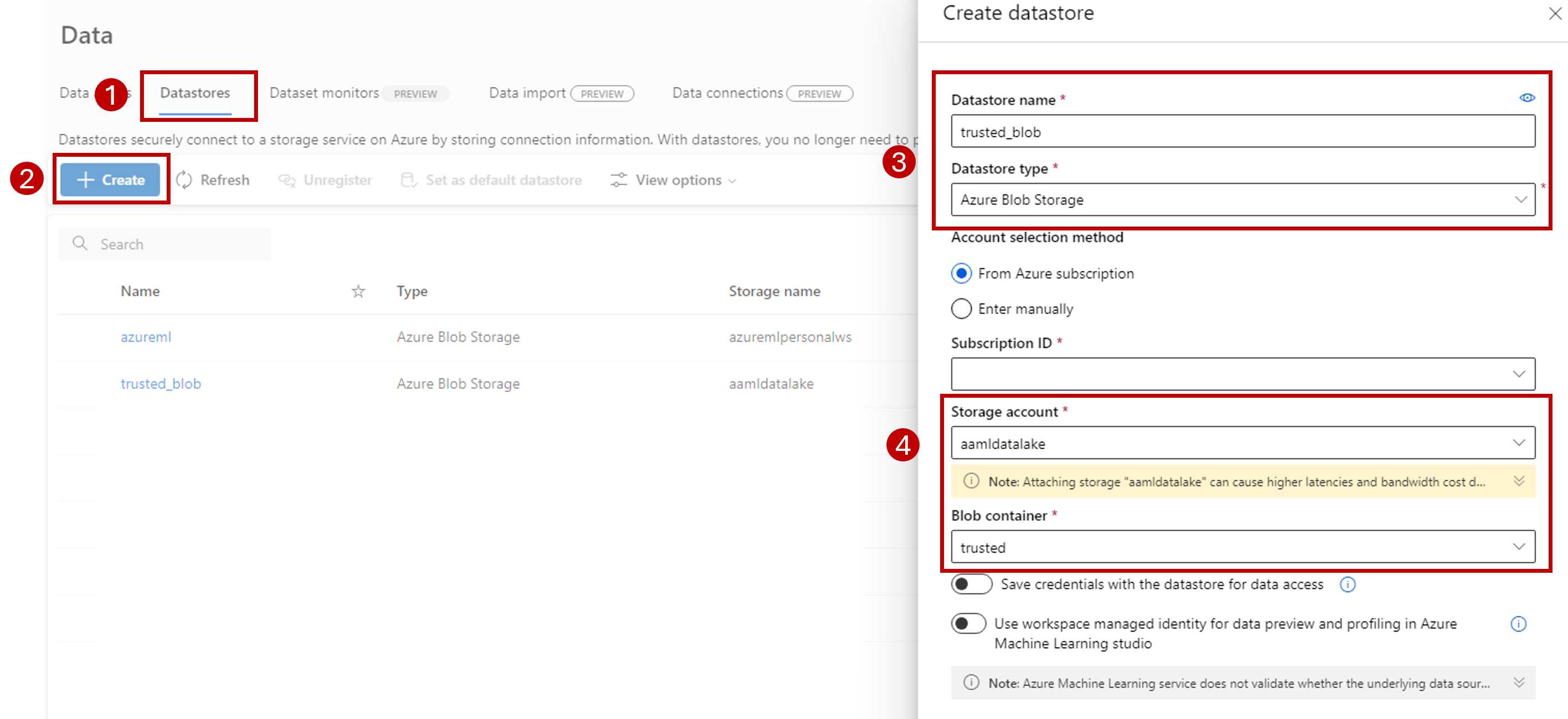
Vyberte Vytvořit.
Ujistěte se, že výpočetní prostředky, na kterých je spuštěný koncový bod dávky, má oprávnění připojit data v tomto účtu úložiště. Přestože je přístup stále udělen identitou, která volá koncový bod, výpočetní prostředky, ve kterých se spouští dávkové koncové body, musí mít oprávnění k připojení účtu úložiště, který zadáte. Další informace najdete v tématu Přístup ke službám úložiště.
Nahrání ukázkové datové sady
Nahrajte ukázková data pro koncový bod, která se mají použít jako vstup:
Přejděte do pracovního prostoru Prostředky infrastruktury.
Vyberte objekt lakehouse, ve kterém jste vytvořili zástupce.
Přejděte na zástupce datových sad.
