Vytváření úloh a vstupních dat pro dávkové koncové body
Když ve službě Azure Machine Learning používáte dávkové koncové body, můžete provádět dlouhé dávkové operace nad velkými objemy vstupních dat. Data se můžou nacházet na různých místech, například v různých oblastech. Některé typy dávkových koncových bodů mohou také přijímat literály jako vstupy.
Tento článek popisuje, jak zadat vstupy parametrů pro dávkové koncové body a vytvořit úlohy nasazení. Tento proces podporuje práci s daty z různých zdrojů, jako jsou datové prostředky, úložiště dat, účty úložiště a místní soubory.
Požadavky
Dávkové koncové body a nasazení. Pokud chcete tyto prostředky vytvořit, přečtěte si téma Nasazení modelů MLflow v dávkových nasazeních ve službě Azure Machine Learning.
Oprávnění ke spuštění dávkového nasazení koncového bodu Ke spuštění nasazení můžete použít role azureML Datoví vědci, přispěvatele a vlastníka. Pokud chcete zkontrolovat konkrétní oprávnění požadovaná pro vlastní definice rolí, přečtěte si téma Autorizace v dávkových koncových bodech.
Přihlašovací údaje pro vyvolání koncového bodu Další informace naleznete v tématu Vytvoření ověřování.
Čtení přístupu ke vstupním datům z výpočetního clusteru, kde je koncový bod nasazený.
Tip
V některých situacích se jako vstup dat vyžaduje použití úložiště dat bez přihlašovacích údajů nebo externího účtu azure Storage. V těchto scénářích se ujistěte, že nakonfigurujete výpočetní clustery pro přístup k datům, protože spravovaná identita výpočetního clusteru se používá pro připojení účtu úložiště. Stále máte podrobné řízení přístupu, protože identita úlohy (invoker) se používá ke čtení podkladových dat.
Navázání ověřování
K vyvolání koncového bodu potřebujete platný token Microsoft Entra. Když vyvoláte koncový bod, Azure Machine Learning vytvoří úlohu dávkového nasazení pod identitou přidruženou k tokenu.
- Pokud k vyvolání koncových bodů používáte azure Machine Learning CLI (v2) nebo sadu Azure Machine Learning SDK pro Python (v2), nemusíte token Microsoft Entra získat ručně. Během přihlašování systém ověřuje vaši identitu uživatele. Také za vás načte a předá token.
- Pokud k vyvolání koncových bodů použijete rozhraní REST API, musíte token získat ručně.
Pro vyvolání můžete použít vlastní přihlašovací údaje, jak je popsáno v následujících postupech.
Pomocí Azure CLI se přihlaste pomocí interaktivního ověřování kódu nebo pomocí kódu zařízení:
az login
Další informace o různých typech přihlašovacích údajů najdete v tématu Spouštění úloh pomocí různých typů přihlašovacích údajů.
Vytvoření základních úloh
Pokud chcete vytvořit úlohu z dávkového koncového bodu, vyvoláte koncový bod. Volání je možné provést pomocí azure Machine Learning CLI, sady Azure Machine Learning SDK pro Python nebo volání rozhraní REST API.
Následující příklady ukazují základy vyvolání dávkového koncového bodu, který přijímá jednu vstupní složku dat ke zpracování. Příklady, které zahrnují různé vstupy a výstupy, najdete v tématu Vysvětlení vstupů a výstupů.
invoke Použijte operaci v rámci dávkových koncových bodů:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Vyvolání konkrétního nasazení
Koncové body služby Batch můžou hostovat více nasazení ve stejném koncovém bodu. Výchozí koncový bod se použije, pokud uživatel nezadá jinak. Pomocí následujících postupů můžete změnit nasazení, které používáte.
Použijte argument --deployment-name nebo -d zadejte název nasazení:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--deployment-name $DEPLOYMENT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Konfigurace vlastností úlohy
Některé vlastnosti úlohy můžete nakonfigurovat při vyvolání.
Poznámka:
V současné době můžete konfigurovat vlastnosti úlohy pouze v dávkových koncových bodech s nasazeními součástí kanálu.
Konfigurace názvu experimentu
Ke konfiguraci názvu experimentu použijte následující postupy.
