Transformace dat s fondy Apache Sparku (zastaralé)
PLATÍ PRO: Python SDK azureml v1
Python SDK azureml v1
Upozorňující
Integrace Azure Synapse Analytics se službou Azure Machine Learning, která je dostupná v sadě Python SDK v1, je zastaralá. Uživatelé stále můžou používat pracovní prostor Synapse zaregistrovaný ve službě Azure Machine Learning jako propojenou službu. Nový pracovní prostor Synapse však již není možné zaregistrovat ve službě Azure Machine Learning jako propojenou službu. Doporučujeme používat bezserverové výpočetní prostředky Sparku a připojené fondy Synapse Spark dostupné v CLI v2 a Python SDK v2. Další informace najdete na adrese https://aka.ms/aml-spark.
V tomto článku se dozvíte, jak interaktivně provádět úlohy transformace dat v rámci vyhrazené relace Synapse využívající Azure Synapse Analytics v poznámkovém bloku Jupyter. Tyto úlohy závisí na sadě Azure Machine Learning Python SDK. Další informace o kanálech Azure Machine Learning najdete v tématu Použití Apache Sparku (využívajícího Azure Synapse Analytics) v kanálu strojového učení (Preview). Další informace o tom, jak používat Azure Synapse Analytics s pracovním prostorem Synapse, najdete v úvodní sérii Azure Synapse Analytics.
Integrace služby Azure Machine Learning a Azure Synapse Analytics
Díky integraci Azure Synapse Analytics se službou Azure Machine Learning (Preview) můžete připojit fond Apache Sparku, který podporuje Azure Synapse, pro interaktivní zkoumání a přípravu dat. S touto integrací můžete mít vyhrazený výpočetní prostředek pro transformaci dat ve velkém měřítku, a to vše ve stejném poznámkovém bloku Pythonu, který používáte k trénování modelů strojového učení.
Požadavky
Konfigurace vývojového prostředí pro instalaci sady Azure Machine Learning SDK nebo použití výpočetní instance služby Azure Machine Learning s již nainstalovanou sadou SDK
Instalace sady Azure Machine Learning Python SDK
Vytvoření fondu Apache Spark pomocí webu Azure Portal, webových nástrojů nebo synapse Studia
azureml-synapseNainstalujte balíček (Preview) s tímto kódem:pip install azureml-synapsePropojení pracovního prostoru Azure Machine Learning a pracovního prostoru Azure Synapse Analytics se sadou Azure Machine Learning Python SDK nebo s studio Azure Machine Learning
Připojení fondu Synapse Spark jako cílového výpočetního objektu
Spuštění fondu Synapse Spark pro úlohy transformace dat
Pokud chcete zahájit přípravu dat s fondem Apache Spark, zadejte připojený název výpočetních prostředků Synapse Sparku. Tento název najdete pomocí studio Azure Machine Learning na kartě Připojené výpočty.
