Trénování doporučovacího systému SVD
Tento článek popisuje, jak používat komponentu Train SVD Recommender v návrháři služby Azure Machine Learning. Tato komponenta slouží k trénování modelu doporučení na základě algoritmu SVD (Single Value Decomposition).
Komponenta Train SVD Recommender čte datovou sadu trojité hodnocení položek uživatele. Vrátí natrénovaný doporučovač SVD. Potom můžete použít natrénovaný model k predikci hodnocení nebo generování doporučení připojením komponenty Score SVD Recommender .
Další informace o modelech doporučení a doporučovacím nástroji SVD
Hlavním cílem systému doporučení je doporučit uživatelům systému jednu nebo více položek. Příkladem položky může být film, restaurace, kniha nebo skladba. Uživatel může být osoba, skupina osob nebo jiná entita s předvolbami položek.
Existují dva hlavní přístupy k doporučovacím systémům:
- Přístup založený na obsahu využívá funkce pro uživatele i položky. Uživatelé mohou být popsáni vlastnostmi, jako je věk a pohlaví. Položky mohou být popsány vlastnostmi, jako je autor a výrobce. Typické příklady systémů doporučení založených na obsahu najdete na webech pro tvorbu sociálních shody.
- Při filtrování spolupráce se používají jenom identifikátory uživatelů a položek. Získá implicitní informace o těchto entitách z (řídké) matice hodnocení udělených uživateli k položkám. O uživateli můžeme zjistit informace o položkách, které ohodnotil, a od jiných uživatelů, kteří ohodnotili stejné položky.
Doporučovací nástroj SVD používá identifikátory uživatelů a položek a matici hodnocení, kterou uživatelé přiřadují k položkám. Jedná se o doporučovací nástroj pro spolupráci.
Další informace o doporučovací funkci SVD najdete v příslušném výzkumném dokumentu: Techniky faktorizace matice pro doporučovací systémy.
Postup konfigurace doporučovacího modulu SVD Train
Příprava dat