Pomocí argumentu --experiment-name zadejte název experimentu:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--experiment-name "my-batch-job-experiment" \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Vysvětlení vstupů a výstupů
Koncové body služby Batch poskytují odolné rozhraní API, které uživatelé můžou použít k vytváření dávkových úloh. Stejné rozhraní lze použít k určení vstupů a výstupů, které vaše nasazení očekává. Pomocí vstupů předejte všechny informace, které koncový bod potřebuje k provedení úlohy.
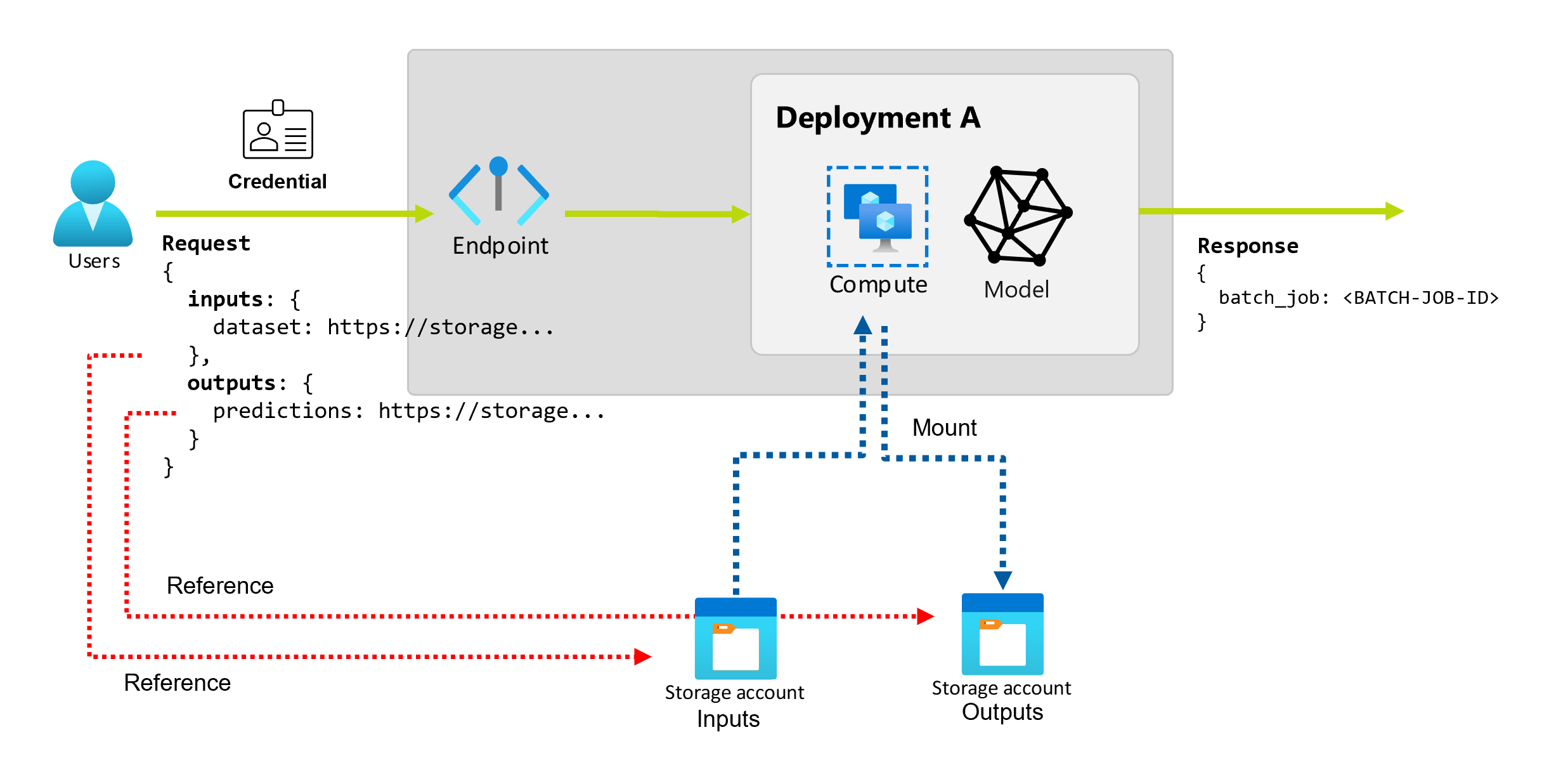
Koncové body služby Batch podporují dva typy vstupů:
- Vstupy dat nebo ukazatele na konkrétní umístění úložiště nebo prostředek služby Azure Machine Learning
- Literální vstupy nebo hodnoty literálů, jako jsou čísla nebo řetězce, které chcete předat úloze
Počet a typ vstupů a výstupů závisí na typu dávkového nasazení. Nasazení modelu vždy vyžadují jeden vstup dat a vytvoří jeden výstup dat. Vstupy literálů nejsou podporovány v nasazeních modelů. Nasazení součástí kanálu naproti tomu poskytují obecnější konstruktor pro vytváření koncových bodů. V nasazení komponenty kanálu můžete zadat libovolný počet vstupů dat, literálových vstupů a výstupů.