Vytvořte složku pro uložení ukázkové datové sady, kterou chcete určit skóre. Pojmenujte složku uci-heart-unlabeled.
Pomocí možnosti Získat data a výběrem možnosti Nahrát soubory nahrajte ukázkovou datovou sadu heart-unlabeled.csv.

Nahrajte ukázkovou datovou sadu.
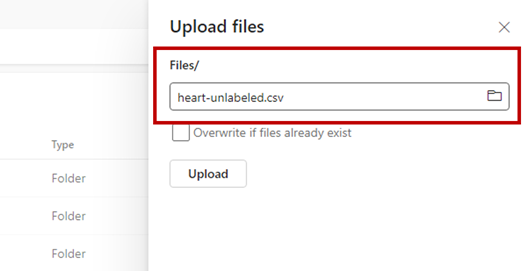
Ukázkový soubor je připravený k použití. Poznamenejte si cestu k umístění, kam jste ho uložili.


Vytvoření kanálu pro odvozování dávek z prostředků infrastruktury
V této části vytvoříte kanál odvozování fabric-to-batch ve stávajícím pracovním prostoru Fabric a vyvoláte koncové body dávky.
Vraťte se do Datoví technici prostředí (pokud jste už od něj přešli) pomocí ikony selektoru prostředí v levém dolním rohu domovské stránky.
Otevřete pracovní prostor Fabric.
V části Nový na domovské stránce vyberte Datový kanál.
Pojmenujte kanál a vyberte Vytvořit.
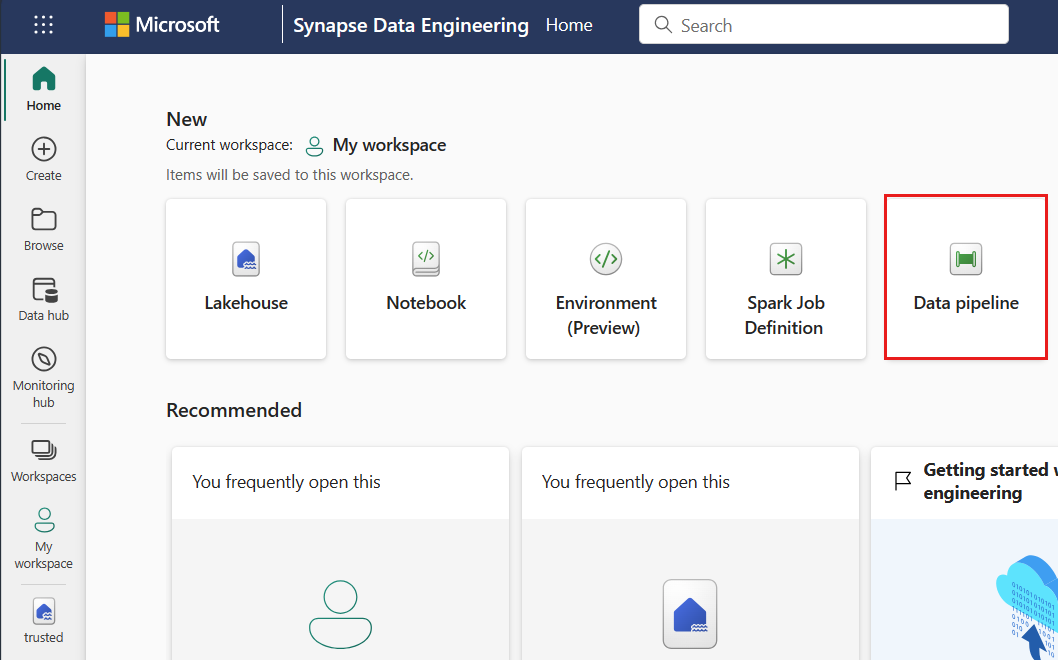
Na plátně návrháře vyberte kartu Aktivity na panelu nástrojů.
Na konci karty vyberte další možnosti a vyberte Azure Machine Learning.