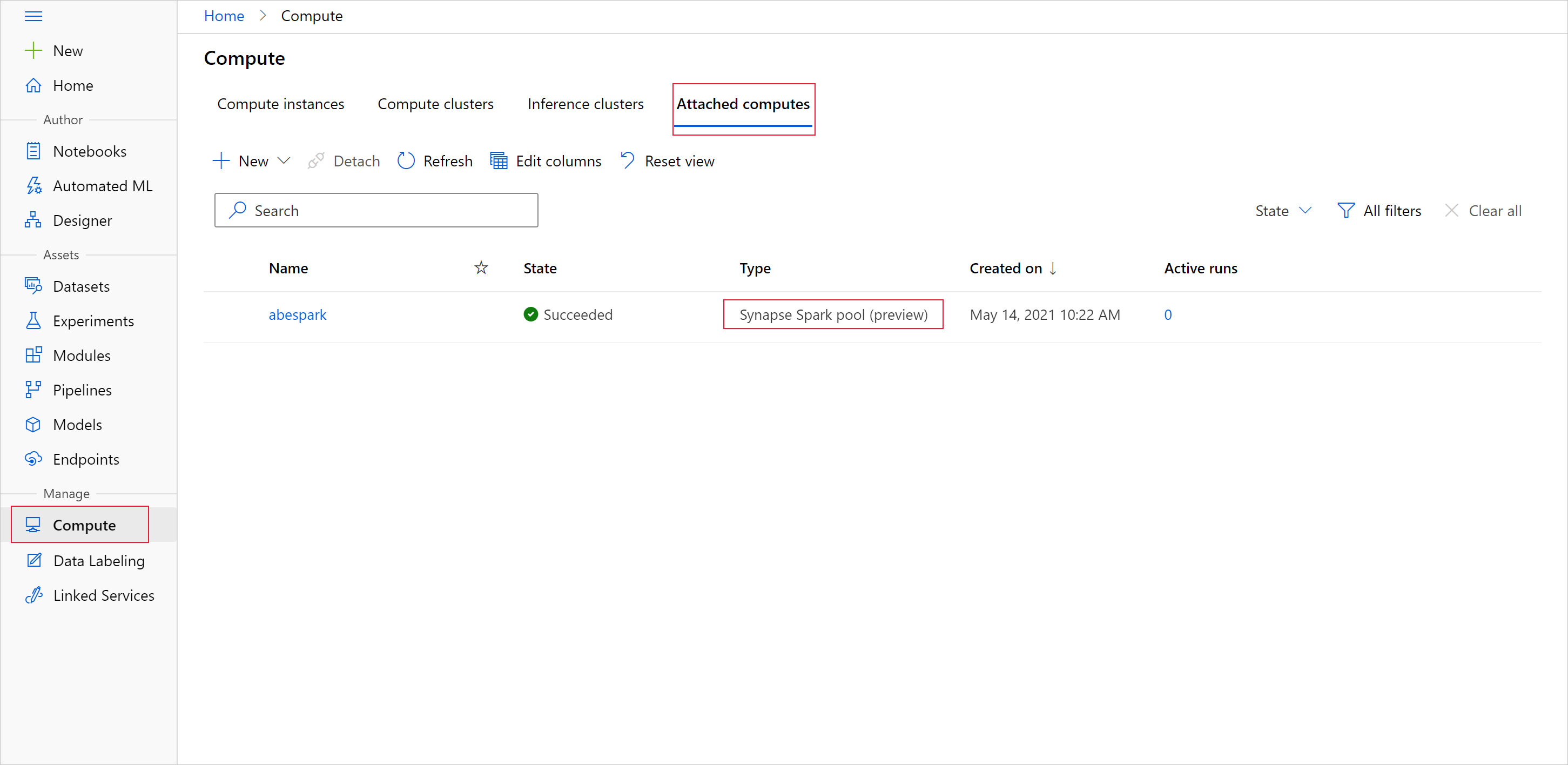
Důležité
Pokud chcete pokračovat v používání fondu Apache Spark, musíte určit, který výpočetní prostředek se má použít v rámci úloh transformace dat. Slouží %synapse pro jednotlivé řádky kódu a %%synapse pro více řádků:
%synapse start -c SynapseSparkPoolAlias
Po spuštění relace můžete zkontrolovat metadata relace:
%synapse meta
Můžete zadat prostředí Azure Machine Learning, které se má použít během relace Apache Sparku. Projeví se pouze závislosti Conda zadané v prostředí. Image Dockeru nejsou podporované.
Upozorňující
Závislosti Pythonu zadané v závislosti Conda prostředí nejsou podporovány ve fondech Apache Sparku. V současné době se ve sys.version_info skriptu podporují pouze pevné verze Pythonu, aby se zkontrolovala vaše verze Pythonu.
Tento kód vytvoří proměnnoumyenv prostředí pro instalaci azureml-core verze 1.20.0 a numpy verze 1.17.0 před spuštěním relace. Toto prostředí pak můžete zahrnout do příkazu relace start Apache Sparku.
from azureml.core import Workspace, Environment
# creates environment with numpy and azureml-core dependencies
ws = Workspace.from_config()
env = Environment(name="myenv")
env.python.conda_dependencies.add_pip_package("azureml-core==1.20.0")
env.python.conda_dependencies.add_conda_package("numpy==1.17.0")
env.register(workspace=ws)
Pokud chcete zahájit přípravu dat s fondem Apache Spark ve vlastním prostředí, zadejte název fondu Apache Spark i prostředí, které se má použít během relace Apache Sparku. Můžete zadat ID předplatného, skupinu prostředků pracovního prostoru strojového učení a název pracovního prostoru strojového učení.
%synapse start -c SynapseSparkPoolAlias -e myenv -s AzureMLworkspaceSubscriptionID -r AzureMLworkspaceResourceGroupName -w AzureMLworkspaceName
Načtení dat z úložiště
Po spuštění relace Apache Sparku si přečtěte data, která chcete připravit. Načítání dat se podporuje pro Azure Blob Storage a Azure Data Lake Storage generace 1 a 2.
Máte dvě možnosti načtení dat z těchto služeb úložiště:
Přímé načtení dat z úložiště s cestou systému distribuovaných souborů Hadoop (HDFS)
Čtení dat z existující datové sady Azure Machine Learning
Pro přístup k těmto službám úložiště potřebujete oprávnění čtenáře dat objektů blob služby Storage. K zápisu dat zpět do těchto služeb úložiště potřebujete oprávnění Přispěvatel dat objektů blob služby Storage. Přečtěte si další informace o oprávněních a rolích úložiště.