Následující tabulka shrnuje vstupy a výstupy pro dávkové nasazení:
| Typ nasazení | Počet vstupů | Podporované vstupní typy | Počet výstupů | Podporované typy výstupu |
|---|---|---|---|---|
| Nasazení modelu | 0 | Vstupy dat | 0 | Výstupy dat |
| Nasazení součásti kanálu | 0-N | Datové vstupy a literální vstupy | 0-N | Výstupy dat |
Tip
Vstupy a výstupy jsou vždy pojmenovány. Každý název slouží jako klíč pro identifikaci dat a předání hodnoty během vyvolání. Vzhledem k tomu, že nasazení modelu vždy vyžadují jeden vstup a výstup, názvy se při vyvolání v nasazení modelu ignorují. Můžete přiřadit název, který nejlépe popisuje váš případ použití, například sales_estimation.
Prozkoumání datových vstupů
Vstupy dat odkazují na vstupy, které odkazují na umístění, kde jsou data umístěna. Vzhledem k tomu, že dávkové koncové body obvykle spotřebovávají velké objemy dat, nemůžete vstupní data předávat jako součást žádosti o vyvolání. Místo toho zadáte umístění, kam má koncový bod dávky přejít, aby vyhledaly data. Vstupní data se připojují a streamují do cílové výpočetní instance, aby se zlepšil výkon.
Koncové body služby Batch mohou číst soubory, které jsou umístěné v následujících typech úložiště:
-
Datové prostředky služby Azure Machine Learning, včetně typů složek (
uri_folder) a souborů (uri_file). - Úložiště dat Azure Machine Learning, včetně Azure Blob Storage, Azure Data Lake Storage Gen1 a Azure Data Lake Storage Gen2.
- Účty Azure Storage, včetně služby Blob Storage, Data Lake Storage Gen1 a Data Lake Storage Gen2.
- Místní datové složky a soubory, když k vyvolání koncových bodů použijete Azure Machine Learning CLI nebo sadu Azure Machine Learning SDK pro Python. Místní data se ale nahrají do výchozího úložiště dat vašeho pracovního prostoru Azure Machine Learning.
Důležité
Oznámení o vyřazení: Datové prostředky typu FileDataset (V1) jsou zastaralé a v budoucnu se vyřadí z provozu. Stávající dávkové koncové body, které spoléhají na tuto funkci, budou i nadále fungovat. V dávkových koncových bodech vytvořených pomocí:
- Verze azure Machine Learning CLI verze 2, které jsou obecně dostupné (2.4.0 a novější).
- Obecně dostupné verze rozhraní REST API (2022-05-01 a novější).
Prozkoumání vstupů literálů
Literální vstupy odkazují na vstupy, které lze reprezentovat a přeložit při vyvolání, jako jsou řetězce, čísla a logické hodnoty. Jako součást nasazení komponenty kanálu se obvykle používají literální vstupy k předávání parametrů do koncového bodu. Koncové body služby Batch podporují následující typy literálů:
stringbooleanfloatinteger
Vstupy literálů jsou podporovány pouze v nasazeních součástí kanálu. Pokud chcete zjistit, jak zadat koncové body literálu, přečtěte si téma Vytváření úloh s literálními vstupy.
Prozkoumání výstupů dat
Výstupy dat odkazují na umístění, kde jsou umístěny výsledky dávkové úlohy. Každý výstup má identifikovatelný název a Azure Machine Learning automaticky přiřadí každému pojmenovaného výstupu jedinečnou cestu. Pokud potřebujete, můžete zadat jinou cestu.
Důležité
Koncové body služby Batch podporují pouze zápis výstupů v úložištích dat Blob Storage. Pokud potřebujete zapisovat do účtu úložiště s povolenými hierarchickými obory názvů, jako je Data Lake Storage Gen2, můžete službu úložiště zaregistrovat jako úložiště dat Blob Storage, protože služby jsou plně kompatibilní. Tímto způsobem můžete zapisovat výstupy z dávkových koncových bodů do Data Lake Storage Gen2.