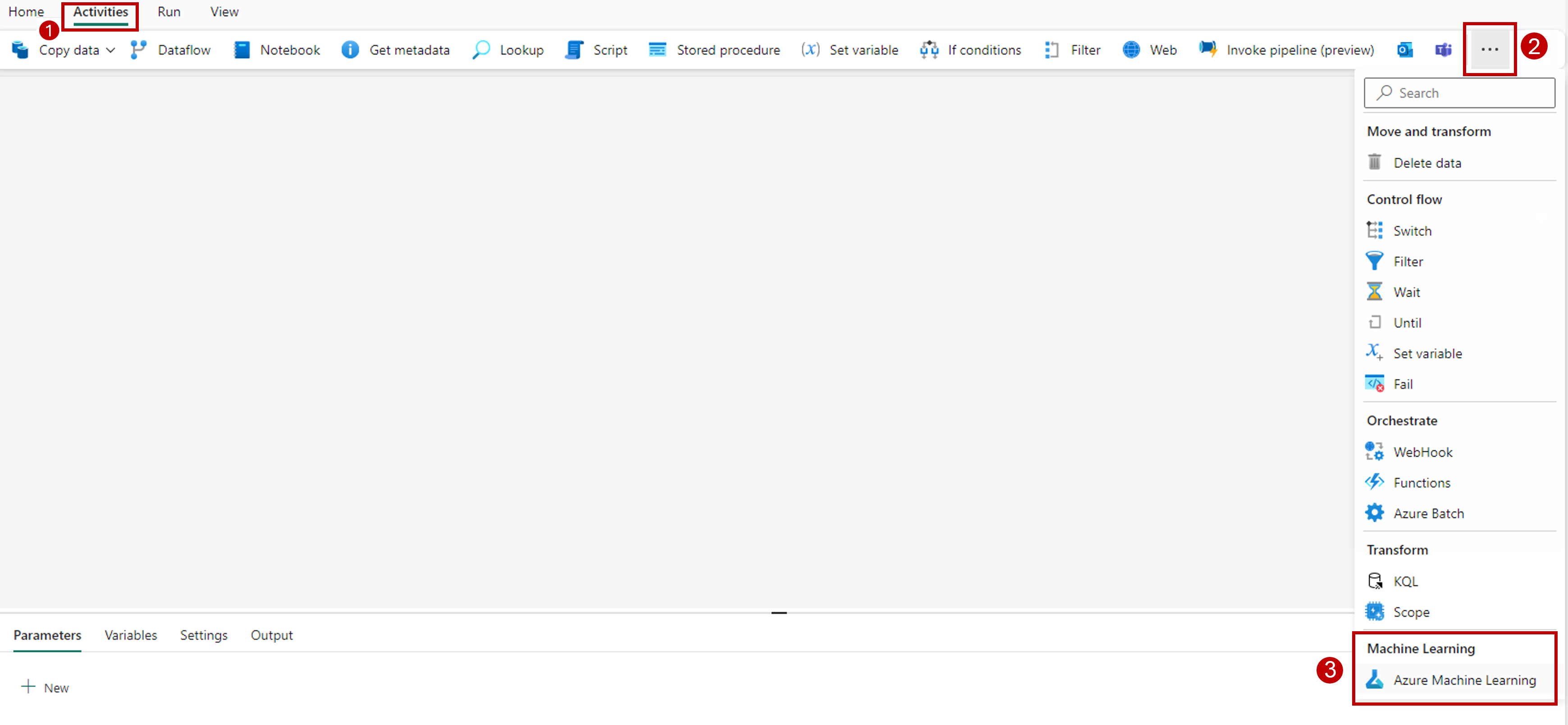
Přejděte na kartu Nastavení a nakonfigurujte aktivitu následujícím způsobem:
Výběrem možnosti Nový vedle připojení Azure Machine Learning vytvořte nové připojení k pracovnímu prostoru Azure Machine Learning, který obsahuje vaše nasazení.