Načtení dat pomocí cesty systému distribuovaných souborů Hadoop (HDFS)
K načtení a čtení dat z úložiště s odpovídající cestou HDFS potřebujete k dispozici přihlašovací údaje pro ověření přístupu k datům. Tyto přihlašovací údaje se liší v závislosti na typu úložiště. Tento ukázkový kód ukazuje, jak číst data z úložiště objektů blob v Azure do datového rámce Sparku s tokenem sdíleného přístupového podpisu (SAS) nebo přístupovým klíčem:
%%synapse
# setup access key or SAS token
sc._jsc.hadoopConfiguration().set("fs.azure.account.key.<storage account name>.blob.core.windows.net", "<access key>")
sc._jsc.hadoopConfiguration().set("fs.azure.sas.<container name>.<storage account name>.blob.core.windows.net", "<sas token>")
# read from blob
df = spark.read.option("header", "true").csv("wasbs://demo@dprepdata.blob.core.windows.net/Titanic.csv")
Tento ukázkový kód ukazuje, jak číst data z Azure Data Lake Storage Generation 1 (ADLS Gen1) pomocí přihlašovacích údajů instančního objektu:
%%synapse
# setup service principal which has access of the data
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.access.token.provider.type","ClientCredential")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.client.id", "<client id>")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.credential", "<client secret>")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.refresh.url",
"https://login.microsoftonline.com/<tenant id>/oauth2/token")
df = spark.read.csv("adl://<storage account name>.azuredatalakestore.net/<path>")
Tento ukázkový kód ukazuje, jak číst data z Azure Data Lake Storage Generation 2 (ADLS Gen2) pomocí přihlašovacích údajů instančního objektu:
%%synapse
# setup service principal which has access of the data
sc._jsc.hadoopConfiguration().set("fs.azure.account.auth.type.<storage account name>.dfs.core.windows.net","OAuth")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth.provider.type.<storage account name>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.id.<storage account name>.dfs.core.windows.net", "<client id>")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.secret.<storage account name>.dfs.core.windows.net", "<client secret>")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.endpoint.<storage account name>.dfs.core.windows.net",
"https://login.microsoftonline.com/<tenant id>/oauth2/token")
df = spark.read.csv("abfss://<container name>@<storage account>.dfs.core.windows.net/<path>")
Čtení dat z registrovaných datových sad
Existující registrovanou datovou sadu můžete také umístit do pracovního prostoru a provést na ni přípravu dat, pokud ji převedete na datový rámec Sparku. Tento příklad se ověří v pracovním prostoru, získá zaregistrovanou tabulkovou datovou sadu –blob_dset která odkazuje na soubory v úložišti objektů blob a převede tuto tabulkovou datovou sadu na datový rámec Sparku. Při převodu datových sad na datové rámce Spark můžete použít pyspark knihovny pro zkoumání a přípravu dat.
%%synapse
from azureml.core import Workspace, Dataset
subscription_id = "<enter your subscription ID>"
resource_group = "<enter your resource group>"
workspace_name = "<enter your workspace name>"
ws = Workspace(workspace_name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group)
dset = Dataset.get_by_name(ws, "blob_dset")
spark_df = dset.to_spark_dataframe()
Provádění úloh transformace dat
Po načtení a prozkoumání dat můžete provádět úlohy transformace dat. Tento vzorový kód se rozšiřuje o příklad HDFS v předchozí části. Na základě sloupce Survivor filtruje data v datovém rámci df Sparku a seskupuje podle věku:
%%synapse
from pyspark.sql.functions import col, desc
df.filter(col('Survived') == 1).groupBy('Age').count().orderBy(desc('count')).show(10)
df.show()
Ukládání dat do úložiště a zastavení relace Sparku
Po dokončení průzkumu a přípravy dat uložte připravená data pro pozdější použití v účtu úložiště v Azure. V této ukázce kódu se připravená data zapisují zpět do služby Azure Blob Storage a přepíšou původní Titanic.csv soubor v training_data adresáři. Abyste mohli zapisovat zpět do úložiště, potřebujete oprávnění Přispěvatel dat v objektech blob služby Storage. Další informace najdete v tématu Přiřazení role Azure pro přístup k datům objektů blob.
%% synapse
df.write.format("csv").mode("overwrite").save("wasbs://demo@dprepdata.blob.core.windows.net/training_data/Titanic.csv")
Po dokončení přípravy dat a uložení připravených dat do úložiště ukončete použití fondu Apache Spark tímto příkazem:
%synapse stop
Vytvoření datové sady pro reprezentaci připravených dat
Až budete připraveni využívat připravená data pro trénování modelu, připojte se k úložišti dat Azure Machine Learning a zadejte soubor nebo soubor, který chcete použít s datovou sadou Azure Machine Learning.
Tento příklad kódu
- Předpokládá, že jste už vytvořili úložiště dat, které se připojuje ke službě úložiště, do které jste uložili připravená data.