Vytváření úloh s datovými vstupy
Následující příklady ukazují, jak vytvářet úlohy při přebírání datových vstupů z datových prostředků, úložišť dat a účtů Azure Storage.
Použití vstupních dat z datového assetu
Datové prostředky Azure Machine Learning (dříve označované jako datové sady) se podporují jako vstupy pro úlohy. Pomocí těchto kroků spusťte úlohu dávkového koncového bodu, která používají vstupní data uložená v registrovaném datovém assetu ve službě Azure Machine Learning.
Upozorňující
Datové prostředky tabulky typu (MLTable) se v současné době nepodporují.
Vytvořte datový asset. V tomto příkladu se skládá ze složky, která obsahuje více souborů CSV. K paralelnímu zpracování souborů použijete dávkové koncové body. Tento krok můžete přeskočit, pokud jsou vaše data už zaregistrovaná jako datový prostředek.
Vytvořte definici datového prostředku v souboru YAML s názvem heart-data.yml:
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json name: heart-data description: An unlabeled data asset for heart classification. type: uri_folder path: dataVytvoření datového assetu:
az ml data create -f heart-data.yml
Nastavte vstup:
DATA_ASSET_ID=$(az ml data show -n heart-data --label latest | jq -r .id)ID datového assetu má formát
/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/data/<data-asset-name>/versions/<data-asset-version>.Spusťte koncový bod:
--setK zadání vstupu použijte argument. Nejprve nahraďte všechny pomlčky v názvu datového assetu podtržítkem. Klíče můžou obsahovat pouze alfanumerické znaky a podtržítka.az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$DATA_ASSET_IDU koncového bodu, který obsluhuje nasazení modelu, můžete použít
--inputargument k určení vstupu dat, protože nasazení modelu vždy vyžaduje pouze jeden vstup dat.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $DATA_ASSET_ID--setArgument má tendenci vytvářet dlouhé příkazy při zadávání více vstupů. V takových případech můžete vypsat vstupy v souboru a při vyvolání koncového bodu odkazovat na soubor. Můžete například vytvořit soubor YAML s názvem inputs.yml, který obsahuje následující řádky:inputs: heart_data: type: uri_folder path: /subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/data/heart-data/versions/1Pak můžete spustit následující příkaz, který pomocí argumentu
--fileurčí vstupy:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Použití vstupních dat z úložiště dat
Úlohy dávkového nasazení můžou přímo odkazovat na data, která jsou v registrovaných úložištích dat služby Azure Machine Learning. V tomto příkladu nejprve nahrajete některá data do úložiště dat v pracovním prostoru Služby Azure Machine Learning. Pak na tato data spustíte dávkové nasazení.
Tento příklad používá výchozí úložiště dat, ale můžete použít jiné úložiště dat. V jakémkoli pracovním prostoru Azure Machine Learning je název výchozího úložiště dat objektů blob pracovní prostorblobstore. Pokud chcete v následujících krocích použít jiné úložiště dat, nahraďte workspaceblobstore ho názvem upřednostňovaného úložiště dat.
Nahrajte ukázková data do úložiště dat. Ukázková data jsou k dispozici v úložišti azureml-examples . Data najdete ve složce sdk/python/endpoints/batch/deploy-models/heart-classifier-mlflow/data daného úložiště.
- V studio Azure Machine Learning otevřete stránku datových prostředků pro výchozí úložiště dat objektů blob a vyhledejte název kontejneru objektů blob.
- Pomocí nástroje, jako je Průzkumník služby Azure Storage nebo AzCopy, nahrajte ukázková data do složky s názvem heart-disease-uci-unlabeled v tomto kontejneru.