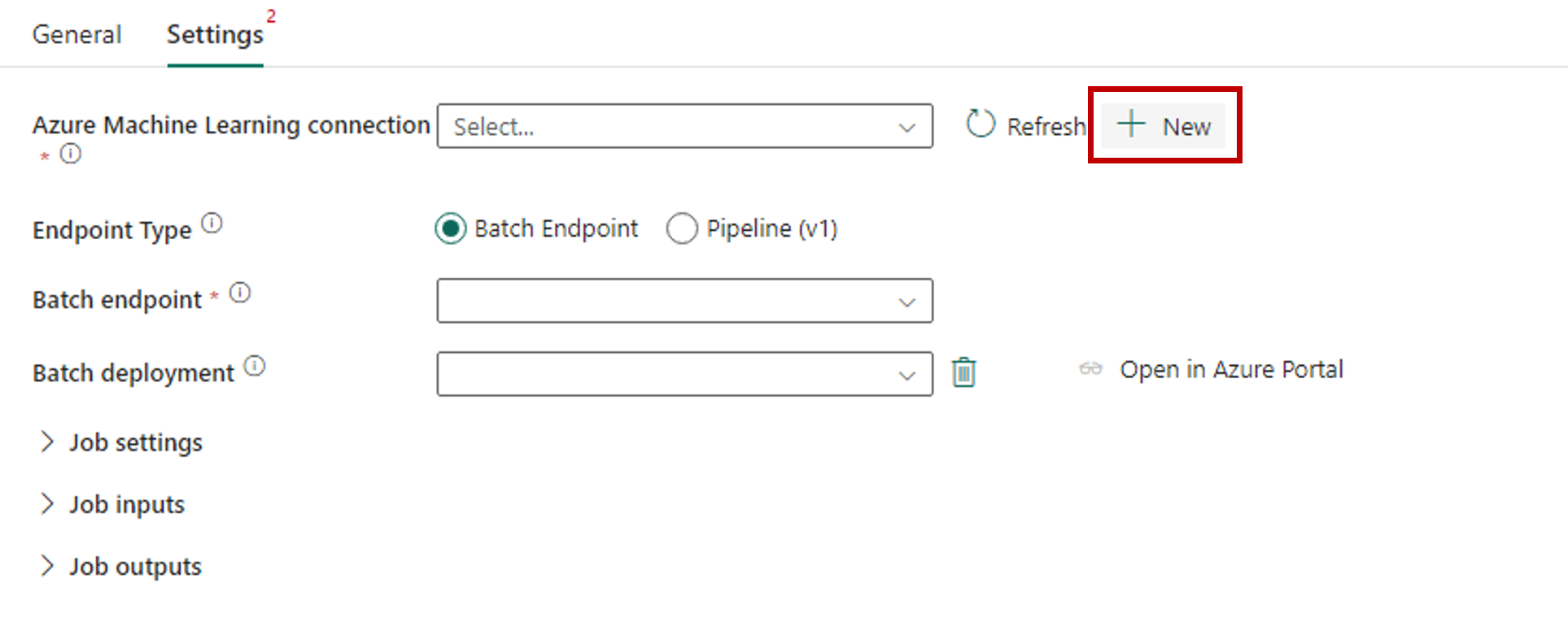
V části Nastavení připojení průvodce vytvořením zadejte hodnoty ID předplatného, název skupiny prostředků a název pracovního prostoru, kde je váš koncový bod nasazený.
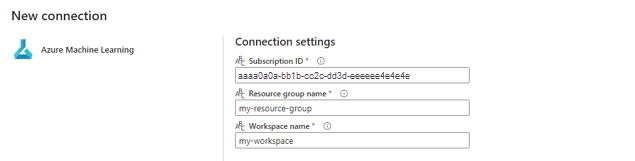
V části Přihlašovací údaje pro připojení vyberte účet organizace jako hodnotu pro typ ověřování pro vaše připojení. Účet organizace používá přihlašovací údaje připojeného uživatele. Případně můžete použít instanční objekt. V produkčním nastavení doporučujeme použít instanční objekt. Bez ohledu na typ ověřování se ujistěte, že identita přidružená k připojení má práva k volání dávkového koncového bodu, který jste nasadili.

Uložte připojení. Po výběru připojení služba Fabric automaticky naplní dostupné koncové body dávky ve vybraném pracovním prostoru.
V části Koncový bod služby Batch vyberte dávkový koncový bod, který chcete volat. V tomto příkladu vyberte klasifikátor heart-....