- Načte existující úložiště dat –
mydatastorez pracovního prostoruwspomocí metody get(). - Vytvoří FileDataset,
train_dskterý bude odkazovat na připravené datové soubory umístěné vmydatastoretraining_dataadresáři. - Vytvoří proměnnou
input1. Později může tato proměnná zpřístupnit datové souborytrain_dsdatové sady cílovému výpočetnímu objektu pro vaše trénovací úkoly.
from azureml.core import Datastore, Dataset
datastore = Datastore.get(ws, datastore_name='mydatastore')
datastore_paths = [(datastore, '/training_data/')]
train_ds = Dataset.File.from_files(path=datastore_paths, validate=True)
input1 = train_ds.as_mount()
ScriptRunConfig Použití příkazu k odeslání experimentu do fondu Synapse Spark
Pokud jste připraveni automatizovat a productionizovat úlohy transformace dat, můžete odeslat spuštění experimentu do připojeného fondu Synapse Spark s objektem ScriptRunConfig . Podobně platí, že pokud máte kanál Azure Machine Learning, můžete pomocí synapseSparkStep určit fond Synapse Spark jako cílový výpočetní objekt pro krok přípravy dat ve vašem kanálu. Dostupnost dat do fondu Synapse Spark závisí na typu datové sady.
- Pro FileDataset můžete použít metodu
as_hdfs(). Po odeslání spuštění se datová sada zpřístupní fondu Synapse Spark jako distribuovaného systému souborů Hadoop (HFDS). - Pro TabularDataset můžete použít metodu
as_named_input().
Následující ukázka kódu
- Vytvoří proměnnou
input2ze sady FileDatasettrain_ds, která byla vytvořena v předchozím příkladu kódu. - Vytvoří proměnnou
outputHDFSOutputDatasetConfigurations třídou. Po dokončení spuštění nám tato třída umožňuje uložit výstup spuštění jako datovou sadutestv úložištimydatastoredat. V pracovním prostorutestAzure Machine Learning se datová sada zaregistruje pod názvem.registered_dataset - Konfiguruje nastavení, která má spuštění použít k provedení ve fondu Synapse Spark.
- Definuje parametry ScriptRunConfig pro
dataprep.pyPoužití skriptu pro spuštění- Zadejte data, která se mají použít jako vstup, a jak tato data zpřístupnit fondu Synapse Spark.
- Určení, kam se mají ukládat
outputvýstupní data
from azureml.core import Dataset, HDFSOutputDatasetConfig
from azureml.core.environment import CondaDependencies
from azureml.core import RunConfiguration
from azureml.core import ScriptRunConfig
from azureml.core import Experiment
input2 = train_ds.as_hdfs()
output = HDFSOutputDatasetConfig(destination=(datastore, "test").register_on_complete(name="registered_dataset")
run_config = RunConfiguration(framework="pyspark")
run_config.target = synapse_compute_name
run_config.spark.configuration["spark.driver.memory"] = "1g"
run_config.spark.configuration["spark.driver.cores"] = 2
run_config.spark.configuration["spark.executor.memory"] = "1g"
run_config.spark.configuration["spark.executor.cores"] = 1
run_config.spark.configuration["spark.executor.instances"] = 1
conda_dep = CondaDependencies()
conda_dep.add_pip_package("azureml-core==1.20.0")
run_config.environment.python.conda_dependencies = conda_dep
script_run_config = ScriptRunConfig(source_directory = './code',
script= 'dataprep.py',
arguments = ["--file_input", input2,
"--output_dir", output],
run_config = run_config)
Další informace o obecné konfiguraci Sparku najdete v run_config.spark.configuration dokumentaci ke třídě SparkConfiguration a konfiguraci Apache Sparku.
Po nastavení ScriptRunConfig objektu můžete spuštění odeslat.
from azureml.core import Experiment
exp = Experiment(workspace=ws, name="synapse-spark")
run = exp.submit(config=script_run_config)
run
Další informace, včetně informací o skriptu použitém dataprep.py v tomto příkladu, najdete v ukázkovém poznámkovém bloku.
Po přípravě dat je můžete použít jako vstup pro trénovací úlohy. V příkladu kódu výše byste zadali registered_dataset jako vstupní data pro trénovací úlohy.
Příklady poznámkových bloků
V těchto ukázkových poznámkových blocích najdete další koncepty a ukázky možností integrace Azure Synapse Analytics a Azure Machine Learning:
- Spusťte interaktivní relaci Sparku z poznámkového bloku v pracovním prostoru Azure Machine Learning.
- Odešlete experiment služby Azure Machine Learning s fondem Synapse Spark jako vaším cílovým výpočetním objektem.
Další kroky
- Trénování modelu
- Trénujte s využitím datové sady Azure Machine Learning.