Správa balíčků v rozsahu relace
Kromě balíčků na úrovni fondu můžete na začátku relace poznámkového bloku zadat také knihovny v rámci relace. Knihovny v rámci relací umožňují v rámci relace poznámkového bloku zadávat a používat balíčky Pythonu, jar a R.
Při používání knihoven v rámci relací je důležité mít na paměti následující body:
- Při instalaci knihoven v rámci relace má přístup k zadaným knihovnám jenom aktuální poznámkový blok.
- Tyto knihovny nemají žádný vliv na jiné relace nebo úlohy, které používají stejný fond Sparku.
- Tyto knihovny se instalují nad knihovny základního modulu runtime a na úrovni fondu a mají nejvyšší prioritu.
- Knihovny v rámci relací se neuchovávají napříč relacemi.
Balíčky Pythonu s oborem relace
Správa balíčků Pythonu v rozsahu relace prostřednictvím souboru environment.yml
Určení balíčků Pythonu v rozsahu relace:
- Přejděte do vybraného fondu Sparku a ujistěte se, že jste povolili knihovny na úrovni relace. Toto nastavení můžete povolit tak, že přejdete na kartu Spravovat>balíčky fondu >Apache Sparku.
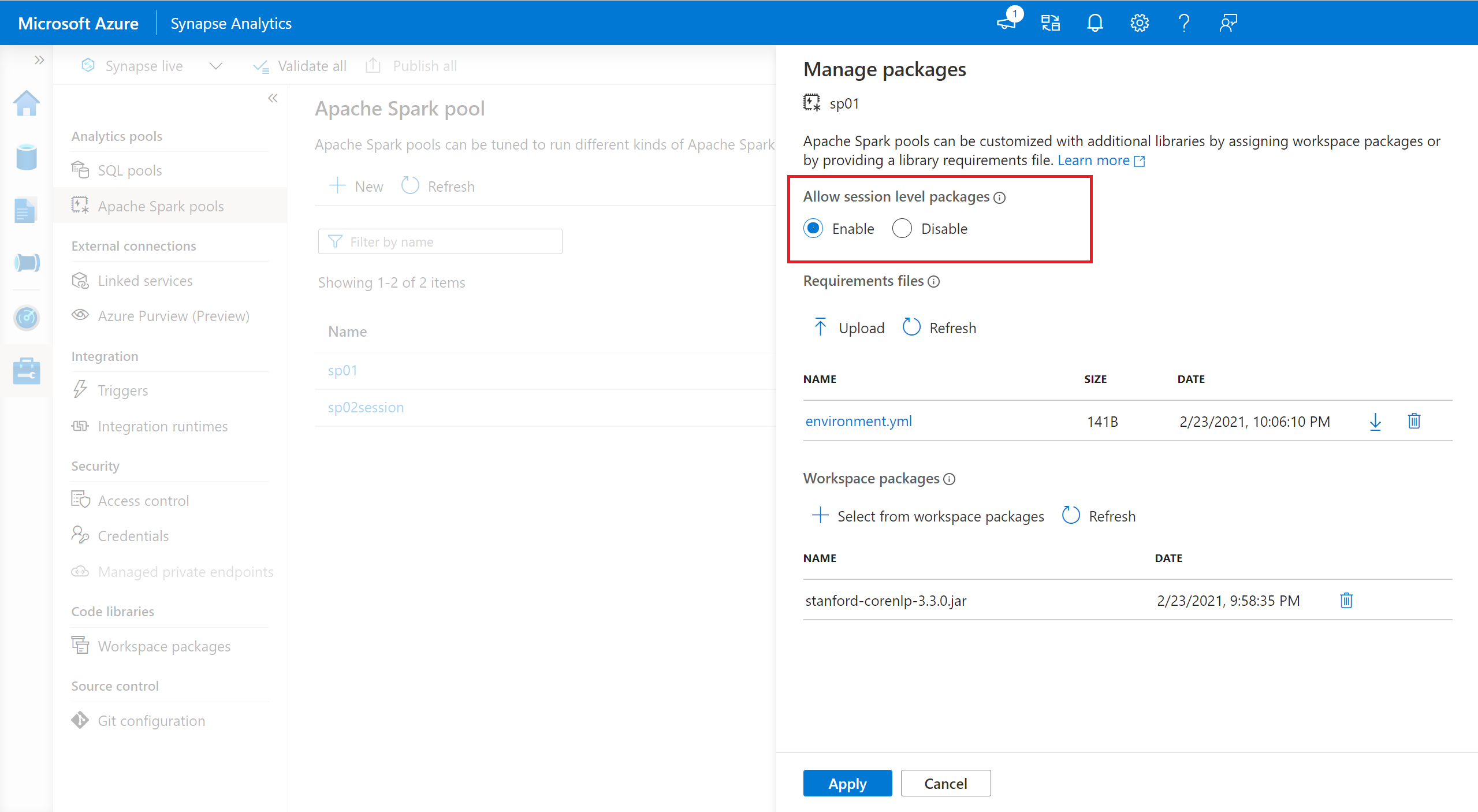
- Jakmile nastavení platí, můžete otevřít poznámkový blok a vybrat Konfigurovatbalíčkyrelací>.