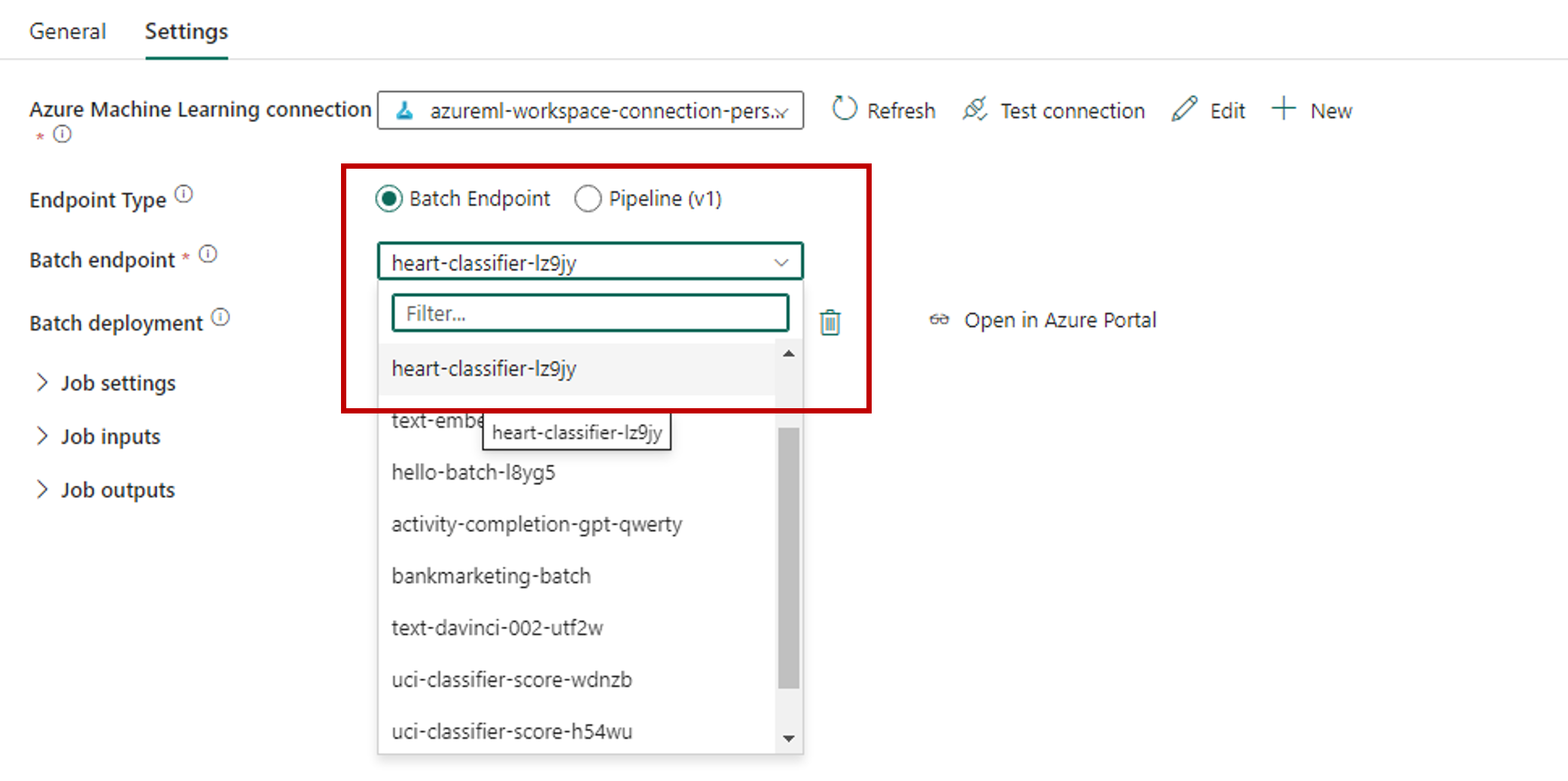
Oddíl nasazení služby Batch automaticky naplní dostupná nasazení v rámci koncového bodu.
V případě nasazení služby Batch vyberte v seznamu konkrétní nasazení, pokud je to potřeba. Pokud nevyberete nasazení, fabric vyvolá výchozí nasazení v rámci koncového bodu a umožní tvůrci dávkového koncového bodu rozhodnout, které nasazení se volá. Ve většině scénářů byste chtěli zachovat toto výchozí chování.







Konfigurace vstupů a výstupů pro koncový bod dávky
V této části nakonfigurujete vstupy a výstupy z dávkového koncového bodu. Vstupy do dávkových koncových bodů poskytují data a parametry potřebné ke spuštění procesu. Kanál batch služby Azure Machine Learning v prostředcích infrastruktury podporuje nasazení modelů i nasazení kanálů. Zadaný počet a typ vstupů závisí na typu nasazení. V tomto příkladu použijete nasazení modelu, které vyžaduje přesně jeden vstup a vytvoří jeden výstup.
Další informace o vstupech avýstupch
Konfigurace vstupního oddílu
Oddíl Vstupy úlohy nakonfigurujte následujícím způsobem:
Rozbalte část Vstupy úlohy.
Výběrem možnosti Nový přidáte nový vstup do koncového bodu.