Před použitím komponenty musí být vstupní data ve formátu, který model doporučení očekává. Vyžaduje se trénovací datová sada trojitých hodnocení položek uživatele.
- První sloupec obsahuje identifikátory uživatelů.
- Druhý sloupec obsahuje identifikátory položek.
- Třetí sloupec obsahuje hodnocení pro dvojici položek uživatele. Hodnoty hodnocení musí být číselného typu.
Datová sada Hodnocení filmů v návrháři služby Azure Machine Learning (výběr datových sad a následných ukázek) ukazuje očekávaný formát:
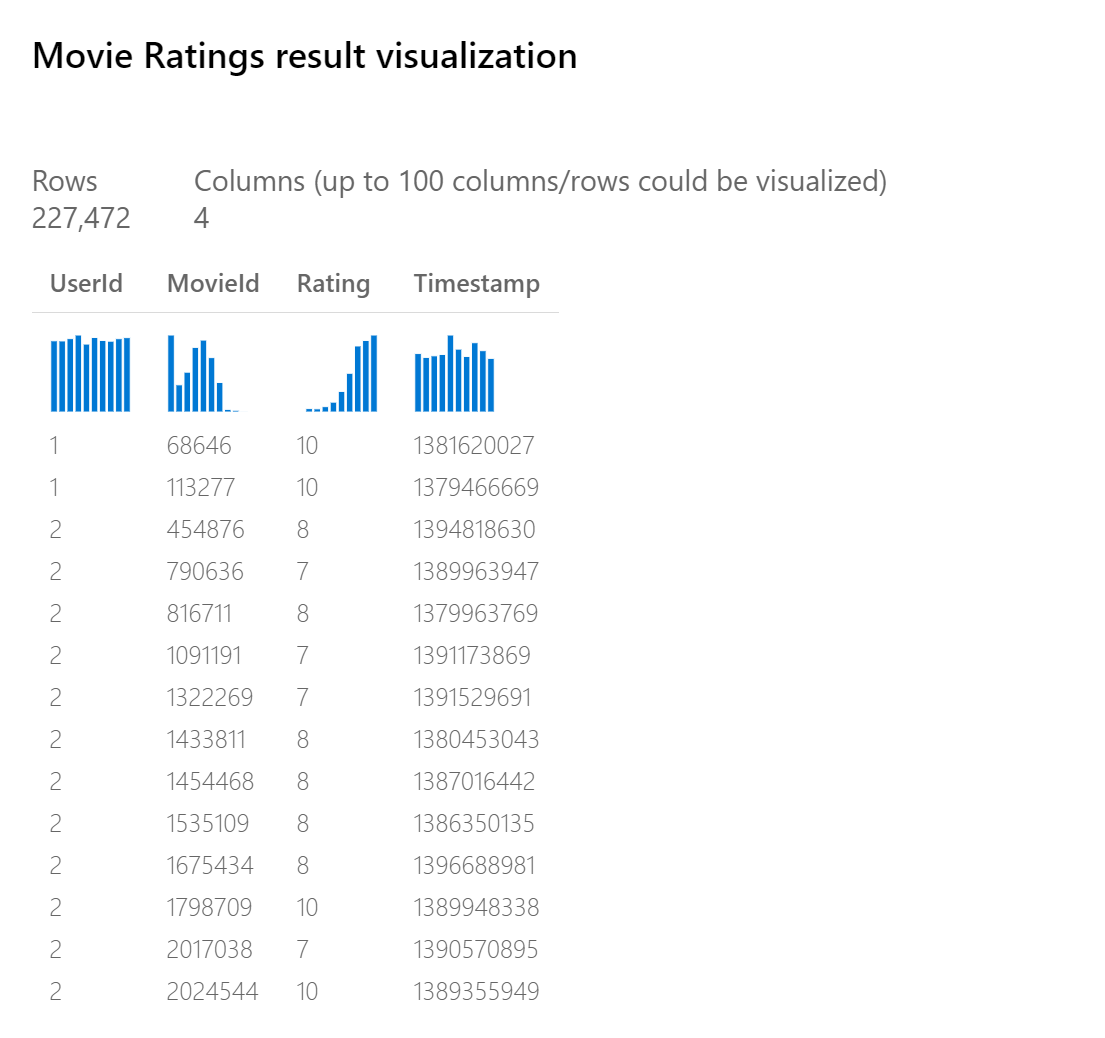
Z této ukázky vidíte, že jeden uživatel ohodnotil několik filmů.
Trénování modelu
Přidejte do kanálu v návrháři komponentu Train SVD Recommender a připojte ji k trénovacím datům.
V části Počet faktorů zadejte počet faktorů, které se mají použít s doporučovacím nástrojem.
Každý faktor měří, kolik uživatel souvisí s položkou. Počet faktorů je také rozměrnost latentního faktorového prostoru. S rostoucím počtem uživatelů a položek je lepší nastavit větší počet faktorů. Pokud je ale číslo příliš velké, může dojít k poklesu výkonu.
Počet iterací algoritmu doporučení označuje, kolikrát by měl algoritmus zpracovávat vstupní data. Čím vyšší je toto číslo, tím přesnější jsou předpovědi. Vyšší číslo ale znamená pomalejší trénování. Výchozí hodnota je 30.
V části Rychlost učení zadejte číslo od 0,0 do 2,0, které definuje velikost kroku pro výuku.
Rychlost učení určuje velikost kroku při každé iteraci. Pokud je velikost kroku příliš velká, můžete optimální řešení překroutit. Pokud je velikost kroku příliš malá, trénování trvá déle, než najdete nejlepší řešení.
Odešlete kanál.
Výsledky
Po dokončení úlohy kanálu pro použití modelu pro bodování připojte nástroj Train SVD Recommender k určení skóre doporučovacího nástroje SVD a predikujte hodnoty pro nové příklady vstupu.
Další kroky
Podívejte se na sadu komponent dostupných pro Azure Machine Learning.