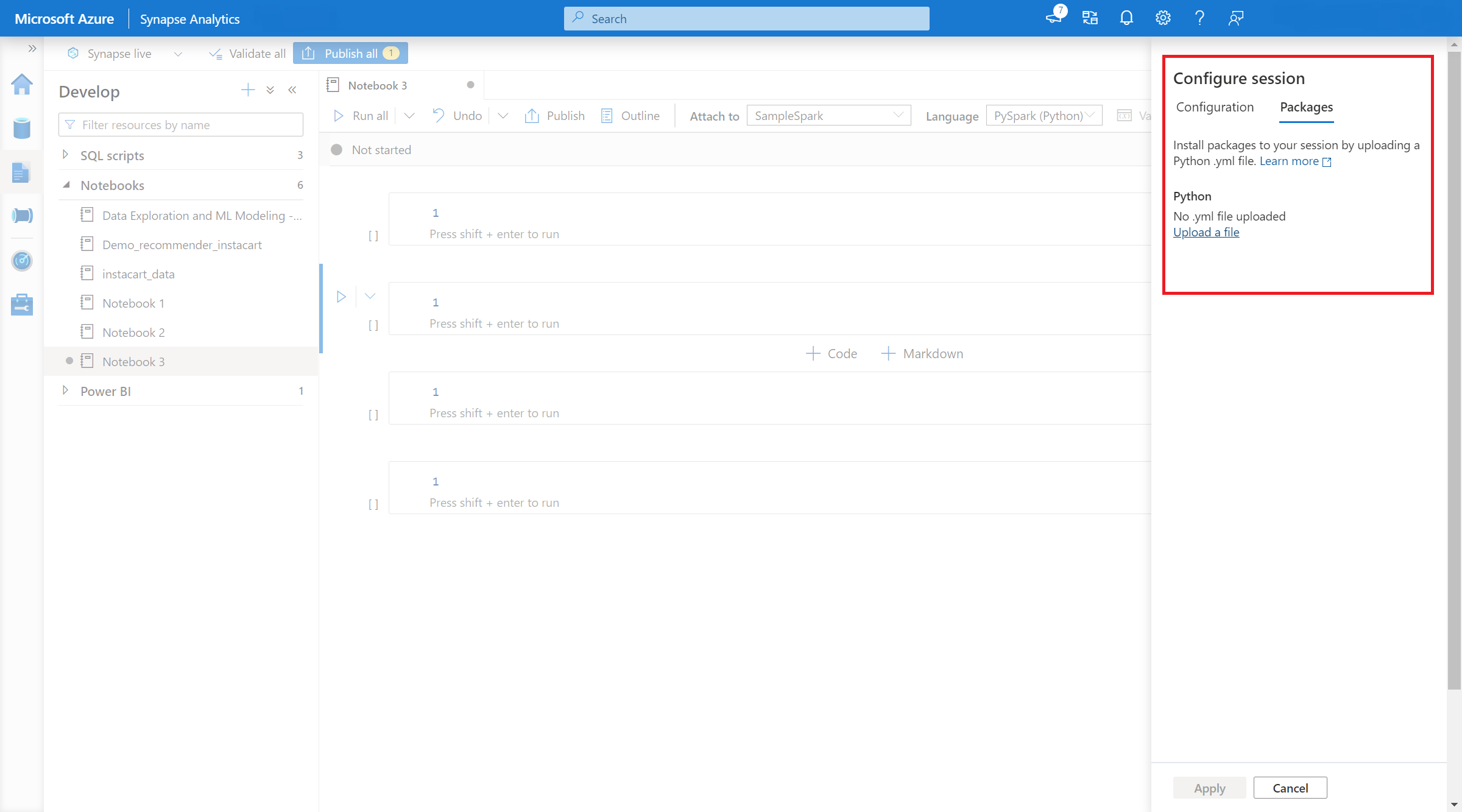
- Tady můžete nahrát soubor Conda environment.yml pro instalaci nebo upgrade balíčků v rámci relace. Zadané knihovny se zobrazí po zahájení relace. Tyto knihovny už nebudou po ukončení relace dostupné.