Pojmenujte vstup
input_data. Vzhledem k tomu, že používáte nasazení modelu, můžete použít libovolný název. V případě nasazení kanálu ale musíte určit přesný název vstupu, který model očekává.Výběrem rozevírací nabídky vedle vstupu, který jste právě přidali, otevřete vlastnost vstupu (pole název a hodnota).
Do pole Název zadejte
JobInputTypetyp vstupu, který vytváříte.Do pole Hodnota zadejte
UriFolder, že vstup je cesta ke složce. Další podporované hodnoty pro toto pole jsou UriFile (cesta k souboru) nebo literál (jakákoli hodnota literálu , jako je řetězec nebo celé číslo). Musíte použít správný typ, který vaše nasazení očekává.Vyberte znaménko plus vedle vlastnosti a přidejte další vlastnost pro tento vstup.
Do pole Název zadejte
Uricestu k datům.Zadejte
azureml://datastores/trusted_blob/datasets/uci-heart-unlabeledcestu k vyhledání dat v poli Hodnota . Tady použijete cestu, která vede k účtu úložiště, který je propojený s OneLake v Prostředcích infrastruktury i se službou Azure Machine Learning. azureml://datastores/trusted_blob/datasets/uci-heart-unlabeled je cesta k souborům CSV s očekávanými vstupními daty modelu nasazeného do dávkového koncového bodu. Můžete také použít přímou cestu k účtu úložiště, napříkladhttps://<storage-account>.dfs.azure.com.
Tip
Pokud je vstup typu Literál, nahraďte vlastnost
Urihodnotou Value.
Pokud váš koncový bod vyžaduje více vstupů, opakujte předchozí kroky pro každý z nich. V tomto příkladu nasazení modelu vyžadují přesně jeden vstup.
Konfigurace výstupního oddílu
Následujícím způsobem nakonfigurujte oddíl Výstupy úlohy:
Rozbalte oddíl Výstupy úlohy.
Výběrem možnosti Nový přidáte do koncového bodu nový výstup.
Pojmenujte výstup jako
output_data. Vzhledem k tomu, že používáte nasazení modelu, můžete použít libovolný název. U nasazení kanálů ale musíte určit přesný název výstupu, který model generuje.Výběrem rozevírací nabídky vedle výstupu, který jste právě přidali, otevřete vlastnost výstupu (pole název a hodnota).
Do pole Název zadejte
JobOutputTypetyp výstupu, který vytváříte.Do pole Hodnota zadejte
UriFile, že výstup je cesta k souboru. Další podporovaná hodnota tohoto pole je UriFolder (cesta ke složce). Na rozdíl od vstupního oddílu úlohy není literál (jakákoli hodnota literálu, jako je řetězec nebo celé číslo), podporován jako výstup.Vyberte znaménko plus vedle vlastnosti a přidejte další vlastnost pro tento výstup.
Do pole Název zadejte
Uricestu k datům.Zadejte
@concat(@concat('azureml://datastores/trusted_blob/paths/endpoints', pipeline().RunId, 'predictions.csv')cestu k umístění výstupu do pole Hodnota . Koncové body služby Azure Machine Learning batch podporují jako výstupy pouze použití cest k úložišti dat. Vzhledem k tomu,@concat(@concat('azureml://datastores/trusted_blob/paths/endpoints', pipeline().RunId, 'predictions.csv')že výstupy musí být jedinečné, aby nedocházelo ke konfliktům, použili jste k vytvoření cesty dynamický výraz.
Pokud váš koncový bod vrátí více výstupů, opakujte předchozí kroky pro každý z nich. V tomto příkladu nasazení modelu vytvoří přesně jeden výstup.
(Volitelné) Konfigurace nastavení úlohy
Nastavení úlohy můžete také nakonfigurovat přidáním následujících vlastností:
Pro nasazení modelu:
| Nastavení | Popis |
|---|---|
MiniBatchSize |
Velikost dávky. |
ComputeInstanceCount |
Počet výpočetníchinstancích |
Pro nasazení kanálů:
| Nastavení | Popis |
|---|---|
ContinueOnStepFailure |
Označuje, jestli má kanál zastavit zpracování uzlů po selhání. |
DefaultDatastore |
Označuje výchozí úložiště dat, které se má použít pro výstupy. |
ForceRun |
Označuje, jestli má kanál vynutit spuštění všech komponent, i když je možné výstup odvodit z předchozího spuštění. |
Po nakonfigurování můžete kanál otestovat.