Nastavení vstupních informací:
Umístěte cestu k souboru do
INPUT_PATHproměnné:DATA_PATH="heart-disease-uci-unlabeled" INPUT_PATH="azureml://datastores/workspaceblobstore/paths/$DATA_PATH"Všimněte si, jak
pathsje složka součástí vstupní cesty. Tento formát označuje, že následující hodnota je cesta.Spusťte koncový bod:
Pomocí argumentu
--setzadejte vstup:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$INPUT_PATHU koncového bodu, který obsluhuje nasazení modelu, můžete použít
--inputargument k určení vstupu dat, protože nasazení modelu vždy vyžaduje pouze jeden vstup dat.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_PATH --input-type uri_folder--setArgument má tendenci vytvářet dlouhé příkazy při zadávání více vstupů. V takových případech můžete vypsat vstupy v souboru a při vyvolání koncového bodu odkazovat na soubor. Můžete například vytvořit soubor YAML s názvem inputs.yml, který obsahuje následující řádky:inputs: heart_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/<data-path>Pokud jsou vaše data v souboru, použijte
uri_filemísto toho typ pro vstup.Pak můžete spustit následující příkaz, který pomocí argumentu
--fileurčí vstupy:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Použití vstupních dat z účtu Azure Storage
Koncové body služby Azure Machine Learning batch můžou číst data z cloudových umístění v účtech Azure Storage, a to jak ve veřejném, tak privátním. Pomocí následujících kroků spusťte úlohu dávkového koncového bodu s daty v účtu úložiště.
Další informace o dalších požadovaných konfiguracích pro čtení dat z účtů úložiště najdete v tématu Konfigurace výpočetních clusterů pro přístup k datům.
Nastavte vstup:
Nastavte proměnnou
INPUT_DATA:INPUT_DATA="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"Pokud jsou vaše data v souboru, použijte k definování vstupní cesty formát podobný následujícímu:
INPUT_DATA="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data/heart.csv"Spusťte koncový bod:
Pomocí argumentu
--setzadejte vstup:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$INPUT_DATAU koncového bodu, který obsluhuje nasazení modelu, můžete použít
--inputargument k určení vstupu dat, protože nasazení modelu vždy vyžaduje pouze jeden vstup dat.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_DATA --input-type uri_folderArgument
--setmá tendenci vytvářet dlouhé příkazy při zadávání více vstupů. V takových případech můžete vypsat vstupy v souboru a při vyvolání koncového bodu odkazovat na soubor. Můžete například vytvořit soubor YAML s názvem inputs.yml, který obsahuje následující řádky:inputs: heart_data: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/dataPak můžete spustit následující příkaz, který pomocí argumentu
--fileurčí vstupy:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlPokud jsou vaše data v souboru, použijte
uri_filepro vstup dat typ v souboru inputs.yml.
Vytváření úloh s literálními vstupy
Nasazení komponent kanálu můžou přijímat literální vstupy. Příklad dávkového nasazení, které obsahuje základní kanál, najdete v tématu Postup nasazení kanálů s koncovými body dávky.
Následující příklad ukazuje, jak zadat vstup s názvem score_mode, typu string, s hodnotou append:
Umístěte vstupy do souboru YAML, například do souboru s názvem inputs.yml:
inputs:
score_mode:
type: string
default: append
Spusťte následující příkaz, který pomocí argumentu --file určuje vstupy.
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Argument můžete použít --set také k určení typu a výchozí hodnoty. Tento přístup ale při zadávání více vstupů obvykle vytváří dlouhé příkazy:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--set inputs.score_mode.type="string" inputs.score_mode.default="append"
Vytváření úloh s výstupy dat
Následující příklad ukazuje, jak změnit umístění výstupu s názvem score. Pro úplnost příklad také nakonfiguruje vstup s názvem heart_data.
V tomto příkladu se používá výchozí úložiště dat workspaceblobstore. V pracovním prostoru ale můžete použít jakékoli jiné úložiště dat, pokud se jedná o účet Blob Storage. Pokud chcete použít jiné úložiště dat, nahraďte workspaceblobstore ho v následujících krocích názvem upřednostňovaného úložiště dat.
Získejte ID úložiště dat.
DATA_STORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')ID úložiště dat má formát
/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/datastores/workspaceblobstore.Vytvoření výstupu dat:
Definujte vstupní a výstupní hodnoty v souboru s názvem inputs-and-outputs.yml. Ve výstupní cestě použijte ID úložiště dat. Pro úplnost také definujte vstup dat.
inputs: heart_data: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data outputs: score: type: uri_file path: <data-store-ID>/paths/batch-jobs/my-unique-pathPoznámka:
Všimněte si, jak
pathsje složka součástí výstupní cesty. Tento formát označuje, že následující hodnota je cesta.Spusťte nasazení:
Pomocí argumentu
--filezadejte vstupní a výstupní hodnoty:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs-and-outputs.yml