Správa balíčků Pythonu v rozsahu relace prostřednictvím příkazů %pip a %conda
Oblíbené příkazy %pip a %conda můžete použít k instalaci dalších knihoven třetích stran nebo vlastních knihoven během relace poznámkového bloku Apache Spark. V této části použijeme příkazy %pip k předvedení několika běžných scénářů.
Poznámka
- Pokud chcete nainstalovat nové knihovny, doporučujeme umístit příkazy %pip a %conda do první buňky poznámkového bloku. Interpret Pythonu se restartuje po správě knihovny na úrovni relace, aby se změny projevily.
- Tyto příkazy pro správu knihoven Pythonu budou při spouštění úloh kanálu zakázané. Pokud chcete nainstalovat balíček v rámci kanálu, musíte využít možnosti správy knihoven na úrovni fondu.
- Knihovny Pythonu v oboru relace se automaticky instalují na uzel ovladače i pracovní uzly.
- Následující příkazy %conda nejsou podporované: create, clean, compare, activate, deactivate, run, package.
- Úplný seznam příkazů najdete v příkazech %pip a %conda .
Instalace balíčku třetí strany
Knihovnu Pythonu můžete snadno nainstalovat z PyPI.
# Install vega_datasets
%pip install altair vega_datasets
Pokud chcete ověřit výsledek instalace, můžete spuštěním následujícího kódu vizualizovat vega_datasets
# Create a scatter plot
# Plot Miles per gallon against the horsepower across different region
import altair as alt
from vega_datasets import data
cars = data.cars()
alt.Chart(cars).mark_point().encode(
x='Horsepower',
y='Miles_per_Gallon',
color='Origin',
).interactive()
Instalace balíčku wheel z účtu úložiště
Pokud chcete nainstalovat knihovnu z úložiště, musíte se ke svému účtu úložiště připojit spuštěním následujících příkazů.
from notebookutils import mssparkutils
mssparkutils.fs.mount(
"abfss://<<file system>>@<<storage account>.dfs.core.windows.net",
"/<<path to wheel file>>",
{"linkedService":"<<storage name>>"}
)
A pak můžete pomocí příkazu %pip install nainstalovat požadovaný balíček wheel.
%pip install /<<path to wheel file>>/<<wheel package name>>.whl
Instalace jiné verze integrované knihovny
Pomocí následujícího příkazu můžete zjistit, jaká je integrovaná verze určitého balíčku. Jako příklad použijeme knihovnu pandas .
%pip show pandas
Výsledkem je následující protokol:
Name: pandas
Version: **1.2.3**
Summary: Powerful data structures for data analysis, time series, and statistics
Home-page: https://pandas.pydata.org
... ...
Pomocí následujícího příkazu můžete knihovnu pandas přepnout na jinou verzi, řekněme 1.2.4.
%pip install pandas==1.2.4
Odinstalace knihovny v rozsahu relace
Pokud chcete odinstalovat balíček, který se nainstaloval v této relaci poznámkového bloku, můžete použít následující příkazy. Předdefinované balíčky však nelze odinstalovat.
%pip uninstall altair vega_datasets --yes
Instalace knihoven ze souborurequirement.txt pomocí příkazu %pip
%pip install -r /<<path to requirement file>>/requirements.txt
Balíčky Java nebo Scala s oborem relace
Pokud chcete určit balíčky Java nebo Scala s oborem relace, můžete použít %%configure možnost:
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<file system>>@<<storage account>.dfs.core.windows.net/<<path to JAR file>>",
}
}
Poznámka
- Doporučujeme spustit %%configure na začátku poznámkového bloku. Úplný seznam platných parametrů najdete v tomto dokumentu .
Balíčky R s oborem relace (Preview)
Azure Synapse Analytické fondy zahrnují mnoho oblíbených knihoven R. Během relace poznámkového bloku Apache Sparku můžete také nainstalovat další knihovny třetích stran.
Poznámka
- Tyto příkazy pro správu knihoven jazyka R budou při spouštění úloh kanálu zakázané. Pokud chcete nainstalovat balíček v rámci kanálu, musíte využít možnosti správy knihoven na úrovni fondu.
- Knihovny R v rozsahu relace se automaticky instalují na uzel ovladače i pracovní uzly.
Instalace balíčku
Knihovnu R můžete snadno nainstalovat z CRAN.
# Install a package from CRAN
install.packages(c("nycflights13", "Lahman"))
Jako úložiště můžete také použít snímky CRAN, abyste měli jistotu, že si pokaždé stáhnete stejnou verzi balíčku.
install.packages("highcharter", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
Instalace balíčků pomocí devtools
Knihovna devtools zjednodušuje vývoj balíčků, aby urychlila běžné úlohy. Tato knihovna je nainstalovaná ve výchozím modulu runtime Azure Synapse Analytics.
Pomocí příkazu devtools můžete určit konkrétní verzi knihovny, kterou chcete nainstalovat. Tyto knihovny se nainstalují na všechny uzly v rámci clusteru.
# Install a specific version.
install_version("caesar", version = "1.0.0")
Podobně můžete knihovnu nainstalovat přímo z GitHubu.
# Install a GitHub library.
install_github("jtilly/matchingR")
V současné době jsou v rámci služby Azure Synapse Analytics podporované následující devtools funkce:
| Příkaz | Popis |
|---|---|
| install_github() | Nainstaluje balíček R z GitHubu. |
| install_gitlab() | Nainstaluje balíček R z GitLabu. |
| install_bitbucket() | Nainstaluje balíček R z BitBucketu. |
| install_url() | Nainstaluje balíček R z libovolné adresy URL. |
| install_git() | Instalace z libovolného úložiště Git |
| install_local() | Instalace z místního souboru na disku |
| install_version() | Instalace z konkrétní verze v CRAN |
Zobrazení nainstalovaných knihoven
Pomocí příkazu se můžete dotazovat na všechny knihovny nainstalované v rámci relace library .
library()
Ke kontrole verze knihovny můžete použít packageVersion funkci :
packageVersion("caesar")
Odebrání balíčku R z relace
K odebrání knihovny z oboru názvů můžete použít detach funkci . Tyto knihovny zůstanou na disku, dokud se znovu nenačtou.
# detach a library
detach("package: caesar")
Pokud chcete z poznámkového bloku odebrat balíček v rozsahu relace, použijte příkaz remove.packages() . Tato změna knihovny nemá žádný vliv na jiné relace ve stejném clusteru. Uživatelé nemůžou odinstalovat ani odebrat integrované knihovny výchozího modulu runtime Azure Synapse Analytics.
remove.packages("caesar")
Poznámka
Základní balíčky, jako jsou SparkR, SparklyR nebo R, nemůžete odebrat.
Knihovny R s rozsahem relace a SparkR
Knihovny v rámci poznámkových bloků jsou k dispozici v pracovních prostředích SparkR.
install.packages("stringr")
library(SparkR)
str_length_function <- function(x) {
library(stringr)
str_length(x)
}
docs <- c("Wow, I really like the new light sabers!",
"That book was excellent.",
"R is a fantastic language.",
"The service in this restaurant was miserable.",
"This is neither positive or negative.")
spark.lapply(docs, str_length_function)
Knihovny R s rozsahem relace a SparklyR
S spark_apply() v SparklyR můžete použít libovolný balíček R ve Sparku. Ve výchozím nastavení je argument packages v souboru sparklyr::spark_apply() nastaven na FALSE. Tím se knihovny v aktuálních knihovnách libPaths zkopírují do pracovních procesů a umožní vám je importovat a používat v pracovních procesů. Spuštěním následujícího příkazu můžete například vygenerovat zprávu zašifrovanou caesarem pomocí sparklyr::spark_apply():
install.packages("caesar", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
spark_version <- "3.2"
config <- spark_config()
sc <- spark_connect(master = "yarn", version = spark_version, spark_home = "/opt/spark", config = config)
apply_cases <- function(x) {
library(caesar)
caesar("hello world")
}
sdf_len(sc, 5) %>%
spark_apply(apply_cases, packages=FALSE)
Další kroky
- Zobrazení výchozích knihoven: Podpora verzí Apache Sparku
- Správa balíčků mimo portál Synapse Studio: Správa balíčků prostřednictvím příkazů Az a rozhraní REST API